Структура HTML документа
Хотя основа документа HTML – простой текст, чтобы создать настоящий HTML документ, необходимо кое-что еще. А именно задать структуру документа HTML.
Структура документа HTML состоит из тегов, которые окружают содержимое и придают ему определенное техническое значение.
Измените свой документ следующим образом:
Это моя первая веб-страница
Теперь сохраните документ, вернитесь в браузер и выберите команду «Обновить» (это перезагрузит вашу веб-страницу).
Внешний вид страницы никак не изменился. Однако предназначение HTML – определение значения для содержимого, а не внешнего представления, и данный пример показал нам несколько фундаментальных элементов веб-страницы, задающих базовую структуру документа HTML.
Вернемся к нашему примеру. Следующая команда в структуре документа HTML, команда , — открывающий тег, который прекращает все недомолвки и прямо говорит браузеру, что все, что между ним и закрывающим тегом , является HTML документом. Все что находится между и является основным содержимым веб-страницы и выводится в окне браузера.
Закрывающие теги
Теги и закрывают соответствующие открывающие теги. Все теги в структуре документа HTML 4.01 (XHTML) должны быть закрыты. Хотя более ранние стандарты прохладно смотрели на то, что некоторые теги оставались открытыми, новые стандарты языка требуют, чтобы абсолютно все теги были закрыты. В любом случае следование этому правилу будет хорошей привычкой.
Не у всех тегов есть соответствующие закрывающие теги (вроде ). Некоторые теги, которые не заключают в себе контент, закрывают сами себя. Например, тег разрыва строки выглядит следующим образом:
. Мы вернемся к этому примеру позднее. Все что нужно запомнить, это то, что все теги в структуре документа HTML должны быть закрыты, и большинство из них (те которые содержат какой-нибудь контент) имеют следующую форму: открывающий тег → контент → закрывающий тег.
Атрибуты
У тегов также могут быть атрибуты. Атрибуты – это определенная дополнительная информация. Атрибуты определяются в открывающем теге, а их значения всегда заключаются в кавычки. Все это выглядит следующим образом:
<тег атрибут="значение">контент
Подробнее о тегах с атрибутами мы поговорим немного позже.
Элементы
Предназначение тегов – обозначать начало и конец элемента структуры документа HTML. Элементы же это кирпичики, из которых складывается веб-страница. Так, например, все что находится между тегами и , включая сами эти теги, является элементом body.
HTML5 — Основы создания структуры документа
Структура документа играет очень важную роль для понимания того, как устроена веб-страница. Она определяет то, как контенты организованы и взаимосвязаны между собой в документе, а также их относительную важность. Если воспользоваться схемой документа, то можно увидеть, как более просто стало просматривать информацию. Правильно спроектированная структура придаёт содержимому страницы смысл, делает его более лёгким для чтения, которое осуществляется поисковыми системами и другими пользовательскими агентами. На сайте, в котором правильно спроектирована структура, проще ориентироваться и находить нужную информацию.

Создание структуры документа до HTML 5
Перед изучением процесса создания структуры документа в HTML 5, желательно познакомиться с тем, как это осуществлялось в предыдущей версии языка и с какими проблемами веб-разработчику при этом приходилось сталкиваться.
Как образуется структура документа в HTML 4
Создание структуры документа в HTML 4 осуществляется с помощью 6 элементов ( h1 , h2 , h3 , h4 , h5 , h6 ). Эти элементы, при их размещении на странице, создают неявные разделы. Данные разделы называются неявными, потому что автор их в документе явно не создаёт. Они образуются автоматически, как только user agent встречает один из этих элементов в документе. Впоследствии из всех созданных user agent-ом разделов образуется структура документа.
Проблемы при реализации структуры документа
Модель структуры документа, использованная в HTML 4, имеет существенные ограничения, которые связаны с тем, что автору доступны для её создания всего 6 элементов h1 , h2 , h3 , h4 , h5 и h6 . С помощью этих элементов веб-разработчик не может спроектировать структуру документа, которая одновременно обеспечивала бы логическую взаимосвязь между разделами и отвечала критериям SEO.
Более подробно познакомиться с процессом создания структуры документа в HTML 4 и с проблемами при её реализации можно в следующей статье.
Создание структуры документа в HTML 5
Стратегия создания структуры документа в HTML5 значительно изменилась. Теперь она не определяется только одними заголовками, т.к. это всегда для большинства веб-разработчиков выглядело как-то нелепо. Заголовки позволяют определить структуру документа, но они не группируют контент. До HTML 5 авторы группировали контент с помощью элементов div , а затем использовали атрибуты классов или id атрибуты для того, чтобы присвоить этим разделам более семантически верное значение. К счастью в HTML5 появилась новая группа элементов sectioning, которые позволяют авторам создавать описание (структуру) документа. К этой группе относятся элементы article , aside , nav и section . Их основное назначение сделать код HTML более семантическим, добавить в него смысл с помощью разметки.
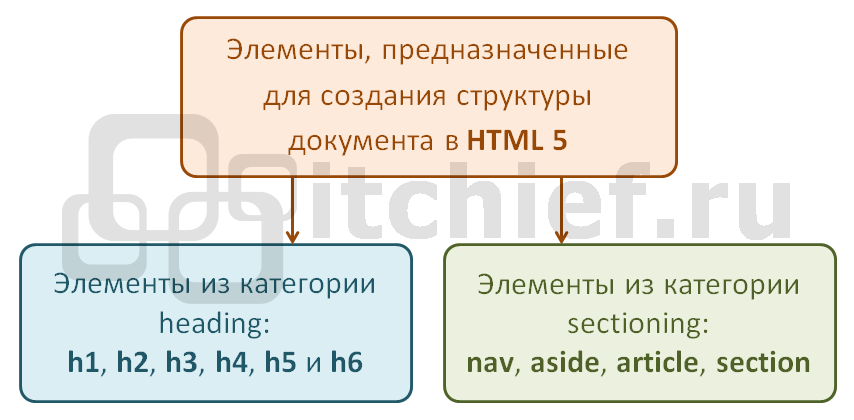
Элементы, предназначенные для создания структуры в HTML 5
Для создания структуры документа в HTML 5 используются заголовочные элементы ( h1 , h2 , h3 , h4 , h5 и h6 ) и элементы nav , aside , section и article из группы sectioning. Данные элементы в отличие от заголовков предназначены для создания явных разделов и установления этим разделам некоторого смысла.
Процесс создания структуры документа в HTML5
Для того чтобы было более просто понять основные принципы структурирования документа в HTML 5 будет считать, что элементы body , nav , aside , section и article создают секции (явные разделы), а элементы h1 , h2 , h3 , h4 , h5 и h6 — обычные разделы (неявные разделы).
Процесс разработки структуры документа рассмотрим посредством пошаговых инструкций.
В HTML 5 создание структуры документа начинается с элемента body . Данный элемент создаёт основную секцию (раздел на уровне документа).
--> Вышеприведённый пример будет создавть следующую структуру документа: [document] Untitled
После этого обычно переходят к созданию секций внутри body (основной секции). Например, создадим секции nav , section и aside . Эти секции будут являться дочерними по отношению к body .
--> Вышеприведённый пример будет создавать следующую структуру документа: [document] Untitled [nav] Untitled [section] Untitled [aside] Untitled
Каждая из секций ( nav , aside , section , article ) в свою очередь тоже может содержать секции. Таким образом, в HTML 5 получается структура документа. Т.е. одни секции вкладываются в другие. Секции, которые расположены непосредственно в body , имеют 2 уровень. А секции, которые расположены непосредственно в секциях 2 уровня будут уже иметь 3 уровень и т.д.
Например, создадим в section 3 секции article .
--> Вышеприведённый пример будет создавать следующую структуру документа: [document] Untitled [nav] Untitled [section] Untitled [article] Untitled [article] Untitled [article] Untitled [aside] Untitled
Элементы h1 , h2 , h3 , h4 , h5 и h6 в HTML5 применяются для указания названия секции (т.е. выступают в качестве заголовка секции) и для создания неявных разделов внутри секции. Причём взаимосвязь между неявными разделами осуществляется только в пределах одной секции. Т.е. заголовочные элементы, находящиеся в одной секции, не связаны с заголовочными элементами, находящимися в другой секции. Другими словами неявные разделы одной секции изолированы от неявных разделах другой секции. В качестве заголовка секции выступает заголовочный элемент, находящийся в этой секции и имеющий самый высокий ранг (уровень). Если секция не содержит заголовочный элемент, то она не имеет названия (Untitled).
Внимание: В HTML 4 в отличие от HTML 5 взаимосвязь между неявными разделами осуществлялась в пределах всего документа, а не в пределах секции ( body , nav , aside , section , article ). В HTML 4 нет элементов для создания секций.
Например, создадим названия для всех секций кроме nav .
A
B
C
D
E
Например, создадим неявные разделы в секции section и aside :
A
B
C
D
E
B-R1
B-R2
B-R3
7 Общая структура документа HTML
Пробельные символы (пробелы, символы новой строки, символы табуляции и комментарии) могут появляться до или после этого раздела. Разделы 2 и 3 должны быть в границах элемента HTML .
Вот пример простого документа HTML:
My first HTML document Hello world!
7.2 Информация о версии HTML
Корректный документ HTML объявляет, какую версию HTML использует данный документ. Объявление типа документа именует определение типа документа (ОТД) для использования в этом документе (см. [ISO8879] ).
HTML 4.01 специфицирует три ОТД, таким образом, авторы обязаны включить в свой документ одно из нижеследующих объявлений типа документа. ОТД различаются тем, какие элементы они поддерживают.
-
HTML 4.01 Strict/Строгое ОТД включает все элементы и атрибуты, которые не являются не рекомендуемыми или не входят в документ типа «набор фрэймов». Для документов, использующих это ОТД, дайте такое объявление типа :
URI в каждом из этих объявлений типа документа позволяет пользовательским агентам (ПА) загрузить необходимые ОТД наборы мнемоник . Следующие (относительные) URI ссылаются на ОТД и наборы мнемоник для HTML 4:
- «strict.dtd » — строгое ОТД ,по умолчанию
- «loose.dtd » — свободное ОТД
- «frameset.dtd » — ОТД для набора фрэймов
- «HTMLlat1.ent » — Latin-1 мнемоники
- «HTMLsymbol.ent » — мнемоники символов
- «HTMLspecial.ent » — специальные мнемоники
Связь между публичными идентификаторами и файлами может быть установлена с использованием файла каталога образцов в соответствии с форматом, рекомендованным Oasis Open Consortium (см. [OASISOPEN] ). Файл каталога образцов HTML 4.01 включён в начало раздела справочной информации SGML для HTML. Последние две буквы в объявлении обозначают язык ОТД. Для HTML это всегда английский («EN»).
Примечание. Начиная с версии HTML 4.01 от 24 декабря, the HTML Working Group придерживается следующей политики:
- любые будущие изменения в ОТД HTML 4 не изменят корректности документов. соответствующих ОТД настоящей спецификации. The HTML Working Group оставляет за собой право корректировать обнаруженные «жучки»;
- программные средства, соответствующие ОТД настоящей спецификации, могут игнорировать возможности будущих ОТД HTML 4, которые ими не распознаются.
Это означает, что в объявлении типа документа авторы могут спокойно использовать системные идентификаторы, которые ссылаются на позднейшую версию ОТД HTML 4.
Авторы могут также выбрать использование системных идентификаторов, ссылающихся на специфическую (датированную) версию ОТД HTML 4 при проверке необходимости наличия конкретного ОТД.
W3C приложит соответствующие усилия для того, чтобы архивные документы были неограниченно доступны по своим оригинальным адресам и в своей оригинальной форме.
7.3 Элемент HTML
HTML O O (%html.content; ) -- корневой элемент документа --> %i18n; -- lang , dir -- >
Начальный тег: не обязателен, Конечный тег: не обязателен
version = cdata [CN] Не рекомендуется. Значением этого атрибута является версия ОТД HTML, под управлением которого создан текущий документ. Этот атрибут не рекомендуется использовать, поскольку он является излишним при наличии информации о версии , предоставляемой объявлением типа документа.
Атрибут, определённый в другом месте
После объявления типа документа, остальной документ HTML является содержимым элемента HTML .
Таким образом, типичный документ HTML имеет такую структуру:
. элементы head, body и т.п. идут здесь.
7.4 «Шапка» документа
7.4.1 Элемент HEAD
%head.misc; определённый ранее как "SCRIPT|STYLE|META|LINK|OBJECT" --> HEAD O O (%head.content; ) +(%head.misc; ) -- "шапка" документа --> %i18n; -- lang , dir -- profile %URI; #ПРЕДПОЛАГАЕТСЯ -- именованный словарь метаинформации -- >
Начальный тег: не обязателен, Конечный тег: не обязателен
profile = uri [CT] Определяет размещение одного или более профилей метаданных, разделённых пробелами. С учётом будущих расширений, ПА должны рассматривать значение как список, даже если в данной спецификации значащим является только первый URI. Профили обсуждаются ниже в разделе метаданные .
Атрибут, определённый в другом месте
Элемент HEAD содержит информацию о текущем документе, такую как название/title, ключевые слова, которые могут оказаться полезными при использовании маши поиска, и другие данные, не являющиеся содержимым документа. ПА вообще-то не должны отображать как содержимое документа информацию элемента HEAD . Они могут, однако, сделать информацию из HEAD доступной пользователю с помощью других механизмов.
7.4.2 Элемент TITLE
TITLE - - (#PCDATA) -(%head.misc; ) -- Заголовок документа --> %i18n >
Начальный тег: необходим, Конечный тег: необходим
Атрибуты, определённые в другом месте
Каждый документ HTML обязан элемент TITLE в разделе HEAD .
Авторы должны использовать элемент TITLE для идентификации содержимого документа. Поскольку пользователи часто обращаются к документам вне контекста, авторы должны предоставлять осмысленные заголовки. Таким образом, вместо такого заголовка, как «Introduction», который не даёт достаточно информации о документе, авторы должны записать, например, так: «Introduction to Medieval Bee-Keeping».
Из соображений доступности документов, ПА всегда должны делать содержимое элемента TITLE доступным для пользователя (включая элемент TITLE фрэймов).
Конкретный механизм выполнения этого зависит от ПА (т.е. заглавие, фраза).
Заголовок может содержать символьные мнемоники (для изображения букв с акцентами, специальных символов и т.д.), но не может содержать разметку (в том числе и комментарии).
Вот пример заголовка:
A study of population dynamics . другие элементы "шапки". . тело документа.
7.4.3 Атрибут title
title = text [CS] Этот атрибут предоставляет информативные данные об элементе, в котором он содержится.
В отличие от элемента TITLE , который даёт информацию обо всём документе и может появиться в документе только один раз, атрибут title может содержаться в любом количестве элементов. См. определения элементов, чтобы удостовериться, что они поддерживают этот атрибут.
Значения атрибута title по разному могут рассматриваться ПА. К примеру, визуальные браузеры часто отображают title как «подсказку» (краткое сообщение, появляющееся при наведении указательного устройства на объект). Аудио ПА могут «произносить» информацию заголовка в аналогичном контексте. Например, установка этого атрибута для гиперссылки позволяет ПА (визуальным и не-) сделать сообщение о связанном ресурсе:
. какой-нибудь текст. Here's a photo of me scuba diving last summer . ещё какой-нибудь текст.
Атрибут title при использовании с элементом LINK дополнительно играет роль указателя на внешнюю таблицу стилей . См. детали в разделе гиперссылки и таблицы стилей .
Примечание. Для улучшения качества воспроизведения голосового синтеза, будущие версии HTML могут включать атрибут для введения фонетической и голосовой информации.
7.4.4 Метаданные
Примечание. The W3C Resource Description Framework (Структура Описания Ресурса) (см. [RDF10] ) стал W3C Recommendation в феврале 1999 года. RDF даёт авторам возможность специфицировать читаемые машиной метаданные о документах HTML и других ресурсах, доступных в сети.
HTML позволяет авторам специфицировать метаданные — информацию о самом документе, а не о его содержимом — различными способами.
Например, чтобы специфицировать автора документа, можно использовать элемент META :
Элемент META определил свойство (здесь — «Author») и установил ему значение (здесь — «Dave Raggett»).
Эта спецификация не определяет набор действительных свойств метаданных. Значение свойства и набор действительных значений для этого свойства должны быть определены в справочном словаре, называемом профиль . Например, профиль, созданный для помощи поисковым машинам при индексировании документов, может определять свойства, такие как «author», «copyright», «keywords» и т.д.
Спецификация метаданных
Вообще спецификация метаданных состоит из двух шагов:
- объявление свойства и значения этого свойства. Это можно сделать двояко:
- из документа через элемент META ;
- вне документа связыванием метаданных через элемент LINK (см. раздел типы ссылок );
- ссылка на профиль , где определены свойства и их действительные значения. Чтобы создать профиль, используйте атрибут profile элемента HEAD .
Учтите, что, поскольку профиль определён для элемента HEAD , этот же профиль применяется и для всех элементов META и LINK в «шапке» документа.
От ПА не требуется поддержка механизма метаданных. Для тех ПА, которые поддерживают метаданные, эта спецификация не определяет, как метаданные должны интерпретироваться.
Элемент META
META - O EMPTY -- родовая метаинформация --> %i18n; -- lang , dir , для использования с этим содержимым -- http-equiv NAME #ПРЕДПОЛАГАЕТСЯ -- HTTP имя "шапки" ответа -- name NAME #ПРЕДПОЛАГАЕТСЯ -- имя метаинформации -- content CDATA #НЕОБХОДИМ -- ассоциированная информация -- scheme CDATA #ПРЕДПОЛАГАЕТСЯ -- выбор формы содержимого -- >
Начальный тег: требуется, Конечный тег: запрещён
Для следующих атрибутов допустимые значения и их интерпретация зависят от profile :
name = name [CS] Устанавливает имя свойства. Эта спецификация не содержит списка действительных значений для этого атрибута. content = cdata [CS] Определяет значение свойства. Эта спецификация не содержит списка действительных значений для этого атрибута. scheme = cdata [CS] Этот атрибут именует схему, используемую для интерпретации значения свойства (см. детали в разделе профили ). http-equiv = name [CI] Этот атрибут может использоваться вместо атрибута name . HTTP серверы используют этот атрибут для получения информации для «шапки» ответа HTTP.
Атрибут, определённый в другом месте
Элемент META можно использовать для идентификации свойств документа (напр., автора, конечной даты использования, списка ключевых слов и т.д.) и установки значений этих свойств. Эта спецификация не определяет нормативный набор свойств.
Каждый элемент META определяет пару свойство-значение. Атрибут name идентифицирует свойство, а атрибут content определяет значение свойства.
Например, следующее объявление устанавливает значение для свойства Author:
Атрибут lang может использоваться элементом META для определения языка значения атрибута content . Это делает возможным использование речевого синтеза, устанавливая зависящие от языка правила произношения.
В этом примере имя автора объявляется как французское:
Примечание. Элемент META это общий механизм для спецификации метаданных. Однако некоторые элементы и атрибуты HTML уже обрабатывают отдельные части метаданных и могут быть использованы авторами вместо META : элемент TITLE , элемент ADDRESS , элементы INS и DEL , атрибут title и атрибут cite .
Примечание. Если свойство элемента META принимает значение — URI , некоторые авторы предпочитают устанавливать метаданные элементом LINK . Таким образом, следующее объявление метаданных:
можно записать также:
META и «шапки» HTTP
Атрибут http-equiv может использоваться вместо атрибута name имеет специальное значение при возврате документов по протоколу Hypertext Transfer Protocol (HTTP). HTTP серверы могут использовать имя свойства, специфицированное атрибутом http-equiv , для создания «шапки» в стиле [RFC822] для ответа HTTP. См. спецификацию HTTP ([RFC2616] ) о правильных «шапках» HTTP.
Следующая выдержка из объявления META :
даст в результате «шапку» HTTP:
Expires: Tue, 20 Aug 1996 14:25:27 GMT
Это может использоваться при кэшировании для определения того, когда вызывать свежую копию ассоциированного документа.
Примечание. Некоторые ПА поддерживают использование META для обновления текущей страницы по истечении определённого количества секунд с возможностью замены её другим URI. Авторы не должны использовать этот метод перевода пользователя на другую страницу, поскольку это делает страницу недоступной для некоторых пользователей. Вместо этого, автоматическое перенаправление страницы должно осуществляться с использованием серверного перенаправления.
META и машины поиска
Обычно META специфицирует ключевые слова, которые используются поисковыми машинами для повышения качества и скорости поиска. Если несколько элементов META предоставляют информацию, связанную с языком документа, поисковые машины могут осуществлять фильтрацию на основе атрибута lang для отображения результата поиска с использованием языковых установок пользователя. Например,
Эффективность работы поисковой машины может также быть повышена за счёт использования элемента LINK для установки ссылок на версии документа на других языках, ссылок на версии документа на других носителях (напр., PDF), и, если документ является частью коллекции, ссылок на подходящую стартовую точку для начала просмотра коллекции.
META и PICS
Platform for Internet Content Selection /Платформа для Выбора Содержимого Internet (PICS, специфицированная в [PICS] ) это инфраструктура для ассоциирования лэйблов (метаданных) с содержимым Internet. Созданная первоначально как помощь родителям и педагогам для контроля за тем, к чему дети могут получить доступ в Internet, она также даёт возможность использовать лэйблы для пометок кода, политики безопасности и обслуживания прав интеллектуальной собственности.
Этот пример иллюстрирует, как можно использовать объявление META для включения лэйбла PICS 1.1:
<em>. заголовок документа .</em>
META и информация по умолчанию
Элемент META может использоваться для спецификации информации по умолчанию для следующих объектов документа:
- язык скриптов по умолчанию ;
- язык таблиц стилей по умолчанию ;
- набор символов документа .
В следующем примере определён набор символов документа — ISO-8859-5:
Профили метаданных
- Как уникальное глобальное имя. ПА могут иметь способность распознавать имя (без явного запроса профиля) и выполнять какие-нибудь действия на базе известных соглашений для данного профиля. К примеру, поисковые машины могли бы предоставлять интерфейс для поиска в каталогах документов HTML, где все эти документы используют тот же профиль для представления вхождений каталога.
- Как гиперссылку. ПА могут разыменовывать URI и выполнять некоторые действия на базе текущих определений в профиле (напр., авторизовать использование профиля в текущем документе HTML). Эта спецификация не определяет форматы профилей.
Это пример ссылки на гипотетический профиль, определяющий используемые свойства для индексации документа. Свойства, определённые этим профилем, включая «author», «copyright», «keywords» и «date», имеют свои значения, установленные последовательными объявлениями META :
Так как эта спецификация уже написана, обычной практикой является использование форматов даты, описанных в [RFC2616] , раздел 3.3.
Поскольку эти форматы относительно сложны для обработки, мы рекомендуем авторам использовать формат даты [ISO8601] . Дополнительно см. раздел об элементах INS и DEL .
Атрибут scheme позволяет авторам предоставлять ПА информацию, более подходящую для корректной интерпретации метаданных. Иногда такая дополнительная информация может быть критичной, если метаданные специфицированы в другом формате. Например, автор может установить дату в (неоднозначном) формате «10-9-97», что может означать 9 октября 1997 или 10 сентября 1997 г. Значение атрибута scheme «Month-Day-Year» может однозначно определить значение этой даты.
В других случаях, атрибут scheme может предоставлять дополнительную не критичную информацию для ПА.
Например, следующее объявление scheme может помочь ПА определить, что значение свойства «identifier» — это код ISBN:
Значения атрибута scheme зависят от свойства name и ассоциированного profile .
Примечание. Существует образец профиля под названием Dublin Core (см. [DCORE] ). Этот профиль определяет набор рекомендуемых свойств описаний электронной библиографии и предназначен для взаимодействия несоотносимых моделей описания.
7.5 Тело документа
7.5.1 Элемент BODY
BODY O O (%block; |SCRIPT)+ +(INS|DEL) -- тело документа --> %attrs; -- %coreattrs , %i18n , %events -- onload %Script; #ПРЕДПОЛАГАЕТСЯ -- документ был загружен -- onunload %Script; #ПРЕДПОЛАГАЕТСЯ -- документ был удалён -- >
Начальный тег: не обязателен, Конечный тег: не обязателен
background = uri [CT] Не рекомендуется. Значением атрибута является URI, обозначающий источник изображения. Изображение обычно используется для размножения и заполнения фона (для визуальных браузеров). text = color [CI] Не рекомендуется. Устанавливает цвет текста (для визуальных браузеров). link = color [CI] Не рекомендуется. Цвет непосещённых гиперссылок (для визуальных браузеров). vlink = color [CI] Не рекомендуется. Цвет посещённых гиперссылок (для визуальных браузеров). alink = color [CI] Не рекомендуется. Цвет гиперссылок при выборе пользователем (для визуальных браузеров).
Атрибуты, определённые в другом месте
- id , class (идентификаторы документа )
- lang (язык ), dir (направление текста )
- title (заголовок элемента )
- style (инлайн-стиль )
- bgcolor (цвет фона )
- onload , onunload (внутренние события )
- onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , onmouseout , onkeypress , onkeydown , onkeyup (внутренние события )
В теле документа находится содержимое документа. Содержимое может быть представлено ПА разными способами. Например, для визуальных ПА можно представить тело как канву, на которой появляется содержимое: текст, изображения, цвета, графика и т.д. В аудио ПА то же содержимое может быть звучащей речью. Поскольку сейчас предпочтительно использование таблиц стилей для спецификации представления документа, атрибуты представления BODY не рекомендуются .
НЕ РЕКОМЕНДУЕТСЯ:
Этот фрагмент HTML иллюстрирует использование не рекомендуемых атрибутов.
Здесь установлен белый цвет фона канвы, чёрный цвет текста, красный первоначальный цвет гиперссылок, фуксиновый при активации и коричневый после посещения.
A study of population dynamics . тело документа.
Использование таблиц стилей приведёт к тому же результату:
A study of population dynamics BODY < background: white; color: black>A:link < color: red >A:visited < color: maroon >A:active . тело документа.
Использование внешних (связанных) таблиц стилей позволяет более гибко управлять представлением, не пересматривая документ-источник HTML:
A study of population dynamics . тело документа.
Наборы фрэймов и тело документа HTML. Документы, содержащие набор фрэймов, замещают элемент BODY элементом FRAMESET . См. раздел фрэймы .
7.5.2 Идентификаторы элемента: атрибуты id и class
id = name [CS] Устанавливает имя элемента. Имя должно быть уникальным для данного документа. class = cdata-list [CS] Устанавливает имя класса или набор имён классов для элемента. Любому количеству элементов может быть назначено то же имя или имена класса. Множественные имена классов могут разделяться пробельными символами.
Атрибут id назначает элементу уникальны идентификатор (который может проверяться разборщиком SGML). Например, следующие параграфы различаются значениями своих id :
Атрибут id имеет несколько ролей в HTML:
- переключатель таблиц стилей ;
- anchor/якорь назначения для гипертекстовых ссылок;
- как значение для ссылки на конкретный элемент из скрипта ;
- как имя объявленного элемента OBJECT ;
- для общих надобностей обработки в ПА (напр., для идентификации полей при извлечении данных из страниц HTML в базы данных, переводе документов HTML в другие форматы и т.п.).
Атрибут class одновременно назначает элементу одно или более имён классов; можно сказать, что элемент принадлежит данным классам. Имя класса может разделяться несколькими объектами элемента. Атрибут class имеет несколько ролей в HTML:
- переключатель таблиц стилей (если автор захочет назначить информацию о стиле нескольким элементам);
- для общих надобностей обработки в ПА.
В следующем примере элемент SPAN используется вместе с атрибутами id и class для разметки сообщений документа. Сообщения появляются в английской и французской версиях.
Variable declared twice Undeclared variable Bad syntax for variable name
Variable déclarée deux fois Variable indéfinie Erreur de syntaxe pour variable
Следующие правила CSS (Каскадной Таблицы Стилей) могут сообщить визуальным ПА, что необходимо отобразить информационные сообщения зелёным цветом, предупреждения — жёлтым, а ошибки — красным:
SPAN.info < color: green >SPAN.warning < color: yellow >SPAN.error
Обратите внимание, что французское «msg1» и английское «msg1» не могут появляться в одном документе, поскольку они разделяют одно значение id . Авторы могут также использовать атрибут id для уточнения представления определённых сообщений, делать их якорями назначения и т.п.
Почти любому элементу HTML может быть назначен идентификатор и информация класса.
Предположим, например, что мы создаём документ о языке программирования. Документ содержит несколько отформатированных примеров. Мы используем элемент PRE для форматирования примеров. Мы назначаем также цвет фона (зелёный) всем объектам элемента PRE , принадлежащих классу «example».
<em>. заголовок документа .</em> PRE.example
Установив в этом примере атрибут id , мы можем
(1) делать ссылки на класс и
(2) переопределять информацию стиля класса с помощью объекта информации стиля.
Примечание. Атрибут id разделяет то же пространство имён, что и атрибут name , когда используется для именования якоря. См. дополнительно раздел якоря с id .
7.5.3 Элементы инлайн и уровня блока
Некоторые элементы HTML, которые могут появляться в BODY , называются «элементы уровня блока» , а другие — «inline/инлайн» (известные также как «text level/уровня текста»). Значение может быть выведено из нескольких понятий:
Модель содержимого Вообще, элементы уровня блока могут содержать инлайн-элементы и другие элементы уровня блока. Вообще, инлайн-элементы могут содержать только данные и другие инлайн-элементы. Сущностью этого структурного отличия является идея, что элементы блока создают более «широкие» структуры, чем инлайн-элементы. Форматирование По умолчанию элементы уровня блока форматируются иначе, нежели инлайн-элементы.
Как правило элементы уровня блока начинаются с новой строки, а инлайн-элементы — нет. Информацию о пробелах, разрывах строки и форматировании блоков см. в разделе о тексте . Направление (текста) По техническим причинам — включение двунаправленного текстового алгоритма [UNICODE] , элементы уровня блока и инлайн различаются тем, как они наследуют информацию о направлении. См. детали в разделе наследование направления текста .
Таблицы стилей предоставляют значения для спецификации представления произвольных элементов, в том числе — элементов уровня блока и инлайн-элементов. В некоторых случаях, таких как инлайн-стиль элементов-списков, это подходит, но в целом авторам не рекомендуется таким образом переопределять согласованную интерпретацию элементов HTML.
Изменение традиционных идиом представления для элементов уровня блока и инлайн также воздействует на двунаправленный текстовый алгоритм . См. раздел действие таблиц стилей на двунаправленность .
7.5.4 Группирование элементов: элементы DIV и SPAN
DIV - - (%flow; )* -- общий язык/контейнер стиля --> %attrs; -- %coreattrs , %i18n , %events -- > SPAN - - (%inline; )* -- общий язык/контейнер стиля --> %attrs; -- %coreattrs , %i18n , %events -- >
Начальный тег: необходим, Конечный тег: необходим
Атрибуты, определённые в другом месте
- id , class (идентификаторы документа )
- lang (язык ), dir (направление текста )
- title (заголовок элемента )
- style (инлайн-стиль )
- align (выравнивание )
- onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , onmouseout , onkeypress , onkeydown , onkeyup (внутренние события )
Элементы DIV и SPAN в сочетании с атрибутами id и class предоставляют общий механизм для добавления структуры к документу. Эти элементы определяют содержимое как инлайн ( SPAN ) или уровня блока ( DIV ), но не навязывают других идиом представления содержимого. Таким образом, авторы могут использовать эти элементы в сочетании с таблицами стилей , атрибутом lang и т.д. и приспособить HTML к выполнению нужных задач.
Предположим, например, что мы хотим сгенерировать документ HTML, на основе информации из базы данных клиента. Поскольку HTML не имеет элементов, идентифицирующих объект, таких как «client», «telephone number», «email address» и т.д., мы используем DIV и SPAN для достижения желаемого структурного эффекта и представления. Можно использовать элемент TABLE для структурирования информации:
First name:Stephane Tel:(212) 555-1212 Email:sb@foo.org
First name:Yves Tel:(617) 555-1212 Email:yves@coucou.com
Позже мы легко можем добавить объявление таблицы стилей для более точной настройки представления объектов этой базы данных.
Другие примеры использования см. в разделе атрибуты class и id .
Визуальные ПА обычно помещают разрыв строки перед и после элементов DIV , например:
aaaaaaaaabbbbbbbbbcccccccccc
что обычно отображается так:
aaaaaaaaa bbbbbbbbb ccccc ccccc
7.5.5 Заголовки: элементы H1 , H2 , H3 , H4 , H5 , H6
H1 |H2 |H3 |H4 |H5 |H6 "> %heading; ) - - (%inline; )* -- заголовок %attrs; -- %coreattrs , %i18n , %events -- >
Начальный тег: необходим, Конечный тег: необходим
Атрибуты, определённые в другом месте
- id , class (идентификаторы документа )
- lang (язык ), dir (направление текста )
- title (заголовок элемента )
- style (инлайн-стиль )
- align (выравнивание )
- onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , onmouseout , onkeypress , onkeydown , onkeyup (внутренние события )
Элемент heading кратко описывает смысл раздела, которому он предшествует. Информация заголовка может использоваться ПА, например, для автоматического создания оглавления документа.
Имеется шесть уровней заголовков HTML: от H1 (самый крупный/верхний) до H6 . Визуальные браузеры обычно отображают более значительный заголовок более крупным шрифтом.
В этом примере видно, как с помощью элемента DIV ассоциировать заголовок с разделом документа, который следует за ним. Это позволит Вам определить таблицу стилей для данного раздела (фон, шрифт и т.д.).
Forest elephants
In this section, we discuss the lesser known forest elephants. . раздел продолжается.Habitat
Forest elephants do not live in trees but among them. . этот раздел продолжается.
Эта структура может быть украшена с помощью таблицы стилей:
<em>. заголовок документа .</em> DIV.section < text-align: justify; font-size: 12pt>DIV.subsection < text-indent: 2em >H1 < font-style: italic; color: green >H2
Нумерованные разделы и ссылки.
HTML сам по себе не генерирует номера разделов в соответствии с заголовками. Это может, однако, выполняться некоторыми ПА. В ближайшем будущем языки таблиц стилей, такие как CSS, позволят авторам управлять генерацией заголовков разделов (что может пригодиться для создания ссылок в печатных документах (см. раздел 7.2).
Некоторые считают скрывание уровней заголовков плохой практикой. Они принимают H1 H2 H1 не принимают H1 H3 H1, поскольку во втором случае заголовок уровня H2 пропущен.
7.5.6 Элемент ADDRESS
%inline; )* -- информация об авторе --> %attrs; -- %coreattrs , %i18n , %events -- >
Начальный тег: необходим, Конечный тег: необходим
Атрибуты, определённые в другом месте
- id , class (идентификаторы документа )
- lang (язык ), dir (направление текста )
- title (заголовок элемента )
- style (инлайн-стиль )
- onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , onmouseout , onkeypress , onkeydown , onkeyup (внутренние события )
Элемент ADDRESS может использоваться авторами для указания контактной информации в документе или в большой части документа, например, в форме. Этот элемент часто появляется в начале или в конце документа.
Например, страница на W3C Web-сайте, относящаяся к HTML, может содержать следующую контактную информацию:
Dave Raggett, Arnaud Le Hors, contact persons for the W3C HTML Activity $Date: 1999/12/24 23:07:14 $
Структура сайта: классические составляющие + фишки
Структура сайта – это четкая схема, по которой будет разрабатываться ресурс. Наглядная структура покажет вид будущего сайта.
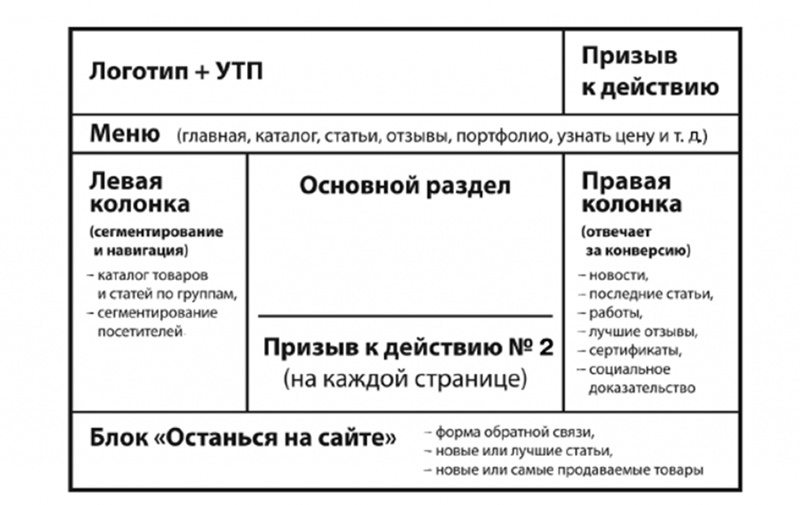
Существуют классические составляющие структуры любого сайта, но есть и дополнительные фишки, которые преследуют свою цель. Например, в интернет-магазине обязательно должна быть страница для оплаты, а в лендинге – место под призыв к действию. Иначе для чего все затевается?

Описание структуры сайта
Любой ресурс создается согласно определенному плану. Именно он отображает структуру сайта. В плане обязательно указывается, как должны располагаться страницы ресурса относительно друг друга. Чаще всего это делается в виде графической схемы с отдельными блоками и связывающими их стрелками.
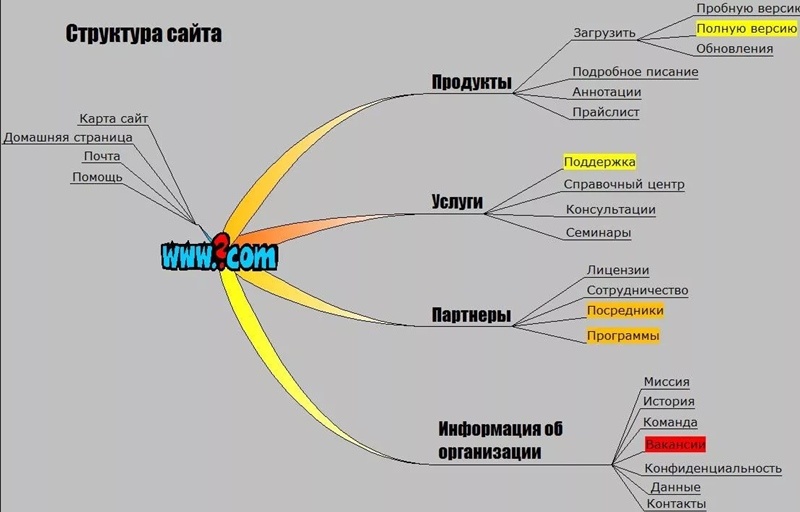
Структура может быть внешней и внутренней. Внешняя представляет собой макет страницы, на котором блоками обозначены отдельные ее элементы. Внутренняя структура включает в себя категории и разделы сайта и отношение к ним отдельных страниц. Ее сложнее всего организовать правильно.
Схема ресурса в первую очередь зависит от его специфики и направленности, того, какую бизнес-задачу он решает. Если речь идет об одностраничном сайте-визитке, то составить его план довольно просто: на одной странице будет размещаться вся основная информация. Другое дело – информационный портал или интернет-магазин.

Требования к структуре сайта могут быть разными, однако независимо от них информация должна подаваться таким образом, чтобы пользователи:
- получали исчерпывающий ответ на свои вопросы;
- понимали логику сайта;
- увлекались опубликованным материалом и стремились найти и другие статьи.
Помимо перечисленного, размещенный контент должен улучшать положение сайта в поисковых выдачах.

«Мы обязаны делать клиентов довольными
любыми доступными способами!»
Алексей Молчанов,
основатель международной IT-компании Envybox

Текущая ситуация в стране и мире с каждым днем набирает все больше и больше оборотов.
Сегодня каждый предприниматель задается вопросом: “А что же сейчас будет с моим бизнесом?”
Если вы поддадитесь всеобщей панике и “заморозите” деятельность компании, то ни к чему хорошему это не приведет. Если вы видите, что кризис неизбежен и доход компании уже начинает сокращаться — не приостанавливайте свою деятельность. Ни в коем случае не сокращайте расходы на рекламу и не прекращайте продвижение (если вас, конечно, не закрыли из-за Постановления правительства).
Направляйте максимум усилий и внимания на продвижение своей компании и увеличение потока новых клиентов.
Для того, чтобы у вас было понимание, как следует себя вести во время кризиса — поделюсь с вами полезными инструментами, которые помогли нам не только преодолеть кризис, но и выйти из него победителями.
Ниже вы можете скачать чек-лист из простых и доступных для любой компании инструментов привлечения стабильного потока новых клиентов или возвращения существующих. А также в качестве бонуса получить бесплатное использование наших сервисов для увеличения заявок с сайта в течение 7 дней и 30% скидку на их подключение. Желаем вам удачи, новых клиентов и больших продаж!
СКАЧАТЬ ЧЕК-ЛИСТ
+ БОНУС
Формирование четкой структуры ресурса дает следующие преимущества:
- позволяет разработать план развития проекта, на основе которого будут создаваться новые страницы и контент;
- делает возможным планирование расходов на открытие площадки.

4 вида структуры сайта
1. Линейная
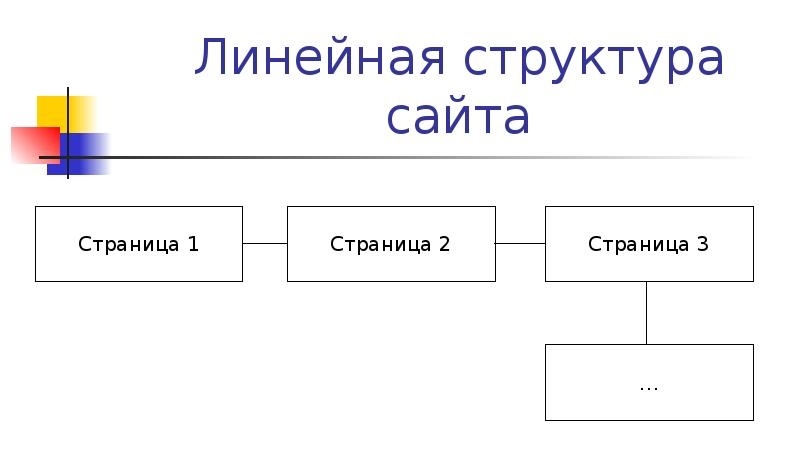
Логика такой структуры – ознакомить пользователей сайта со всеми его страницами, расположенными в определенной последовательности. Линейная схема применяется в сайтах-презентациях и портфолио. Из главной страницы как бы вытекают все остальные и расставляются цепочкой, звенья которой взаимосвязаны. Подобная структура не удобна для продвижения. Это обусловлено тем, что рекламировать можно только главную страницу.

2. Линейная с ответвлениями
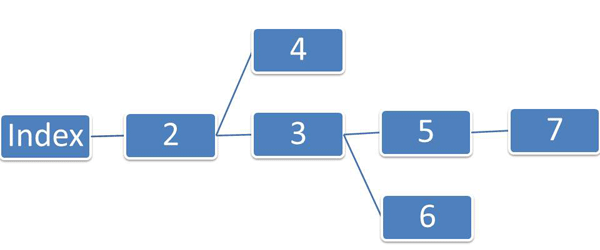
Пример – сайт-портфолио фотомодели, работающей в нескольких разных стилях. Благодаря ответвлениям на одном сайте можно показывать сразу несколько продуктов. Переходя на ветку, пользователь будет видеть постраничную презентацию товара. Линейная структура с ответвлениями подразумевает, что у сайта будет одна главная страница, но несколько последних. Для продвижения схема также не удобна.
3. Блочная
Подразумевает, что есть несколько равнозначных страниц, на которые ссылаются все остальные. Блочная структура сайта подходит для презентации продукта: на страницах можно разместить описания отдельных свойств или характеристик товара. Все страницы будут перелинкованы и связаны с главной, благодаря чему сайт будет легче продвигать. Однако блочная верстка достаточно специфична и подходит не всем видам ресурсов.
4. Древовидная
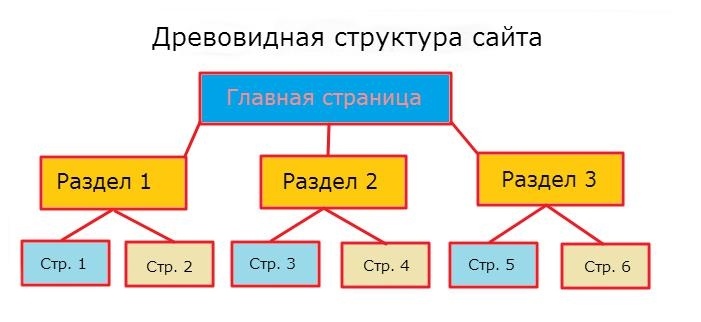
Наиболее универсальный вариант. В нем каждому товару или услуге отводится отдельная ветка: раздел или подраздел. Привычнее всего пользователям общаться именно с такими ресурсами. При древовидной структуре смысловая нагрузка делится между главной страницей и отдельными разделами, так как с ними линкуются отдельные страницы. Для продвижения это наиболее оптимальный вариант, позволяющий рекламировать сразу несколько разделов сайта.
Пример древовидной верстки в URL:
- name.ru/kresla/
- name.ru/kresla/tkani.html
- name.ru/kresla/kozha.html
- name.ru/krovati/
- name.ru/stylya/
- name.ru/stoly/derevo.html
- name.ru/stoly/plastic.html
- name.ru/stoly/rotang.html
- name.ru/stoly/metall.html
Из-за сильной разветвлённости древовидная структура сайта в виде схемы воспринимается проще и нагляднее.
Требования к структуре сайта от Яндекса и Гугла
Все онлайн-ресурсы затачиваются под поисковые системы, так как иначе пользователи их не увидят. Поэтому, говоря о требованиях к верстке, нельзя не вспомнить о Яндексе и Google.

Поисковые системы анализируют верстку ресурса по-своему. Их оценка сильно отличается от пользовательской, так как основывается на других принципах. Поисковые системы исследуют URL-структуру сайта. И у них есть определенные требования.
Рекомендации от Яндекса
Поисковик в своем саппорте разместил детальное описание требований к структуре сайтов. Можно зайти на страницу технической поддержки и ознакомиться с ними. Если говорить коротко, то суть этих рекомендаций заключается в следующем:
- Необходимо иметь четкую ссылочную структуру. Каждая страница или документ должны относиться к своему разделу. На каждую страницу должна вести хотя бы одна ссылка с другой страницы.
- Для ускорения индексации сайта нужна его xml-карта.
- С помощью файла robots.txt необходимо ограничивать индексирование служебной информации.
- У каждой страницы должен быть уникальный URL-адрес. Разные страницы должны размещаться под разными адресами, а одна и та же страница должна иметь только один URL.
- Ссылки на другие разделы необходимо делать текстовыми, так Яндексу проще анализировать информацию.
- Нужно проверять корректность symlink-ов: когда пользователь переходит со страницы на страницу, адреса URL не должны суммироваться (пример от Яндекса, как быть не должно: example.com/name/name/name/name/).

Нельзя сказать, что требования просты. По большей части они касаются не только структуры, но и всего сайта целиком. Однако с предписаниями приходится считаться, так как Яндекс – популярнейший поисковик с огромной аудиторией.
Рекомендации от Google
Этот поисковик лаконичен. В отличие от Яндекса его требования к верстке просты, понятны и занимают всего несколько строк:
- простая структура;
- понятная логика URL-адреса;
- слова, а не идентификаторы;
- присутствие знаков пунктуации в URL (особенно рекомендуется дефис «-»);
- короткие и простые URL.


4 варианта создания структуры сайта
Предположим, вид структуры сайта выбран: линейная, линейная с ответвлениями, блочная или древовидная. Следующий шаг – определиться, как он будет реализован на практике, то есть запланировать страницы, разделы, подразделы и т. п. Визуальное представление (шрифт, цвет кнопок, расположение меню и пр.) пока не обсуждаются.
Структура во многом зависит от того, какие задачи должен решать ресурс. Выделяют четыре основных вида сайтов: визитка, коммерческий, информационный или блог, интернет-магазин. Остановимся на каждом подробнее.
Сайт-визитка

Обладает самой простой структурой. Как правило, состоит всего из двух уровней: главной страницы и остальных.
Коммерческий сайт
Информационный портал и блог
Здесь многоуровневость создается с помощью разделов, которые состоят из отдельных страниц. На эти страницы невозможно попасть из главного меню. Это основное отличие информационного сайта от коммерческого, на все подстраницы которого можно перейти из меню. Исключение – страницы со статьями. Иногда доступ к ним делают не только из меню, но даже с главной страницы.

Интернет-магазин
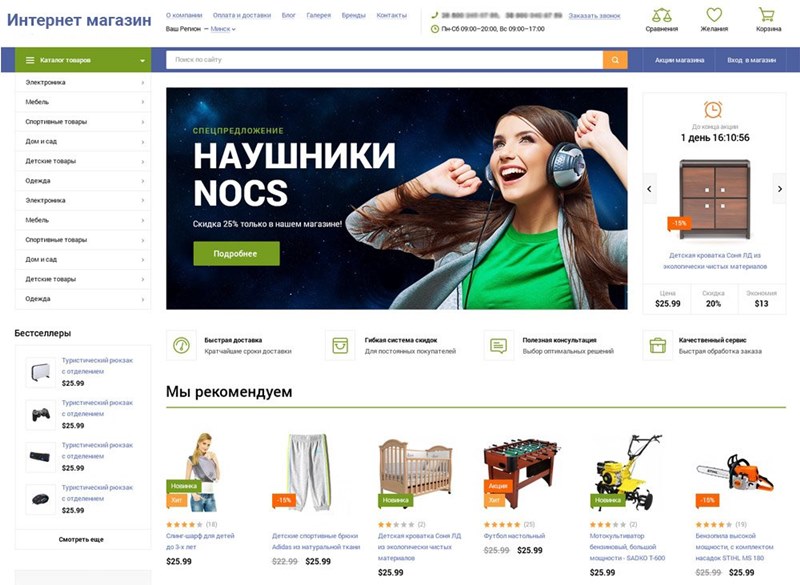
Хотя можно установить несколько фильтров, и тогда пользователи смогут группировать товары сразу по двум-трем и более свойствам. Ведь если магазин специализируется на продаже именно разноцветной мебели, то логично сделать фильтр по цветам. Разветвленная система фильтрации необходима, когда у товаров есть несколько основных характеристик, по которым люди их ищут в поисковых системах. Например, это может быть сочетание цвета и конструкции (диван синий угловой) или размера, цвета и материала (кровать двуспальная белая из дерева).
Фильтры необходимы, когда товары имеют несколько основных характеристик и варианты их сочетаний. Если же магазин специализируется на реализации конкретного продукта, например, одеял из верблюжьей шерсти, у которых меняется только размер, то система фильтрации не нужна.
У разделов каталога сайта могут быть как одинаковые фильтры, так и разные. Здесь все зависит от специфики реализуемой продукции.

Страницы, фигурирующие в структуре сайта
На сегодняшний день особой популярностью пользуются одностраничные сайты. Их структура проста, а создание несложное. Однако такой вид сайтов подходит не под все бизнес-задачи. Поэтому чаще всего встречаются многостраничные ресурсы.
Существует перечень базовых страниц. Не все они обязательно должны присутствовать в структуре сайта, однако поисковые системы обращают внимание на их наличие. Таким образом, включение базовых страниц в схему ресурса может облегчить продвижение по ключевым запросам.
К основным страницам относятся следующие:
Главная
Контакты
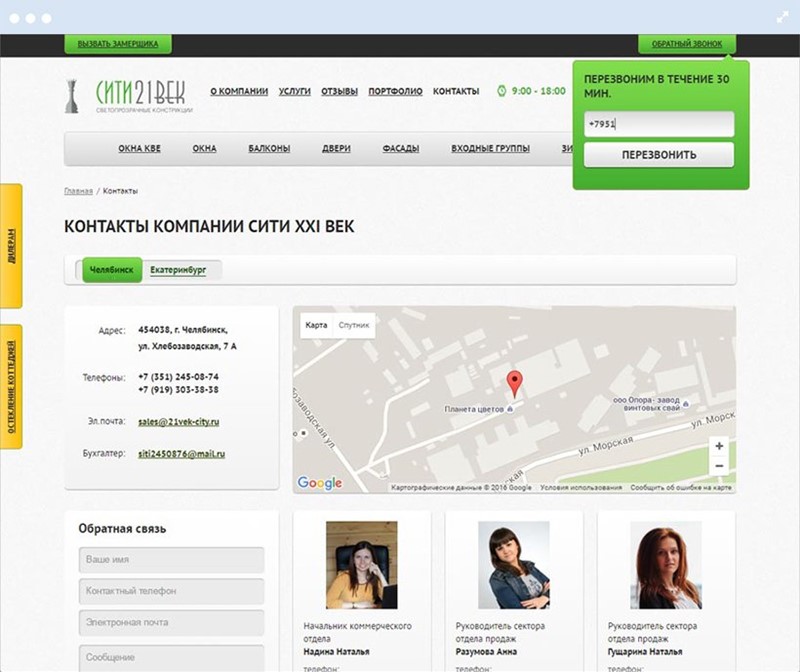
Это также одна из самых важных страниц структуры сайта. От того, легко ли ее найти и как она оформлена, зависит эффективность коммуникации с пользователями. Если у компании несколько каналов связи, то, как правило, приоритетные размещаются в шапке сайта, а остальные в «Контактах». Поисковые системы в первую очередь оценивают наличие этой страницы, поэтому важно, чтобы на ней была размещена максимально подробная информация о способах связи с компанией: городские телефоны, факс, электронную почту, фактический адрес с картой или схемой проезда, социальные сети, мессенджеры. Можно добавить реквизиты фирмы. Обязательно наличие микроразметки schema.org. Если у компании несколько городских номеров или почтовых ящиков, необходимо обозначить, какой за что отвечает. Также на странице «Контакты» должен присутствовать распорядок работы фирмы и период, в который принимаются звонки.
Типичными ошибками являются скудная контактная информация, непривлекательный дизайн, отсутствие микроразметки и стимулов связаться с компанией.
Доставка
Оплата
Вопрос ответ (FAQ)

Почему-то многие компании исключают этот раздел из структуры сайта, а ведь он очень важен. Как правило, люди задают примерно одинаковые вопросы. Если ответы на них разместить на сайте, это снимет часть нагрузки с телефонных операторов.
О компании
Отзывы (Обратная связь)
Если компания постоянно контактирует с клиентами, этот раздел необходим. Он должен быть легкодоступным и простым для заполнения. Не стоит делать раздел доступным только для зарегистрированных пользователей. Отзывы должны быть открыты для всех желающих их почитать.

Многие фирмы стимулируют своих клиентов делиться комментариями, предлагая подарки и дополнительные скидки. Хорошо зарекомендовали себя видеоотзывы. Если есть возможность включить их в структуру сайта, это нужно сделать.
Типичные ошибки – размещение отзывов с одного IP, заказные комментарии с завышенной оценкой компании, анонимные отзывы, небольшое количество публикаций.
Для партнёров (Оптовым клиентам)
Новости (Блог, события, статьи)
Этот раздел помогает привлекать пользователей из поисковиков. Публикуемый контент должен не только содержать ключевые запросы, но и быть интересным и полезным для посетителей сайта. Размещать материал следует регулярно и постоянно. Если у компании нет новостей, то лучше исключить этот раздел из структуры ресурса.
Типичные ошибки – публикации ненужного материала (например, поздравлений с государственными праздниками), редкое размещение статей (раз в месяц), некачественный контент.

Услуги
Страница ошибки 404

Типичные ошибки – отсутствие страницы 404, другой дизайн, отличимый от основного сайта, отсутствие информации для пользователей о том, что делать дальше.
Важность призыва к действию в структуре сайта
Какой бы ни была структура сайта, схема обязательно должна предусматривать призыв к действию. Как правило, он размещается в тексте несколько раз. Первый – сразу после специального предложения. Второй раз – в середине текста. Третий – в конце. Если текст длинный, призывов к действию может быть и больше. Они могут быть сформулированы одинаково или по-разному в зависимости от общего контекста статьи.
Иногда призывы делают двойными, например, «Купите товар и оформите подписку». Или добавляют предложение о выгоде: «Запишитесь на консультацию. Первая бесплатно!». Или ограничивают срок действия предложения: «Купите новые шины. Только сегодня скидка 20 %».

Если товар недорогой и его покупка не требует долгого обдумывания, призыв формулируется с помощью глаголов, обозначающих немедленное действие: купи, закажи, подпишись и т. п.
Когда товар дорогой или сложный или продажи осуществляются в В2В-сегменте, процесс принятия решения о покупке может занять долгое время. Призывы к немедленному действию здесь не сработают. Поэтому продавцы делают акцент на общение с клиентами и установление с ними крепкой эмоциональной связи. Потенциальных покупателей приглашают на бесплатные консультации, клиентские мероприятия, предоставляют пробную версию продукта и т. п.

Также в продажах дорогого или сложного товара для мотивации клиентов часто используются буклеты, электронные рассылки или ссылки. Они нужны тогда, когда потенциальный покупатель не готов общаться с менеджером по телефону или при личной встрече, но ему необходима информация о товаре, которая поможет принять окончательное решение.
Как правило, в конце посадочной страницы, помимо последнего призыва к действию, размещаются контакты компании, ссылка на форму оформления заказа, схема проезда, если у фирмы есть офлайн-офис.
Дополнительные фишки в структуре сайта
В процессе управления структурой сайта можно добавлять различные элементы, которые способны повысить эффективность ресурса. К таким фишкам относятся:
Сценарии использования товара
Форма подписки
Расписание события

Используется, если сайт посвящен мероприятию, протяжённому по времени и состоящему из отдельных этапов. Как правило, расписание оформляется как таблица или таймлайн. Если в событии принимает участие несколько спикеров, желательно разместить их ФИО и фото.
Счетчик обратного отсчета
Видеоконтент
Тезисный список преимуществ

Истории успеха клиентов
Всплывающие окна
Чаще всего в поп-апах размещается информация об акциях или предложение оформить подписку. Всплывающие окна могут появляться как самостоятельно, так и в результате определенного действия посетителя, например, нажатия кнопки.
Факты роста в цифрах
Кнопки обратной связи

От этих элементов напрямую зависит успешность коммуникации с аудиторией. Ведь чем проще человеку связаться с компанией, тем большим доверием он к ней проникнется. А от уровня лояльности целевой аудитории, как известно, напрямую зависит конверсия.
Меню
Иконки социальных сетей
Бывают двух видов: со ссылкой на профиль компании и на шаринг. Иконки могут располагаться в шапке главной страницы, в контактах, во всплывающих окнах.
Мотивирующая фраза

11 советов по разработке структуры сайта
Представление структуры сайта должно основываться не только на потребностях компании, но и на требованиях поисковых систем. Ниже описаны основные правила индексирования, по которым работают Яндекс и Google:
1.Слеш в конце адреса (пример: name.ru/gde-to-tut/) говорит поисковому роботу о том, что необходима индексация глубже. Однако если на этой странице нет внутренних ссылок, система может ее не проиндексировать. Поэтому слеш следует использовать аккуратно.
2. Не нужно страницам с дополнительными статьями давать название «Статьи». Поисковые роботы скорее всего их не проиндексируют. Лучше структурировать информацию и каждой странице присваивать уникальное имя.
3. Закрывайте служебные страницы от поисковых систем.
4. В структуре сайта должна быть предусмотрена строка навигации. Она подскажет пользователю, где он находится, и поможет вернуться на предыдущие уровни.

5. С каждой страницы должен быть переход на главную.
6. URL должен быть понятным человеку и логичным. Пример плохого адреса: name.ru/rt4566543tr/s45456/665665/345663/rtsrt/1t23. При создании ЧПУ (человеко понятных урлов) следует применять транслитерацию.
7. Если есть необходимость в четвертом и последующих уровнях, нужно делать карту сайта и больше ссылок с «верхних» страниц.
8. Правильный путь к страницам третьего уровня должен быть таким: Главная → Документ 2 уровня → Документ 3 уровня.
9. Уровень вложенности не глубже трех. Поисковые системы могут не проиндексировать более глубокие страницы.
10. Внутренняя перелинковка должна быть грамотной, так как она влияет на поведение пользователей и, соответственно, отношение поисковых роботов к страницам сайта.
11. Такие разделы, как «Каталог», «Услуги», следует размещать в одном клике от главной, желательно в ее верхней части. Они должны быть хорошо заметны и доступны для пользователей.