Парсеры Яндекс.Вордстат — 11 сервисов и расширений
Здравствуйте! Яндекс.Вордстат — бесплатный инструмент для сбора ключевых слов для рекламных кампаний и составления семантического ядра сайта. Парсеры позволяют ускорить и автоматизировать процесс сбора ключевиков. Они помогают отслеживать потребности ЦА, полезны при выборе маркетинговой стратегии, создании SEO-текстов и запуске рекламы. Парсеры — это один из инструментов работы SEO-специалистов. В статье расскажем, какие парсеры подходят для сбора ключевых слов из Яндекс.Вордстат.
11 парсеров Яндекс.Вордстат: онлайн-сервисы, программы и бесплатные расширения
Рассказываем кратко о возможностях каждого сервиса. Основная функция большинства парсеров — поиск частотности по заранее заданному списку запросов. С разбивкой по регионам. Если кроме частотности нужен поиск запросов, связанных с исходным словом или похожие запросы, нужно уточнять, есть ли такая функция в сервисе. P.S. Парсер может быть в виде самостоятельного сервиса, одной из функций другого сервиса или в виде расширения для браузеров. Чаще всего такие парсеры входят в функционал сервисов по комплексному продвижению в Интернете.
1. Key Collector
- несколько фильтров для отбора лучших запросов;
- есть дерево групп и редактор структуры — позволяет работать в одном файле, а не создавать несколько файлов под каждую группу;
- автоматическая и ручная кластеризация;
- поиск неявных дублей;
- фильтрация по стоп-словам;
- более 50 параметров статистики;
Дополнительная фишка: регулярные бесплатные обновления, коммьюнити пользователей.
Цена: бессрочная лицензия — 2 200 рублей без абонентской платы.
2. Парсер Wordstat от Click.ru
Парсер встроен в Click.ru — сервис для комплексной настройки и ведения рекламных кампаний.
Возможности:
- проверка частотности по заданному списку фраз из XLS-файла или при ручной загрузке списка;
- кластеризация запросов;
- выбор региона для парсинга;
- сбор поисковых подсказок;
- сбор фраз ассоциаций;
- парсер мета-тегов и заголовков
- составление заголовков и текстов для рекламных объявлений на основе найденных ключевиков;
- формирование отчетов в формате XLSX, которые хранятся в облаке;
- операторы соответствия ключевиков для более точной статистики (широкое соответствие, фиксация количества и порядка слов);
- встроенная защита от повторного парсинга по тем же запросам.
Дополнительные фишки: не нужно использовать прокси-серверы и вводить капчу.
Цена: доступно 50 запросов для теста, далее цены зависят от задачи и количества запросов. В среднем — от 0.02 до 0.12 рублей за запрос.
3. Парсинг поисковых подсказок от Пиксель Тулс
Парсер в составе сервиса Пиксель Тулс. Сам сервис включает в себя несколько инструментов для SEO-продвижения. Парсер позволяет найти схожие ключевики на основе подсказок Яндекса.
Возможности:
- автоматический поиск подсказок (ключевых слов и фраз) — на основе перестановки слов, изменения начала/конца запроса, автосгенерированные;
- экспорт подсказок в виде отчета в CSV-файл;
- можно настроить регион;
- можно настроить глубину парсинга — искать по исходному запросу или к уже полученным подсказкам;
- настройка стоп-слов;
Цена: инструмент доступен только в составе сервиса Пиксель Тулс, отдельно оплатить нельзя. Тарифы сервиса — от 950 до 12 990 рублей в месяц.
4. Парсер от Rush Analytics
Это тоже инструмент в составе сервиса для комплексного SEO-продвижения.
Возможности:
- подбор ключевых слов и частотности (все виды);
- фильтрация гео-запросов;
- фильтрация по стоп-словам;
- кластеризация;
- сбор поисковых подсказок;
- точная проверка позиций в Яндекс (и Google);
Дополнительные фишки: высокая скорость парсинга (100 запросов в секунду), не нужно использовать прокси и вводить капчи. Есть инструмент проверки индексации.
Цена: чтобы пользоваться инструментом, нужно оплатить весь сервис (от 999 рублей в месяц при оплате за год). При этом оплата за запрос — 0,03 рубля за страницу Вордстат или 1 рубль за 40 страниц.
5. OverLead
Онлайн сервис для сбора ключевых слов с Яндекс.Вордстат.
Возможности:
- парсинг основных запросов;
- парсинг похожих запросов, синонимов и ассоциаций;
- сезонный парсинг;
- настройка региона сбора;
- можно установить глубину парсинга;
- есть настройка минус-слов и фильтры частотности;
Дополнительная фишка: + 100 рублей на баланс после регистрации, можно протестировать сервис. Не нужны прокси и капчи.
Цена: от 1 рубля за 60 ключей или 40 страниц. За 100 рублей можно собрать 7 500 ключей или 5 000 страниц.
6. MOAB.Tools Семантика
Онлайн-сервис для сбора семантики. Простой в использовании, без прокси, без капч. За 32 минуты можно собрать 2 млн фраз.
Возможности:
- сбор фраз с Yandex Wordstat, Яндекс.Подсказок и проверка частотности Yandex Wordstat;
- 71 вариант перебора запросов для поиска ультра-НЧ;
- выбор регионов;
- настройка глубины поиска;
- готовый файл с отчетом для скачивания;
Дополнительные фишки: 5 000 фраз в подарок. Интеграция с Key Collector. Бонусы при покупке сервиса.
Цена: видна после регистрации и тестового периода.
7. Мутаген
Мутаген — это сервис для оптимизаторов, вебмастеров и копирайтеров. Один из инструментов — парсер Яндекс.Вордстат и Директ.
Возможности:
- парсинг ключей со всех страниц Вордстат (или только первой);
- определение частотности;
- доступна история проверок;
Цена: 2 копейки за запрос.
8. Букварикс
Программа для подбора слов по списку исходников или одному исходному слову.
Возможности:
- возможность выбора частотностей по двум типам запросов к Яндексу;
- модуль морфологии — позволяет получать ключевики с изменением падежа и числа;
- комбинатор слов;
- настройка минус-слов;
- поддержка более 80 регионов;
- экспорт в форматы .txt и .csv. с возможностью разбивки больших файлов на части.
Цена: ограниченная версия бесплатная, есть продвинутая за 695 рублей в месяц.
9. Парсеры — расширения для браузера
Расширения могут быть частью платного сервиса или самостоятельными. Во втором случае у них обычно ограниченный функционал, который подходит для небольших проверок.
Несколько полезных расширений:
Yandex Wordstat Assistant — ускоряет сбор фраз и определение частотности. Есть автоматическая проверка на дубли. Также есть несколько режимов сортировки: по порядку добавления, по алфавиту, по частотности.
WordStater для Wordstat — расширение от сервиса UTA-manager. Позволяет собрать семантику по конкретной ключевой фразе или списки минус-слов из Вордстата. Дополнительно можно спрогнозировать стоимость клика и количество посетителей Яндекс.Директ по собранным запросам.
Yandex Wordstat Helper — по принципу работы похоже на расширение Yandex Wordstat Assistant. Это виджет, который отображается на страницах Вордстата. Возможности: сбор ключевиков, проверка на дубли, автоматическая сортировка по алфавиту, копирование в один клик.
Заключение
Между парсерами Яндекс.Вордстат не так много отличий. Например, поиск частотности по слову или списку — стандартная функция парсера. У одних чуть больше функций, у других чуть меньше. А также отличаются лимиты и цена.
Для комплексного SEO-продвижения лучше брать парсер в составе сервисов, в которых есть сразу несколько инструментов. Например, Click.ru, Пиксель Тулс, Rush Analytics. Если нужны только ключевики, с этой задачей справится Key Collector, Мутаген, Букварикс. Для простых задач и небольших объемов можно обойтись расширениями.
Яндекс Wordstat – инструкция по применению для новичка

Выполнить эту задачу можно с помощью регулярного мониторинга запросов в Яндекс.Wordstat. Этот бесплатный инструмент позволяет анализировать интересы аудитории с помощью статистики по поисковым фразам. Функционал платформы шире, чем кажется на первый взгляд. Несмотря на интуитивно понятный интерфейс, многие не используют весь его потенциал. В этой статье мы предлагаем пошаговые инструкции по работе со всеми возможностями сервиса.
Основные функции Яндекс.Wordstat
Основа сервиса – статистика поиска Яндекса. Вы вводите в строку ключевое слово или словосочетание, а система выдает данные по этой фразе. В списках будут запросы трех видов:
- Точные, которые включают в себя заданную фразу в неизменном виде.
- Уточненные – в разных формулировках и склонениях.
- Похожие – вариации, смежные слова, которые вводили люди в поиске.
По умолчанию выводится общая статистика по стране и без учета устройств. Вы можете отфильтровать ее по регионам и посмотреть данные по мобильному или десктопному трафику. В интерфейсе вы также найдете историю сезонных колебаний. Эта функция позволяет посмотреть динамику запроса в течение последних двух лет.
Какие задачи можно решить с помощью сервиса?
Описанный функционал позволяет анализировать потребности целевой аудитории, выбирать ориентиры маркетинговой стратегии, готовить тексты для SEO и составлять объявления для контекстной рекламы. Чтобы понять, как работать с Яндекс.Wordstat, необходимо разобраться, с какими задачами он помогает справиться.
Подбор ключевых фраз
Для эффективных маркетинговых мероприятий требуется понимать, чем интересуется целевая аудитория. Когда нужно решить проблему, человек открывает поисковую системы и пишет свой вопрос. Узнать, что ищут ваши потенциальные клиенты, поможет сбор ключевых слов из Яндекс.Wordstat.
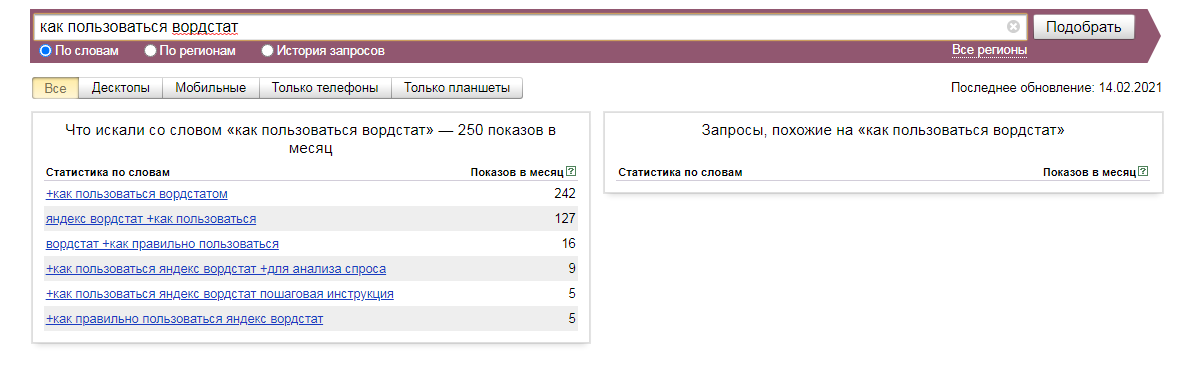
В строку поиска необходимо ввести интересующую вас фразу и нажать кнопку «Подобрать»:

Например, вы продвигаете интернет-магазин мебели и вам нужно продать белый диван. Вы можете проанализировать спрос с помощью статистики. Вместе с подобранными фразами сервис покажет частотность запросов:
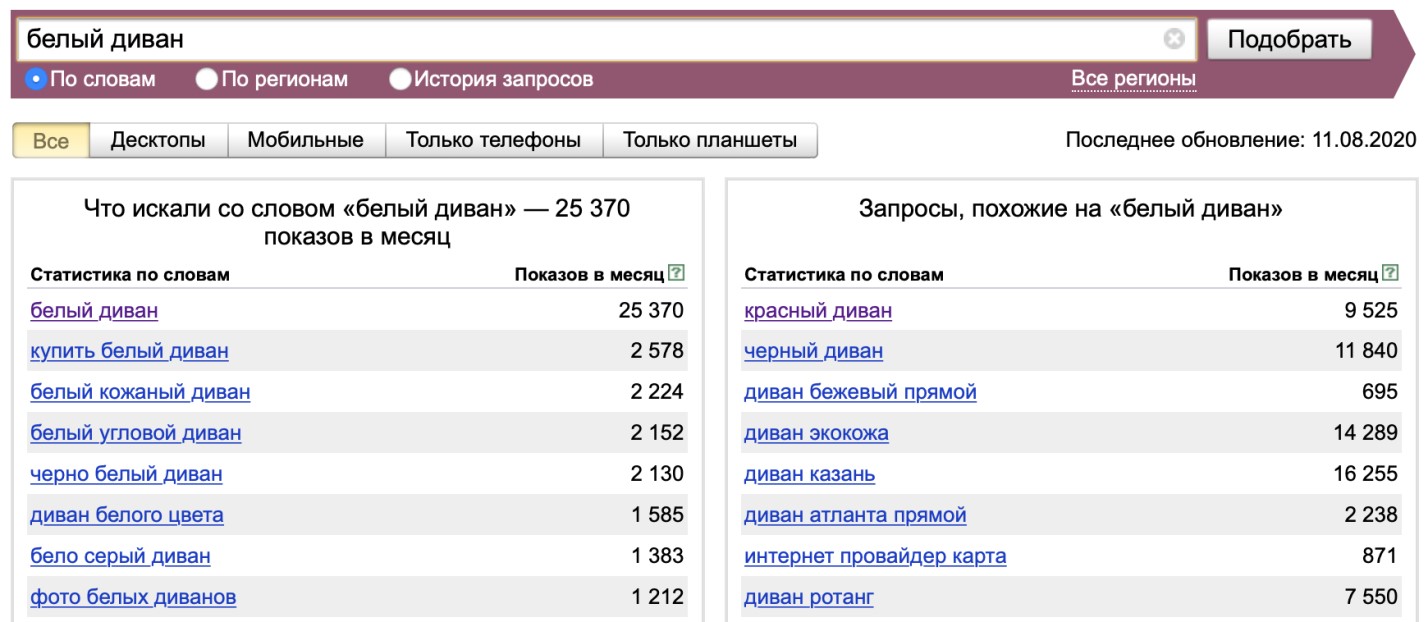
Чтобы правильно анализировать полученные данные, важно понимать, что:
- Цифра по частотности отображает не то, сколько пользователей вводили указанную фразу, а сколько раз была показана реклама в Яндекс.Директ по этому ключевику.
- Неправильно суммировать показы по всем формулировкам, потому что уточненные запросы включаются в основной. На примере: в 25370 показов по фразе «белый диван» входит 2578 по уточнению «купить белый диван».
- Автоматически учитываются все числа и падежи (пример: «фото белых диванов»).
Еще один момент, который нужно учитывать, вводя точный запрос в Вордстат, что ваши конкуренты также пользуются сервисом. Иногда цифры не отражают реальной картины из-за постоянного мониторинга сайтов.
В списке справа показываются похожие фразы. Их можно использовать как ориентиры при анализе потребностей целевой аудитории и смежных интересов.
Оценка запросов по регионам
Пользоваться Яндекс.Wordstat можно не только для сбора общей статистики, но и аналитики по местоположению целевой аудитории. В одном городе, например, в Краснодаре спрос на валенки или теплые пуховики будет существенно ниже, чем в Архангельске. Для продвижения локального бизнеса обязательно учитывать региональную специфику.
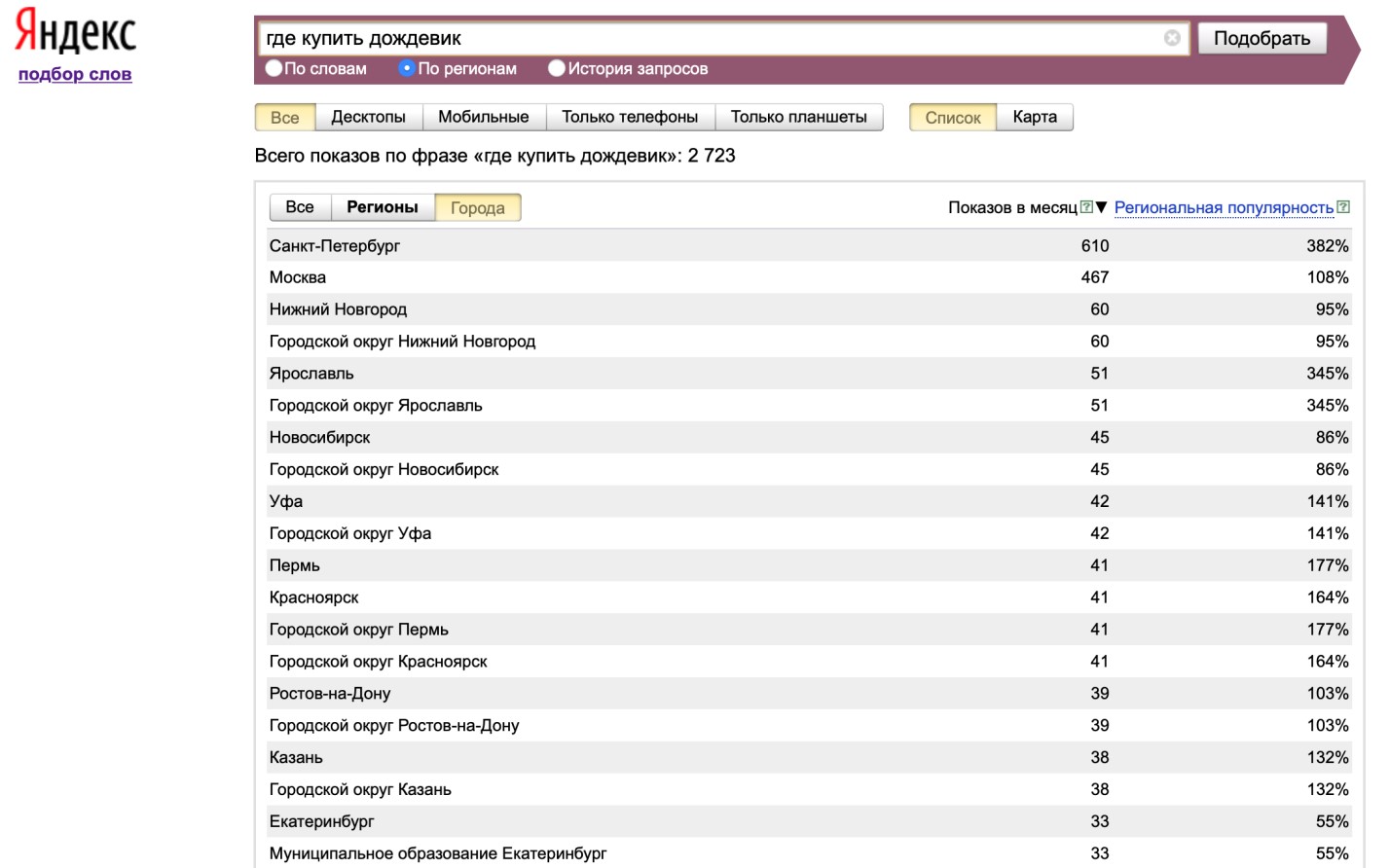
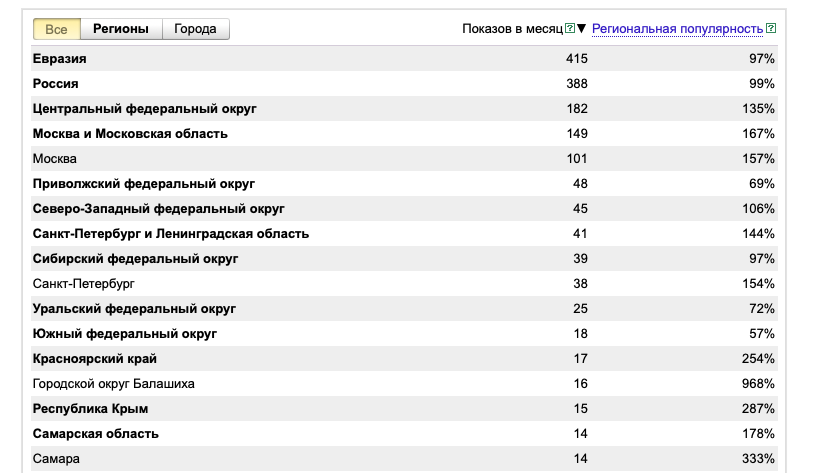
Введите запрос и отметьте опцию «По регионам». В результате вы получите рейтинг его популярности в разных локациях. Региональная популярность измеряется в процентах: все, что выше 100% – это повышенный спрос. Дополнительно вы можете посмотреть частотность запроса на карте.
Анализ сезонности
Многие сферы бизнеса подвержены сезонности, поэтому активные маркетинговые кампании лучше планировать на рост тенденции, а подготовительные работы проводить в периоды спада. Базовая работа сервиса помогает решить и эту задачу. При выборе опции «История запросов» вы увидите динамику популярности ключевой фразы. Статистика доступна за 2 года, а наблюдать за изменениями можно по месяцам или неделям.
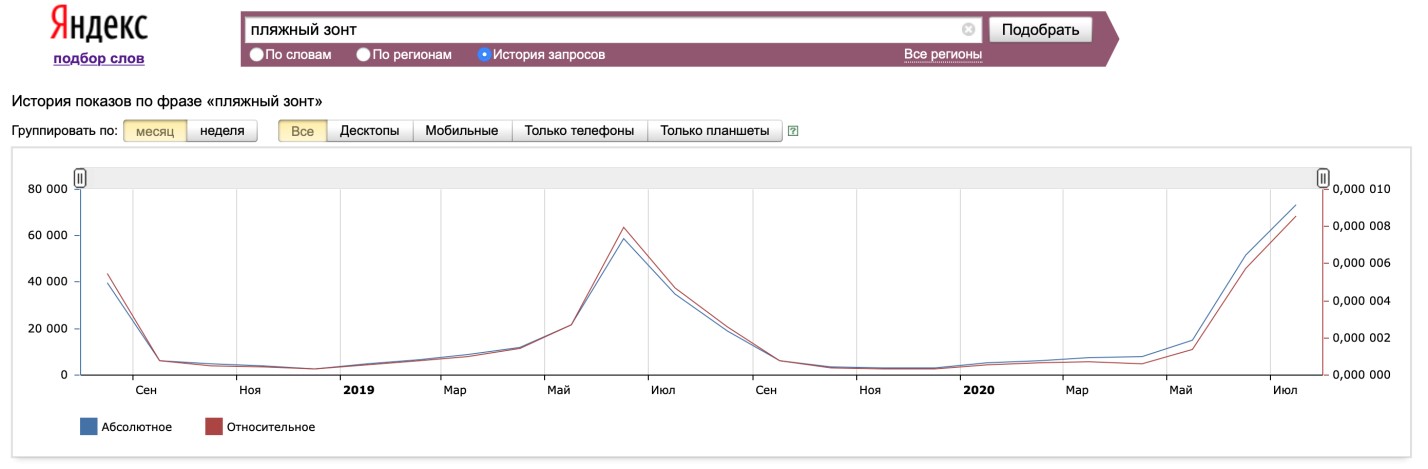
На графике отображается типичный пример сезонного бизнеса с явным всплеском: очевидно, пляжными зонтами покупатели интересуются больше в летние месяцы. Обратите внимание, что здесь учитываются все фразы по широкому соответствию, то есть вы видите совокупный тренд по всем формулировкам, склонениям и уточнениям.
Инструкция использования Яндекс.Wordstat
Хотя функционал сервиса помогает выполнить ключевые маркетинговые задачи, связанные изучением спроса и исследованием целевой аудитории, главное предназначение платформы – сбор слов для контекстной рекламы и SEO. Использования Яндекс.Wordstat доступно только авторизованным пользователям, поэтому вам необходимо зарегистрироваться и зайти в систему.
Стандартные функции платформы не дают достаточного количества информации для глубокого анализа и формирования семантического ядра. Чтобы получить, действительно, полезные данные, необходимо разобраться, что такое базовые операторы и как их использовать.
Операторы Вордстат
Применение операторов необходимо для прогнозов по объему трафика, отдачи от SEO и для точного анализа отдельных фраз.
Например, вам необходимо узнать не суммарный трафик по всем запросам, а точное число показов конкретной формулировки. В этом и помогут операторы синтаксиса, которые представляют собой инструменты для управления системой:
- Восклицательный знак Поставив «!» перед словом, вы показываете системе, что необходимо получить результаты по конкретному запросу в конкретной форме. В таком случае учитывается падеж и окончание.
- Кавычки Символы «» используются для исключения уточняющих словосочетаний. Вордстат покажет вам только статистику по выбранной фразе, включая разные формы слов.
- Совместное использование Если использовать и кавычки, и восклицательный знак перед каждым словом, то вы зафиксируете и конкретную фразу, и форму. В результате вы сможете получить точную частоту.
- Или Символ «|» позволяет сравнивать или объединять фразы в статистике. Это ускоряет подбор семантики. Единственная проблема его использования – ограниченная длина строки.
- Плюс «+» используется для поиска запросов со стоп-словами, в частности с предлогами или частицами.
- Минус «-» – противоположный плюсу оператор, который нужен для исключения отдельных слов из выдачи.
- Квадратные скобки Заключив фразу в «[ ]», вы фиксируете порядок словосочетания. С помощью этих символов вы сможете оценить популярность близких фраз.
- Круглые скобки «( )» включают параметр группировки. Он необходим для комбинации нескольких перечисленных выше операторов.
Всё это поможет собрать семантическое ядро и уточнить прогнозы по трафику.
Как собрать семантическое ядро?
Чтобы запустить эффективную контекстную рекламу и начать продвижение сайта в поиске, необходимо собрать семантическое ядро по запросам целевой аудитории. Эта инструкция работы с Wordstat поможет вам организовать этот процесс.
1. Первое, что нужно сделать – определить, какие формулировки используют потенциальные клиенты в поиске. Начните с широкого запроса, например, «мебель для спальни».
Ваша задача – отобрать только релевантные слова, которые соответствуют предложению. Например, если вы продаете двуспальные кровати, то необходимо исключить «детские спальни мебель». Также лишними будут брендовые запросы других компаний. Уточняйте формулировку, добавляя минус-слова с помощью операторов.
2. Если ваш бизнес привязан к определенной локации, необходимо настроить регион. Здесь же вы можете учесть тип устройства. Например, при создании рекламы для страницы приложения для смартфонов, необходимо анализировать только мобильный трафик.
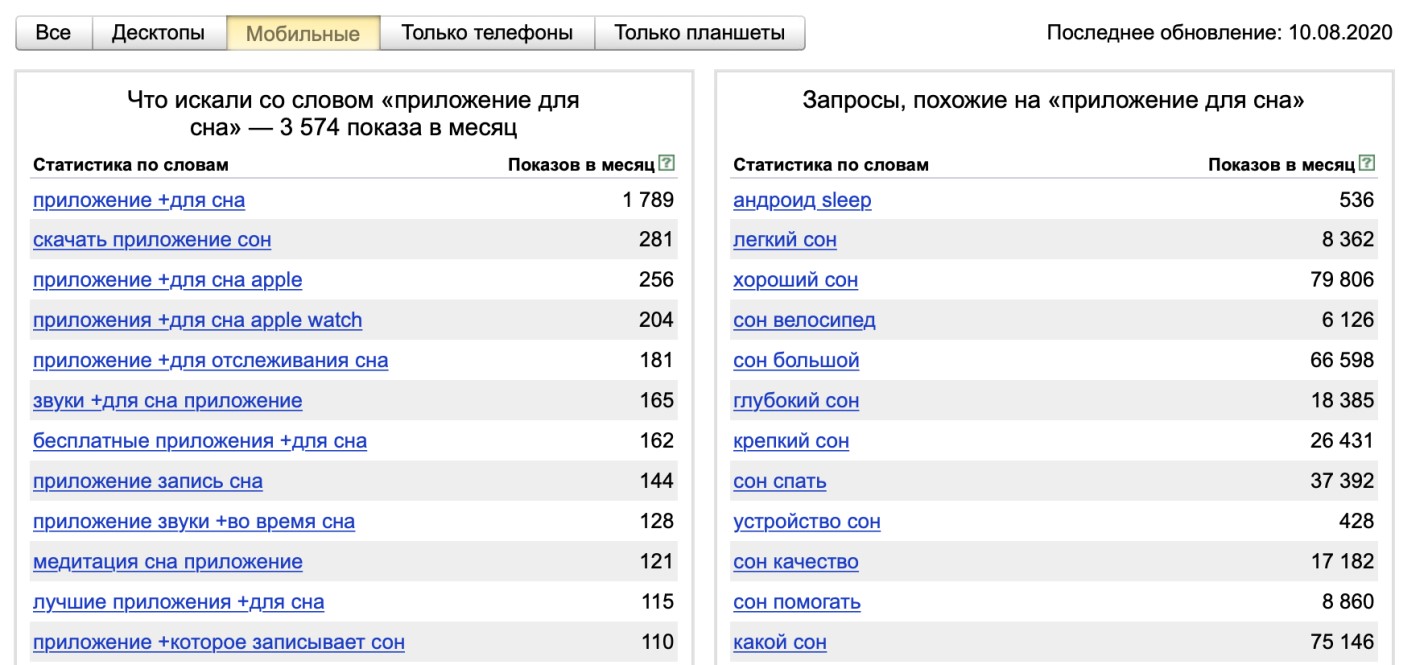
3. Создайте Excel таблицу и копируйте в нее данные с частотой. Для удобства сразу делайте распределение, сегментируйте слова по страницам или тематикам. Проработав основной список, переходите к похожим запросам. Вы можете нажать на любое словосочетание из этой таблицы, чтобы собрать больше целевых фраз.
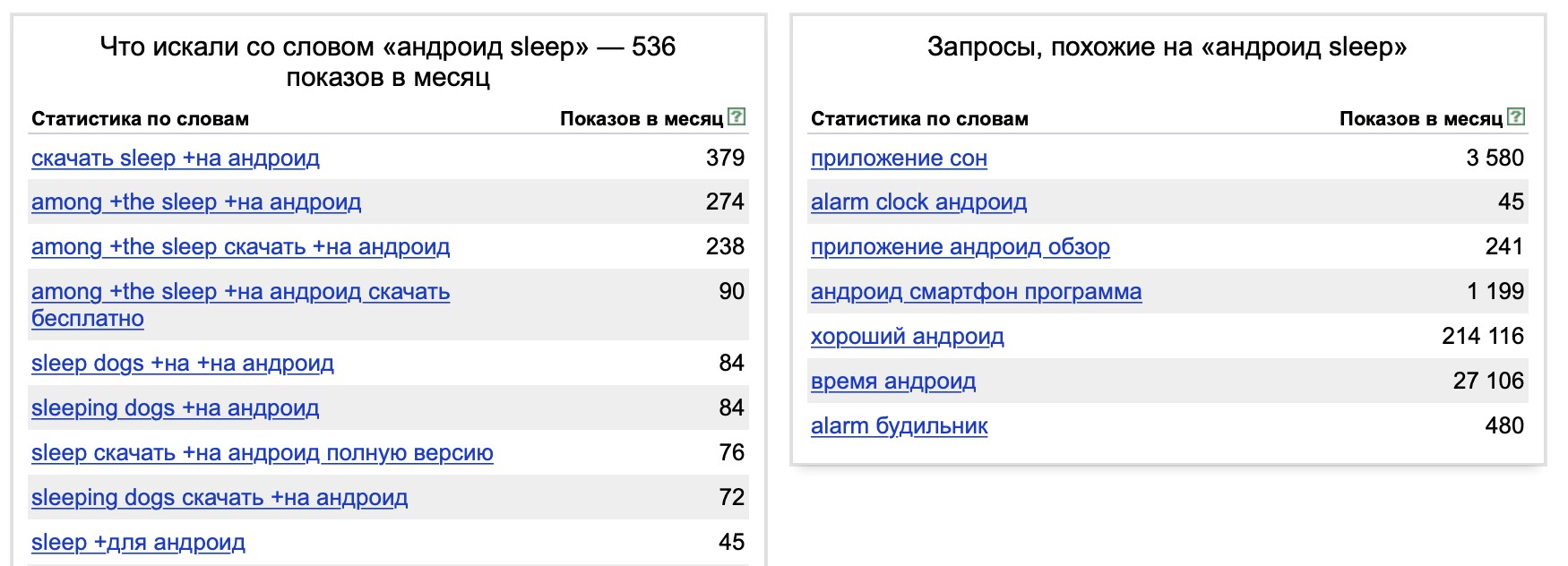
Например, если нажать на «андроид sleep» из правого списка, Вордстат покажет его статистику.
Надстройки и расширения
Выгружать слова из Яндекс.WordStat в Excel по строкам вручную – это долгий и сложный процесс, который можно автоматизировать. Базовые надстройки для браузеров упростят работу за счет установки виджетов. С ними вам не нужно будет переключаться между вкладками и окнами, вы сможете быстро добавлять или удалять фразы и моментально копировать созданный список.
- Yandex Wordstat Helper – базовое расширение для составления СЯ с автоматическими сортировками, проверкой на дубли, счётчиками и т.д.
- Yandex Wordstat Assistant – плагин, который поможет в два клика выгрузить ключевые слова из Вордстат. Также позволяет добавлять свои списки и удалять плюсы перед стоп-словами.
- Wordstat Web-Assistant – инструмент помогает добавлять минус-слова.
- Wordstater – самая продвинутая надстройка Wordstat, в которой, помимо функций указанных выше расширений, можно комбинировать ключевики, добавлять UTM-метки, прогнозировать бюджет работы с Яндекс.Директом, проводить парсинг частоты запросов и т.д.
Выгрузка данных с этими инструментами занимает в разы меньше времени, нежели ручное копирование отдельных строк.
Использование парсеров
Подбирать ключевые слова вручную – не всегда эффективно. По оценкам специалистов, используя базовые функции, можно собрать не более 40% фраз. Кроме того, несмотря на множество возможностей Вордстат, у сервиса есть ряд проблем. Одна из наиболее весомых – ограничение длины запроса в 8 слов.
Улучшить работу с платформой поможет парсинг запросов с помощью специализированных программ, например:
- KeyCollector.
- Магадан.
- YandexKeyParser.
- AllSubmitter.
Сервисы позволяют преодолеть ограничения по длине, провести парсинг частотности Wordstat, автоматизировать работу и собрать более точные данные для дальнейших рекламных кампаний.
Заключение
Используя инструкции и сервисы из этой статьи, вы сможете упростить свою работу с инструментом подбора ключевых слов от Яндекса, правильно собрать семантическое ядро и составить точные прогнозы для SEO. О том, как работать с запросами в поисковых системах, читайте и другие статьи в нашем блоге.
Полное руководство по работе с Яндекс.Wordstat
Разбираемся, что представляет собой Яндекс.Вордстат и как им правильно пользоваться. Цели статьи – узнать предназначение сервиса, выяснить, как работают операторы, и понять, как добывать из Wordstat только полезные данные.
Что такое Яндекс.Вордстат
Речь идет о сервисе компании Яндекс, предоставляющем доступ к статистическим данным из одноименной поисковой службы. Wordstat показывает, что ищут люди в сети.
- Сервис отображает популярность выбранного запроса (он указывается в поисковой строке Wordstat).
- Дает четкое понимание сезонности выбранных запросов.
- Показывает географию спроса на те или иные услуги.
- Показывает техническое оснащение пользователей, выполняющих запрос в сети.
- Отображает долгосрочные тренды в интернете.
- Помогает лучше понимать целевую аудиторию.
Эти данные дают возможность настроить рекламную кампанию, ориентируясь на количество запросов.
Для работы с Яндекс.Вордстат нужен аккаунт в Яндексе (профиль в Метрике или Директе необязателен).
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Зачем обучаться работе с Wordstat?
Яндекс.Вордстат – это удобный инструмент, который почему-то игнорируют многие предприниматели, хотя как раз таки им он может заметно помочь.
- Если вы бизнесмен, то изучение Wordstat поможет лучше понять работу вашего SEO-специалиста и общее направление продвижения бренда. Это еще одна степень контроля, которая точно не помешает при работе с людьми по найму.
- Если вы маркетолог, разбирающийся в теме, то можете проследить количество специфичных запросов (с какой-то узконаправленной терминологией, например) и построить семантическое ядро (вкупе со всей рекламной кампанией) на их базе, избавившись по пути от кучи конкурентов.
Ну а для всех остальных Яндекс.Вордстат остается удобным способом отслеживать статистику запросов. Главное, делать это с умом. А для этого нужно хорошо понимать принципы работы Wordstat.
Как работать с Яндекс.Вордстат?
Интерфейс Wordstat не отличается сложностью. В нем можно разобраться самостоятельно, но есть ряд нюансов.
- С ходу трудно сказать, как вообще пользоваться сервисом. На главной странице нет никаких явных подсказок. Такая неочевидность повышает порог вхождения для новичков в SEO.
- Для наиболее эффективного взаимодействия с сервисом придется выучить поисковые операторы. У них тоже есть свои особенности, и далее мы их подробно рассмотрим.
- Умение управлять инструментом не делает из человека специалиста в области работы с информацией. А умение обрабатывать данные в нашем случае критически важно (важнее умения искать ее).
По ходу статьи мы «устраним » все сложности, мешающие работе с Яндекс.Вордстатом, и рассмотрим другие детали, связанные с работой сервиса и помогающие отыскать подходящую нишу, оценить ее популярность и шансы на успех при попытке монетизировать выбранное направление.
Знакомимся с интерфейсом
Первое, что увидит пользователь, посетив сайт Яндекс.Вордстата, – поисковую строку с небольшим набором настроек и кнопку «Подобрать». Это все, с чем нам придется работать. Здесь же отображается краткая справка по работе с сервисом и в общих чертах описывается логика отображаемых данных.
Первое, что нужно сделать, – ввести фразу, которую вы хотите использовать в качестве ключевого запроса для поисковых служб. Например «электрогитара» или «андроид смартфон». После этого на экране отобразится список запросов и их вариаций в левой колонке, а также схожие ключевые фразы в правой колонке.
Первый запрос в левой колонке содержит в себе все последующие. То есть расширенные ключевые слова под основным – это не дополнительные запросы, а вложенные. Это значит, что «семиструнная электрогитара» с 416 показами включает в себя «семиструнная гитара купить» с 91 показом из вышеназванных 416.
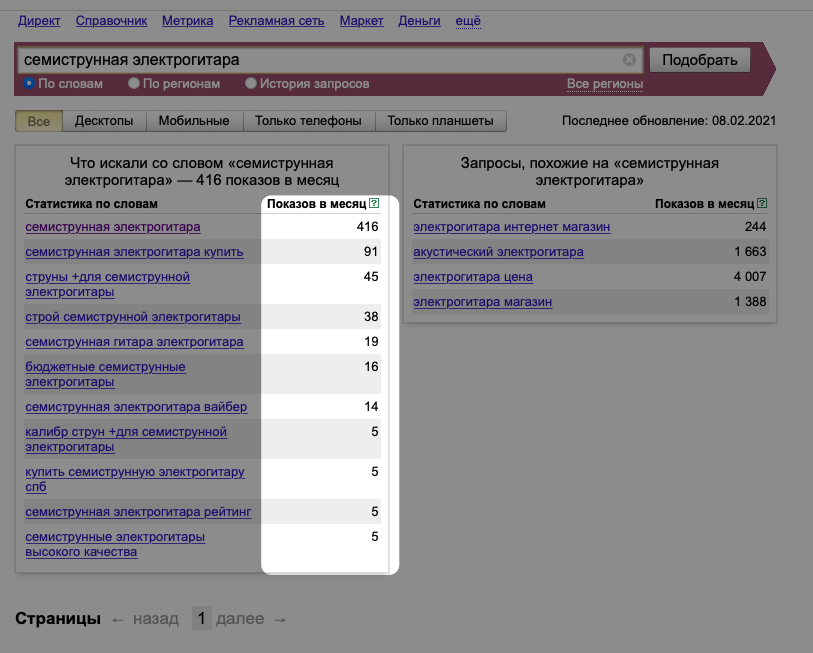
Не нужно складывать «ключи» друг с другом, так как получится некорректный расчет. Сами показатели условны. Это не точная статистика, а лишь прогноз на количество показов по выбранному ключевому слову.
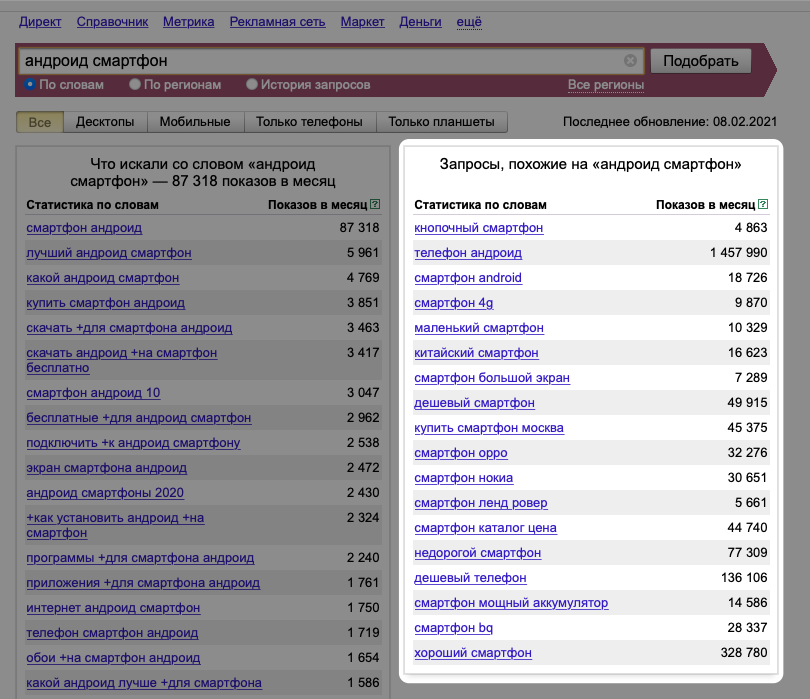
В правой колонке отображаются отдельные запросы. Они независимы друг от друга и показывают количество вхождений только для самих себя. Без вложенных «ключей».
Изучаем поисковые операторы
Запросы в Яндекс.Вордстате можно дополнительно настроить с помощью специальных символов. Их ставят перед словом или фразой для выполнения какого-то условия. Соответственно, у каждого символа есть свое предназначение и выполняемое условие.
- + – этот символ обязывает систему Wordstat учитывать слово при поиске. По умолчанию некоторые слова русского языка игнорируются. Это касается предлогов и следующих союзов: в, на, от, для, как, из, и, от.
- ! – этот символ запрещает Яндекс.Вордстату корректировать словоформу. То есть поиск будет учитывать исключительно ключевые слова с выбранным окончанием, числом, родом и т.п. Его рекомендуют использовать оптовикам, чтобы точно учитывать запросы на покупку большого количества товаров.
- «» – кавычки выводят статистику по выделенному слову или фразе в отдельное окно, чтобы можно было оценить количество запросов без вложенных «ключей». То есть увидеть запрос «купить электрогитару» без «купить электрогитару Ibanez» и других вариаций, которые учитываются в первом значении левого столбца Яндекс.Вордстата.
- [] – этим символом можно зафиксировать используемый в запросе порядок слов. Этим пользуются туристические фирмы и авиакомпании, чтобы предлагать клиентам билеты в точных (а не в похожих) направлениях.
- ( | ) – в скобки можно занести 2 или больше похожих слов. К примеру, если вы продаете товары сразу из двух стран, можно занести их в скобки и посмотреть статистику сразу по двум категориям запросов.
Удаление ненужных слов из запросов (оператор «минус»)
Еще один оператор выделим в отдельную категорию. Он позволяет более адекватно оценивать перспективность выбранной ниши за счет исключения из ключевой фразы всех лишних составляющих, способных повлиять на результат.

Допустим, вы хотите разыскать клиентов по запросу «электрогитара», так как занимаетесь их продажей. Но по такому запросу ищут не только гитары для покупки. Сюда входят:
- обучающие видео и другие формы уроков игры на гитаре;
- популярные выступления на этом инструменте;
- табулатуры, аккорды и ноты для исполнения популярных гитарных композиций;
- странные запросы в духе «электрогитары скачать»;
- поиск Б/У-товаров, что в случае с официальным магазином моментально делает запрос нерелевантным.
Куча «мусора», а нам нужны более конкретные запросы. Поэтому при поиске важно не только включить все необходимые «ключи» в нужной форме, но и исключить все лишние, чтобы не быть обманутым завышенными показателями.
Собираем данные по регионам
Эта опция важна для локального бизнеса. Нужно ориентироваться на клиентов из конкретного региона, поэтому брать статистику запросов по всей стране нет смысла, если продавать свои услуги вы собираетесь только в условном Саранске.
Чтобы увидеть количество запросов в отсортированном по зонам виде, нужно кликнуть по соответствующему фильтру рядом с поисковой строкой.
Процентное соотношение в этом интерфейсе говорит о среднестатистической популярности ключевой фразы. За 100% берется среднее количество выбранных поисковых запросов в регионе. Если это значение выше 100%, значит, популярность «ключа» выше среднего. Если меньше, то наоборот. Но помимо процентного соотношения важно ориентироваться на общее число потенциальных покупателей и население региона.
Для онлайн-магазинов и информационных ресурсов региональный фильтр не так важен. Первые могут продавать товары по всей стране и ориентироваться на общее число поисковых запросов. Вторые могут создавать полезные материалы для людей из соседних регионов, повышая популярность собственного бренда по стране.
Выясняем, как угодить в тренды
Это важный момент, потому что Wordstat не показывает актуальную информацию. Чтобы хоть как-то состыковаться с последними тенденциями, нужно брать в расчет статистику запросов за несколько лет. И это касается только регулярного повышения популярности запросов. Например, повышенный спрос на цветы и разного рода подарки перед 8 марта и в саму дату. Событие произойдет, а в Яндекс.Вордстате информация появится только через пару недель.
Поэтому ориентироваться стоит только на регулярные тренды. В их числе праздники (повышенный спрос на подарки определенной тематики), распространенные сезонные активности (отпуск зимой и летом), постоянное актуальные запросы (аренда жилья) и т.п. А еще стоит обратить внимание на поисковые подсказки. Можно открыть тот же Яндекс и ввести туда «ключ». Вместе с «ключом» появится целый список дополнительных запросов. По ним можно сориентироваться и понять, что сейчас популярно, а что не особо.
Не стоит забывать, что умение прогнозировать и создавать страницы под естественные запросы клиентов куда важнее, чем пытаться «взлететь» на неперспективном тренде, который создает много шума в информационном поле, но однозначно исчезнет в ближайшем будущем.
Разница между коммерческими и информационными запросами
Хотелось бы затронуть эту тему в отдельном блоке. Существует принципиальная разница между запросами: «Android смартфон» и «Android смартфон купить». Да, ни один из них не гарантирует продажи, но у второго шансов на конверсию больше.
Такие запросы, как второй, называются коммерческими. Они включают в себя слова, связанные с покупкой товара. То есть такие, как: купить, сколько стоит, цена, с доставкой и т.п. А еще к коммерческим запросам относят ключевые фразы с названиями населенных пунктов. К примеру:
- «Купить Android смартфон с доставкой»,
- «Сколько стоит Android смартфон в Нижневартовске».
Запрос в духе «Телевизор» считается информационным. В нем не прослеживается интенция что-либо купить, но поисковики часто отображают на первых позициях именно магазины с соответствующим товаром. Поэтому работать с такими ключевыми фразами нужно осторожно. Если же в запросе есть фразы типа «своими руками», то она моментально делает «ключ» бесполезным – по нему точно ничего не удастся продать.
Возможные проблемы при работе с Яндекс.Вордстат
У системы есть недостатки. С чем придется вам столкнуться:
- Зачастую даже половина найденных показов на деле не приносит пользы, потому что содержит вложенные запросы. Если не отсечь лишнее, то статистика будет некорректной.
- Яндекс.Вордстат не дает актуальной информации, только статистику за последние 30 дней.
- Система не воспринимает «ключи», состоящие из более чем 8 слов.
- Пользователи часто вводят запросы, используя синонимы. Поэтому они могут искать один и тот же товар или услугу, но используя десяток разных слов и их форм.
- Яндексом пользуется около половины жителей страны, поэтому реальная статистика может отличаться вдвое. С мобильными устройствами ситуациями аналогичная. В России преобладает Андроид с предустановленными сервисами Google.
Пример использования Wordstat
Вернемся к примеру с теми же гитарами. Можно создать 200 с лишним лендингов под все услуги вашего магазина. Берем запрос «электрогитара» и идем по списку:
- « Купить электрогитару » (каталог+описываем преимущества магазина),
- « Настройка электрогитары » (полезный пост в блоге и ссылка на магазин),
- « Лучшие электрогитары » (можно сделать топ с ссылками на инструменты в нашем магазине).
И таких вариаций много. Все популярные запросы можно проследить в Яндекс.Вордстат и использовать для развития проекта, ориентируясь на темы, которые интересуют пользователей.
Дополнительное программное обеспечение
Чтобы упростить работу с Яндекс.Вордстат, можно использовать сторонние дополнения для браузеров. Рассмотрим два наиболее популярных.
Ассистент Яндекс.Вордстат
Это небольшое расширение, позволяющее собирать подходящие запросы в отдельную группу с последующим ее использованием в других приложениях. После установки Ассистента на сайте Яндекс.Вордстат появляется кнопка « + » рядом с каждым «ключом». Нажатие по нему добавляет текст запроса и частоту его использования в панель Ассистента.
Yandex.Wordstat Helper
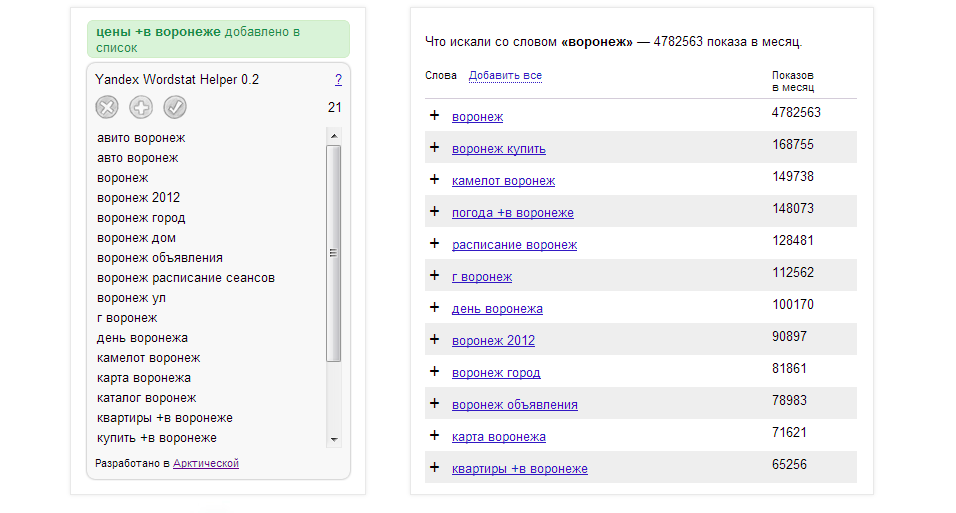
Расширение для браузеров Firefox и Google Chrome, выполняющее схожую с Ассистентом функцию, но немного быстрее. Интерфейс почти не отличается. Преимущество расширения – наличие большего количества категорий, по которым можно сортировать объекты, добавленные в интерфейс расширения.
Вместо заключения
Итак, работая с Wordstat, делаем следующее:
- В первую очередь обращаем внимание на коммерческие запросы со словами «купить».
- Учитываем регион поиска и особенности целевой аудитории.
- Пользуйтесь «минусами» при анализе любых ключевых фраз.
- Сужайте аудиторию за счет использования специфичных терминов.
Описанной информации хватит, чтобы собрать данные из Яндекс.Вордстат и скорректировать SEO-параметры для более эффективного продвижения ресурса.
Как выгрузить из яндекс вордстат в парсере
Что такое Яндекс Вордстат и как им правильно пользоваться
Как производится подбор статистики по запросам и парсинг ключевых слов в Яндекс Вордстат (Wordstat)? Как с ним работать? Как собрать семантическое ядро сайта через данный парсер? И что такое операторы: плюс, минус, восклицательный знак, кавычки и скобки? Давайте сегодня разберем все эти вопросы.
- Онлайн Парсер Wordstat — что это и зачем он нужен
- Как работать с Вордстатом
- Как выгрузить слова из Вордстата в Эксель
- Что такое операторы
- Кавычки
- Восклицательный знак
- Квадратные скобки
- Плюс
- Минус
- Круглые скобочки
- Что такое десктопы
- Как производится массовая проверка частотности запросов
- Как убрать капчу
- Как посмотреть историю запросов
Онлайн Парсер Wordstat — что это и зачем он нужен
Вордстат — это сервис, рассчитанный для сбора статистики ключевых запросов по заданным городам и техническим устройствам, которые пользователи вбивают в поисковой строке Яндекса. Иными словами, с помощью данного парсера вы получаете сведения о базовой или точной частности, а также количестве слов по необходимой теме.
На сегодняшний день Wordstat является очень полезным инструментом в услугах по SEO-оптимизации сайта или его конкретной страницы. Помимо этого, с помощью данного сервиса вы сможете провести анализ любой интересующей вас отрасли и более детально понять насколько она популярна среди других пользователей. Разумеется, SEO-специалисты пользуются множеством других сервисов помимо него, но, в большинстве случаев, первичный анализ по предоставленной информации от клиента, начинается именно с этого парсера. Конечно Вордстат — это не совсем парсер, так как, он является внутренним сервисом Яндекса, который предоставляет сведения о количестве запросов пользователей в самой поисковой системе.
Базовая частотность — это общая информация, которую вы получаете, когда пишите запрос в Вордстате без синтаксиса, склонения и точной словоформы. Она демонстрирует общее число всех слов или словосочетаний, в которых присутствуют фразы, входящие в данный запрос в любых словоформах и очереди.
Точная частотность — это число обращений человека с определенным словом или словосочетанием к поисковой системе в период 30 дней.
Помимо этого, используя Вордстат, вы можете без труда определить сезонность и региональность ключевых слов. В принципе, вот такой незамысловатый сервис. Давайте теперь рассмотрим детали того, как пользоваться Wordstat.
Как работать с Вордстатом
Как же осуществляется проверка частотности ключевых слов в Вордстате? Для начала давайте начнем с простого и понятного примера.
Перед тем, как начать работу в данном сервисе вам необходимо в нем зарегистрироваться (то есть иметь аккаунт в Яндексе).
Регистрация в Вордстате
Затем можете «вбивать» запрос, который вас интересует в поисковую строку. Для того, чтобы рассмотреть функционал сервиса, давайте возьмем часто задаваемый вопрос пользователей: «ремонт телефонов».
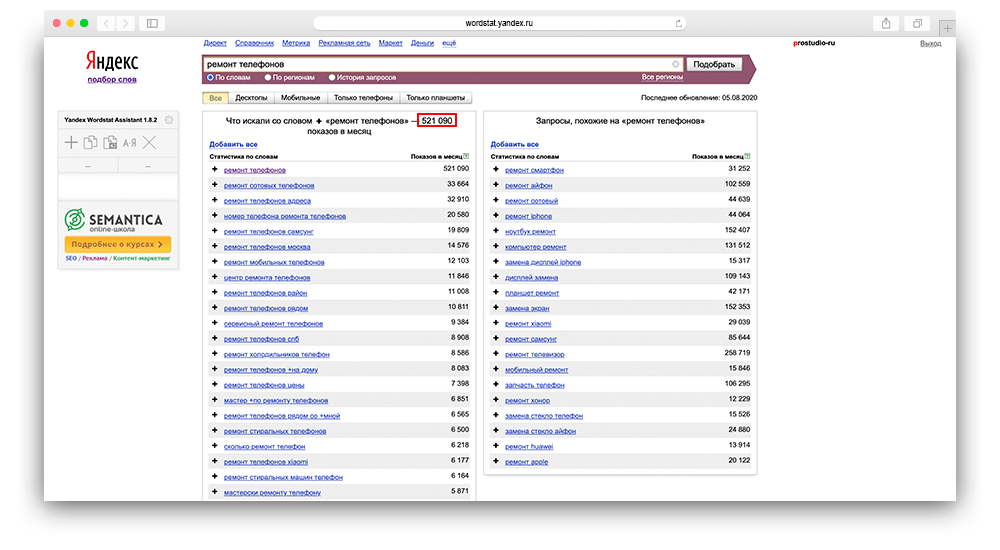
Как работать с Вордстатом
Как вы могли заметить, выдача разделяется на 2 колонки:
- Левая колонка — демонстрируется вся статистика по словам, которые вбивают в связке с «ремонт телефонов». Следовательно, цифра, которая показывает частотность запроса, не относится непосредственно к двум искомым словам, а демонстрирует общее количество запросов, подсчитывая все нижеуказанные словоформы, расположенные под данным словосочетанием. Для сбора точной частотности необходимо использовать вспомогательные операторы.
- Правая колонка — отображаются схожие смысловые запросы с указанной тематикой. У вас может возникнуть вполне логичный вопрос: «Каким образом система определяет аналогичность запросов?». Не вдаваясь в подробности, выглядит это так: Wordstat собирает всю информацию о каждом пользователе: какие запросы он вбивал и в какой период времени, а затем, проводит некий анализ, сопоставляя схожие запросы друг с другом у большинства пользователей за последние 30 дней. Пример: в период 30-и дней 100 человек запросило: «разработка интернет магазина». Из них 40 человек запросило: «продвижение сайта». В следствии чего, система отслеживает одинаковые запросы у одних и тех же пользователей и генерирует готовое решение в правую колонку подсказок.
Как выгрузить слова из Вордстата в Эксель
Здесь все очень просто. Вам необходимо:
- Установить специальное расширение для браузера.
- На странице Wordstat, в левом углу у вас появится окно.
- Затем вводите необходимый запрос.
- Напротив каждого слова или словосочетания, полученных в выдаче, вы увидите иконку «+».
- Вам нужно нажимать на «+», расположенный около каждого интересующего вас запроса, таким образом данные слова будут попадать в окно.
- В верху окна находятся две иконки — скопировать с частотностью и без нее.
- Выберите нужный вам способ копирования, затем вставьте в Эксель.
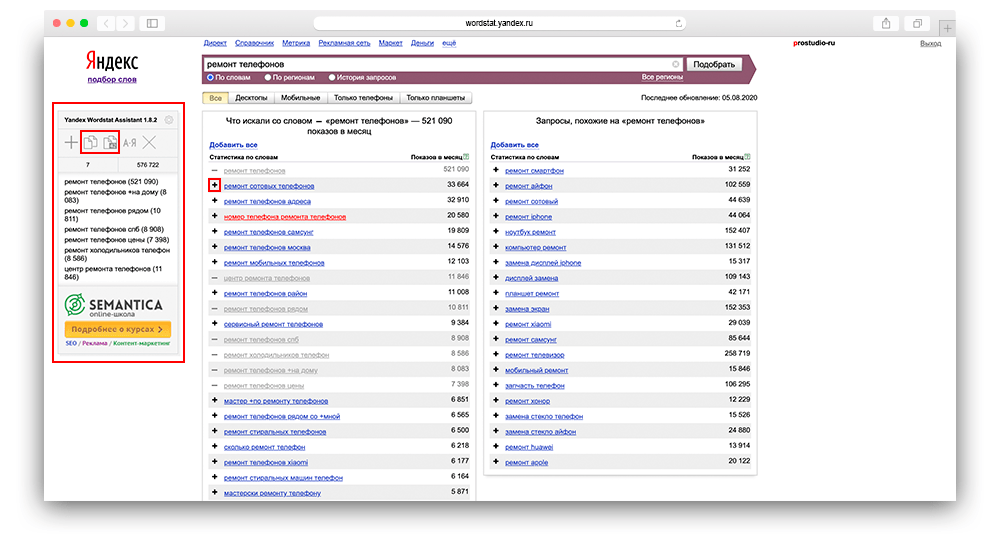
Как выгрузить слова из Водстата в Эксель
Разумеется, вы можете просто их копировать без вспомогательных сервисов, однако у вас уйдет на это чуть больше времени. Разобравшись с базовым функционалом данного сервиса, давайте рассмотрим, как правильно осуществлять подбор ключевых слов для точного вхождения по поисковой фразе.
Что такое операторы
Для уточнения информации по результатам выдачи ключевых слов, необходимо понять, что такое операторы.
Операторы — это специализированные символы, являющие вспомогательным инструментом для определения точной частотности искомого запроса. Перечень операторов:
- кавычки;
- плюс;
- минус;
- восклицательный знак;
- круглые скобочки;
- квадратные скобки.
Кавычки
« » — с помощью данного оператора, вы получите сведения именно о том количестве слов, сколько вписывали в запрос без дополнительных словоформ. То есть, если вы написали: «ремонт телефонов», то информации по: «ремонт мобильных телефонов» не будет. Но данный оператор не фиксирует словосочетание, от склонений, множественной и единственной формы. То есть, вам будут демонстрироваться сведения по: «ремонту телефонов»; «телефонов ремонт» и так далее.
Пример использования: «ремонт телефонов».
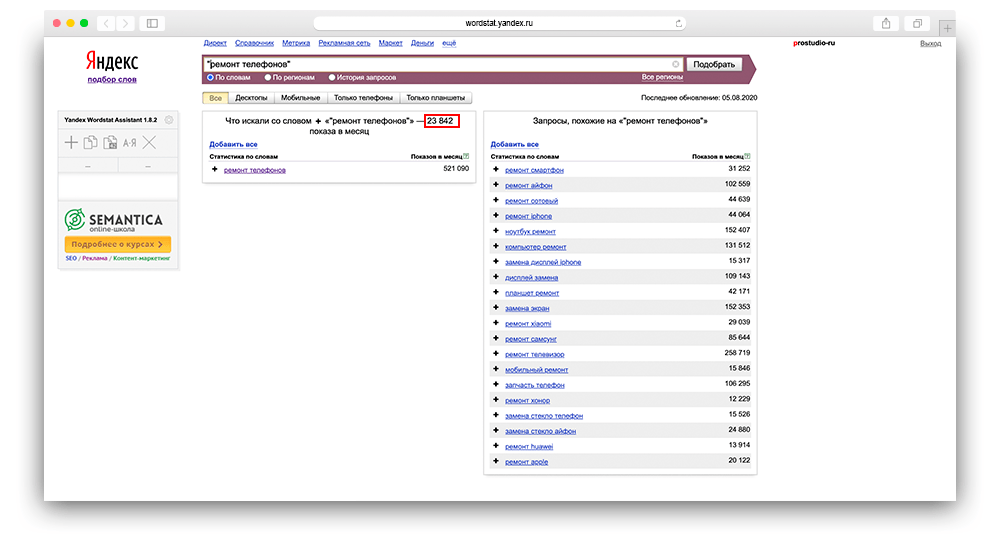
Вордстат — слова в кавычках
Восклицательный знак
! — определяет форму запроса. Другими словами, вы получите точную информацию именно о словосочетании: «ремонт телефонов», без склонения, падежа, числа и времени, таких как: «ремонту телефонов»; «ремонта телефонам» и так далее. Также нельзя забывать о том, что восклицательный знак должен ставиться перед каждым словом, без отступов.
Пример использования: !ремонт !телефонов.

Вордстат — восклицательный знак перед словом
Квадратные скобки
[ ] — показывает порядок слов в запросе. Этот оператор актуально использовать для изучения запросов в отношении билетов из одного города в другой. Например, если вы хотите узнать количество людей, которым интересно путешествие из Санкт-Петербурга в Москву, а не наоборот, то данный оператор вам окажет помощь в этом. Так как, количество запросов «билеты Санкт-Петербург — Москва» составляет 5 916 за последние 30 дней, а: «билеты Москва — Санкт-Петербург» составляет 14 528 за последние 30 дней. Следовательно, как вы сами могли заметить показатели сильно разнятся и без данного уточнения, вы получили бы в корне не верные цифры по искомому запросу. Возвращаясь к примеру: «ремонт телефонов», с помощью этого оператора, вы сможете понять порядок слов и более детально провести анализ запросов в данной области, для дальнейшего формирования рекламного объявления или составления заголовков на продающей странице.
Парсинг Яндекс Вордстат: что это и для чего?
Яндекс Вордстат – это один из базовых сервисов для SEO-оптимизаторов, работающих в Рунете. Штатный инструмент системы позволяет искать ключевые фразы из поисковой выдачи – высоко-, средне- и низкочастотные — используя для этого операторы для повышения эффективности поиска и настройку геолокации. В среде оптимизаторов процесс сбора ключевых запросов, релевантных тематике сайта, называется парсингом.
Специалисты проводят парсинг Яндекс, чтобы сформировать семантическое ядро – лингвистический «костяк» для будущего контента, который наиболее точно отражает нишу или услугу, которую предлагает сайт. Для этого есть собственный инструмент для поиска в Яндексе — Yandex Wordstat Assistant, который можно бесплатно привязать к аккаунту. С его помощью удобно собирать и выгружать собранные ключевые слова в таблицу Excel.
Вы можете пользоваться этим инструментом, но только в том случае, если у вас относительно небольшой сайт, где семантическое ядро составляет не более тысячи запросов. Если объем работы по сбору семантического ядра гораздо больше (например, для интернет-магазина с множеством товаров), то парсить выдачу Яндекса вручную с помощью Wordstat Assistant будет неоправданно долго. Целесообразнее делать это с помощью специальных программ и онлайн-сервисов – бесплатных, условно бесплатных и платных (например, Key Collector).
Рассмотрим основные принципы работы с Вордстат, а также популярные средства для автоматического сбора поисковых запросов.
Как правильно парсить в Вордстат: обзор программ для анализа поисковой выдачи
Парсинг выдачи Яндекса – это процесс сбора поисковых запросов по заданной тематике (с помощью базовых маркеров). С Yandex Wordstat Assistant можно легко получить основную информацию для формирования семантического ядра – поисковые запросы, количество показов в месяц по каждой фразе, а также схожие по тематике слова, помогающие расширить охват целевой аудитории. Парсер Wordstat позволяет получить информацию по словам и по регионам, при этом система ориентируется именно на сайты.
Если хотите выполнить расширенный поиск, включающий не только Яндекс, но и социальные сети и другие поисковые системы, необходимо воспользоваться универсальными инструментами, например, A-Parser. Этот программный продукт отличается удобством в работе, но для эффективной работы с ним нужно купить прокси для парсинга.
В какой среде бы Вы ни работали, используйте универсальную схему сбора семантического ядра:
- формирование базового списка маркеров (запросов, однозначно релевантных сайту);
- сбор ключевых слов;
- удаление «мусора» — ненужных и случайно попавших в список запросов;
- кластеризация ключевиков по разделам сайта или тематикам.
Рассматриваем основной алгоритм работы с Вордстат и парсим Яндекс для сбора семантики на примере сайта агентства недвижимости. Допустим, нам нужно составить перечень релевантных ключевых запросов, соответствующих базовому маркеру «аренда квартир».
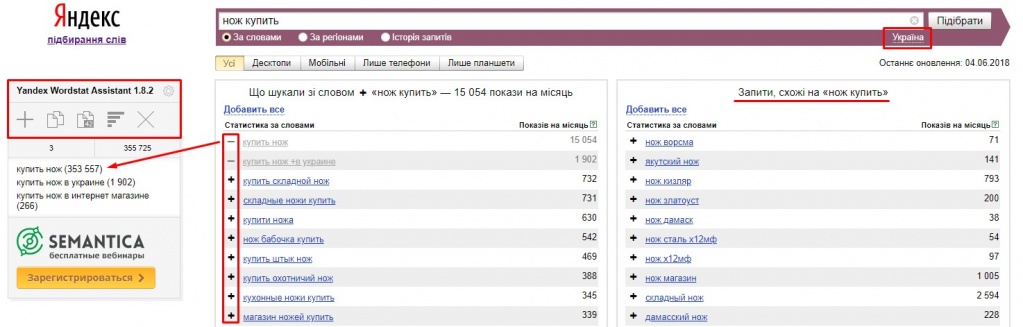
- Вводим базовый маркер в поисковую строку Яндекс Вордстат.
- При необходимости устанавливаем регион для более точного отбора запросов (например, Москва или Санкт-Петербург).
- В полученных результатах поиска используем значок «+» для выгрузки в таблицу Excel.
- Выгружаем полученные данные через буфер обмена (инструмент «A-Z»).
Совет! Обращайте внимание на подсказки типа «вместе с этим ищут» в соседнем поле выдачи результатов парсинга – это поможет вам охватить больше аудитории при составлении SEO-контента.
Чтобы облегчить себе задачу по ручному парсингу, используйте операторы Яндекс. Например, поставив в конце поисковой фразы знак «!», вы зафиксируете окончание поискового запроса, и система будет искать слова именно в этой словоформе. Оператор «-» (минус) позволит убрать лишние слова, а квадратные скобки «[ ]» — зафиксировать порядок слов в запросе.
Советы и рекомендации по использованию программ для парсинга
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).
Среди других полезных сервисов для SEO такие:
- Serpstat – многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs – веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор – это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс – она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс – бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Автоматический сбор Яндекс Wordstat. Парсинг Яндекс Вордстат: что это и для чего? Парсер запросов яндекс
Если у вас крупный проект с семантическим ядром на несколько сотен или тысяч запросов, согласитесь, сидеть в Вордстате и подбирать их вручную покажется изощрённой пыткой. Хорошо, что существуют программы-помощники, способные взять основную часть рутинной работы на себя. Одна из таких программ называется Словоёб.
Что такое Словоёб
Словоёб (Slovoeb) – бесплатная (и значительно урезанная по функционалу) версия программы , полюбившейся профессиональным оптимизаторам. Большинство функций КейКоллетора обычному пользователю вряд ли понадобится, поэтому можно обойтись Словоёбом для решения главной задачи – подбора ключевых слов.
Кстати, платный KeyCollector позволяет парсить слова и из Google AdWords – это особенно полезно, если ваш сайт ориентирован в первую очередь на страны, где основной трафик даёт именно Гугл. Бесплатный Slovoeb ограничен только Яндексом.
Для начала нужно скачать программу Словоёб. Сделать это можно по ссылке в блоге SEOM.info .
Программа не требует установки. Просто распакуйте архив в любое удобное место на компьютере и запустите Slovoeb.exe. В дальнейшем все ваши настройки будут храниться в выбранной папке. Перед началом работы не забудьте прочитать материал о – информация в статье актуальна и для этой программы.
Настройка Slovoeb
Вот что мы увидим после запуска:
Прежде чем приступить к работе, необходимо выполнить ряд настроек. Первое – указать аккаунты Яндекса для парсинга ключевых слов. Напоминаю, что работать в Вордстате можно только после авторизации. Поэтому советую , штук пять аккаунтов, специально предназначенных для Словоёба. Не используйте спецсимволы в паролях этих аккаунтов!
Не советую использовать свой настоящий аккаунт, так как программа делает очень много запросов к Яндексу за единицу времени, за что можно получить санкции.
Нажмите на значок шестерёнки в верхней левой части окна программы и перейдите в настройки.
Выберите вкладку Yandex.Direct и введите данные аккаунтов в формате логин:пароль . По желанию можно указать и прокси. Обязательно прочтите памятку в окне настроек!

Советую изучить и изменить другие настройки софта.
Автоматическое распознавание капчи
Следующим шагом является автоматизация распознавания капчи. Согласитесь, какой смысл в программе, если она каждый раз требует от вас вручную вводить капчу, выдаваемую Яндексом. Так как Словоёб будет много раз отправлять запросы к Яндексу за короткий промежуток времени, капчи неизбежны.
Я пользуюсь сервисом Antigate . По желанию вы можете воспользоваться и другими программами. Slovoeb поддерживает следующие:
О многих из них я прежде никогда не слышал.
В случае с Антигейтом есть нюанс: они переехали на новый сайт (хотя старый всё ещё доступен). Они используют общую базу, поэтому на обоих сайтах единый аккаунт. На каком регистрироваться – решать вам. Первый более классический, спартанский, более привычный для веб-мастеров со стажем. Второй же более современный.
Учтите, что Antigate платный. Но недорогой. Мне хватает 1 доллара на 2 месяца работы (а то и больше).
Перейдите на страницу настроек антикапчи, щёлкнув по вкладке в левой части окна настроек.
В поле Antigate Key введите ваш ключ антикапчи. Получить его можно в настройках профиля Antigate.

На этом базовая настройка Словоёба завершена.
Подбор ключевых слов с помощью Словоёб
Пора приступить непосредственно к подбору запросов. Для этого нужно создать новый проект. Все его данные сохранятся в файл. Таких файлов может быть неограниченное количество, так что вы легко сможете переключаться между проектами.
Нажмите на кнопку “Создать проект”:
В открывшемся окне выберите, куда сохранить файл и как его назвать. Я обычно называю файлы по имени сайта и сохраняю в папку проекта (там, где лежат все остальные данные по нему). Кто-то держит все файлы Словоёба в единой папке. Кому как удобнее.
Следующий шаг после создания проекта – настройка региона. Если ваш сайт ориентирован только на определённый регион (или регионы), вам нужна статистика поисковых запросов именно по нему, а не по всему миру. Нажмите на кнопку выбора региона и установите нужные вам галочки.
Здесь всё так же, как в интерфейсе Вордстата:

Настало время подбора ключевых слов!
Для начала подбора запросов кликните по кнопке “Пакетный сбор запросов из левой колонки Yandex.Wordstat “, как показано на скриншоте.
В открывшемся окне введите ключевые слова, на основе которых вы хотите подобрать запросы. Всё точно так же, как в интерфейсе Вордстата. Главное отличие – в программе вы можете ввести сразу несколько слов, и программа будет работать с ними по очереди, а в Вордстате нужно работать с каждым словом по очереди, вручную, что значительно увеличивает время работы.

Нажмите на кнопку “Начать сбор “. Ура, теперь можно пойти сделать кофе или переключиться на другие задачи. Словоёбу понадобится время, чтобы собрать запросы.
Стоп-слова
После того как программа отпарсила ключевые слова, необходимо отфильтровать их, отбросив не интересующие нас сочетания и формулировки. Это можно сделать с помощью стоп-слов. Нажмите на большую кнопку “Стоп-слова ” с изображением щита. В открывшемся окне кликните по кнопке “Добавить списком “. В ещё одном открывшемся окне перечислите стоп-слова (каждое с новой строчки), которых не должно быть в вашем поисковом запросе. Например, нас не интересуют запросы со словами “скачать”, “торрент”, “новая версия”, “последняя версия” и т. д., так как мы распространяем не саму программу, а только её описание.
После введения стоп-слов нажмите на кнопку “Отметить фразы в таблице ” в левом нижнем углу окна стоп-слов.
Работа с частотностью в Словоёб
Остался один нюанс: частотность запросов, отображаемая в колонке, – это базовая частотность, то есть фраза со всеми словоформами. Чтобы определить частотности с помощью операторов, кликните по кнопке с изображением лупы и выберите пункт “Собрать частотности вида ” ” “.
Яндекс Вордстат — это один из базовых сервисов для SEO-оптимизаторов, работающих в Рунете. Штатный инструмент системы позволяет искать ключевые фразы из поисковой выдачи — высоко-, средне- и низкочастотные — используя для этого операторы для повышения эффективности поиска и настройку геолокации. В среде оптимизаторов процесс сбора ключевых запросов, релевантных тематике сайта, называется парсингом.
Специалисты проводят парсинг Яндекс, чтобы сформировать семантическое ядро — лингвистический «костяк» для будущего контента, который наиболее точно отражает нишу или услугу, которую предлагает сайт. Для этого есть собственный инструмент для поиска в Яндексе — Yandex Wordstat Assistant, который можно бесплатно привязать к аккаунту. С его помощью удобно собирать и выгружать собранные ключевые слова в таблицу Excel.
Вы можете пользоваться этим инструментом, но только в том случае, если у вас относительно небольшой сайт, где семантическое ядро составляет не более тысячи запросов. Если объем работы по сбору семантического ядра гораздо больше (например, для интернет-магазина с множеством товаров), то парсить выдачу Яндекса вручную с помощью Wordstat Assistant будет неоправданно долго. Целесообразнее делать это с помощью специальных программ и онлайн-сервисов — бесплатных, условно бесплатных и платных (например, Key Collector).
Рассмотрим основные принципы работы с Вордстат, а также популярные средства для автоматического сбора поисковых запросов.
Как правильно парсить в Вордстат: обзор программ для анализа поисковой выдачи
Парсинг выдачи Яндекса — это процесс сбора поисковых запросов по заданной тематике (с помощью базовых маркеров). С Yandex Wordstat Assistant можно легко получить основную информацию для формирования семантического ядра — поисковые запросы, количество показов в месяц по каждой фразе, а также схожие по тематике слова, помогающие расширить охват целевой аудитории. Парсер Wordstat позволяет получить информацию по словам и по регионам, при этом система ориентируется именно на сайты.
Если хотите выполнить расширенный поиск, включающий не только Яндекс, но и социальные сети и другие поисковые системы, необходимо воспользоваться универсальными инструментами, например, A-Parser. Этот программный продукт отличается удобством в работе, но для эффективной работы с ним нужно купить прокси для парсинга.
В какой среде бы Вы ни работали, используйте универсальную схему сбора семантического ядра:
- формирование базового списка маркеров (запросов, однозначно релевантных сайту);
- сбор ключевых слов;
- удаление «мусора» — ненужных и случайно попавших в список запросов;
- кластеризация ключевиков по разделам сайта или тематикам.
Рассматриваем основной алгоритм работы с Вордстат и парсим Яндекс для сбора семантики на примере сайта агентства недвижимости. Допустим, нам нужно составить перечень релевантных ключевых запросов, соответствующих базовому маркеру «аренда квартир».
Совет! Обращайте внимание на подсказки типа «вместе с этим ищут» в соседнем поле выдачи результатов парсинга — это поможет вам охватить больше аудитории при составлении SEO-контента.
Чтобы облегчить себе задачу по ручному парсингу, используйте операторы Яндекс. Например, поставив в конце поисковой фразы знак «!», вы зафиксируете окончание поискового запроса, и система будет искать слова именно в этой словоформе. Оператор «-» (минус) позволит убрать лишние слова, а квадратные скобки «» — зафиксировать порядок слов в запросе.
Специалисты советуют сочетать ручной и автоматический выбор запросов для составления семантического ядра, особенно для новичков. Пользуясь штатным инструментом Яндекс Вордстат Ассистент, вы нарабатываете навыки интуитивного подбора поисковых фраз, которые приводят на сайт целевых клиентов с помощью средне- и низкочастотных ключей. Высокочастотные фразы не всегда работают, особенно в конкурентной нише.
Если у вас нет времени на ручной парсинг в Яндекс Вордстат, используйте специальные инструменты. В интернете можно найти различное программное обеспечение, но большинство русскоязычных специалистов по SEO-оптимизации делают парсинг выдачи Яндекса с помощью Key Collector.
Это десктопный продукт, позволяющий создавать и хранить в локальной памяти компьютера проекты для каждого сайта, загружать и сохранять файлы и делать парсинг ключевых слов в соответствии с региональными настройками. Программа требует привязки к аккаунту. Для работы с ключевыми поисковыми запросами в Кей Коллекторе имеются пиктограммы основных поисковых систем в Рунете (в нашем случае это Yandex-парсер, хотя можно выбрать Google, Bing и другие).
Среди других полезных сервисов для SEO такие:
- Serpstat — многофункциональная платформа для профессионалов, имеющая триальную версию с ограниченным функционалом, а также платную подписку от 19 до 299$ в месяц;
- Ahrefs — веб-сервис с множеством полезных опций, включая мониторинг ниши, анализ конкурентов и улучшение индексации сайта. Для сбора семантического ядра предусмотрен инструмент Keywords Explorer. Протестировать его можно от 7$ в неделю;
- Semrush — аналог Ahrefs по части функционала, более дорогой по тарифам (от 99$ и выше).
Специалисты утверждают, что Кей Коллектор — это самая удобная и функциональная программа, позволяющая значительно облегчить жизнь оптимизатора. У нее есть множество полезных опций для точной настройки параметров парсера Yandex (например, глубины поиска, избирательного поиска запросов по базовой частотности и т.п.).
Но у программы есть нюанс — она платная. Стоимость лицензии составляет 1800-1900 рублей по электронному и безналичному расчету соответственно.
Совет! Если по какой-то причине вы не хотите пользоваться этим продуктом, можете попробовать его бесплатный аналог «Словоёб». Подойдет и более простой вариант — Букварикс — бесплатный сервис для сбора ключевых слов и формирования семантического ядра.
Парсинг Яндекс Вордстат можно делать самостоятельно и с помощью специальных программ. Ручной сбор посредством инструмента Wordstat Assistant оправдывает себя в том случае, если ваша ниша имеет узкую направленность и мало конкурентов, а перечень поисковых запросов относительно невелик. При больших объемах работ рекомендуется пользоваться специальными программами для парсинга и аналитики.
Один из наиболее популярных модулей в Rush Analytics – парсер Яндекс Вордстат, и это не случайно. При сборе семантического ядра необходимо точно знать частотность собранных запросов, чтобы правильно расставить приоритеты по продвижению и избавится от «мусорных» и нулевых запросов. Часто стоит задача пробить несколько десятков тысяч запросов на частотность в Яндексе, но это не совсем простая задача для самописных парсеров Вордстата и десктопных программ, и вот почему:
- Yandex Wordstat имеет хорошую защиту от парсинга, например бан IP-адресов с которых осуществляется парсинг и выбрасывание капчи в ответ на запросы от ботов. Чтобы эффективно собирать данные с Wordstat, нужен эффективный алгоритм подключения IP-адресов и другие хитрости
- Для парсинга большого количества данных с помощью десктопных программ понадобится много IP-адресов (прокси), которые Яндекс с легкостью банит при неоптимальном алгоритме подключения, а прокси – удовольствие недешевое
- Так же для парсинга понадобится автоматическое введение большого количества капчи (например подключение Antigate для этой задачи). Данный фактор, при неоптимальном алгоритме парсинга, может сделать сам парсинг нерентабельным, так как стоимость капчи будет чрезмерно высока
- Большинство десктопных программ не имеют защиты от потери данных при сборе. Так, например, собрав половину данных и потратив на это деньги, при сбое в парсере, вы рискуете не только не получить оставшиеся данные, но и потерять уже собранные
Парсинг Яндекс Вордстат в Rush Analytics
Учитывая все трудности которые могут возникнуть при парсинге Вордстата, мы сделали свой парсер Wordstat максимально быстрым, удобным и устойчивым к максимальному количеству проблем, связанных с парсингом:
- Никаких прокси и капчи! Вам больше не нужно думать о бане ваших прокси или огромном количестве капчи, которую выдает Яндекс. Просто создайте проект, загрузите ключевые слова и ждите готовый файл с результатом
- Высокая скорость парсинга. Наши алгоритмы используют оптимальную схему подключения IP-адресов и другие хитрости, чтобы сделать скорость парсинга феноменально высокой – вы и не заметите, как ваш проект будет выполнен!
- Сохранность данных. Создавая проект в нашем парсере, вы можете быть уверены, что он будет успешно завершен и доступен для скачивания в любое время и из любой точки мира – все данные хранятся в облаке!
- Поддержка всех регионов Яндекса. У многих пользователей есть потребность определять частотность запросов в Яндексе не только по региону «Москва» или «Россия», но и по другим, включая «Украину» и «Беларусь». В Rush Analytics вы сможете определить частотность запросов по любому региону, который поддерживает Яндекс на данный момент.
- Сбор всех частотностей. С помощью нашего парсера вы сможете собрать все частотности: поисковый запрос, «поисковый запрос», «!поисковый!запрос».
- Сбор левой колонки Wordstat. Помимо проверки частотности запросов, доступен сбор ключевых слов из левой колонки Wordstat с настройкой глубины парсинга от одной страницы до сбора всех имеющих в левой колонке страниц.
- Сбор правой колонки Wordstat. Доступен сбор ключевых слов из правой колонки Wordstat.
Если вам нужен скоростной сбор частотностей Яндекс Wordstat – Rush Analytics лучшее решение, особенно если вам нужно собирать большие объемы данных. Для пользователей с потребностью сбора боле 100 000 запросов в месяц предусмотрены индивидуальные условия, просто напишите в нашу поддержку на
Простой и бесплатный пример PHP парсера (parser) статистики ключевых слов с wordstat Яндекс.
Понятно, что перед тем как продвигать сайт, нужно определиться с ключевиками. это не сложный, но кропотливый труд. Для того же чтоб найти что-то стоящее, нужно перелопатить кучу данных. Поэтому здесь не обойтись без средств автоматизации процесса. В данной заметке я хочу остановиться на создании PHP парсера данных с wordstat Яндекс.
И так. Основная проблема при парсинге данных с сервиса статистики ключевых слов wordstat Яндекс заключается в наличии капчи. Обойти ее не так уж и сложно. Достаточно передать в запросе куку fuid01, генерируемую при обработки капчи. Другими словами, вам понадобится зайти на сервис, сделать запрос, указав символы с картинки и получить содержание требуемой куки.
Как получить содержание куки fuid01 в браузере Firefox?
Т.к. я не собираюсь замахиваться на эпосы и прочие великие труды человечества, то опишу лишь процесс получения содержания куки fuid01 в браузере Firefox (использую версию 8.0). В общем, запускаем Firefox. Считаем, что запрос в wordstat уже сделан и кука создана. Жмем кнопку «Firefox» в левом верхнем углу окна браузера. В меню выбираем: Настройки > Настройки (я ничего не путаю).

В открывшемся окне «Настройки», переходим на вкладку «Приватность». Здесь нас интересует блок «История». Выбираем в списке Firefox «будет использовать ваши настройки хранения истории» и жмем появившуюся кнопку «Показать куки…».

В окне «Куки», в поле «Поиск» введите имя интересующей нас куки, т.е. «fuid01». В списке должно отобразиться найденное. Выберите одну из предложенных кук и в поле информации, выделите и скопируйте ее «Содержимое».

Как работать с PHP парсером wordstat Яндекс
Бесплатно скачать PHP парсер wordstat Яндекс можно здесь . Сразу скажу, что это лишь пример, работа которого заключается в парсинге ключевых слов и выводе их на экран, но все по порядку.
Первое, что вам надо понять – все данные представлены в кодировке UTF-8. Так что если что не забудьте сконвертировать данные. Более того, на некоторых серверах с этим может возникнуть проблема, подробней . Следующий нюанс заключается в том, что для работы скрипта понадобится поддержка . В остальном все достаточно просто.
Содержание куки fuid01 мы присваиваем переменной $fuid01 . По сути, это значение задается в curl_setopt() через CURLOPT_COOKIE , но для удобства я вывел его отдельно. Далее нас интересует массив $params — это переменные, передаваемые в запросе к wordstat Яндекс. В качестве примера я ограничился простейшим вариантом, так что обошлось без динамики. В частности, парсится только первая страница выдачи: «page» => 1 , значение text получается через GET, ну а для региона выбрана Москва : «geo» => 1 .
Понятно, что идентификатор региона, в случае если нужен другой, придется уточнять. Для этого заходим на wordstat Яндекс, кликаем ссылку «Уточнить регион…» и выбираем требуемое.

Сделав запрос, в URL надо посмотреть значение требуемого параметра. Следует отметить, что если выбрано более одного региона, их идентификаторы будут перечислены через запятую.
Дальше идет запрос к сервису статистики и парсинг данных wordstat Яндекс. Последнее имеет один небольшой нюанс. Дело в том, что wordstat Яндекс выводит статистику в виде двух таблиц: «что искали со словом…» и «что еще искали люди, искавшие…» — я же использовал только первую. Впрочем, там нет ничего сложного. Регулярные выражения достаточно простые. Думаю, разберетесь. Удачи!
Парсер ключевых слов — это настройка Datacol, которая автоматически собирает запросы из статистики сервиса Wordstat по заданным пользователем ключевым словам. Таким образом, вам необходимо всего лишь задать базовые ключевые слова, после чего Datacol самостоятельно соберет информацию по производным запросам. Наряду с запросами сохраняется частота показов каждого запроса в месяц. При парсинге Datacol проходит по всем страницам выдачи Wordstat.
- С помощью парсера Wordstat Вы сможете собрать запросы и частоту показа из статистики;
- Вам нужно указать только список ключевых слов, данные по которым Вам необходимо собрать;
- Сохраняйте собранную информацию в любом удобном формате (Excel, TXT, WordPress, MySQL и т. д.).
Парсинг Wordstat подразумевает обработку Javascript, а также необходимость авторизации для сбора данных. Такую возможность мы получаем благодаря плагину . При запуске кампании Datacol откроет один или более экземпляров браузера Chrome для загрузки через них вебстраниц. Количество работающих экземпляров Chrome равно количеству потоков кампании. Обратите внимание, что инициализация экземпляров браузеров может занять некоторое время.
Кем и для чего используется парсер ключевых слов яндекса
Парсер ключевых слов чаще всего используется специалистами по поисковому продвижению сайтов. В частности, это касается реализации задачи составления семантического ядра сайта. Оговоримся, что ниже речь пойдет о продвижении сайтов в рунете. В данном контексте более актуален парсер ключевых слов яндекс директа.
Парсер поисковых запросов директа
Для начала опишем стандартную схему работы парсера директа.
1. Пользователь задает поисковые запросы, производные которых необходимо собрать.
2. Парсер авторизуется на яндексе и начинает парсить яндекс вордстат поочередно для каждого запроса.
3. Для каждого запроса получаются производные ключевые слова не только с первой страницы выдачи директа, но и со всех последующих.В результате на выходе мы имеем достаточно большое количество вариантов ключевых слов, которые в дальнейшем используются для формирования семантического ядра сайта.
Парсер ключевиков и количества показов — “скользкий момент”
Отметим, что помимо ключевых слов мы получаем так называемое “прогнозируемое количество показов” — показатель к которому стоит относиться очень осторожно. Для начала разберемся, что об этом значении пишет сам Яндекс:
В результатах выводится статистика запросов поисковой системы Яндекс, содержащих заданное слово или словосочетание, и других запросов, которые осуществляли искавшие его люди (справа).
Цифры рядом с каждым запросом в результатах выдачи вордстат дают предварительный прогноз числа показов в месяц, которое вы будете иметь, выбрав данный запрос в качестве ключевого слова.Ошибкой многих оптимизаторов является то, что они читают только первую часть описания, и при этом — читают не совсем внимательно. Идем дальше:
Цифра рядом со словом «телевизор» обозначает число показов по абсолютно всем запросам, включающим слово «телевизор»: «купить телевизор» , «плазменный телевизор», «купить плазменный телевизор», «купить новый плазменный телевизор» и т.п.
Вы уже наверное догадались, на что мы намекаем? Итак, вы должны понять главное — при парсинге производных запросов по Wordstat не стоит обращать внимание на показатель их частотности, поскольку данное значение суммируется из частотностей всех производных запросов.
Но как в таком случае определить какие ключевики более “жирные” а какие менее? Сразу развенчаем ошибочное мнение, что производные ключевики всегда имеют меньше реальных показов, что основные. Это откровенная чушь! Найти реальные количества показов ключевиков (с вычетом количества показов производных) нам позволит операторы кавычки. Таким образом, для поиска запросов и определения самых “жирных” необходимо применять следующую схему:
1. Запустить парсер ключей для поиска производных.
2. Взять все производные запросы и отпарсить количество показов каждого, задавая запрос в кавычках.Мы согласны, что это несколько более длинный и сложный путь. Однако представьте ситуацию. У вас есть около 500 запросов, по которым вы хотите продвинуть основной сайт. 30 из них являются (по вашему первоначальному мнению, то есть по изначально спарсенной статистике Wordstat) наиболее высокочастотными. Далее вы тратите 3 месяца времени и несколько тысяч убитых енотов (да ребята — качественное продвижение это дорогостоящее и длительное мероприятие) и в итоге оказывается, что поискового трафика в несколько раз меньше чем ожидалось. Вы сильно расстраиваетесь, ищите профессионального специалиста по продвижению и он вам открывает глаза на то, что вы продвигали совсем не те запросы, которые приводят трафик (в частности, он показывает вам реальную статистику по запросам в кавычках).
Тестирование парсера запросов
На нашем сайте вы можете бесплатно скачать парсер ключевых слов яндекса и протестировать его. Мы также можем обсудить настройку парсера кеев, которая будет проверять значения собранных запросов в кавычках.
Тестирование парсера Wordstat
Чтобы протестировать работу парсера Wordstat :
Шаг 1. Установите . Демо-версия программы имеет все возможности платной, но сохраняет только первые 25 результатов парсинга.
Шаг 2. В дереве кампаний присутствует кампания seo-parsers/wordstat-keywords-parser.par . Выберите ее и нажмите кнопку Запуск (Play) . Перед запуском можно отредактировать Входные данные , чтобы изменить набор базовых запросов , по которым будет собираться статистика.
кликните на изображении для увеличения
После запуска кампании открывается окно браузера, в которое необходимо ввести авторизационные данные для доступа к статистике Wordstat.
Автоматизация в сети
Всё для автоматизации в сети: парсеры, регеры, постеры, лайкеры. Готовые шаблоны для ZennoPoster. Шаблоны (боты) на заказ.
Быстрый способ выгрузить ключевые слова в excel из сервиса Wordstat
- Получить ссылку
- Электронная почта
- Другие приложения
Каким образом можно выгрузить ключевые слова
в excel из сервиса Wordstat ?
WordstatParser — бесплатный парсер + кластеризатор ключевых слов из сервиса wordstat.yandex.ru
Скачать архив с парсером
Данный парсер собирает ключевые слова и частотность в эксель файл из сервиса яндекс wordstat.
Если в Ваших частых задачах присутсвует сбор статистики по ключевым словам из сервиса yandex водстат, то одним из способов оптимизации рабочего процесса — является делегирование парсеру задачу парсинга ключевых слов.
Данный парсер не является оригинальным в функциональности, но оригинален в простоте настроек и получения данных по ключевым словам.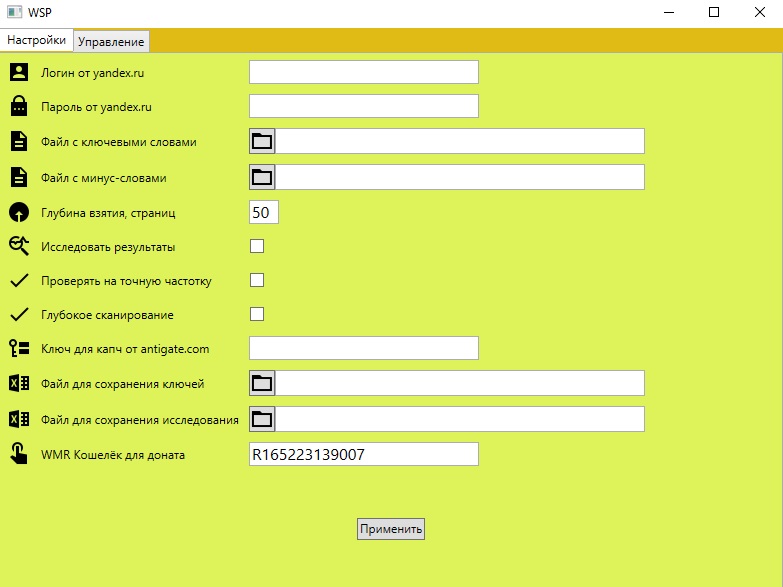
Функциональность данного парсера позволяет собрать кллючевые слова из сервиса wordstat.yandex.ru , статистику запрашиваемости собранных ключей, точную частоту ключей, а так же разгруппировать на кластеры собранные ключи.
1. Логин от yandex.ru — в данное поле необходимо ввести адрес Вашего почтового ящика от яндекс почты
2. Пароль от yandex.ru — в данное поле необходимо ввести пароль от Вашей почты на яндексе
3. Файл с ключевыми словами — в данное поле указывается файл со списком ключевых слов (файл должен быть сохранён в формате utf-8, каждый ключ с новой строки), если Вы планируете активировать кластеризацию запросов после сбора, то в данном файле должна находится только 1 базовая ключевая фраза (все слова только в нижнем регистре (маленькими буквами))
4. Файл с минус-словами — в данное поле указывается файл со списком минус-слов (файл должен быть сохранён в формате utf-8, каждое минус-слово с новой строки)
5. Глубина взятия — до какой глубины парсить
6. Исследовать результаты — данная опция активирует этап кластеризации запросов, после того, как будут собраны ключи по базовой фразе (активируя данную опцию Вы обязательно должны указать файл для сохранения исследования)
7. Проверять на точную частоту — данная опция активрует сбор точной частотки по собранным ключам
8. Глубокое сканирование — данная опция активирует глубокое сканирование
9. Ключ для капч — указывать необязательно
10. Файл для сохранения ключей — эксель файл, в который будут сохраняться ключевые слова из сервиса wordstat.yandex.ru
11. Файл для сохранения исследования — эксель файл, в который будут сохраненны сгруппированые кластеры после кластеризации
Похожие публикации:
- Как в яндекс почте найти письмо за определенную дату
- Как вернуть дизлайки на ютубе в яндексе
- Как включить webgl в яндекс браузере
- Как включить ретро интерфейс в яндекс такси