Установка Beautifulsoup и примеры
Разберем как производится установка beautifulsoup — библиотеки, которая позволяет работать с содержимым веб-страниц в интернете, извлекая из больших объемов структурированной информации нужную. Используется для парсинга.
Python beautifulsoup: установка и использование, примеры
Прежде всего, создадим виртуальное окружение. Назвать его можно, например, parser
Подробнее о виртуальном окружении и необходимых для его работы пакетах
(parser) admin@desktop:/
В терминале после активации появляется указанное ранее имя.
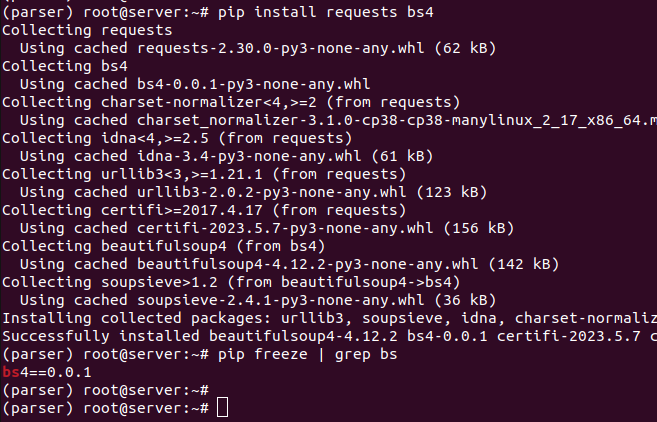
Как установить beautifulsoup python
BeautifulSoup является частью библиотеки bs4, парсер также требует requests, все устанавливается через pip из окружения
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1 urllib3-1.23 beautifulsoup4-4.6.3 bs4-0.0.1
Пример вывода на скриншоте:
Установка завершена, теперь можно перейти к созданию скрипта
import requests from bs4 import BeautifulSoup page = requests.get('https://yandex.ru') soup = BeautifulSoup(page.text, 'html.parser')
Создается объект BeautifulSoup, в скобках указываются два параметра.
Первый — результат применения метода text к содержимому переменной page. Переменная page содержит текст страницы, путь к которой задан.
Второй аргумент — html.parser
С данными далее можно производить любые манипуляции.
Пример форматирования результата полученного с помощью BeautifulSoup
Добавим в скрипт такие строки
city = soup.find(class_='geolink__reg') print (city.prettify())
Вызов скрипта из консоли
Скрипт спарсил главную страницу Яндекса и получил содержимое тега с классом geolink__reg из HTML кода. Класс выбран для демонстрации при визуальном анализе исходного кода (CTRL+U в браузере).
В данном случае в нем находится город, определенный при помощи geoip
Здесь используется метод prettify, который позволяет создавать отформатированное дерево тегов с результатами поиска.
Теперь закомментируем последний print и вместо него
city = soup.find(class_='geolink__reg') #print (city.prettify) print (city.contents[0])
Если вызвать скрипт сейчас можно увидеть, что он отдает только сам контент, в данном случае — имя города.
Екатеринбург
Это достигнуто использованием contents[0], все лишние тэги удалены. Результаты парсинга можно сохранять в csv файлы или обычные текстовые документы. Записывать можно не все, а выбирать только нужное содержимое работая с ним как с текстом.
Скрипты с BeautifulSoup можно запускать по какому-то расписанию по системному планировщику задач CRON
How To Install BeautifulSoup
To install BeautifulSoup on a MacOS or Linux machines run:
sudo pip3 install beautifulsoup4
To install BeautifulSoup on a Windows machine run:
pip3 install beautifulsoup4
To import BeautifulSoup into your Python script:
from bs4 import BeautifulSoup
Then to use BeautifulSoup to parse a HTML file, simply initialize a BeautifulSoup instance with the HTML file.
from bs4 import BeautifulSoup html_doc = """ Hello!
""" soup = BeautifulSoup(html_doc, 'html.parser') print(soup.find('h1').get_text()) # --> 'Hello!'
In this guide for The Python Web Scraping Playbook, we will look at how to install and use Python’s popular BeautifulSoup library on Windows, MacOS, Linux machines.
We will walk your through:
- How To Install BeautifulSoup On MacOS & Linux
- How To Install BeautifulSoup On Windows
- How To Import & Setup BeautifulSoup
First, let’s get a quick overview of what is BeautifulSoup.
How To Install BeautifulSoup On MacOS & Linux
Installing Python’s BeautifulSoup on a MacOS machine is very straightforward.
Step 1: Install Latest Python Version
To do so, run the following command in your terminal:
python3 --version >> Python 3.11.0
Step 2: Upgrade Pip
Next upgrade pip to the latest version to avoid any installation issues.
sudo pip3 install --upgrade pip
Step 3: Install BeautifulSoup
Finally, we just need to install BeautifulSoup.
sudo pip3 install beautifulsoup4
How To Install BeautifulSoup On Windows
Installing Python’s BeautifulSoup on a Windows machine is very straightforward.
Step 1: Install Latest Python Version
To do so, run the following command in your terminal:
python3 --version >> Python 3.11.0
Step 2: Upgrade Pip
Next upgrade pip to the latest version to avoid any installation issues.
pip3 install --upgrade pip
Step 3: Install BeautifulSoup
Finally, we just need to install BeautifulSoup.
pip3 install beautifulsoup4
How To Import & Setup BeautifulSoup
To import BeautifulSoup into your Python script import BeautifulSoup from the bs4 module:
from bs4 import BeautifulSoup
Then to use BeautifulSoup to parse a HTML file, simply initialize a BeautifulSoup instance with the HTML file.
from bs4 import BeautifulSoup html_doc = """ Hello!
""" soup = BeautifulSoup(html_doc, 'html.parser') print(soup.find('h1').get_text()) # --> 'Hello!'
More Web Scraping Tutorials
So that’s how to install Python BeautifulSoup.
If you would like to learn more about how to use BeautifulSoup then check out our other BeautifulSoup guides:
- BeautifulSoup Guide: Scraping HTML Pages With Python
- Fix BeautifulSoup Returns Empty List or Value
- How To Use BeautifulSoup’s find() Method
- How To Use BeautifulSoup’s find_all() Method
Or if you would like to learn more about Web Scraping, then be sure to check out The Python Web Scraping Playbook.
Or check out one of our more in-depth guides:
- How to Scrape The Web Without Getting Blocked Guide
- The State of Web Scraping 2020
- The Ethics of Web Scraping
- How To Install BeautifulSoup On MacOS & Linux
- Step 1: Install Latest Python Version
- Step 2: Upgrade Pip
- Step 3: Install BeautifulSoup
- Step 1: Install Latest Python Version
- Step 2: Upgrade Pip
- Step 3: Install BeautifulSoup
Модуль BeautifulSoup4 в Python, разбор HTML
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер html.parser . BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml , html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль beautifulsoup4 (VirtualEnv):~$ python3 -m pip install -U beautifulsoup4
Содержание:
- Выбор парсера для использования в BeautifulSoup4.
- Парсер lxml .
- Парсер html5lib .
- Встроенный в Python парсер html.parser .
- Навигация по структуре HTML-документа.
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу.
- Поиск тегов при помощи CSS селекторов.
- Дочерние элементы.
- Родительские элементы.
- Изменение имен тегов HTML-документа.
- Добавление новых тегов в HTML-документ.
- Удаление и замена тегов в HTML-документе.
- Изменение атрибутов тегов HTML-документа.
Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке: .
Парсер lxml .
- Для запуска примера, необходимо установить модуль lxml .
- Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
>>> from bs4 import BeautifulSoup >>> BeautifulSoup(" ", "lxml") #
Обратите внимание, что тег заключен в теги и , а висячий тег
просто игнорируется.
Парсер html5lib .
- Для запуска примера, необходимо установить модуль html5lib .
- Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
>>> from bs4 import BeautifulSoup >>> BeautifulSoup(" ", "html5lib") #
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег
, и к тому же добавляет открывающий тег
. Также html5lib добавляет пустой тег ( lxml этого не сделал).
Встроенный в Python парсер html.parser .
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как lxml .
- Более строгий, чем html5lib .
>>> from bs4 import BeautifulSoup >>> BeautifulSoup(" ", 'html.parser') #
Как и lxml , встроенный в Python парсер игнорирует закрывающий тег
. В отличие от html5lib , этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги или .
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup() . Можно передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup # передаем объект открытого файла with open("index.html") as fp: soup = BeautifulSoup(fp, 'html.parser') # передаем строку soup = BeautifulSoup("a web page", 'html.parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
>>> from bs4 import BeautifulSoup >>> html = " Sacré bleu!" >>> parse = BeautifulSoup(html, 'html.parser') >>> print(parse) # Sacré bleu!
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
html_doc = """html>head>title>The Dormouse's storytitle>head> body> p class="title">b>The Dormouse's storyb>p> p class="story">Once upon a time there were three little sisters; and their names were a href="http://example.com/elsie" class="sister" id="link1">Elsiea>, a href="http://example.com/lacie" class="sister" id="link2">Laciea> and a href="http://example.com/tillie" class="sister" id="link3">Tilliea>; and they lived at the bottom of a well.p> p class="story">. p>"""Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html_doc, 'html.parser') >>> print(soup.prettify()) # # # # The Dormouse's story # # # #
# # The Dormouse's story # #
## Once upon a time there were three little sisters; and their names were
# # Elsie # # , # # Lacie # # and # # Tillie # # ; and they lived at the bottom of a well. # ## .
# #