Краткое руководство по созданию запросов к базе данных с помощью Python
При работе с этим кратким руководством вы будете использовать Python для подключения к Базе данных SQL Azure, Управляемому экземпляру SQL Azure или базе данных Synapse SQL, а затем выполните запрос данных с помощью инструкций T-SQL.
Необходимые компоненты
Для работы с этим кратким руководством вам понадобится:
Для дальнейшего изучения Python и базы данных в службе «Базы данных SQL Azure» см. Библиотеки Базы данных SQL Azure для Python, репозитория репозиторий pyodbc и выборку pyodbc.
Создание кода для запроса базы данных
- Создайте файл sqltest.py в текстовом редакторе.
- Добавьте следующий код. Получите сведения о подключении из раздела о предварительных требованиях и замените параметры , , и собственными значениями.
import pyodbc server = '.database.windows.net' database = '' username = '' password = '>' driver= '' with pyodbc.connect('DRIVER='+driver+';SERVER=tcp:'+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password) as conn: with conn.cursor() as cursor: cursor.execute("SELECT TOP 3 name, collation_name FROM sys.databases") row = cursor.fetchone() while row: print (str(row[0]) + " " + str(row[1])) row = cursor.fetchone() Выполнение кода
- В командной строке выполните следующую команду:
python sqltest.py - Убедитесь, что имя сервера, имя базы данных, имя пользователя и пароль, который вы используете, правильны.
- Убедитесь, что установленный драйвер ODBC является той же версией, что driver и переменная в приведенном выше коде. Например, в коде отображается 17, но может быть установлена другая версия.
- Если вы запускаете код из локальной среды, убедитесь, что брандмауэр ресурса Azure, к которому вы пытаетесь получить доступ, настроен для разрешения доступа с IP-адреса вашей среды.
Следующие шаги
- Руководство по разработке первой базы данных в службе «База данных SQL Azure»
- Сведения о драйверах Microsoft Python для SQL Server
- Центр по разработке на Python
Как создать таблицы базы данных в Python со встроенной СУБД
Продолжим работать с базами данных со встроенной Python-библиотекой — sqlite3, которая предоставляет интерфейс SQLite. На практическом примере расскажем о создании таблиц, построим отношение один-ко-многим и покажем результаты в SQL-клиенте — DBeaver.
Интерфейс SQLite в Python
В прошлой статье мы разобрались с интерфейсом sqlite3, а именно:
- как устанавливать соединение с базой данных,
- как совершать транзакции, используя контекстный менеджер with,
- как инициализировать объект Cursor, полезный для получения данных,
- как писать безопасные запросы, используя ? или :value .
Теперь можем приступить к созданию таблиц.
Создаем таблицу user
Для выполнения запросов используется метод execute . Пусть будет таблица User с тремя атрибутами: id, имя, возраст. Код в Python для создания таблицы будет выглядеть так:
import sqlite3 con = sqlite3.connect("test.db") cur = con.cursor() with con: cur.execute(""" CREATE TABLE user ( id INT NOT NULL PRIMARY KEY, name TEXT, age INTEGER ); """)
Типов данных в SQLite всего 5: NULL, INT, REAL, TEXT, BLOB. Последний тип данных — это Binary Large OBjects, т.е. бинарные объекты (документы, рисунки, аудио).
Добавляем данные
Добавить можно как одну запись, так и список записей. Во втором случае используется executemany . Выполним два запроса в Python:
query = 'INSERT INTO USER (id, name, age) values(?, ?, ?)' data = [ (2, 'Vova', 25), (3, 'Anna', 21), (4, 'Kolya', 19) ] with con: cur.executemany(query, data)
data = (1, "Sasha", 32) with con: cur.execute("INSERT INTO user (id, name, age) values(?, ?, ?)", data)
Выводим данные пользователей
Используя метод fetchall объекта Cursor , можно получить все записи, например:
cur.execute("SELECT * FROM user WHERE age
В то время как метод fetchone выдаст только первую:
cur.execute("SELECT * FROM USER WHERE age
Отношение один-ко-многим
Воспроизведем отношение один-ко-многим. Допустим, каждый пользователь знает несколько иностранных языков. Для этого нам понадобятся еще две таблицы: таблица с языками и таблица, которая связывает id пользователя и id языка.
Таблица языков с Python-кодом будет выглядеть так:
with con: cur.execute(""" CREATE TABLE language ( id INT NOT NULL PRIMARY KEY, name TEXT ); """)
Таблица, которая связывает id пользователя и id языка, должна иметь внешние ключи этих id, которые вместе образуют первичный ключ. В итоге, это выглядит так:
with con: cur.execute(""" CREATE TABLE user_language ( user_id INT, language_id INT, PRIMARY KEY(user_id, language_id), FOREIGN KEY(user_id) REFERENCES user(id), FOREIGN KEY(language_id) REFERENCES language(id) ); """)
Добавляем данные языков
Добавим несколько языков в таблицу Language. Запрос в Python:
data = [ (1, "english"), (2, "spanish"), (3, "french") ] with con: cur.executemany("INSERT INTO language VALUES(?, ?)", data)
Теперь обозначим пользователей, которые знают иностранные языки:
data = [ (1, 2), # Саша знает испанский (2, 1), # Вова знает английский (2, 2), # Вова еще знает испанский (3, 3), # Анна знает французский ] with con: cur.executemany("INSERT INTO user_language VALUES(?, ?)", data)
Выводим данные пользователей, знающих иностранные языки
Выведем пользователей и языки, которые они знают. Нам нужно только записать условие совпадения идентификаторов. В Python запрос выглядит следующим образом:
cur.execute(""" SELECT user.name, language.name FROM user, language, user_language WHERE (user.id = user_language.user_id AND language.id = user_language.language_id) """).fetchall()
На выходе получили:
[('Sasha', 'spanish'), ('Vova', 'english'), ('Vova', 'spanish'), ('Anna', 'french')]
После работы с базой данных следует закрыть соединение:
con.close()
SQL-клиент DBeaver для просмотра результатов
Можно получить доступ к базам данных с помощью SQL-клиента, например, свободного и открытого DBeaver. Запустив DBeaver, необходимо установить соединение с базой данных во вкладке Базы данных (Database), как это показано на рисунке ниже. После этого указать тип БД и путь к ней.
В DBeaver также можно писать запросы. Кроме этого, мы можем посмотреть на ER-диаграмму созданных таблиц в соответствующей вкладке. На рисунке ниже это проиллюстрировано.
Использованный код доступен в репозитории на Github. В следующей статье поговорим о интеграции SQLite с Python-библиотекой Pandas. А о том, как работать с данными в Python на проектах Data Science, вы узнаете на курсах в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Лучшие библиотеки Python для создания баз данных SQL

Многие программы взаимодействуют с данными с помощью систем управления базами данных (СУБД). В одних языках программирования предусмотрены встроенные модули для работы с СУБД, другие же требуют использования библиотек, предоставляемых сторонними пакетами.
В этой статье рассмотрены различные SQL-библиотеки Python, а также процесс создания простого приложения для работы с базами данных SQLite, MySQL и PostgreSQL.
Благодаря этому руководству можно научиться:
- Подключаться к различным СУБД с помощью SQL-библиотек Python.
- Работать с базами SQLite, MySQL и PostgreSQL.
- Выполнять из приложения Python типичные запросы к базам данных.
- Разрабатывать приложения для различных баз данных, используя скрипты Python.
Для получения максимальной пользы от руководства нужно знать основы Python, SQL и работы с СУБД. Вы должны уметь скачивать и импортировать пакеты в Python. Знать, как устанавливать и запускать разные серверы баз данных, локально или удалённо.
Логическая структура базы данных
В этом руководстве мы создадим небольшую базу данных для приложения социальной сети. База будет состоять из четырёх таблиц:
Логическая структура нашей базы данных показана ниже:
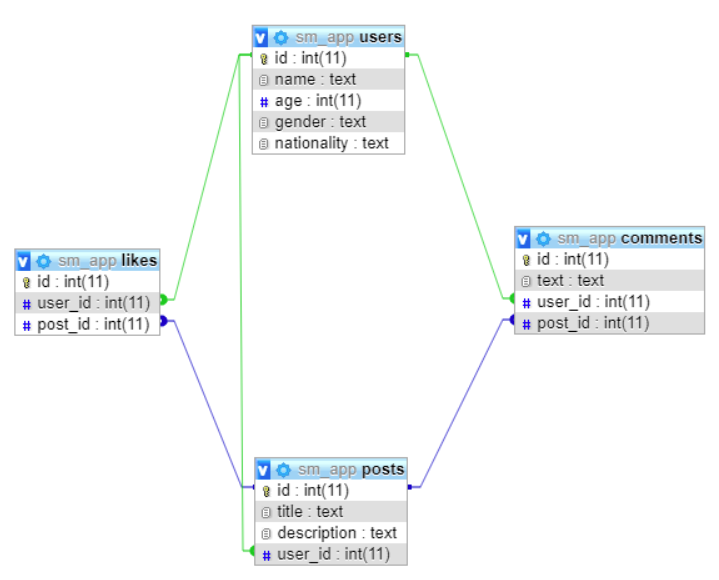
У таблиц «users» и «posts» будут связи типа «один ко многим», поскольку один пользователь может поставить лайк нескольким постам. Точно так же один пользователь может оставить много комментариев или сделано много комментариев к одной и той же публикации.
Поэтому таблицы «users» и «posts» имеют связь типа «один ко многим» с таблицей «comments». То же самое с таблицей «likes» — таблицы «users» и «posts» будут иметь связь типа «один ко многим» и с ней.
Подключение к базам данных с помощью SQL-библиотек Python
Прежде чем работать с любой базой при помощи SQL-библиотек Python, к ней необходимо подключиться. В этом разделе вы увидите, как подключиться к PostgreSQL, SQLite и MySQL из приложения Python.
Примечание. Для выполнения скриптов из подразделов MySQL и PostgreSQL вам понадобятся их запущенные серверы.
Рекомендуется создать для каждой из трёх СУБД по отдельному файлу Python. Так вы сможете запускать скрипт для каждой базы из нужного файла.
SQLite

SQLite — это, пожалуй, самая простая база данных SQL для Python, поскольку не требует установки внешних SQL модулей. По умолчанию в установленной системе Python уже есть SQL библиотека «sqlite3», которая позволяет подключаться к базе SQLite.
Более того, базы SQLite не нуждаются в сервере и самодостаточны, поскольку просто считывают и записывают данные в файл. В отличие от MySQL и PostgreSQL, для выполнения операций с базами данных даже не нужно устанавливать и запускать серверное приложение.
Подключение к базе SQLite в Python с помощью «sqlite3» происходит следующим образом:
1 import sqlite3 2 from sqlite3 import Error 3 4 def create_connection(path): 5 connection = None 6 try: 7 connection = sqlite3.connect(path) 8 print("Подключение к базе данных SQLite прошло успешно") 9 except Error as e: 10 print(f"Произошла ошибка ''") 11 12 return connection
Как работает этот код:
- Строки 1 и 2 импортируют библиотеку «sqlite3» и класс «Error» этого модуля.
- Строка 4 определяет функцию «.create_connection()», которая принимает в качестве входного параметра путь к базе данных SQLite (path).
- В строке 7 используется функция «.connect()» из модуля «sqlite3», которой передаётся этот путь. Если база данных находится в указанном месте, с ней устанавливается соединение. В противном случае там создаётся новая база и подключение осуществляется уже к ней.
- Строка 8 выводит статус успешного подключения к базе.
- Строка 9 перехватывает исключение, которое может возникнуть, если по методу «.connect()» подключиться к базе SQL не удалось.
- Строка 10 выводит на терминал сообщение об ошибке.
Метод «sqlite3.connect(path)» возвращает объект «(connection)». Его же, в свою очередь, возвращает и наша функция «create_connection()».
Объект «connection» можно использовать для выполнения запросов к базе SQLite. Следующий скрипт устанавливает подключение к SQLite:
connection = create_connection("E:\\sm_app.sqlite")
Когда вы запустите скрипт базы данных SQL, то увидите, что в корневом каталоге создан файл базы данных «sm_app.sqlite». Путь к файлу можно изменить.
MySQL

В отличие от SQLite, в Python нет встроенного модуля для подключения к базам MySQL. Чтобы подключиться к базе MySQL из Python, нужно установить подходящий SQL-драйвер. Один из таких — «mysql-connector-python».
Скачать этот SQL модуль можно с помощью менеджера пакетов «pip»:
$ pip install mysql-connector-python
Учтите, что MySQL — серверная СУБД. Поэтому на одном сервере может быть много баз. В отличие от SQLite, где подключение к базе равносильно её созданию, в MySQL для создания базы нужны два шага:
- Подключение к серверу MySQL.
- Выполнение запроса на создание базы данных SQL.
Подключение к серверу MySQL
Определим функцию, которая подключается к серверу MySQL и возвращает объект «connection»:
1 import mysql.connector 2 from mysql.connector import Error 3 4 def create_connection(host_name, user_name, user_password): 5 connection = None 6 try: 7 connection = mysql.connector.connect( 8 host=host_name, 9 user=user_name, 10 passwd=user_password 11 ) 12 print("Подключение к базе данных MySQL прошло успешно") 13 except Error as e: 14 print(f"Произошла ошибка ''") 15 16 return connection 17 18 connection = create_connection("localhost", "root", "")
В приведенном выше скрипте определяется функция «create_connection()». Она принимает три параметра:
- host_name (имя сервера)
- user_name (имя пользователя)
- user_password (пароль пользователя)
В строке 7 для подключения к серверу MySQL используется метод «.connect()» из модуля «mysql.connector». После установки соединения объект «connection» возвращается вызывающей функции.
Наконец, в строке 18 вызывается функция «create_connection()». Её аргументами служат имя сервера, пользователь и пароль.
Выполнение запроса на создание базы данных
Пока мы только установили подключение MySQL к Python, но база данных ещё не создана. Чтобы это сделать, мы определим ещё функцию «create_database()». Она будет принимать два параметра:
- connection — объект подключения к серверу баз данных.
- query — запрос, который создаёт новую базу.
Функция выглядит так:
def create_database(connection, query): cursor = connection.cursor() try: cursor.execute(query) print("База данных создана успешно") except Error as e: print(f"Произошла ошибка ''")
Для выполнения SQL запросов используется объект «cursor». Запрос «query» передаётся методу «cursor.execute()» в формате строки.
Создадим на сервере MySQL базу данных под названием «sm_app» для нашего приложения соцсети:
create_database_query = "CREATE DATABASE sm_app" create_database(connection, create_database_query)
Теперь на сервере баз данных создана база «sm_app». Однако, объект «connection», возвращённый функцией «create_connection()», всё ещё указывает на сам сервер баз данных MySQL. А нам нужно подключиться к базе «sm_app». Чтобы сделать это, изменим функцию «create_connection()» так:
1 def create_connection(host_name, user_name, user_password, db_name): 2 connection = None 3 try: 4 connection = mysql.connector.connect( 5 host=host_name, 6 user=user_name, 7 passwd=user_password, 8 database=db_name 9 ) 10 print("Подключение к базе данных MySQL прошло успешно") 11 except Error as e: 12 print(f"Произошла ошибка ''") 13 14 return connection
Как видно из приведенного кода, на строке 8 теперь функция «create_connection()» принимает дополнительный параметр «db_name». Он указывает имя базы данных для подключения. Теперь имя базы, к которой вы хотите подключиться, можно передать при вызове функции:
connection = create_connection("localhost", "root", "", "sm_app")
Этот скрипт успешно вызывает функцию «create_connection()» и подключается к базе «sm_app».
PostgreSQL

Как и в случае с MySQL, в PostgreSQL нет встроенной в Python SQL библиотеки. Для подключения к PostgreSQL из Python можно использовать сторонний драйвер баз данных. Примером может послужить модуль «psycopg2».
Для установки в Python SQL-модуля «psycopg2» выполним в терминале следующую команду:
$ pip install psycopg2
Как и в случае с MySQL и SQLite, для подключения к базе PostgreSQL определим функцию «create_connection()»:
import psycopg2 from psycopg2 import OperationalError def create_connection(db_name, db_user, db_password, db_host, db_port): connection = None try: connection = psycopg2.connect( database=db_name, user=db_user, password=db_password, host=db_host, port=db_port, ) print("Подключение к базе данных PostgreSQL прошло успешно") except OperationalError as e: print(f"Произошла ошибка ''") return connection
Для подключения из нашего приложения Python к серверу PostgreSQL используется метод «psycopg2.connect()».
После этого для подключения к самой базе можно использовать функцию «create_connection()». Сперва подключимся к «postgres», базе по умолчанию:
connection = create_connection( "postgres", "postgres", "abc123", "127.0.0.1", "5432" )
Затем нужно создать внутри базы «postgres» уже нашу базу «sm_app». Можно определить функции для выполнения в PostgreSQL любых SQL-запросов. Ниже определим функцию «create_database()», которая создаст новую базу данных на сервере PostgreSQL.
def create_database(connection, query): connection.autocommit = True cursor = connection.cursor() try: cursor.execute(query) print("Запрос выполнен успешно") except OperationalError as e: print(f"Произошла ошибка ''") create_database_query = "CREATE DATABASE sm_app" create_database(connection, create_database_query)
После запуска скрипта мы увидим, что на сервере PostgreSQL создана база «sm_app».
Прежде чем выполнять SQL запросы к базе «sm_app», к ней нужно подключиться:
connection = create_connection( "sm_app", "postgres", "abc123", "127.0.0.1", "5432" )
При выполнении скрипта установится соединение с базой «sm_app» на сервере баз данных «postgres». Параметр «127.0.0.1» задаёт IP-адрес сервера баз данных, а «5432» — это номер порта сервера баз данных.
Создание таблиц
В предыдущем разделе вы узнали, как подключиться к базам данных SQLite, MySQL и PostgreSQL, используя SQL-библиотеки Python. На всех трёх СУБД мы создали базу «sm_app». В этом разделе расскажем, как создать таблицы баз данных SQL внутри этих трёх баз.
Как уже говорилось, мы будем создавать четыре таблицы:
SQLite
Для выполнения запросов в SQLite используется метод «cursor.execute()». В этом разделе мы определим для его использования функцию «execute_query()». Она будет принимать объект «connection» и строку запроса. Эти аргументы она передаст методу «cursor.execute()».
Метод «.execute()» может выполнять любой запрос, переданный в форме строки. В этом разделе мы используем его для создания таблиц. В остальных разделах также прибегнем к нему уже для выполнения запросов на обновление или удаление.
Примечание. Этот фрагмент кода должен выполняться из того же файла, в котором создаётся подключение к нашей базе SQLite .
Вот определение функции:
def execute_query(connection, query): cursor = connection.cursor() try: cursor.execute(query) connection.commit() print("Запрос выполнен успешно") except Error as e: print(f"Произошла ошибка ''")
Этот код пытается выполнить запрос «query», при необходимости выводя сообщение об ошибке.
Теперь напишем наш запрос «query»:
create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, age INTEGER, gender TEXT, nationality TEXT ); """
Это позволяет создать таблицу «users» с пятью столбцами:
Наконец, для создания этой таблицы выполняем «execute_query()». Мы передаём созданный в предыдущем сеансе объект «connection» вместе со строкой «create_users_table», которая содержит запрос на создание таблицы.
execute_query(connection, create_users_table)
Следующий запрос создаст таблицу «posts»:
create_posts_table = """ CREATE TABLE IF NOT EXISTS posts( id INTEGER PRIMARY KEY AUTOINCREMENT, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) ); """
Как уже говорилось, таблицы «users» и «posts» связаны по типу «один ко многим». Поэтому в таблице «posts» есть внешний ключ «user_id», отсылающий к столбцу «id» таблицы «users». Выполним скрипт для создания таблицы «posts»:
execute_query(connection, create_posts_table)
Наконец, таблицы «comments» и «likes» можно создать таким скриптом:
create_comments_table = """ CREATE TABLE IF NOT EXISTS comments ( id INTEGER PRIMARY KEY AUTOINCREMENT, text TEXT NOT NULL, user_id INTEGER NOT NULL, post_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id) ); """ create_likes_table = """ CREATE TABLE IF NOT EXISTS likes ( id INTEGER PRIMARY KEY AUTOINCREMENT, user_id INTEGER NOT NULL, post_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id) ); """ execute_query(connection, create_comments_table) execute_query(connection, create_likes_table)
Как видно из примера, создание таблиц в SQLite очень похоже на использование языка SQL напрямую. Нужно лишь поместить запрос в строковую переменную и передать её методу «cursor.execute()».
MySQL
Для создания таблиц в MySQL воспользуемся драйвером «mysql-connector-python». Точно так же, как и с SQLite, нам нужно передать методу «cursor.execute()» запрос, который возвращается функцией «.cursor()» по объекту «connection».
Мы можем создать свою функцию «execute_query()». Её аргументами также будут объект подключения «connection» и строка запроса «query»:
1 def execute_query(connection, query): 2 cursor = connection.cursor() 3 try: 4 cursor.execute(query) 5 connection.commit() 6 print("Запрос выполнен успешно") 7 except Error as e: 8 print(f"Произошла ошибка ''")
На строке 4 запрос «query» передаётся методу «cursor.execute()».
Теперь с помощью этой функции можно создать таблицу «users»:
create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id INT AUTO_INCREMENT, name TEXT NOT NULL, age INT, gender TEXT, nationality TEXT, PRIMARY KEY (id) ) ENGINE = InnoDB """ execute_query(connection, create_users_table)
По сравнению с SQLite, запрос на создание отношения по внешнему ключу для MySQL немного отличается. Кроме того, для создания столбцов, значение которых при добавлении новых записей автоматически возрастает на единицу, MySQL использует ключевое слово «AUTO_INCREMENT», а не «AUTOINCREMENT», как SQLite.
Этот скрипт создаёт таблицу «posts» с внешним ключом «user_id», связанным со столбцом «id» таблицы «users»:
create_posts_table = """ CREATE TABLE IF NOT EXISTS posts ( id INT AUTO_INCREMENT, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER NOT NULL, FOREIGN KEY fk_user_id (user_id) REFERENCES users(id), PRIMARY KEY (id) ) ENGINE = InnoDB """ execute_query(connection, create_posts_table)
Аналогично можно создать таблицы «comments» и «likes», передав методу «execute_query()» запросы «CREATE».
PostgreSQL
Как и в случае с MySQL и SQLite, возвращаемый функцией «psycopg2.connect()» объект «connection» содержит в себе объект «cursor». Для выполнения SQL-запросов к базам данных PostgreSQL в Python воспользуемся методом «cursor.execute()».
Определим функцию «execute_query()»:
def execute_query(connection, query): connection.autocommit = True cursor = connection.cursor() try: cursor.execute(query) print("Запрос выполнен успешно") except OperationalError as e: print(f"Произошла ошибка ''")
С помощью этой функции в базе PostgreSQL можно создавать таблицы, а также добавлять, изменять и удалять записи.
Теперь создадим внутри базы «sm_app» таблицу «users»:
create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id SERIAL PRIMARY KEY, name TEXT NOT NULL, age INTEGER, gender TEXT, nationality TEXT ) """ execute_query(connection, create_users_table)
Как видно, в PostgreSQL запрос на создание таблицы «users» немного отличается от аналогичных для SQLite и MySQL. Здесь для автоинкремента столбца используется ключевое слово «SERIAL». Вспомним, что в MySQL использовалось «AUTO_INCREMENT».
Связь по внешнему ключу также задаётся иначе, что видно по скрипту, создающему таблицу «posts»:
create_posts_table = """ CREATE TABLE IF NOT EXISTS posts ( id SERIAL PRIMARY KEY, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER REFERENCES users(id) ) """ execute_query(connection, create_posts_table)
Для создания таблицы «comments» нужно написать для неё запрос «CREATE» и передать функции «execute_query()». Процесс создания для таблицы «likes» тот же. Нужно лишь изменить запрос «CREATE» так, чтобы вместо таблицы «comments» создалась «likes».
Добавление записей
В предыдущем разделе вы узнали, как создавать таблицы в базах SQLite, MySQL и PostgreSQL с помощью разных модулей Python. В этом разделе вы узнаете, как добавлять данные в ваши таблицы.
SQLite
Чтобы добавить записи в нашу базу SQLite, можно использовать ту же функцию «execute_query()», что мы использовали для создания таблиц. Сперва нужно задать строку с запросом «INSERT INTO». Затем можно передать объект «connection» и строковой запрос «query» на вход функции «execute_query()».
Внесём в таблицу «users» пять записей:
create_users = """ INSERT INTO users (name, age, gender, nationality) VALUES ('Джеймс', 25, 'мужской', 'США'), ('Лейла', 32, 'женский', 'Франция'), ('Бриджит', 35, 'женский', 'Англия'), ('Майк', 40, 'мужской', 'Дания'), ('Элизабет', 21, 'женский', 'Канада'); """ execute_query(connection, create_users)
Так как мы задали для столбца «id» автоинкремент, указывать его значение для таблицы «users» незачем. Она сама заполнит значения «id» для этих пяти записей числами от 1 до 5.
Теперь внесём шесть записей в таблицу «posts»:
create_posts = """ INSERT INTO posts (title, description, user_id) VALUES ("Счастлив", "Сегодня я очень счастлив", 1), ("Жара", "Погода сегодня очень жаркая", 2), ("Помогите", "Мне надо немного помочь с работой", 2), ("Отличная новость", "Я женюсь", 1), ("Интересная игра", "Это был потрясающий теннисный матч", 5), ("Вечеринка", "Кто готов сегодня ночью тусить?", 3); """ execute_query(connection, create_posts)
Важно отметить, что столбец «user_id» таблицы «posts» связан по внешнему ключу со столбцом «id» таблицы «users». Это означает, что столбец «user_id» должен содержать значение, которое уже есть в столбце «id» таблицы «users». Если такового нет, вы получите ошибку.
Аналогично внесёт записи в таблицы «comments» и «likes» такой скрипт:
create_comments = """ INSERT INTO comments (text, user_id, post_id) VALUES ('Я с вами', 1, 6), ('А с чем помочь?', 5, 3), ('Поздравляю, чувак', 2, 4), ('А я за Надаля болел', 4, 5), ('Помочь тебе с дипломом?', 2, 3), ('Мои поздравления', 5, 4); """ create_likes = """ INSERT INTO likes (user_id, post_id) VALUES (1, 6), (2, 3), (1, 5), (5, 4), (2, 4), (4, 2), (3, 6); """ execute_query(connection, create_comments) execute_query(connection, create_likes)
В обоих случаях вы задаёте запрос «INSERT INTO» в виде строки и выполняете его с помощью функции «execute_query()».
MySQL
Есть два способа добавлять записи в базы MySQL из Python-приложения. Первый подход аналогичен действиям с SQLite. Можно создать строку-запрос «INSERT INTO», а затем для добавления записей в таблицу SQL вызвать функцию «cursor.execute()».
Ранее мы уже определили функцию-обёртку «execute_query()», с помощью которой добавляли записи. Ту же самую функцию можно использовать для внесения записей в таблицу MySQL. Следующий скрипт вносит записи в таблицу «users» с помощью функции «execute_query()»:
create_users = """ INSERT INTO `users` (`name`, `age`, `gender`, `nationality`) VALUES ('Джеймс', 25, 'мужской', 'США'), ('Лейла', 32, 'женский', 'Франция'), ('Бриджит', 35, 'женский', 'Англия'), ('Майк', 40, 'мужской', 'Дания'), ('Элизабет', 21, 'женский', 'Канада'); """ execute_query(connection, create_users)
Второй подход использует метод «cursor.executemany()», принимающий два входных параметра:
- Строку запроса, которая содержит заполнители для вносимых записей.
- Список записей для добавления.
Посмотрим на случай, в котором в таблицу «likes» вносят две записи:
sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )" val = [(4, 5), (3, 4)] cursor = connection.cursor() cursor.executemany(sql, val) connection.commit()
Для внесения записей в таблицу MySQL можно использовать любой подход. Если вы хорошо разбираетесь в SQL, можете использовать метод «.execute()».
Если вы мало с ним знакомы, проще будет обратиться к методу «.executemany()». Успешно добавить записи в таблицы «posts», «comments» и «likes» позволят оба подхода.
PostgreSQL
В предыдущем разделе мы рассмотрели два подхода, которые позволяют добавлять записи в таблицы базы MySQL. Первый использует строку с SQL-запросом, а второй — метод «.executemany()».
Модуль «psycopg2» следует второму подходу c использованием заполнителей «%s», хотя его метод и назван просто «.execute()». Поэтому мы передаём этому методу SQL запрос на добавление записей с заполнителями и список записей.
Каждая запись в списке представляет собой кортеж, значения которого соотносятся со столбцами в таблице базы. Добавить пользователей в таблицу «users» базы PostgreSQL можно так:
users = [ ("Джеймс", 25, "мужской", "США"), ("Лейла", 32, "женский", "Франция"), ("Бриджит", 35, "женский", "Англия"), ("Майк", 40, "мужской", "Дания"), ("Элизабет", 21, "женский", "Канада"), ] user_records = ", ".join(["%s"] * len(users)) insert_query = ( f"INSERT INTO users (name, age, gender, nationality) VALUES " ) connection.autocommit = True cursor = connection.cursor() cursor.execute(insert_query, users)
Этот скрипт создаёт список «users», который содержит пять пользовательских записей в формате кортежа. Теперь для пяти пользовательских записей создадим строку с пятью заполнителями «%s». Строка с заполнителями связана с запросом, который добавляет записи в таблицу «users». Наконец, пользовательские записи и строка с запросом передаются методу «.execute()». Скрипт успешно добавляет пять записей в таблицу users.
Посмотрим на ещё один пример добавления записей в таблицу PostgreSQL. Этот скрипт вносит записи в таблицу «posts»:
posts = [ ("Счастлив", "Сегодня я очень счастлив", 1), ("Жара", "Погода сегодня очень жаркая", 2), ("Помогите", "Мне надо немного помочь с работой", 2), ("Отличная новость", "Я женюсь", 1), ("Интересная игра", "Это был потрясающий теннисный матч", 5), ("Вечеринка", "Кто готов сегодня ночью тусить?", 3), ] post_records = ", ".join(["%s"] * len(posts)) insert_query = ( f"INSERT INTO posts (title, description, user_id) VALUES " ) connection.autocommit = True cursor = connection.cursor() cursor.execute(insert_query, posts)
Добавить записи в таблицы «comments» и «likes» можно точно так же.
Выборка записей
В этом разделе вы узнаете, как делать из таблиц выборки записей с помощью SQL модулей Python. В частности, выполнять запросы «SELECT» для наших баз SQLite, MySQL и PostgreSQL.
SQLite
Чтобы получить выборку записей из SQLite, можно снова обратиться к функции «cursor.execute()». Однако после этого понадобится ещё вызов метода «.fetchall()». Он возвращает полученные записи в виде списка кортежей, каждый из которых соответствует определенной строке таблицы.
Процесс можно упростить, создав функцию «execute_read_query()»:
def execute_read_query(connection, query): cursor = connection.cursor() result = None try: cursor.execute(query) result = cursor.fetchall() return result except Error as e: print(f"Произошла ошибка ''")
Эта функция принимает объект «connection» и запрос «SELECT», возвращая выбранную запись.
SELECT
Сделаем выборку всех записей таблицы «users».
select_users = "SELECT * from users" users = execute_read_query(connection, select_users) for user in users: print(user)
В этом скрипте запрос «SELECT» выбирает всех пользователей из таблицы «users». Он передаётся функции «execute_read_query()», которая возвращает все записи из таблицы «users». После получения записей они выводятся на терминал.
Примечание. Использование запроса «SELECT *» не рекомендуется для больших таблиц. Это может привести к большому числу операций ввода-вывода и увеличить объём передаваемого сетевого трафика.
Результат запроса выглядит примерно так:
(1, 'Джеймс, 25, 'мужской', 'США') (2, 'Лейла', 32, 'женский', 'Франция') (3, 'Бриджит', 35, 'женский', 'Англия') (4, 'Майк', 40, 'мужской', 'Дания') (5, 'Элизабет', 21, 'женский', 'Канада')
Точно так же можно извлечь все записи из таблицы «posts»:
select_posts = "SELECT * FROM posts" posts = execute_read_query(connection, select_posts) for post in posts: print(post)
Результат выглядит примерно так:
(1, 'Счастлив', 'Сегодня я очень счастлив', 1) (2, 'Жара', 'Погода сегодня очень жаркая', 2) (3, 'Помогите', 'Мне надо немного помочь с работой', 2) (4, 'Отличная новость', 'Я женюсь', 1) (5, 'Интересная игра', 'Это был потрясающий теннисный матч', 5) (6, 'Вечеринка', 'Кто готов сегодня ночью тусить?', 3)
Здесь показаны все записи таблицы «posts».
JOIN
Извлекать данные из двух связанных таблиц можно также при помощи комплексных запросов с оператором «JOIN». Например такой скрипт вернёт идентификаторы и имена пользователей, связав это с описаниями публикаций:
select_users_posts = """ SELECT users.id, users.name, posts.description FROM posts INNER JOIN users ON users.id = posts.user_id """ users_posts = execute_read_query(connection, select_users_posts) for users_post in users_posts: print(users_post)
(1, 'Джеймс', 'Сегодня я очень счастлив') (2, 'Лейла', 'Погода сегодня очень жаркая') (2, 'Лейла', 'Мне надо немного помочь с работой') (1, 'Джеймс', 'Я женюсь') (5, 'Элизабет', 'Это был потрясающий теннисный матч') (3, 'Бриджит', 'Кто готов сегодня ночью тусить?')
Используя несколько операторов «JOIN» можно сделать выборку сразу из трёх таблиц. Этот скрипт выводит все публикации с комментариями под ними и имена оставивших их пользователей:
select_posts_comments_users = """ SELECT posts.description as post, text as comment, name FROM posts INNER JOIN comments ON posts.id = comments.post_id INNER JOIN users ON users.id = comments.user_id """ posts_comments_users = execute_read_query( connection, select_posts_comments_users ) for posts_comments_user in posts_comments_users: print(posts_comments_user)
Результат выглядит примерно так:
('Кто готов сегодня ночью тусить?', 'Я с вами, 'Джеймс') ('Мне надо немного помочь с работой', 'А с чем помочь?', 'Элизабет') ('Я женюсь', 'Поздравляю, приятель', 'Лейла') ('Это был потрясающий теннисный матч', 'А я за Надаля болел', 'Майк') ('Мне надо немного помочь с работой', 'Помочь тебе с дипломом?', ''Бриджит') ('Я женюсь', 'Мои поздравления', 'Элизабет')
Как видно, метод «.fetchall()» не возвращает названия столбцов. Чтобы их получить, можно использовать атрибут «.description» объекта «cursor». Например следующий список возвращает все имена столбцов из предыдущего запроса:
cursor = connection.cursor() cursor.execute(select_posts_comments_users) cursor.fetchall() column_names = [description[0] for description in cursor.description] print(column_names) Результат выглядит примерно так: Командная строка ['post', 'comment', 'name']
Здесь содержатся имена столбцов для данного запроса.
WHERE
Теперь выполним запрос «SELECT», который возвращает публикации вместе с числом набранных лайков:
select_post_likes = """ SELECT description as Post, COUNT(likes.id) as Likes FROM likes, posts WHERE posts.id = likes.post_id GROUP BY likes.post_id """ post_likes = execute_read_query(connection, select_post_likes) for post_like in post_likes: print(post_like)
('Погода сегодня очень жаркая', 1) ('Мне надо немного помочь с работой', 1) ('Я женюсь', 2) ('Это был потрясающий теннисный матч', 1) ('Кто готов сегодня ночью тусить?', 2)
Так, с помощью оператора «WHERE» можно получить более конкретные результаты.
MySQL
Выборка записей из MySQL происходит точно так же, как и из SQLite. Можно воспользоваться методом «cursor.execute()», а затем «.fetchall()». Этот скрипт создаёт функцию-обёртку «execute_read_query()», которая позволяет делать выборки записей:
def execute_read_query(connection, query): cursor = connection.cursor() result = None try: cursor.execute(query) result = cursor.fetchall() return result except Error as e: print(f"Произошла ошибка ''")
Сделаем выборку всех записей из таблицы «users»:
select_users = "SELECT * from users" users = execute_read_query(connection, select_users) for user in users: print(user)
Результат выполнения похож на то, что мы видели у SQLite.
PostgreSQL
Процесс выборки записей из таблиц PostgreSQL с помощью SQL-модуля «psycopg2» напоминает то, что мы делали с SQLite и MySQL.
Для получения записей из таблицы PostgreSQL мы снова используем сначала метод «cursor.execute()», а затем «.fetchall()». Этот скрипт получает все записи из таблицы «users» и выводит их на терминал:
def execute_read_query(connection, query): cursor = connection.cursor() result = None try: cursor.execute(query) result = cursor.fetchall() return result except OperationalError as e: print(f"Произошла ошибка ''") select_users = "SELECT * from users" users = execute_read_query(connection, select_users) for user in users: print(user)
Результат аналогичен тому, что мы уже видели.
Обновление табличных записей
В прошлом разделе вы узнали, как получать записи из баз SQLite, MySQL и PostgreSQL. В этом разделе мы рассмотрим, как обновлять записи, используя SQL-библиотеки Python: SQLite, PostgreSQL и MySQL.
SQLite
Обновление записей в SQLite происходит довольно просто. Можно вновь воспользоваться методом «execute_query()».
Для примера обновим текст публикации (поле «description») с идентификатором («id») 2. Используем оператор «SELECT» для извлечения текста публикации:
select_post_description = "SELECT description FROM posts WHERE = execute_read_query(connection, select_post_description) for description in post_description: print(description)
Мы должны получить такой результат:
('Погода сегодня очень жаркая',)
Этот скрипт изменит текст:
update_post_description = """ UPDATE posts SET description = "Установилась приятная погода" WHERE id = 2 """ execute_query(connection, update_post_description)
Если теперь снова выполнить запрос «SELECT», вывод команды будет иным:
('Установилась приятная погода',)
Как видно, результат изменился.
MySQL
При использовании драйвера «mysql-connector-python» процесс обновления записей в MySQL ничем не отличается от «sqlite3». Нужно лишь передать строку запроса методу «cursor.execute()».
К примеру такой скрипт обновит текст публикации с идентификатором («id») 2:
update_post_description = """ UPDATE posts SET description = "Установилась приятная погода" WHERE id = 2 """ execute_query(connection, update_post_description)
Здесь для обновления текста публикации мы вновь использовали нашу функцию-обёртку «execute_query()».
PostgreSQL
В PostgreSQL запрос на изменение записи похож на те, что мы видели в SQLite и MySQL. Для обновления записей в таблице PostgreSQL можно использовать те же скрипты.
Удаление табличных записей
В этом разделе вы узнаете, как удалить запись в таблице, используя модули Python для баз данных SQLite, MySQL и PostgreSQL.
Процесс удаления записей для всех трёх СУБД в Python одинаков, поскольку использование оператора «DELETE» в них идентично.
SQLite
Для удаления записей из нашей базы SQLite можно вновь прибегнуть к функции «execute_query()». Нужно лишь передать ей объект «connection» и строку запроса с указанием записи, которую мы хотим удалить.
Затем функция «execute_query()» создаст на основе объекта «connection» объект «cursor» и передаст строку запроса методу «cursor.execute()», который и удалит записи.
Для примера попробуем удалить комментарий с идентификатором («id») 5:
delete_comment = "DELETE FROM comments WHERE delete_comment)
Если теперь сделать выборку всех записей таблицы «comments», будет видно, что пятый комментарий удалён.
MySQL
В MySQL удаление аналогично тому же действию в SQLite:
delete_comment = "DELETE FROM comments WHERE delete_comment)
Здесь мы удаляем второй комментарий из таблицы «comments» в базе данных «sm_app» на сервере MySQL.
PostgreSQL
Запрос на удаление в PostgreSQL выполняется аналогично подобным запросам в SQLite и MySQL.
Можно написать строку с запросом на удаление, в которой будет использоваться оператор «DELETE». Затем передать эту строку вместе с объектом «connection» функции «execute_query()». Это удалит указанные записи из нашей базы PostgreSQL.
Заключение
Из этого руководства вы узнали, как использовать три основные SQL-библиотеки Python. Модули «sqlite3», «mysql-connector-python» и «psycopg2» позволяют подключиться из приложений Python к базам SQLite, MySQL и PostgreSQL соответственно.
Теперь вы умеете:
- Применять Python для работы с MySQL, SQLite и PostgreSQL.
- Использовать три различных SQL модуля Python.
- Выполнять из приложений Python SQL запросы для различных баз данных.
Но всё это только вершина айсберга. В Python есть и SQL-библиотеки для объектно-реляционного отображения (ORM). Например SQLAlchemy или Django ORM, которые автоматизируют работу с SQL базами данных из Python.
Нужна надёжная база для разработки программных продуктов? Выбирайте виртуальные серверы от Eternalhost с технической поддержкой 24/7 и бесплатной защитой от DDoS!
Базы данных в Python

Эта статья о том, как работать с базами данных в Python. Эта статья носит, скорее, вступительный характер. Вы не изучите весь язык SQL, вместо этого, я дам вам развернутое представление о командах SQL и затем мы научимся подключаться к нескольким популярным базам данных в Python. Большая часть баз данных использует базовые команды SQL одинаково, но они также могут использовать специальные команды для бекенда той или иной базы данных, или просто работают с некоторыми отличиями. Рекомендую ознакомиться с документацией к базам данных, если у вас возникнут проблемы. Мы начнем статью с изучения базового синтаксиса SQL.
Базовый синтаксис SQL
SQL расшифровывается как Structured Query Language (язык структурированных запросов). Это, в сущности, де-факто язык для взаимодействия с базами данных и является примитивным языком программирования. В данном разделе мы рассмотрим основы CRUD (Create, Read, Update и Delete). Это самые важные функции, которые вам нужно освоить, перед тем как использовать базы данных в Python. Конечно, вам также понадобится узнать как создавать запросы, но мы рассмотрим это по ходу дела, когда нужно будет выполнять запрос для чтения, обновления или удаления.
Создание таблицы
Первое что вам нужно для базы данных – это таблица. Это место, где ваши данные будут организованы и храниться. Большую часть времени вам будут нужны несколько таблиц, в каждой из которых будут храниться поднастройки ваших данных. Создание таблицы в SQL это просто. Все что вам нужно сделать, это следующее:
CREATE TABLE table_name (
id INTEGER ,
name VARCHAR ,
make VARCHAR
model VARCHAR ,
PRIMARY KEY (id)
Это довольно обобщенный код, но он работает в большей части случаев. Первое, на что стоит обратить внимание – куча слов прописанных заглавными буквами. Это команды SQL. Их не всегда нужно вписывать через капс, но мы сделали это, чтобы помочь вам увидеть их. Я также хочу обратить внимание на то, что каждая база данных поддерживает слегка отличающиеся команды. Большинство будет содержать CREATE TABLE, но типы столбцов баз данных могут быть разными. Обратите внимание на то, что в этом примере у нас есть базы данных INTEGER, VARCHAR и DATE.
DATE может вызывать много разных штук, как и VARCHAR. Проконсультируйтесь с документацией на тему того, что вам нужно делать. В любом случае, в этом примере мы создаем базу данных с пятью столбцами. Первый – это id, который мы настраиваем в качестве нашего основного ключа. Он не должен быть NULL, но мы и не указываем, что в нем, так как еще раз, каждый бекенд базы данных выполняет работу по-разному, или делает это автоматически для нас. Остальные столбцы говорят сами за себя
Введение данных
Сейчас наша база данных пустая. Это не очень полезно в использовании, так что в этом разделе мы научимся добавлять данные в базу. Вот общая идея:
INSERT INTO table_name (id, name, make, model, year )
VALUES (1, 'Marly' , 'Ford' , 'Explorer' , '2000' );
SQL использует команды INSERT INTO для добавления данных в определенную базу данных. Вы также указываете, в какие столбцы вы добавляете данные. Когда мы создаем таблицу, мы можем определить необходимый столбец, который может вызвать ошибку, если мы не добавим в него необходимые данные. Однако, мы не делали этого в нашем определении таблицы ранее. Это просто на заметку. Вы также получите ошибку, если передадите неправильный тип данных, от этой вредной привычки я не мог отвыкнуть целый год. Я передавал строку или varchar, вместо данных. Конечно, каждая база данных требует определенный формат этих самых данных, так что вам может понадобиться разобраться с тем, что именно значит DATE для вашей базы данных.
Обновление данных
Представим, что мы сделали опечатку в нашем INSERT. Чтобы это исправить, нам нужно использовать команду SQL под названием UPDATE:
UPDATE table_name
SET name = 'Chevrolet'
WHERE id = 1 ;
Команда UPDATE говорит нам, какая таблица нуждается в обновлении. Далее мы используем SET в одном или более столбцах для вставки нового значения. Наконец, на нужно указать базе данных ту строку, которую мы хотим обновить. Мы можем использовать команду WHERE, чтобы указать базе данных, что мы хотим изменить строчку, Id которой является 1.
Чтение данных
Чтение данных нашей базы данных осуществляется при помощи оператора SQL под названием SELECT:
SELECT name , make , model
FROM table_name ;
Так мы возвращаем все строчки из нашей базы данных, но результат будет содержать только три части данных: название, создание и модель. Если вы хотите охватить все данные в базе данных, вы можете выполнить следующее:
SELECT * FROM table_name ;
Звездочка в данном случае это подстановка, которая говорит SQL, что вы хотите охватить все столбцы. Если вы хотите ограничить выбранный вами охват, вы можете добавить команду WHERE в вашем запросе:
SELECT name , make , model
FROM table_name
WHERE year >= '2000-01-01' AND
year <= '2006-01-01' ;
Так мы получим информацию о названии, создании и модели для 2000-2006 годов. Существует ряд других команд SQL, которые помогут вам в работе с запросами. Убедитесь, что ознакомитесь с такими командами как BETWEEN, LIKE, ORDER BY, DISTINCT и JOIN.
Удаление данных
Возможно, вам понадобиться удалить данные из вашей базы данных. Как это сделать:
DELETE FROM table_name
WHERE name = 'Ford' ;
Этот код удалит все строчки, в поле названия которых указано «Ford» из нашей таблицы. Если вы хотите удалить всю таблицу, вы можете воспользоваться оператором DROP:
DROP TABLE table_name ;
Используйте DROP и DELETE осторожно, так как вы легко можете потерять все данные, если вызовете оператор неправильно. Всегда держите хороший, годный, проверенный бекап вашей базы данных.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
adodbapi
В версиях Python2.4 и 2.5, мне нужно было подключаться к серверу SQL 2005 и Microsoft Access, и один из них или оба были настроены только для использования методологии подключения Microsoft к ADO. На то время решением было использовать пакет adodbapi. Этот пакет следует использовать тогда, когда вам нужно получить доступ к базе данных через Microsoft ADO. Я заметил, что этот пакет не обновлялся с 2014 года, так что помните об этом. К счастью, вам не нужно использовать этот пакет, так как Microsoft также предоставляет драйвер связи ODBC, но если по какой-то причине вам нужно поддерживать только ADO, то этот пакет – то, что вам нужно!
Запомните: adodbapi зависит от наличия установленного пакета PyWin32.
Для установки adodbapi, вам нужно сделать следующее:
pip install adodbapi
Давайте посмотрим на простой пример, который я использую для связи с Microsoft Access на протяжении длительного времени:
import adodbapi
database = "db1.mdb"
constr = 'Provider=Microsoft.Jet.OLEDB.4.0; Data Source=%s'
tablename = "address"
# Подключаемся к базе данных.
conn = adodbapi . connect ( constr )
# Создаем курсор.
cur = conn . cursor ( )
# Получаем все данные.
sql = "select * from %s" % tablename
cur . execute ( sql )
# Показываем результат.
result = cur . fetchall ( )
for item in result :
print item
# Завершаем подключение.
cur . close ( )
conn . close ( )
Сначала мы создаем строку соединения. Эти строки определяют, как связаться с Microsoft Access или сервером SQL. В данном случае, мы подключаемся к Access. Для непосредственной связи с базой данных, вы вызываете метод connect и передаете ему вашу строку связи. Теперь у вас есть объект соединения, но для взаимодействия с базой данных вам нужен курсор. Его мы и создаем. Следующая часть – написание запроса SQL. В данном случае мы используем всю базу данных, так что мы выделяем * и передаем этот оператор SQL методу execute нашего курсора. Для получения результата мы вызываем fetchall, который возвращает весь результат. Наконец, мы закрываем cursor и connection. Если вы используете пакет adodbapi, я настоятельно рекомендую пройтись по справочному документу. Это очень полезно для понимания пакета, так как он не слишком хорошо документирован.
pyodbc
ODBC (Open Database Connectivity) – это стандартный API для доступа к базам данных. Большая часть баз данных продукции включает драйвер ODBC, который вы можете установить для связи с базой данных. Один из самых популярных методов связи с Python через ODBC – это пакет pyodbc. В соответствии с его страницей на Python Packaging Index, вы можете использовать его как на Windows, так и Linux. Пакет pyodbc реализует спецификацию DB API 2.0. Вы можете установить pyodbc при помощи pip:
pip install pyodbc
Давайте взглянем на довольно обобщенный способ подключения к серверу SQL при помощи pyodbc и выберем какие-нибудь данные, как мы делали это в разделе adodbapi:
import pyodbc
driver = 'DRIVER=
server = 'SERVER=localhost'
port = 'PORT=1433'
db = 'DATABASE=testdb'
user = 'UID=me'
pw = 'PWD=pass'
conn_str = ';' . join ( [ driver , server , port , db , user , pw ] )
conn = pyodbc . connect ( conn_str )
cursor = conn . cursor ( )
cursor . execute ( 'select * from table_name' )
row = cursor . fetchone ( )
rest_of_rows = cursor . fetchall ( )
В данном коде мы создаем очень длинную строку связи. У нее много частей. Драйвер, сервер, номер порта, название базы данных, пользователь и пароль. Возможно, вам захочется сохранить большую часть этой информации в какой-нибудь файл конфигурации, так что вам не нужно будет вводить эту строку каждый раз. Желательно не перемудрить с именем пользователя и паролем. После получения нашей строки связи, мы попытаемся соединиться с базой данных, вызвав функцию connection. Если подключение прошло удачно, то мы получаем объект подключения, который мы можем использовать для создания объекта курсора. Теперь у нас есть курсор, мы можем запросить базу данных и запустить любые команды, которые нам нужны, в зависимости от того, какой доступ у базы данных. В этом примере, мы запускаем SELECT * для извлечения всех строчек. Далее мы демонстрируем нашу возможность брать по одной строчке за раз и вытягивать их через fetchone и fetchall соответственно. Также у нас в распоряжении имеется функция fetchmany, которую вы можете использовать для определения того, как много строчек вам нужно вернуть. Если вы имеете дело с базой данных, которая работает с ODBC, вы также можете использовать данный пакет. Обратите внимание на то, что базы данных Microsoft не единственные поддерживают данный метод соединения.
pypyodbc
Пакет pypyodbc, по сути, чистый скрипт Python. Это, в целом, переопределенный pyodbc чисто под Python. Это значит, что pyodbc – это Python, обернутый в бекенд C++, в то время как pypyodbc это чистый код Python. Он поддерживает тот же API, как и предыдущий модуль, так что эти модули взаимозаменяемые в большинстве случаев. В связи с этим, я не буду показывать никаких примеров в данном разделе, так как единственная разница между ними – это импорт.
MySQL в Python
MySQL – это очень популярный бекенд баз данных с открытым кодом. Вы можете подключить его к Python несколькими различными путями. Например, вы можете подключить его, используя один из методов ODBC, которые я упоминал в последних двух разделах. Один из наиболее популярных способов подключения MySQL к Python это пакет MySQLdb. Существует несколько вариантов того пакета:
Первый – это привычный способ подключения MySQL к Python. Однако, в основном он используется только в разработке и на данный момент не получает никаких новых функций. Разработчики переключились на MySQLdb2, и преобразовали его в проект moist. В MySQL произошел раскол после того, как их купили Oracle, что привело к разветвлению на проект, который называется Maria. Так что мы имеем дело с проектами MariaDB, MySQL и еще одной веткой, под названием Drizzle, каждая из которых, в той или иной мере основана на исходном коде MySQL. Проект moist направлен на создание моста, который мы можем использовать для соединения со всеми этими бекендами, к тому же, он все еще находится на этапах альфа или бета с момента публикации. Путаницу также создает тот факт, что MySQLdb завернут в _mysql, который вы можете использовать напрямую, если это нужно. В любом случае, вы быстро заметите, что MySQLdb не совместим с Python 3, вообще. Совместимость с проектом moist скоро будет, но пока её нет. Итак, как же работать с Python 3? У вас есть несколько вариантов:
- mysql-connector-python
- pymysql
- CyMySQL
- mysqlclient
mysqlclient – это ответвление MySQL-Python (другими словами, MySQLdb), который обеспечивает поддержку Python 3. Это метод, который проект Django рекомендует для подключения к MySQL. Так что мы сфокусируемся на этом пакете в данном разделе. Обратите внимание на то, что вам понадобится установленный MySQL или MySQL Client для успешной установки пакета mysqlclient. Если вы уже сделали это ранее, то вам остается только использовать pip для установки: