Типы char и varchar (Transact-SQL)
Символьные типы данных имеют фиксированный (char) или переменный (varchar) размер. Начиная с SQL Server 2019 (15.x) при использовании параметров сортировки с поддержкой UTF-8 эти типы данных хранят весь диапазон символьных данных Юникод и используют кодировку UTF-8. Если указаны параметры сортировки без поддержки UTF-8, эти типы данных хранят только подмножество символьных данных, поддерживаемых соответствующей кодовой страницей указанных параметров сортировки.
Аргументы
char [ ( n ) ]
Строковые данные фиксированного размера. n определяет размер строки в байтах и должно иметь значение от 1 до 8000. Для наборов символов однобайтовой кодировки, таких как Latin , размер хранилища равен n байтам, а количество символов, которые можно хранить, также равно n. Для многобайтовых кодировок размер при хранения тоже равен n байт, но количество хранимых символов может быть меньше n. Синонимом по стандарту ISO для типа char является character. Дополнительные сведения о кодировках см. в статье Однобайтовые и многобайтовые кодировки.
varchar [ ( n | max ) ]
Строковые данные переменного размера. Используйте n для определения размера строки в байтах и может быть значением от 1 до 8 000 или использовать максимальное значение, чтобы указать размер ограничения столбца до максимального объема хранилища 2^31-1 байт (2 ГБ). Для наборов символов кодировки с одним байтом, например Latin , размер хранилища равен n байтам + 2 байтам, а количество символов, которые можно сохранить, также равно n. Для многобайтовых кодировок размер при хранения тоже равен n байт + 2 байта, но количество хранимых символов может быть меньше n. Синонимы ISO для varchar являются разными или символьными. Дополнительные сведения о кодировках см. в статье Однобайтовые и многобайтовые кодировки.
Замечания
Распространенное заблуждение заключается в том, чтобы думать, что с char(n) и varchar(n), n определяет количество символов. Однако в char(n) и varchar(n) n определяет длину строки в байтах (от 0 до 8 000). n никогда не определяет количество хранимых символов. Это аналогично определению nchar(n) и nvarchar(n).
Неправильное представление происходит, так как при использовании однобайтовой кодировки размер хранилища char и varchar составляет n байтов, а число символов также равно n. Однако для многобайтовой кодировки, например UTF-8, более высокие диапазоны Юникода (от 128 до 114 111) приводят к одному символу с использованием двух или более байтов. Например, в столбце, определенном как char(10), ядро СУБД может хранить 10 символов, использующих однобайтовое кодирование (диапазон Юникода от 0 до 127), но менее 10 символов при использовании многобайтовой кодировки (диапазон Юникода от 128 до 114 111). Дополнительные сведения о хранении символов Юникода и их диапазонах см. в разделе Различия в хранении UTF-8 и UTF-16.
Если значение n в определении данных или инструкции объявления переменной не указано, длина по умолчанию равна 1. Если n не указан при использовании CAST и CONVERT функциях, длина по умолчанию составляет 30.
Объекты, использующие char или varchar , назначаются параметры сортировки по умолчанию базы данных, если только не назначено определенное параметры сортировки с помощью COLLATE предложения. Параметры сортировки контролируют кодовую страницу, используемую для хранения символьных данных.
Многобайтовые кодировки в SQL Server включают следующие:
- двухбайтовые кодировки (DBCS) для некоторых языков Восточной Азии, использующих кодовые страницы 936 и 950 (китайский), 932 (японский) или 949 (корейский).
- UTF-8 с кодовой страницей 65001. Область применения: SQL Server 2019 (15.x) и более поздних версий.
Если у вас есть сайты, поддерживающие несколько языков, примите к сведению следующие рекомендации:
- Для поддержки Юникода и минимизации проблем с преобразованием символов рекомендуем использовать параметры сортировки с поддержкой UTF-8 (начиная с SQL Server 2019 (15.x)).
- Если используется предыдущая версия SQL Server ядро СУБД, рекомендуется использовать типы данных Юникод nchar или nvarchar, чтобы свести к минимуму проблемы с преобразованием символов.
Если вы используете char или varchar, рекомендуется:
- Если размеры записей данных столбцов постоянны, используйте char.
- Если размеры записей данных столбцов значительно изменяются, используйте varchar.
- использовать varchar(max), если размеры записей данных в столбцах существенно отличаются и длина строки может превышать 8000 байт.
Если SET ANSI_PADDING выполняется OFF либо CREATE TABLE ALTER TABLE выполняется, столбец char, определенный как NULL, обрабатывается как varchar.
Для каждого столбца varchar(max) или nvarchar(max) требуется 24 байта дополнительного фиксированного выделения, которое подсчитывает ограничение строки 8060 байтов во время операции сортировки. Это может неявно ограничивать число ненулевых столбцов varchar(max) или nvarchar(max), которые могут быть созданы в таблице.
При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Такой размер строки может вызывать ошибки (например, ошибку 512) во время некоторых обычных операций, таких как обновление ключа кластеризованного индекса, или сортировки полного набора столбцов, которая происходит только во время выполнения операции.
Преобразование символьных данных
При преобразовании символьного выражения в символьный тип данных другой длины значения, слишком длинные для нового типа данных, усекаются. Тип uniqueidentifier считается символьным типом, используемым при преобразовании из символьного выражения, поэтому на него распространяются правила усечения при преобразовании в символьный тип. См. раздел «Примеры».
Если символьное выражение преобразуется в символьное выражение другого типа данных или размера, например из char(5) в varchar(5) или из char(20) в char(15), то преобразованному значению присваиваются параметры сортировки входного значения. Если несимвольное выражение преобразуется в символьный тип данных, то преобразованному значению присваиваются параметры сортировки, заданные по умолчанию в текущей базе данных. В любом случае необходимые параметры сортировки можно присвоить с помощью предложения COLLATE.
Преобразования страниц кода поддерживаются для типов данных char и varchar, но не для текстового типа данных. Как и в ранних версиях SQL Server, о потере данных во время преобразования кодовых страниц не сообщается.
Символьные выражения, которые преобразуются в приближенный тип данных numeric, могут содержать необязательную экспоненциальную нотацию Это нотация является строчным или верхним регистром e E , за которым следует необязательный знак плюс ( + ) или минус ( — ), а затем число.
Символьные выражения, которые преобразуются в точный числовый тип данных, должны состоять из цифр, десятичной запятой и необязательного плюса ( + ) или минуса ( — ). Начальные пробелы не учитываются. Разделители запятой, такие как разделитель 123,456.00 тысяч, не допускаются в строке.
Символьные выражения, преобразованные в типы данных money или smallmoney , также могут включать необязательный десятичный знак и знак доллара ( $ ). Разделители запятой, как и в $123,456.00 , разрешены.
Когда пустая строка преобразуется в int, его значение становится 0 . Когда пустая строка преобразовывается в дату, ее значением становится значение даты по умолчанию, то есть 1900-01-01 .
Примеры
А. Отображение значения по умолчанию n при использовании в объявлении переменной
В следующем примере показано значение по умолчанию n равно 1 для типов данных char и varchar , когда они используются в объявлении переменной.
DECLARE @myVariable AS VARCHAR = 'abc'; DECLARE @myNextVariable AS CHAR = 'abc'; --The following returns 1 SELECT DATALENGTH(@myVariable), DATALENGTH(@myNextVariable); GO B. Отображение значения по умолчанию n при использовании varchar с CAST и CONVERT
В следующем примере показано, что значение по умолчанию n равно 30, если типы данных char или varchar используются с CAST и CONVERT функциями.
DECLARE @myVariable AS VARCHAR(40); SET @myVariable = 'This string is longer than thirty characters'; SELECT CAST(@myVariable AS VARCHAR); SELECT DATALENGTH(CAST(@myVariable AS VARCHAR)) AS 'VarcharDefaultLength'; SELECT CONVERT(CHAR, @myVariable); SELECT DATALENGTH(CONVERT(CHAR, @myVariable)) AS 'VarcharDefaultLength'; C. Преобразование данных для отображения
В следующем примере два столбца преобразуются в символьные типы, после чего к ним применяется стиль, применяющий к отображаемым данным конкретный формат. Тип денег преобразуется в символьные данные и стиль 1 , который отображает значения с запятыми каждые три цифры слева от десятичной точки и две цифры справа от десятичной запятой. Тип даты и времени преобразуется в символьные данные и стиль 3 , который отображает данные в формате dd/mm/yy . WHERE В предложении тип денег привязывается к типу символов для выполнения операции сравнения строк.
USE AdventureWorks2022; GO SELECT BusinessEntityID, SalesYTD, CONVERT (VARCHAR(12),SalesYTD,1) AS MoneyDisplayStyle1, GETDATE() AS CurrentDate, CONVERT(VARCHAR(12), GETDATE(), 3) AS DateDisplayStyle3 FROM Sales.SalesPerson WHERE CAST(SalesYTD AS VARCHAR(20) ) LIKE '1%'; BusinessEntityID SalesYTD DisplayFormat CurrentDate DisplayDateFormat ---------------- --------------------- ------------- ----------------------- ----------------- 278 1453719.4653 1,453,719.47 2011-05-07 14:29:01.193 07/05/11 280 1352577.1325 1,352,577.13 2011-05-07 14:29:01.193 07/05/11 283 1573012.9383 1,573,012.94 2011-05-07 14:29:01.193 07/05/11 284 1576562.1966 1,576,562.20 2011-05-07 14:29:01.193 07/05/11 285 172524.4512 172,524.45 2011-05-07 14:29:01.193 07/05/11 286 1421810.9242 1,421,810.92 2011-05-07 14:29:01.193 07/05/11 288 1827066.7118 1,827,066.71 2011-05-07 14:29:01.193 07/05/11 D. Преобразование данных uniqueidentifer
В следующем примере значение uniqueidentifier преобразуется в тип данных char.
DECLARE @myid uniqueidentifier = NEWID(); SELECT CONVERT(CHAR(255), @myid) AS 'char'; Следующий пример показывает усечение данных, когда значение является слишком длинным для преобразования в заданный тип данных. Так как тип данных uniqueidentifier ограничен 36 символами, все символы, выходящие за пределы этой длины, будут усечены.
DECLARE @ID NVARCHAR(max) = N'0E984725-C51C-4BF4-9960-E1C80E27ABA0wrong'; SELECT @ID, CONVERT(uniqueidentifier, @ID) AS TruncatedValue; String TruncatedValue -------------------------------------------- ------------------------------------ 0E984725-C51C-4BF4-9960-E1C80E27ABA0wrong 0E984725-C51C-4BF4-9960-E1C80E27ABA0 (1 row(s) affected) См. также
- nchar и nvarchar (Transact-SQL)
- CAST и CONVERT (Transact-SQL)
- COLLATE (Transact-SQL)
- Преобразование типов данных (ядро СУБД)
- Типы данных (Transact-SQL)
- Оценка размера базы данных
- Поддержка параметров сортировки и Юникода
- Однобайтовые и многобайтовые кодировки
Разница между CHAR, VARCHAR и TEXT
MySQL предоставляет 3 типа данных для хранения текстовой информации: CHAR, VARCHAR и TEXT .
С каким же из них проще всего работать и какой тип данных обеспечивает более быструю работу?
Отличия в скорости работы между этими тремя MySQL типами данных будет очень тяжело выявить, до тех пор пока ваша база данных не разрастётся до довольно больших объёмов.
Данные типа CHAR, которые имеют фиксированную длину, быстрее всего сохраняют и достают информацию но могут потреблять излишнее дисковое пространство.
VARCHAR, строка изменяющейся длины, работает медленнее чем CHAR но не потребляют излишнее дисковое пространство.
Тип TEXT переменная типа BLOB – он занимает больше места и I/O чем предыдущие 2 типа.
Использование типа CHAR для текстовых данных технически самый быстродействующий способ, но данные типа CHAR имеют ограничение длинны в 255 символов. Последняя версия СУБД MySQL позволяет хранить в переменной типа VARCHAR данные длиной вплоть до 65,535 символов, это максимальная длинна этого типа данных.
Тип TEXT более привлекательный с первого взляда, потому что в отличии от типа VARCHAR, в нём можно хранить множественные TEXT элементы в одной ячейке. Для того что бы включить полнотекстовое индексирование данных типа text, необходимо что бы тип таблицы был MyISAM так как он не обращает внимания на то какой тип данных
SQL-Ex blog

Когда использовать CHAR, VARCHAR или VARCHAR(MAX)
Добавил Sergey Moiseenko on Четверг, 21 июля. 2022
В каждой базе данных имеются различные виды данных, которые нужно хранить. Некоторые данные строго числовые, в то время как другие данные состоят только из букв или комбинации букв, чисел и даже специальных символов. Даже при простом хранении данных в памяти или на диске требуется, чтобы каждая часть данных имела тип. Выбор правильного типа зависит от характеристик сохраняемых данных. В этой статье объясняется разница между CHAR, VARCHAR и VARCHAR(MAX).
При выборе типа данных столбца необходимо подумать о характеристиках данных, чтобы назначить правильный тип данных. Будет ли каждое значение иметь одну и ту же длину, или размер будет сильно различаться от значения к значению? Как часто будут меняться данные? Будет ли длина столбца меняться со временем? Могут быть и другие факторы, подобные эффективному использованию пространства и производительности, которые могут привести вас к принятию того или иного типа данных.
Типы данных CHAR, VARCHAR и VARCHAR(MAX) могут хранить символьные данные. В этой статье будут обсуждаться и сравниваться эти три различных типа символьных данных. Приведенная информация призвана помочь вам выбрать подходящий среди этих трех типов данных.
Символьный тип данных фиксированной длины CHAR
Тип данных CHAR является типом данных фиксированной длины. Он может хранить буквы, числа и специальные символы в строках размером до 8000 байт. Тип данных CHAR наилучшим образом используется для хранения данных, которые имеют сопоставимую длину. Например, двухсимвольные коды штатов США, односимвольные коды половой принадлежности, номера телефонов, почтовые коды и т.п. Столбец CHAR является не лучшим выбором для хранения данных, у которых существенно варьируется длина. Столбцы, хранящие данные типа адресов или мемо-полей не подходят для столбцов с типом данных CHAR.
Это не означает, что столбец CHAR не может содержать значения, которые варьируются по размеру. Когда в столбец CHAR заносятся строки, которые короче, чем длина столбца, справа будут добавляться пробелы. Число этих пробелов определяется разностью между размером столбца и длиной сохраняемых символов. Поскольку столбцы CHAR при необходимости полностью добиваются пробелами, каждый столбец занимает одно и то же пространство на диске или в памяти. Концевые пробелы также играют роль при поиске в столбцах типа CHAR. Подробнее об этом несколько позже.
Символьный тип данных переменной длины VARCHAR
Столбцы VARCHAR, как подразумевает название, хранят данные переменной длины. Они могут хранить буквы, числа и специальные символы, как и столбец CHAR, и поддерживают строки размером до 8000 байт. Столбец переменной длины занимает только то место, которое требуется для хранения строки символов, и не дополняются никакими пробелами. По этой причине столбцы VARCHAR отлично подходят для хранения строк, которые сильно варьируются по размеру.
Для поддержки столбцов переменной длины необходимо, помимо самих данных, хранить их длину. Поскольку длина необходима для вычислений и используется ядром базы данных при чтении и сохранении столбцов переменной длины, считается, что они несколько менее производительны по сравнению со столбцами CHAR. Однако, если учесть, что они используют только то пространство, которое им необходимо, экономия места на диске сама по себе может компенсировать потери производительности при использовании типа VARCHAR.
Различия типов данных CHAR и VARCHAR
Фундаментально отличие CHAR от VARCHAR состоит в том, что тип данных CHAR имеет фиксированную длину, в то время как тип данных VARCHAR поддерживает столбцы данных переменной длины. Но он и похожи. Оба предназначены для хранения алфавитно-цифровых данных. Для лучшего понимания разницы между этими двумя типами, посмотрите таблицу 1, где сделан обзор их подобия и отличий.

Таблица 1: сравнение типов CHAR и VARCHAR
Что означает «N» в CHAR(N) или VARCHAR(N)
«N» означает не максимальное число символов, которое может храниться в столбце CHAR или VARCHAR, а максимальное число байтов, которое займет тип данных. SQL Server имеет различные коллации для хранения символов. Некоторые наборы символов, подобные Latin, хранят каждый символ и одном байте пространства. В то время как другие наборы символов, например, японский, требуют нескольких байтов на символ.
Столбцы CHAR и VARCHAR могут хранить до 8000 байтов. Если используется односимвольный набор, то столбец CHAR или VARCHAR может хранить до 8000 символов. Если используется мультибайтовая коллация, максимальное число символов, которое может хранить CHAR или VARCHAR, будет меньше 8000. Обсуждение коллации выходит за рамки этой статьи, но если вы хотите больше узнать об однобайтовом и многобайтовыми наборами символов, обратитесь к документации.
Ошибка усечения
Если столбец определен как CHAR(N) или VARCHAR(N), «N» представляет число байтов, которое может храниться в столбце. При заполнении столбца CHAR(N) или VARCHAR(N) символьной строкой может возникнуть подобная ошибка усечения, показанная на рисунке 1.
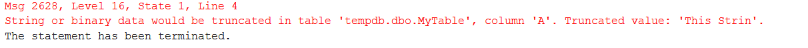
Рис.1 Ошибка усечения
Эта ошибка возникает при попытке сохранить строку, размер которой превышает максимальную длину столбца
CHAR или VARCHAR. Когда возникает подобная ошибка усечения, код TSQL прерывается, и последующий код не выполняется. Это можно продемонстрировать следующим кодом в листинге 1.
Листинг 1: код, приводящий к ошибке усечения
USE tempdb;
GO
CREATE TABLE MyTable (A VARCHAR(10));
INSERT INTO MyTable VALUES ('This String');
-- Продолжение
SELECT COUNT(*) FROM MyTable;
GO
Код в листинге 1 вызывает ошибку, показанную на рисунке 1, при выполнении оператора INSERT. Оператор SELECT, следующий за оператором INSERT, не был выполнен из-за ошибки усечения. Ошибка усечения и прерывание выполнения скрипта могут давать вам желаемую функциональность, но иногда вы не хотите получать ошибку усечения, прерывающую ваш код.
Предположим, что необходимо перенести данные из старой системы в новую. В старой системе есть таблица MyOldData, которая содержит данные, созданные с помощью скрипта в листинге 2.
Листинг 2: таблица в старой системе
USE tempdb;
GO
CREATE TABLE MyOldData (Name VARCHAR(20), ItemDesc VARCHAR(45));
INSERT INTO MyOldData
VALUES ('Widget', 'This item does everything you would ever want'),
('Thing A Ma Jig', 'A thing that dances the jig');
GO
Планируется перенести данные из таблицы MyOldData в таблицу MyNewTable, которая имеет меньший размер столбца ItemDesc. Код в листинге 3 используется для создания новой таблицы и переноса данных.
Листинг 3: перенос данных в новую таблицу
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
INSERT INTO MyNewData SELECT * FROM MyOldData;
SELECT * FROM MyNewData;
GO
При выполнении кода в листинге 3 вы получите ошибку усечения, подобную ошибке на рис.1, и никакие данные перенесены не будут.
Для успешного переноса данных необходимо определиться с тем, что делать с усечением, чтобы гарантировать перенос всех строк. Одним из методов является усечение описания элемента (ItemDesc) с помощью функции SUBSTRING при выполнении кода в листинге 4.
Листинг 4: Устранение ошибки усечения с помощью SUBSTRING
DROP Table MyNewData
GO
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
INSERT INTO MyNewData SELECT Name, substring(ItemDesc,1,40)
FROM MyOldData;
SELECT * FROM MyNewData;
GO
При выполнении кода в листинге 4 все записи переносятся. При этом ItemDesc превышающая 40 будет усекаться с помощью функции SUBSTRING, но есть и другой способ.
Если вы хотите избежать ошибки усечения без написания специального кода усечения столбцов, длина которых слишком велика, можно выключить параметр ANSI_WARNINGS, как показано в листнге 5.
Листинг 5: устранение ошибки усечения при выключении ANSI_WARNINGS.
DROP Table MyNewData
GO
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
SET ANSI_WARNINGS OFF;
INSERT INTO MyNewData SELECT * FROM MyOldData;
SET ANSI_WARNINGS ON;
SELECT * FROM MyNewData;
GO
При выключении параметра ANSI_WARNINGS ядро SQL Server не следует стандарту ISO для некоторых состояний ошибок, одним из которых является состояние ошибки усечения. При отключении этого параметра SQL Server автоматически усекает исходный столбец для соответствия его целевым столбцам без возвращения ошибки. Следует осторожно использовать выключение параметра ANSI_WARNINGS, поскольку при этом могут также остаться незамеченными другие ошибки. Поэтому изменение параметра ANSI_WARNINGS следует использовать ситуативно.
VARCHAR(MAX)
Тип данных VARCHAR(MAX) подобен типу данных VARCHAR в том, что он поддерживает символьные данные переменной длины. VARCHAR(MAX) отличается от VARCHAR тем, что он поддерживает строки символов длиной вплоть до 2 Гб (2,147,483,647 байтов). Вам следует рассмотреть использование VARCHAR(MAX) только тогда, когда каждая строка, сохраняемая в этом типе данных существенно варьируется по длине, и значение может превышать 8000 байтов.
Вы можете спросить себя, почему бы не использовать VARCHAR(MAX) везде вместо использования VARCHAR(N)? Вы можете, но имеется несколько причин, почему этого делать не стоит:
столбцы VARCHAR(MAX) не могут быть включены в ключевые столбцы индекса;
столбцы VARCHAR(MAX) не позволяют ограничить длину столбца;
для хранения больших строк столбцы VARCHAR(MAX) используют единицы распределения LOB_DATA. Хранилище LOB_DATA существенней медленней, чем использование единиц распределения хранилища IN_ROW_DATA;
хранилище LOB_DATA не поддерживает сжатие страниц и строк.
Можно подумать, что столбцы VARCHAR(MAX) будут устранять ошибку усечения, которую мы наблюдали ранее. Это частично верно при условии, что вы не пытаетесь сохранить строку со значением длинее, чем 2,147,483,647 байтов. Если вы попытаетесь записать строку, размер которой превышает 2,147,483,647 байтов, вы получите ошибку, показанную на рисунке 2.

Рис.2: ошибка, когда размер строки превышает 2 Гб
Столбцы VARCHAR(MAX) следует использовать только тогда, когда вы знаете, что некоторые сохраняемые данные будут ожидаемо превосходить 8000-байтовый предел для столбца VARCHAR(N), и все данные будут короче предела 2 Гб для типа данных VARCHAR(MAX).
Проблемы конкатенации со столбцами CHAR
Когда столбец CHAR не полностью заполнен строкой символов, неиспользованные символы замещаются пробелами. Когда столбец CHAR дополняется пробелами, это может вызвать некоторые проблемы при конкатенации столбцов CHAR. Для лучшего понимания рассматрим несколько примеров, которые используют таблицу, созданную в листинге 6.
Листинг 6: таблица для примеров Sample
USE tempdb;
GO
CREATE TABLE Sample (
ID int identity,
FirstNameChar CHAR(20),
LastNameChar CHAR(20),
FirstNameVarChar VARCHAR(20),
LastNameVarChar VARCHAR(20));
INSERT INTO Sample VALUES ('Greg', 'Larsen', 'Greg', 'Larsen');
Таблица Sample, созданная в листинге 6, содержит 4 столбца. Первые два определены как CHAR(20), а вторые два — VARCHAR(20). Эти столбцы будут использоваться для хранения моего имени и фамилии.
Для демонстрации проблем конкатенации, связанной с дополняемыми столбцами CHAR, выполните код в листинге 7.
Листинг 7: демонстрация проблемы конкатенации
SELECT FirstNameChar + LastNameChar AS FullNameChar,
FirstNameVarChar + LastNameVarChar AS FullNameVarChar FROM Sample;

Результат выполнения кода в листнге 7
Здесь столбец FirstNameCHAR содержит несколько пробелов между именем и фамилией. Эти пробелы являются пробелами, дополненными в столбце FirstNameCHAR при сохранении имени в столбце типа CHAR. Столбец FullNameVARCHAR не содержит пробелов между именем и фамилией. Если длина записываемого значения меньше длины столбца VARCHAR, пробелы не добавляются.
При конкатенации столбцов CHAR вам может понадобиться удалить концевые пробелы, чтобы получить желаемый результат. Вы можете использовать функцию RTRIM для удаления пробелов, как показано в листинге 8.
Листинг 8: удаление концевых пробелов с помощью функции RTRIM
SELECT RTRIM(FirstNameChar) + RTRIM(LastNameChar) AS FullNameChar,
FirstNameVarChar + LastNameVarChar AS FullNameVarchar
FROM Sample;
Результат выполнения скрипта показан на рисунке ниже.
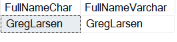
Пр использовани функции RTRIM все дополнительные пробелы, добавленные к столбцам FirstNameCHAR и LastNameCHAR удаляются перед выполнением конкатенации.
Проблемы с поиском пробелов в столбцах CHAR
Поскольку столбцы CHAR могут дополняться пробелами, поиск пробела может стать проблемой.
Предположим, что имеется таблица, содержащая фразы, подобные создаваемым в листинге 9.
Листинг 9: создание таблицы Phrase
USE tempdb;
GO
CREATE TABLE Phrase (PhraseChar CHAR(100));
INSERT INTO Phrase VALUES ('Worry Less'),
('Oops'),
('Think Twice'),
('Smile');
Некоторые фразы в таблице Phrase состоят из одного слова, а другие содержать два. Для поиска в таблице Phrase всех фраз, которые содержат два слова, воспользуемся кодом в листинге 10.
Листинг 10: попытка найти фразы из двух слов
SELECT PhraseChar FROM Phrase WHERE PhraseChar like '% %';
Результат выполнения скрипта показан ниже.

Почему были возвращены все фразы из таблицы Phrase, хотя имеется только две строки, состоящие из двух слов? Поисковая строка % % также находит пробелы, которые были добавлены в конце значения столбца. И опять, функция RTRIM может использоваться, чтобы гарантировать, что дополненные пробелы не будут включены в результаты поиска при выполнении кода в листинге 11.
Листинг 11: удаление концевых пробелов
SELECT PhraseChar FROM Phrase
WHERE RTRIM(PhraseChar) like '% %';
Вы можете сами проверить, что будут возвращены только фразы из двух слов.
Сравнение производительности VARCHAR и CHAR
Количество работы, которое выполняет движок базы данных при сохранении и извлечения столбцов VARCHAR, больше, чем для столбца CHAR. При каждом извлечении информации из столбца VARCHAR движок базы данных должен использовать информацию о длине, хранящуюся вместе с данными в столбце VARCHAR.
Использование информации о длине вызывает лишние циклы работы ЦП. В то же время фиксированная длина столбца CHAR позволяет SQL Server более легко выполнять навигацию по записям столбца CHAR, благодаря его фиксированной длине.
При работе со столбцами CHAR и VARCHAR проблемой может стать дисковое пространство. Поскольку столбец типа CHAR имеет фиксированную длину, он всегда будут занимать одинаковое пространство диска. Столбцы VARCHAR изменяются по размеру, поэтому необходимое пространство основывается на размере хранимых строк, а не на размере в определении столбца. Когда подавляющее большинство значений, хранимых в столбце CHAR, меньше заданного размера, то использование столбца VARCHAR может использовать меньше дискового пространства. Когда используется меньше дискового пространства, требуется меньше операций ввода/вывода при работе с данными столбца, что означает улучшение производительности. Эти два соображения определяют выбор между CHAR и VARCHAR.
CHAR, VARCHAR и VARCHAR(MAX)
Столбцы CHAR фиксированы по размеру, в то время как столбцы VARCHAR и VARCHAR(MAX) поддерживают данные переменной длины. Столбцы CHAR следует использовать для столбцов, длина которых меняется незначительно. Строковые значения, которые значительно варьируются по длине и не превышают 8000 байтов, следует хранить в столбце VARCHAR. Если у вас огромные строки (свыше 8000 байтов), то следует использовать VARCHAR(MAX). При использовании столбцов VARCHAR вместе с данными хранится информация о длине строки. Вычисление и хранение значения длины для столбца VARCHAR означает, что SQL Server должен выполнить немного больше работы для записи и извлечения столбцов VARCHAR по сравнению типом данных CHAR.
Когда вам предстоит решить, должен ли новый столбец иметь тип CHAR, VARCHAR или VARCHAR(MAX), задайте себе несколько вопросов, чтобы выбрать подходящий тип. Все ли сохраняемые строковые значения близки по размеру? Если да, то следует выбрать CHAR. Если сохраняемые строки значительно варьируются по размеру, и их размер не превышает 8000, используйте VARCHAR. В противном случае следует использовать VARCHAR(MAX).
CHAR и VARCHAR стр. 1
Недавно мне довелось искать ошибку в решении, которое содержало такое преобразование:
Те, кто изучил схему «Компьютеры», подумают о бессмысленности преобразования типа в тот же самый тип (столбец model определен как VARCHAR(50)). Однако именно это преобразование и делало запрос неверным.
Дело в том, что, если размер типа при преобразовании не указан, то в Cистема управления реляционными базами данных (СУБД), разработанная корпорацией Microsoft. Язык структурированных запросов) — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. SQL Server принимается значение по умолчанию, которое для VARCHAR равно 30. При этом если преобразуемая строка имеет больший размер, то отсекаются все символы кроме первых 30-ти. Разумеется, никакой ошибки при этом не возникает. Как раз на «длинных» номерах моделей предложенное решение и давало неверный результат. Как говорится в таких случаях, читайте документацию. Однако интересно, что по этому поводу говорит Стандарт?
Согласно стандарту, если для типов CHAR и VARCHAR размер не указан, то подразумевается CHAR(1) и VARCHAR(1) соответственно. Давайте проверим, как следуют стандарту доступные мне СУБД: SQL Server, MySQL, PostgreSQL.
Тут имеется два аспекта:
1. Преобразование типа
2. Использование типов CHAR/VARCHAR при описании схемы (DDL).
Начнем с преобразования типа.
SQL Server 2008

 Консоль
Консоль
 Выполнить
Выполнить