Python: коллекции, часть 1/4: классификация, общие подходы и методы, конвертация

Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции.
Частая проблема при изучении коллекций заключается в том, что разобрав каждый тип довольно детально, обычно потом не уделяется достаточного внимания разъяснению картины в целом, не проводятся чёткие сходства и различия между типами, не показывается как одну и туже задачу решать для каждой из коллекций в сравнении.
Вот именно эту проблему я хочу попытаться решить в данном цикле статей – рассмотреть ряд подходов к работе со стандартными коллекциями в Python в сравнении между коллекциями разных типов, а не по отдельности, как это обычно показывается в обучающих материалах. Кроме того, постараюсь затронуть некоторые моменты, вызывающие сложности и ошибки у начинающих.
Для кого: для изучающих Python и уже имеющих начальное представление о коллекциях и работе с ними, желающих систематизировать и углубить свои знания, сложить их в целостную картину.
Будем рассматривать стандартные встроенные коллекционные типы данных в Python: список (list), кортеж (tuple), строку (string), множества (set, frozenset), словарь (dict). Коллекции из модуля collections рассматриваться не будут, хотя многое из статьи должно быть применимым и при работе с ними.
ОГЛАВЛЕНИЕ:
- Классификация коллекций;
- Общие подходы к работе с коллекциями;
- Общие методы для части коллекций;
- Конвертирование коллекций.
1. Классификация коллекций
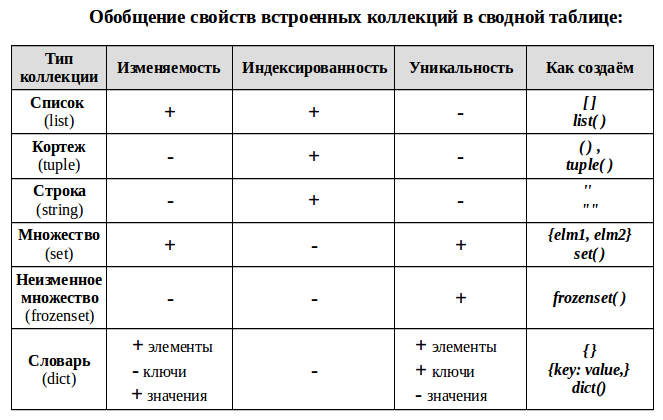
Пояснения терминологии:
Индексированность – каждый элемент коллекции имеет свой порядковый номер — индекс. Это позволяет обращаться к элементу по его порядковому индексу, проводить слайсинг («нарезку») — брать часть коллекции выбирая исходя из их индекса. Детально эти вопросы будут рассмотрены в дальнейшем в отдельной статье.
Уникальность – каждый элемент коллекции может встречаться в ней только один раз. Это порождает требование неизменности используемых типов данных для каждого элемента, например, таким элементом не может быть список.
Изменяемость коллекции — позволяет добавлять в коллекцию новых членов или удалять их после создания коллекции.
Примечание для словаря (dict):
- сам словарь изменяем — можно добавлять/удалять новые пары ключ: значение;
- значения элементов словаря — изменяемые и не уникальные;
- а вот ключи — не изменяемые и уникальные, поэтому, например, мы не можем сделать ключом словаря список, но можем кортеж. Из уникальности ключей, так же следует уникальность элементов словаря — пар ключ: значение.
UPD: Важное замечание от sakutylev: Для того, чтобы объект мог быть ключом словаря, он должен быть хешируем. У кортежа, возможен случай, когда его элемент является не хешируемым объектом, и соответственно сам кортеж тогда тоже не является хешируемым и не может выступать ключом словаря.
a = (1, [2, 3], 4) print(type(a)) # b = # TypeError: unhashable type: 'list' a = <> print(type(a)) # b = print(type(b)) # c = print(type(c)) #
2 Общие подходы к работе с любой коллекцией
Разобравшись в классификацией, рассмотрим что можно делать с любой стандартной коллекцией независимо от её типа (в примерах список и словарь, но это работает и для всех остальных рассматриваемых стандартных типов коллекций):
# Зададим исходно список и словарь (скопировать перед примерами ниже): my_list = ['a', 'b', 'c', 'd', 'e', 'f'] my_dict =
2.1 Печать элементов коллекции с помощью функции print()
print(my_list) # ['a', 'b', 'c', 'd', 'e', 'f'] print(my_dict) # # Не забываем, что порядок элементов в неиндексированных коллекциях не сохраняется. 2.2 Подсчёт количества членов коллекции с помощью функции len()
print(len(my_list)) # 6 print(len(my_dict)) # 6 - для словаря пара ключ-значение считаются одним элементом. print(len('ab c')) # 4 - для строки элементом является 1 символ 2.3 Проверка принадлежности элемента данной коллекции c помощью оператора in
x in s — вернет True, если элемент входит в коллекцию s и False — если не входит
Есть и вариант проверки не принадлежности: x not in s, где есть по сути, просто добавляется отрицание перед булевым значением предыдущего выражения.
my_list = ['a', 'b', 'c', 'd', 'e', 'f'] print('a' in my_list) # True print('q' in my_list) # False print('a' not in my_list) # False print('q' not in my_list) # True Для словаря возможны варианты, понятные из кода ниже:
my_dict = print('a' in my_dict) # True - без указания метода поиск по ключам print('a' in my_dict.keys()) # True - аналогично примеру выше print('a' in my_dict.values()) # False - так как 'а' — ключ, не значение print(1 in my_dict.values()) # True Можно ли проверять пары? Можно!
print(('a',1) in my_dict.items()) # True print(('a',2) in my_dict.items()) # False Для строки можно искать не только один символ, но и подстроку:
print('ab' in 'abc') # True2.4 Обход всех элементов коллекции в цикле for in
В данном случае, в цикле будут последовательно перебираться элементы коллекции, пока не будут перебраны все из них.
for elm in my_list: print(elm) Обратите внимание на следующие моменты:
- Порядок обработки элементов для не индексированных коллекций будет не тот, как при их создании
- У прохода в цикле по словарю есть свои особенности:
for elm in my_dict: # При таком обходе словаря, перебираются только ключи # равносильно for elm in my_dict.keys() print(elm) for elm in my_dict.values(): # При желании можно пройти только по значениям print(elm)
Но чаще всего нужны пары ключ(key) — значение (value).
for key, value in my_dict.items(): # Проход по .items() возвращает кортеж (ключ, значение), # который присваивается кортежу переменных key, value print(key, value) Чтобы этого избежать подобных побочных эффектов, можно, например, итерировать копию коллекции:
for elm in list(my_list): # Теперь можете удалять и добавлять элементы в исходный список my_list, # так как итерация идет по его копии. 2.5 Функции min(), max(), sum()
- Функции min(), max() — поиск минимального и максимального элемента соответственно — работают не только для числовых, но и для строковых значений.
- sum() — суммирование всех элементов, если они все числовые.
print(min(my_list)) # a print(sum(my_dict.values())) # 21 3 Общие методы для части коллекций
Ряд методов у коллекционных типов используется в более чем одной коллекции для решения задач одного типа.
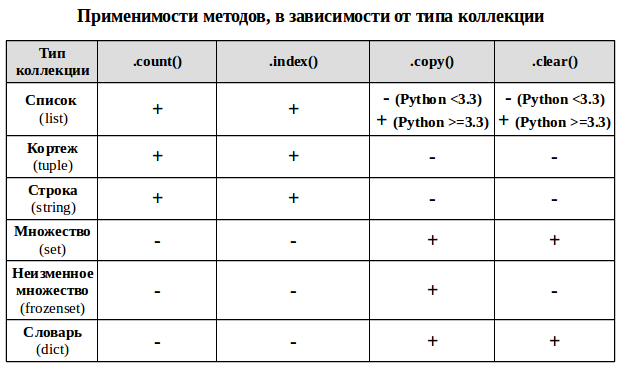
Объяснение работы методов и примеры:
-
.count() — метод подсчета определенных элементов для неуникальных коллекций (строка, список, кортеж), возвращает сколько раз элемент встречается в коллекции.
my_list = [1, 2, 2, 2, 2, 3] print(my_list.count(2)) # 4 экземпляра элемента равного 2 print(my_list.count(5)) # 0 - то есть такого элемента в коллекции нет my_list = [1, 2, 2, 2, 2, 3] print(my_list.index(2)) # первый элемент равный 2 находится по индексу 1 (индексация с нуля!) print(my_list.index(5)) # ValueError: 5 is not in list - отсутствующий элемент выдаст ошибку! my_set = my_set_2 = my_set.copy() print(my_set_2 == my_set) # True - коллекции равны - содержат одинаковые значения print(my_set_2 is my_set) # False - коллекции не идентичны - это разные объекты с разными id my_set = print(my_set) # my_set.clear() print(my_set) # set() Особые методы сравнения множеств (set, frozenset)
- set_a.isdisjoint(set_b) — истина, если set_a и set_b не имеют общих элементов.
- set_b.issubset(set_a) — если все элементы множества set_b принадлежат множеству set_a, то множество set_b целиком входит в множество set_a и является его подмножеством (set_b — подмножество)
- set_a.issuperset(set_b) — соответственно, если условие выше справедливо, то set_a — надмножество
set_a = set_b = # порядок элементов не важен! set_c = set_d = print(set_a.isdisjoint(set_c)) # True - нет общих элементов print(set_b.issubset(set_a)) # True - set_b целиком входит в set_a, значит set_b - подмножество print(set_a.issuperset(set_b)) # True - set_b целиком входит в set_a, значит set_a - надмножество При равенстве множеств они одновременно и подмножество и надмножество друг для друга
print(set_a.issuperset(set_d)) # True print(set_a.issubset(set_d)) # True 4 Конвертация одного типа коллекции в другой
В зависимости от стоящих задач, один тип коллекции можно конвертировать в другой тип коллекции. Для этого, как правило достаточно передать одну коллекцию в функцию создания другой (они есть в таблице выше).
my_tuple = ('a', 'b', 'a') my_list = list(my_tuple) my_set = set(my_tuple) # теряем индексы и дубликаты элементов! my_frozenset = frozenset(my_tuple) # теряем индексы и дубликаты элементов! print(my_list, my_set, my_frozenset) # ['a', 'b', 'a'] frozenset() Обратите внимание, что при преобразовании одной коллекции в другую возможна потеря данных:
- При преобразовании в множество теряются дублирующие элементы, так как множество содержит только уникальные элементы! Собственно, проверка на уникальность, обычно и является причиной использовать множество в задачах, где у нас есть в этом потребность.
- При конвертации индексированной коллекции в неиндексированную теряется информация о порядке элементов, а в некоторых случаев она может быть критически важной!
- После конвертации в не изменяемый тип, мы больше не сможем менять элементы коллекции — удалять, изменять, добавлять новые. Это может привести к ошибкам в наших функциях обработки данных, если они были написаны для работы с изменяемыми коллекциями.
Дополнительные детали:
-
Способом выше не получится создать словарь, так как он состоит из пар ключ: значение.
Это ограничение можно обойти, создав словарь комбинируя ключи со значениями с использованием zip():
my_keys = ('a', 'b', 'c') my_values = [1, 2] # Если количество элементов разное - # будет отработано пока хватает на пары - лишние отброшены my_dict = dict(zip(my_keys, my_values)) print(my_dict) #
my_tuple = ('a', 'b', 'c') my_str = ''.join(my_tuple) print(my_str) # abc my_list = [1, [2, 3], 4] my_set = set(my_list) # TypeError: unhashable type: 'list'- TimeComplexity (aka «Big O» or «Big Oh») (на английском)
- Complexity of Python Operations (на английском)
Приглашаю к обсуждению:
- Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
- Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
- python
- программирование
- начинающим
- коллекции
- структуры данных
- Python
- Программирование
Что такое коллекция в python
![[Коллекции] Словари (dict) в Python: описание и примеры](https://proghunter.ru/articles/https%3A%2F%2Fproghunter.ru%2Fmedia%2Fimages%2Fthumbnails%2F2023%2F03%2F24%2Fimage-455b33325c.png&w=256&q=90)
[Коллекции] Словари (dict) в Python: описание и примеры
23 марта 2023
Оценки статьи
Еще никто не оценил статью
В Python словарь (dictionary) — это неупорядоченная коллекция элементов, которые хранятся в парах ключ-значение. Ключи должны быть уникальными и неизменяемыми, а значения могут быть любыми объектами.
В этой статье мы рассмотрим, как работать со словарями в Python и основные методы работы с ними.
Создание словаря в Python
Для создания словаря в Python мы можем использовать фигурные скобки <> или конструктор dict() . Например:
# Создание пустого словаря my_dict = > print(my_dict) # Создание словаря с элементами my_dict = "apple": 1, "banana": 2, "orange": 3> print(my_dict) # Создание словаря с помощью функции dict() my_dict = dict(name="John", age=30, city="New York") print(my_dict) Доступ к элементам словаря в Python
Доступ к элементам словаря осуществляется с помощью ключа. Например:
students = 'John': 18, 'Mary': 20, 'Bob': 19> print(students['John']) # Выведется: 18 Если ключ не существует в словаре, то будет выброшено исключение KeyError .
students = 'John': 18, 'Mary': 20, 'Bob': 19> print(students['Anna']) # KeyError: 'Anna' Для избежания ошибки мы можем использовать метод get() , который вернет None, если ключ не найден в словаре:
students = 'John': 18, 'Mary': 20, 'Bob': 19> print(students.get('Anna')) # None Изменение и добавление значений словаря в Python
Мы можем изменить значение, связанное с ключом, используя квадратные скобки. Например:
students = 'John': 18, 'Mary': 20, 'Bob': 19> students['John'] = 19 print(students['John']) # Выведется: 19 Здесь мы изменяем значение, связанное с ключом John , на 19 , используя квадратные скобки.
Если мы попытаемся изменить значение, связанное с ключом, которого нет в словаре, то Python автоматически добавит новую пару ключ-значение в словарь. Например:
students = 'John': 18, 'Mary': 20, 'Bob': 19> students['Alice'] = 21 print(students) # Output: Здесь мы добавляем новую пару ключ-значение в словарь students . Ключ Alice связан со значением 21 .
Удаление пары ключ-значение из словаря в Python
Мы можем удалить пару ключ-значение из словаря, используя оператор del . Например:
students = 'John': 18, 'Mary': 20, 'Bob': 19> del students['John'] print(students) # Output: Здесь мы удаляем пару ключ-значение, связанную с ключом John , из словаря students .
Если мы попытаемся удалить ключ, которого нет в словаре, то мы получим ошибку KeyError . Например:
students = 'John': 18, 'Mary': 20, 'Bob': 19> del students['Alice'] # Raises KeyError Меню категорий
-
Загрузка категорий.
Последовательности и коллекции
В этом разделе рассказывается об обработке последовательности входных данных.
Например: найти сумму введенных чисел; сколько раз встретилась буква z в строке, как найти минимум или второй минимум в последовательности.
- что делает range(10), range(3, 10) и range(3, 10, 2);
- как в цикле for .. in перебрать все элементы из последовательности map;
- next(iter) — взять следующий элемент в последовательности
- None — значение, которое не существует.
- какие аргументы есть у функции print
- операторы break и continue. Как работают циклы for..else и while..else
results matching » «
No results matching » «
Модуль коллекций (collections)
Встроенный пакет коллекций предоставляет несколько специализированных, гибких типов коллекций, которые одновременно являются высокоэффективными и обеспечивают альтернативы общим типам коллекций dict , list , tuple и set . Модуль также определяет абстрактные базовые классы, описывающие различные типы функциональных возможностей коллекции (такие как MutableSet и ItemsView ).
Замечания
В модуле коллекций доступны еще 3 типа, а именно:
Каждый из них действует как оболочка вокруг связанного объекта, например, UserDict действует как оболочка вокруг объекта типа dict . В каждом случае класс имитирует свой именованный тип. Содержимое экземпляра хранится в объекте обычного типа, доступ к которому осуществляется через атрибут data экземпляра-оболочки. В каждом из этих трех случаев потребность в этих типах была частично вытеснена способностью к подклассу непосредственно из базового типа.
collections.ChainMap
ChainMap — новинка в версии 3.3. Возвращает новый ChainMap объект с заданным числом карт. Этот объект группирует несколько словарей или других отображений вместе, чтобы создать единое обновляемое представление.
ChainMap ’ы полезны для управления вложенными контекстами и наложениями. Пример в мире Python находится в реализации Context класса в шаблонном движке Джанго. Это полезно для быстрого связывания нескольких отображений, чтобы результат можно было рассматривать как единое целое. Это часто намного быстрее , чем создание нового словаря и запуск несколько update() вызовов.
В любое время, когда у вас имеется цепочка значений поиска, может быть случай для ChainMap . Пример включает в себя наличие заданных пользователем значений и словаря значений по умолчанию. Другим примером являются карты параметров POST и GET найденные в веб — использовании, например, Django или Flask. Благодаря использованию ChainMap можно получить комбинированный представление двух различных словарей.
Список параметров maps организуется от первого-поискового до последнего-поискового. Поисковые запросы последовательно выполняют поиск соответствующих сопоставления, пока не будет найден ключ. Напротив, операции записи, обновления и удаления действуют только при первом сопоставлении.
import collections # определите 2 словаря с перекрывающимися хотя бы несколькими ключами dict1 = dict2 = # создайте 2 ChainMap’а с разным порядком этих словарей. combined_dict = collections.ChainMap(dict1, dict2) reverse_ordered_dict = collections.ChainMap(dict2, dict1)Обратите внимание на влияние порядка, в котором значение найдено первым в последующем поиске:
for k, v in combined_dict.items(): print(k, v) >>>Out: coconut 1 date 1 apple 1 banana 2 for k, v in reverse_ordered_dict.items(): print(k, v) >>>Out: apple 3 banana 2 coconut 1collections.Counter
Счетчик является подклассом словаря , что позволяет легко считать объекты. У него есть полезные методы для работы с частотностью объектов, которые вы считаете.
import collections counts = collections.Counter([1,2,3]) Приведенный выше код создает объект count, который имеет частоты всех элементов, передаваемых в конструктор. Этот пример имеет значение Counter()
Примеры конструктора
collections.Counter('Happy Birthday') >>>Out: Counter()collections.Counter('I am Sam Sam I am That Sam-I-am That Sam-I-am! I do not like that Sam-I-am'.split()) >>>Out: Counter() Рецепты
c = collections.Counter()Получить количество отдельных элементов
c['a'] >>>Out: 4Установить количество отдельных элементов
c['c'] = -3 c >>>Out: Counter()Получить общее количество элементов в счетчике (4 + 2 + 0 — 3)
sum(c.values()) #отрицательные числа считаются! >>>Out: 3Получить элементы (сохраняются только элементы с положительным счетчиком)
list(c.elements()) >>>Out: ['a', 'a', 'a', 'a', 'b', 'b']Удалить ключи с 0 или отрицательным значением
c - collections.Counter() >>>Counter() c.clear() c >>>Out: Counter()Добавить удалить отдельные элементы
c.update() c.update() # добавление к существующему, устанавливает если не существует c >>>Out: Counter() c.subtract() # вычитание (неготивные значения разрешены) c >>>Out: Counter()collections.defaultdict
collections.defaultdict (default_factory) возвращает подкласс dict , который имеет значение по умолчанию для отсутствующих ключей. Аргумент должен быть функцией, которая возвращает значение по умолчанию при вызове без аргументов. Если нет ничего прошло, по умолчанию None .
state_capitals = collections.defaultdict(str) state_capitals >>>Out: defaultdict(str, <>)возвращает ссылку на defaultdict, который создаст строковый объект с его методом default_factory.
Типичное использование defaultdict это использовать один из встроенных типов , такие как str , int , list или dict как default_factory, так как они возвращают пустые типы при вызове без аргументов:
str() >>>Out: '' int() >>>Out: 0 list() >>>Out: [] Вызов defaultdict с ключом, который не существует, не приводит к ошибке, как в обычном словаре.
state_capitals['Alaska'] >>>Out: '' state_capitals >>>Out: defaultdict(str, )Другой пример с int :
fruit_counts = collections.defaultdict(int) fruit_counts['apple'] += 2 # No errors should occur fruit_counts >>>Out: defaultdict(int, ) fruit_counts['banana'] # No errors should occur >>>Out: 0 fruit_counts # A new key is created >>>Out: default_dict(int, ) Обычные словарные методы работают со словарем по умолчанию
>>> state_capitals['Alabama'] = 'Montgomery' >>> state_capitals defaultdict(, )
Использование list в качестве default_factory создаст список для каждого нового ключа.
>>> s = [('NC', 'Raleigh'),('VA', 'Richmond'),('WA', 'Seattle'),('NC', 'Asheville')] >>> dd = collections.defaultdict(list) >>> for k, v in s: . dd[k].append(v) >>> dd defaultdict(, )
collections.deque
Возвращает новый deque объект, который инициализируется слева направо (( используя append() ) с данными Iterable. Если итератор не указан, новый deque пуст.
Deques — это обобщение стеков и очередей (название произносится как «deck» и сокращенно означает «двусторонняя очередь»). Двусторонних очереди поддерживает потокобезопасность, память эффективно добавляет и извлекает с обеих сторон deque с приблизительно таким же O (1) производительностью в любом направлении
Хотя объекты списка поддерживают аналогичные операции, они оптимизированы для быстрых операций фиксированной длины и требуют O (n) затрат на перемещение памяти для операций pop (0) и insert (0, v), которые изменяют как размер, так и позицию базового представления данных.
Если maxlen не указаны или None , двусторонние очереди могут вырасти до произвольной длины. В противном случае, deque ограничена до заданной максимальной длины. После того, как ограниченная длина deque полна, когда добавляются новые элементы, соответствующее количество элементов, отбрасываются с противоположного конца. Запросы ограниченной длины обеспечивают функциональность, аналогичную хвостовому фильтру в Unix. Они также полезны для отслеживания транзакций и других пулов данных, где интерес представляют только самые последние действия.
from collections import deque d = deque('ghi') # создаем новый deque с 3мя элементами for elem in d: # итерируем элементы deque print elem.upper() G H I d.append('j') # добавляем новую запись в правую d.appendleft('f') # добавляем новую запись в левую часть d # показываем представление deque deque(['f', 'g', 'h', 'i', 'j']) d.pop() # возвращаем и удаляем самый правый >>>Out: 'j' d.popleft() # возвращаем и удаляем самый левый элемент >>>Out: 'f' list(d) # перечисляем содержимое deque >>>Out: ['g', 'h', 'i'] d[0] # смотрим самый левый элемент >>>Out: 'g' d[-1] # смотрим самый правый элемент >>>Out: 'i' list(reversed(d)) # перечисляем содержимое deque в # обратном порядке >>>Out: ['i', 'h', 'g'] 'h' in d # ищем deque >>>Out: True d.extend('jkl') # добавляем множественные элементы за раз d >>>Out: deque(['g', 'h', 'i', 'j', 'k', 'l']) d.rotate(1) # правый поворот d >>>Out: deque(['l', 'g', 'h', 'i', 'j', 'k']) d.rotate(-1) # левый поворот d >>>Out: deque(['g', 'h', 'i', 'j', 'k', 'l']) deque(reversed(d)) # создаем новый deque в обратном >>>Out: deque(['l', 'k', 'j', 'i', 'h', 'g']) d.clear() # опустошаем deque d.pop() # нельзя извлекать элемент из пустого # deque Traceback (most recent call last): File "", line 1, in -toplevel- d.pop() IndexError: pop from an empty deque d.extendleft('abc') # extendleft() переворачивает порядок # ввода d >>>Out: deque(['c', 'b', 'a']) collections.namedtuple
Определим нового типа Person с использованием namedtuple , как в пример ниже:
Person = namedtuple('Person', ['age', 'height', 'name']) Второй аргумент — это список атрибутов, которые будет иметь кортеж. Вы можете перечислить эти атрибуты также в виде строки, разделенной пробелами или запятыми:
Person = namedtuple('Person', 'age, height, name') Person = namedtuple('Person', 'age height name') После определения именованного кортежа можно создать экземпляр, вызвав объект с необходимыми параметрами, например:
dave = Person(30, 178, 'Dave') Именованные аргументы также могут быть использованы:
jack = Person(age=30, height=178, name='Jack S.') Теперь вы можете получить доступ к атрибутам namedtuple:
print(jack.age) >>>Out: 30 print(jack.name) >>>Out: 'Jack S.'Первый аргумент namedtuple конструктора (в нашем примере ‘Person’ ) является typename .Типично используют одно и то же слово для конструктора и имя типа, но они могут быть разными:
Human = namedtuple('Person', 'age, height, name') dave = Human(30, 178, 'Dave') print(dave) # возвращает объект класса Person >>>Out: Person(age=30, height=178, name='Dave')collections.OrderedDict
Порядок ключей в словарях Python произвольный: они не регулируются порядком их добавления.
d = print(d) >>>Out: d['baz'] = 7 print(d) >>>Out: d['foobar'] = 8 print(d) >>>Out:
(Произвольный порядок, подразумеваемый выше, означает, что вы можете получить результаты отличные от результатов показанных выше в примере)
Порядок , в котором появляются ключи — порядок , в котором они будут повторяться, например , с использованием цикла for .
collections.OrderedDict класс предоставляет объекты словаря , которые сохраняют порядок ключей. OrderedDict s могут быть созданы , как показано ниже , с серией упорядоченных элементов (здесь, список пар кортежей ключ-значение):
from collections import OrderedDict d = OrderedDict([('foo', 5),('bar', 6)]) print(d) >>>Out: OrderedDict([('foo', 5),('bar', 6)]) d['baz'] = 7 print(d) >>>Out: OrderedDict([('foo', 5),('bar', 6),('baz', 7)]) d['foobar'] = 8 print(d) >>>Out: OrderedDict([('foo', 5),('bar', 6),('baz', 7),('foobar', 8)]) Или мы можем создать пустой OrderedDict , а затем добавить элементы:
o = OrderedDict() o['key1'] = "value1" o['key2'] = "value2" print(o) >>>Out: OrderedDict([('key1', 'value1'),('key2', 'value2')])Итерация через OrderedDict позволяет доступ к ключам в порядке их добавления.
Что произойдет, если мы присвоим новое значение существующему ключу?
d['foo'] = 4 print(d) >>>Out: OrderedDict([('foo', 4),('bar', 6),('baz', 7),('foobar', 8)])Ключ сохраняет свое первоначальное место в OrderedDict .