SQL-Ex blog

Мое мнение по этому поводу менялось на протяжении нескольких последних лет в связи с большим числом проблем с производительностью, над которыми приходилось работать. Я выступал на SQLSaturday 1000 (Oregon 2020) на прошлых выходных, и мой доклад был в основном о вещах, которые я узнал об оптимизации сборки мусора и аналогичных дополнительных процессах. Во время этой работы я столкнулся с рядом проблем с запросами, подобными следующему примеру для базы данных WideWorldImporters:
DELETE inv
FROM @OrdersGC gc
JOIN Sales.Invoices inv
ON inv.OrderID = gc.OrderID;
Вопросы заказов
Логика здесь достаточно проста. Ранее в процессе мы обнаружили заказы, которые хотели удалить в соответствии с политикой хранения, и поместили значения OrderID в табличную переменную, оптимизированную для памяти (motv). Затем мы используем motv для удаления из всех связанных таблиц, и наконец из таблицы Orders.
Этот запрос не имеет предложения WHERE. Ясно, что мы хотим сделать, чтобы это работало. У нас имеется 100 строк в нашей motv, и мы хотим удалить связанные строки в Invoices. Однако я увидел проблемы, вызываемые планами выполнения, которые нарушают порядок:
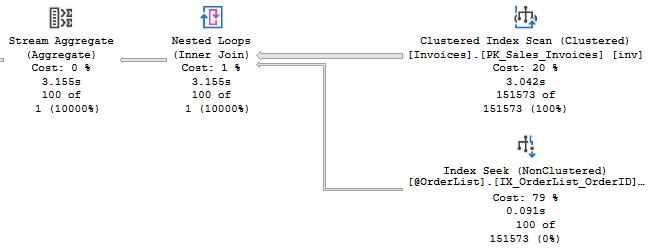
Табличные переменные не имеют статистики, поэтому оптимизатор не знает, сколько строк будет предположительно получено из этой операции (заметим, что табличные переменные иначе компилируются в SQL Server 2019, что может решить проблему). Время от времени я вижу план с порядком соединения, который не совпадает с моими ожиданиями. Здесь все портит отсутствие предложения WHERE, однако тут не существует предложения, которое я могу применить и которое выполнит фильтрацию лучше, чем это уже сделано в моей табличной переменной.
Согласованность
Я работаю с сотнями баз данных, имеющих одну и ту же схему. Они имеют только различные наборы данных и распределения, разные размеры, и их статистика обновляется в разное время. Но если одна из них выбирает плохой план, я должен отбросить всякую другую работу, чтобы исследовать причину высоких значений ЦП на базе данных xyz.
Согласованность весьма важна для меня. И в этом случае ответ прост. Да, я хочу быстро просканировать сначала небольшую оптимизированную для памяти табличную переменную, и использовать её для фильтрации большой более медленной таблицы. Добавление хинта соединения или указанного порядка должно согласовать план и производительность.
DELETE inv
FROM @OrderList gc
INNER LOOP JOIN Sales.Invoices inv
ON inv.OrderID = gc.OrderID;
DELETE inv
FROM @OrderList gc
JOIN Sales.Invoices inv
ON inv.OrderID = gc.OrderID
WITH OPTION(FORCE ORDER);
Оба варианта навязывают порядок соединения. Хинт INNER LOOP JOIN имеет дополнительное преимущество, гарантируя, что план использует соединение вложенными циклами. Соединение hash match не дало бы эффекта при размере пакета в несколько сотен или тысяч строк. Merge join потребовало бы, вероятно, сортировки одного из входов, а это не то, что нужно.
Индексные хинты
Мне пришлось использовать индексный хинт в следующем примере:
DELETE TOP (@BatchSize) vt
FROM Warehouse.VehicleTemperatures vt
WHERE vt.RecordedWhen < DATEADD(DAY, -180, GETUTCDATE());
Это был пример процесса сборки мусора. План не выявляет проблемы, но следует с подозрением отнестись к сканированию здесь:
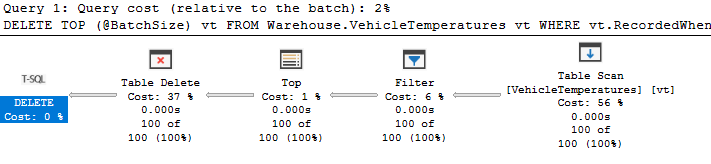
Сканирование таблицы читает только 100 строк, но это потому, что используется оператор ТОР. Первые 100 строк отвечают нашему фильтру, поэтому запрос заканчивается в этом месте. Если никакие строки не отвечают критерию (или их меньше 100), нам придется сканировать всю таблицу.
На столбце RecordedWhen имеется индекс; просто он не был использован. Это другой случай, когда применение хинта кажется очевидным. Возможно, обновление статистики также решило бы проблему, но это дает мне больше уверенности.
DELETE TOP (@BatchSize) vt
FROM Warehouse.VehicleTemperatures vt WITH (INDEX(IX_VehicleTemperatures_RecordedWhen))
WHERE
vt.RecordedWhen < DATEADD(DAY, -180, GETUTCDATE());
Большая ответственность
При использовании хинтов мы принимаем на себя некоторую ответственность, за которую не отвечает SQL Server, и мы можем получить новые проблемы. Ниже приводятся некоторые моменты, которые следует принять во внимание, прежде чем вы попытаетесь применить хинт.
- Связи. Убедитесь, что вы представляете себе объем и связи между таблицами. Это позволит вам представить ожидаемое число строк, которое будет возвращено.
- Индексы. Представление о возможных вариантах для каждой таблицы в запросе. Таблица может использовать один индекс на основе предложения WHERE, или другой на основе предложения ON. Порядок соединения и используемые индексы связаны. Индексный хинт может подтолкнуть SQL Server к конкретному порядку соединения; как и с хинтами соединения/порядка.
- Индексные хинты могут повредить ваш код! Если вы используете индексный хинт в процедуре, а позже удаляете индекс, SQL Server не будет вежливо игнорировать ваше предложение и продолжать выполнение. Процедура будет завершаться с ошибкой, пока вы не удалите хинт или не восстановите индекс. Поэтому, если вы используете индексные хинты, будьте уверены в этом, и всегда проверяйте, нет ли хинтов, ссылающихся на индекс, прежде чем удалить его.
- Наиболее эффективный фильтр. Если логика вашего оператора фильтрует данные в нескольких таблицах, подумайте, какой из фильтров должен максимально уменьшить ваш результирующий набор. Вероятно, вы захотите иметь эту таблицу первой в вашем плане выполнения.
- Тестируйте снова и снова. Новые планы могут существенно отличаться от того, который мы себе представляем, поэтому мы должны тщательно тестировать наши запросы и процедуры с хинтами. Тестируйте на различных вариантах использования, чтобы гарантировать работоспособность вашего кода на реальных данных. Сам я буду периодически тестировать на больших и малых восстановленных базах данных, чтобы убедиться, что код выполняется так, как ожидалось.
Один из моих коллег недавно решил проблему с производительностью, изменив порядок соединения с помощью хинта, или, по его словам, «выполнив Jared Poche». Это говорит о том, как часто я использовал подсказки, и как часто они срабатывали.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
SQL Server Plan Guide и другие не самые лучшие практики
Обычно посты об оптимизации запросов рассказывают о том, как делать правильные вещи, чтобы помочь оптимизатору запросов выбрать оптимальный план выполнения: использовать SARGable-выражения в WHERE, доставать только те столбцы, которые нужны, использовать правильнопостроенные индексы, дефрагментированные и с обновлённой статистикой.
Я же сегодня хочу поговорить о другом — о том, что ни в коем случае не относится к best practices, том, с помощью чего очень легко выстрелить себе в ногу и сделать выполнявшийся ранее запрос более медленным, или вообще больше не выполняющимся из-за ошибки. Речь пойдёт о хинтах и plan guides.
Хинты — это «подсказки» оптимизатору запросов, полный список можно найти в MSDN. Часть из них — это и правда подсказки (например, можно указать OPTION (MAXDOP 4)), чтобы запрос мог выполняться с max degree of parallelism = 4, но нет никаких гарантий, что SQL Server вообще сгенерирует с этим хинтом паралелльный план.
Другая часть — прямое руководство к действию. Например, если вы напишете OPTION (HASH JOIN), то SQL Server будет строить план без NESTED LOOPS и MERGE JOIN'ов. И знаете что будет, если окажется, что невозможно построить план только с хэш джойнами? Оптимизатор так и скажет — не могу построить план и запрос выполняться не будет.
Проблема в том, что доподлинно неизвестно (по крайней мере мне) какие хинты — это хинты-подсказки, на которые оптимизатор может забить; а какие хинты — хинты-руководства, которые могут привести к тому, что запрос упадёт, если что-то пойдёт не так. Наверняка уже есть какой-то готовый сборник, где это описано, но это в любом случае не официальная информация и может измениться в любой момент.
Plan Guide — это такая штука (которую я не знаю как корректно перевести), которая позволяет привязать к конкретному запросу, текст которого вам известен, конкретный набор хинтов. Это может быть актуальным, если вы не можете напрямую влиять на текст запроса, который формируется ORM, например.
И хинты, и plan guide'ы ни в коем случае не относятся к лучшим практикам, скорее хорошей практикой является отсутствие хинтов и этих гайдов, потому что распределение данных может поменяться, типы данных могут измениться и может произойти ещё миллион вещей, из-за которых ваши запросы с хинтами станут работать хуже чем без них, а в некоторых случаях и вообще перестанут работать. Вы на сто процентов должны отдавать себе отчёт в том что вы делаете и зачем.
Теперь маленькое объяснение зачем я вообще в это полез.
У меня есть широкая таблица с кучей nvarchar-полей разной размерности — от 10 до max. И есть куча запросов к этой таблице, которая CHARINDEX'ом ищет вхождение подстрок в одном или нескольких из этих столбцов. Например, есть запрос, который выглядит таким образом:
SELECT * FROM table WHERE CHARINDEX(N'пользовательский текст', column)>1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET x ROWS FETCH NEXT y ROWS ONLYВ таблице есть кластерный индекс по Id и неуникальный некластерный индекс по column. Как вы сами понимаете, толку от всего этого ноль, поскольку в WHERE мы используем CHARINDEX, который совершенно однозначно не SARGable. Чтобы избежать возможных проблем с СБ, я смоделирую эту ситуацию на открытой БД StackOverflow2013, которую можно найти здесь.
Рассмотрим таблицу dbo.Posts, в которой есть только кластерный индекс по Id и такой запрос:
SELECT * FROM dbo.Posts WHERE CHARINDEX (N'Data', Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLYДля соответствия моей реальной БД, создаю индекс по колонке Title:
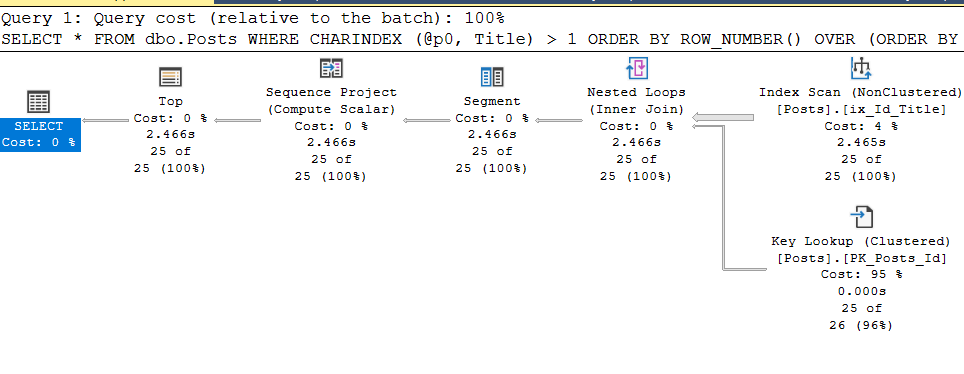
CREATE INDEX ix_Title ON dbo.Posts (Title);В результате, конечно, мы получаем абсолютно логичный план выполнения, который состоит из сканирования кластерного индекса в обратном направлении:
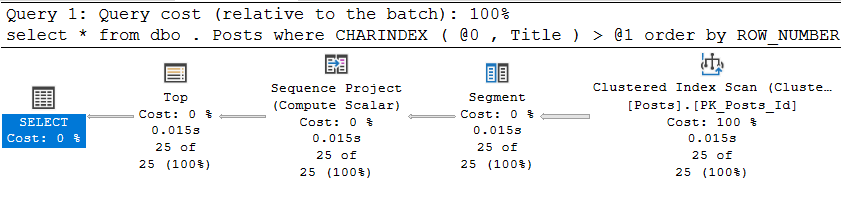

И он, надо признать, выполняется достаточно неплохо:
Table 'Posts'. Scan count 1, logical reads 516, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms
Но что произойдёт, если вместо частовстречаемого слова 'Data' мы будем искать что-то более редкое? Например, N'Aptana' (без понятия, что это такое). План, естественно, останется прежним, а вот статистика выполнения, кхм, несколько изменится:
Table 'Posts'. Scan count 1, logical reads 253191, physical reads 113, read-ahead reads 224602, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 2563 ms
И это тоже логично — слово встречается гораздо реже и SQL Server приходится сканировать намного больше данных, чтобы найти 25 строк с ним. Но как-то не круто же, да?
А я же создавал некластерный индекс. Может быть будет лучше, если SQL Server использует его? Сам он его использовать не будет, поэтому добавляю хинт:
SELECT * FROM dbo.Posts WHERE CHARINDEX (N'Aptana', Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Title)));И, что-то как-то совсем грустно. Статистика выполнения:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 5, logical reads 109312, physical reads 5, read-ahead reads 104946, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 35031 ms

Теперь план выполнения параллельный и в нём две сортировки, причём обе из них со spill'ами в tempdb. Кстати, обратите внимание на первую сортировку, которая выполняется после сканирования некластерного индекса, перед Key Lookup — это специальная оптимизация SQL Server, которая пытается уменьшить количество Random I/O — key lookup'ы проводятся в порядке нарастания ключа кластерного индекса. Прочитать про это подробнее можно здесь.
Вторая сортировка нужна для того, чтобы отобрать 25 строк по убыванию Id. Кстати, SQL Server мог бы и догадаться, что ему придётся опять сортировать по Id, только по убыванию и делать key lookup'ы в «обратном» направлении, сортируя в начале по убыванию, а не возрастанию ключа кластерного индекса.
Статистику выполнения запроса с хинтом на некластерный индекс с поиском по вхождению 'Data' я не привожу. На моём полудохлом жёстком диске в ноуте, он выполнялся больше 16 минут и я не додумался снять скриншот. Извините, больше я не хочу столько ждать.
Но что же делать с запросом? Неужели сканирование кластерного индекса — это предел мечтаний и быстрее сделать ничего не получится?
А что, если попробовать избежать всех сортировок, подумал я и создал некластерный индекс, который, в общем-то, противоречит тому, что обычно считается best practices для некластерных индексов:
CREATE INDEX ix_Id_Title ON dbo.Posts (Id DESC, Title);Теперь хинтом указываем SQL Server использовать именно его:
SELECT * FROM dbo.Posts WHERE CHARINDEX (N'Aptana', Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Id_Title)));О, неплохо получилось:

Table 'Posts'. Scan count 1, logical reads 6259, physical reads 0, read-ahead reads 7816, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1734 ms
Выигрыш по процессорному времени не велик, а вот читать приходится намного меньше — неплохо. А что для частовстречающейся 'Data'?
Table 'Posts'. Scan count 1, logical reads 208, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms
Ого, тоже хорошо. Теперь, поскольку запрос приходит от ORM и мы не можем менять его текст, нужно придумать как «прибить» этот индекс к запросу. И на помощь приходит plan guide.
Для создания plan guide используется хранимая процедура sp_create_plan_guide (MSDN).
Рассмотрим её подробно:
sp_create_plan_guide [ @name = ] N'plan_guide_name' , [ @stmt = ] N'statement_text' , [ @type = ] N'< OBJECT | SQL | TEMPLATE >' , [ @module_or_batch = ] < N'[ schema_name. ] object_name' | N'batch_text' | NULL >, [ @params = ] < N'@parameter_name data_type [ . n ]' | NULL >, [ @hints = ]
name — понятно, уникальное имя plan guide
stmt — это тот запрос, к которому нужно добавить хинт. Тут важно знать, что этот запрос должен быть написан ТОЧНО ТАК ЖЕ, как запрос, который приходит от приложения. Лишний пробел? Plan Guide не будет использоваться. Перенос строки не в том месте? Plan Guide не будет использоваться. Чтобы упростить себе задачу, есть «лайфхак», к которому я вернусь чуть позже (и который нашёл здесь).
type — указывает на то, где используется запрос, указанный в stmt. Если это часть хранимой процедуры — тут должно быть OBJECT; если это часть какого-то батча из нескольких запросов или это ad-hoc запрос, или батч из одного запроса — тут должно быть SQL. Если же тут указано TEMPLATE — это отдельная история про параметризацию запросов, про которую можно прочитать в MSDN.
@module_or_batch зависит от type. Если type = 'OBJECT', тут должно быть имя хранимой процедуры. Если type = 'BATCH' — тут должен быть текст всего батча, указанный слово-в-слово с тем, что приходит от приложений. Лишний пробел? Ну вы уже в курсе. Если тут NULL — значит считаем, что это батч из одного запроса и он совпадает с тем, что указано в stmt со всеми ограничениями.
params — тут должны быть перечислены все параметры, которые передаются в запрос вместе с типами данных.
@hints — это наконец-то приятная часть, тут нужно указать какие хинты нужно добавить к запросу. Тут же можно явно вставить требуемый план выполнения в формате XML, если он есть. Ещё этот параметр может принимать значение NULL, что приведёт к тому, что SQL Server не будет использовать хинты которые явно указаны в запросе в stmt.
Итак, создаём Plan Guide для запроса:
DECLARE @sql nvarchar(max) = N'SELECT * FROM dbo.Posts WHERE CHARINDEX (N''Data'', Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY'; exec sp_create_plan_guide @name = N'PG_dboPosts_Index_Id_Title' , @stmt = @sql , @type = N'SQL' , @module_or_batch = NULL , @params = NULL , @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'И пробуем выполнить запрос:
SELECT * FROM dbo.Posts WHERE CHARINDEX (N'Data', Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY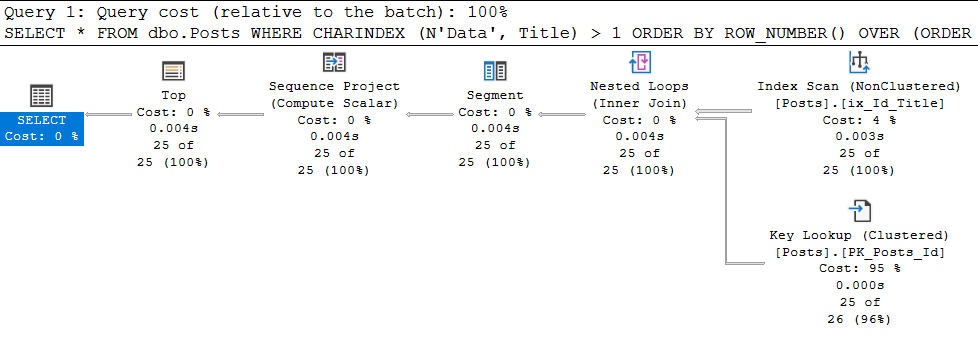
В свойствах последнего оператора SELECT, видим:

Отлично, plan giude применился. А что, если теперь поискать 'Aptana'? А всё будет плохо — мы снова вернёмся к сканированию кластерного индекса со всеми вытекающими. Почему? А потому что, plan guide применяется к КОНКРЕТНОМУ запросу, текст которого один к одному совпадает с выполняющимся.
К счастью для меня, большая часть запросов в моей системе, приходит параметризованной. С непараметризованными запросами я не работал и надеюсь не придётся. Для них можно использовать шаблоны (смотри чуть выше про TEMPLATE), можно включить FORCED PARAMETERIZATION в БД (не делайте этого без понимания того, что вы делаете. ) и, возможно, после этого, получится привязать Plan Guide. Но я правда не пробовал.
В моём случае запрос выполняется примерно таким образом:
exec sp_executesql N'SELECT * FROM dbo.Posts WHERE CHARINDEX (@p0, Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;' , N'@p0 nvarchar(250), @p1 int, @p2 int' , @p0 = N'Aptana', @p1 = 0, @p2 = 25;Поэтому я создаю соответствующий plan guide:
DECLARE @sql nvarchar(max) = N'SELECT * FROM dbo.Posts WHERE CHARINDEX (@p0, Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'; exec sp_create_plan_guide @name = N'PG_paramters_dboPosts_Index_Id_Title' , @stmt = @sql , @type = N'SQL' , @module_or_batch = NULL , @params = N'@p0 nvarchar(250), @p1 int, @p2 int' , @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'И, ура, всё работает как требовалось:

Находясь вне тепличных условий, не всегда получается корректно указать параметр stmt, чтобы прицепить plan guide к запросу и для этого есть «лайфхак», о котором я упоминал выше. Очищаем кэш планов, удаляем гайды, выполняем параметризованный запрос ещё раз и достаём из кэша его план выполнения и его plan_handle.
Запрос для этого можно использовать, например, такой:
SELECT qs.plan_handle, st.text, qp.query_plan FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) st CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qpТеперь мы можем использовать хранимую процедуру sp_create_plan_guide_from_handle для создания plan guide из существующего плана.
Она принимает в качестве параметров name — имя создаваемого гайда, @plan_handle — handle существующего плана выполнения и @statement_start_offset — который определяет начало стэйтмента в батче, для которого должен быть создан гайд.
exec sp_create_plan_guide_from_handle N'PG_dboPosts_from_handle' , 0x0600050018263314F048E3652102000001000000000000000000000000000000000000000000000000000000 , NULL;И теперь в SSMS смотрим, что у нас в Programmability -> Plan Guides:

Сейчас к нашему запросу «гвоздями прибит» текущий план выполнения, с помощью Plan Guide 'PG_dboPosts_from_handle', но, что самое приятное, теперь его, как и почти любой объект в SSMS, можно заскриптовать и пересоздать таким, какой нужен нам.
ПКМ, Script -> Drop AND Create и получаем готовый скрипт, в котором нам нужно заменить значение параметра @hints на нужное нам, так что в результате получаем:
USE [StackOverflow2013] GO /****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/ EXEC sp_control_plan_guide @operation = N'DROP', @name = N'[PG_dboPosts_from_handle]' GO /****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/ EXEC sp_create_plan_guide @name = N'[PG_dboPosts_from_handle]', @stmt = N'SELECT * FROM dbo.Posts WHERE CHARINDEX (@p0, Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY', @type = N'SQL', @module_or_batch = N'SELECT * FROM dbo.Posts WHERE CHARINDEX (@p0, Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;', @params = N'@p0 nvarchar(250), @p1 int, @p2 int', @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))' GOВыполняем и повторно выполняем запрос. Ура, всё работает:

Если заменить значение параметра, всё точно так же работает.
Обратите внимание, одному стэйтменту может соответствовать только один гайд. При попытке добавить тому же стэйтменту ещё один гайд, будет получено сообщение об ошибке.
Msg 10502, Level 16, State 1, Line 1
Cannot create plan guide 'PG_dboPosts_from_handle2' because the statement specified by stmt and @module_or_batch, or by @plan_handle and @statement_start_offset, matches the existing plan guide 'PG_dboPosts_from_handle' in the database. Drop the existing plan guide before creating the new plan guide.
Последнее, о чём хотел бы упомянуть — это о хранимой процедуре sp_control_plan_guide.
С её помощью можно удалять, отключать и включать Plan Guide'ы — как по одному, с указанием имени, так и все гайды (не уверен — вообще все. или все в контексте той БД, в которой выполняется процедура) — для этого используются значения параметра @operation — DROP ALL, DISABLE ALL, ENABLE ALL. Пример использования ХП для конкретного плана приведён чуть выше — удаляется конкретный Plan Guide, с указанным именем.
А можно ли было обойтись без хинтов и plan guide?
Вообще, если вам кажется, что оптимизатор запросов туп и делает какую-то дичь, а вы знаете как лучше — с вероятностью 99% какую-то дичь делаете вы (как и в моём случае). Однако в случае, когда у вас нет возможности напрямую влиять на текст запроса, plan guide, позволяющий добавить хинт к запросу может стать спасением. Предположим, что у нас есть возможность переписать текст запроса так, как нам нужно — может ли это что-то изменить? Конечно! Даже без использования «экзотики» в виде полнотекстового поиска, который, по сути, и должен тут использоваться. Например, у такого запроса вполне нормальный (для запроса) план и статистика выполнения:
;WITH c AS ( SELECT p2.id FROM dbo.Posts p2 WHERE CHARINDEX (N'Aptana', Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY ) SELECT p.* FROM dbo.Posts p JOIN c ON p.id = c.id;
Table 'Posts'. Scan count 1, logical reads 6250, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1500 ms
SQL Server сначала находит по «кривому» индексу ix_Id_Title нужные 25 идентификаторов, а только потом делает поиск в кластерном индексе по выбранным идентификаторам — даже лучше, чем с гайдом! А вот, что будет, если мы выполним запрос по 'Data' и выведем 25 строк, начиная с 20000-й строки:
;WITH c AS ( SELECT p2.id FROM dbo.Posts p2 WHERE CHARINDEX (N'Data', Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET 20000 ROWS FETCH NEXT 25 ROWS ONLY ) SELECT p.* FROM dbo.Posts p JOIN c ON p.id = c.id;
Table 'Posts'. Scan count 1, logical reads 5914, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms
exec sp_executesql N'SELECT * FROM dbo.Posts WHERE CHARINDEX (@p0, Title) > 1 ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC) OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;' , N'@p0 nvarchar(250), @p1 int, @p2 int' , @p0 = N'Data', @p1 = 20000, @p2 = 25;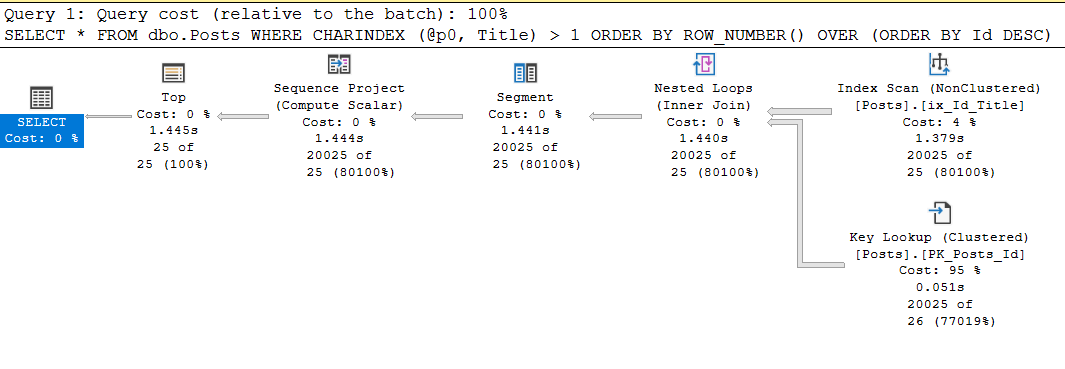
Table 'Posts'. Scan count 1, logical reads 87174, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1437 ms
Да, процессорное время одинаково, поскольку и тратится-то оно на charindex, но вот чтений запрос с гайдом делает на порядок больше, и это может стать проблемой.
Подведу окончательный итог. Хинты и гайды могут очень сильно помочь вам «здесь и сейчас», но с их помощью очень легко сделать происходящее ещё хуже. Если вы явно указываете в тексте запроса хинт с указанием индекса, а потом удаляете индекс — запрос просто не сможет выполниться. На моём SQL Server 2017 запрос с гайдом, после удаления индекса, выполняется нормально — гайд игнорируется, но я не могу быть уверен, что так будет всегда и во всех версиях SQL Server.
На русском про plan guide информации не очень много, поэтому решил написать сам. Тут можно почитать про ограничения в использовании plan guides, в частности про то, что иногда явное указание индекса хинтом с помощью PG может приводить к тому, что запросы будут падать. Желаю вам никогда ими не пользоваться, а если и придётся — ну, желаю удачи — вы знаете к чему это может привести.
- Microsoft SQL Server
- Администрирование баз данных
16 Using Optimizer Hints
Optimizer hints can be used with SQL statements to alter execution plans. This chapter explains how to use hints to instruct the optimizer to use specific approaches.
The chapter contains the following sections:
- Understanding Optimizer Hints
- Specifying Hints
- Using Hints with Views
16.1 Understanding Optimizer Hints
Hints let you make decisions usually made by the optimizer. As an application designer, you might know information about your data that the optimizer does not know. Hints provide a mechanism to instruct the optimizer to choose a certain query execution plan based on the specific criteria.
For example, you might know that a certain index is more selective for certain queries. Based on this information, you might be able to choose a more efficient execution plan than the optimizer. In such a case, use hints to instruct the optimizer to use the optimal execution plan.
The use of hints involves extra code that must be managed, checked, and controlled.
16.1.1 Types of Hints
Hints can be of the following general types:
- Single-table Single-table hints are specified on one table or view. INDEX and USE_NL are examples of single-table hints.
- Multi-table Multi-table hints are like single-table hints, except that the hint can specify one or more tables or views. LEADING is an example of a multi-table hint. Note that USE_NL(table1 table2) is not considered a multi-table hint because it is actually a shortcut for USE_NL(table1) and USE_NL(table2) .
- Query block Query block hints operate on single query blocks. STAR_TRANSFORMATION and UNNEST are examples of query block hints.
- Statement Statement hints apply to the entire SQL statement. ALL_ROWS is an example of a statement hint.
16.1.2 Hints by Category
Optimizer hints are grouped into the following categories:
- Hints for Optimization Approaches and Goals
- Hints for Access Paths
- Hints for Query Transformations
- Hints for Join Orders
- Hints for Join Operations
- Hints for Parallel Execution
- Additional Hints
These categories, and the hints contained within each category, are listed in the sections that follow.
Oracle Database SQL Language Reference for syntax and a more detailed description of each hint
16.1.2.1 Hints for Optimization Approaches and Goals
The following hints let you choose between optimization approaches and goals:
If a SQL statement has a hint specifying an optimization approach and goal, then the optimizer uses the specified approach regardless of the presence or absence of statistics, the value of the OPTIMIZER_MODE initialization parameter , and the OPTIMIZER_MODE parameter of the ALTER SESSION statement.
The optimizer goal applies only to queries submitted directly. Use hints to specify the access path for any SQL statements submitted from within PL/SQL. The ALTER SESSION . SET OPTIMIZER_MODE statement does not affect SQL that is run from within PL/SQL.
If you specify either the ALL_ROWS or the FIRST_ROWS ( n ) hint in a SQL statement, and if the data dictionary does not have statistics about tables accessed by the statement, then the optimizer uses default statistical values, such as allocated storage for such tables, to estimate the missing statistics and to subsequently choose an execution plan. These estimates might not be as accurate as those gathered by the DBMS_STATS package, so you should use the DBMS_STATS package to gather statistics.
If you specify hints for access paths or join operations along with either the ALL_ROWS or FIRST_ROWS ( n ) hint, then the optimizer gives precedence to the access paths and join operations specified by the hints.
16.1.2.2 Hints for Access Paths
Each of the following hints instructs the optimizer to use a specific access path for a table:
Specifying one of these hints causes the optimizer to choose the specified access path only if the access path is available based on the existence of an index or cluster and on the syntactic constructs of the SQL statement. If a hint specifies an unavailable access path, then the optimizer ignores it.
You must specify the table to be accessed exactly as it appears in the statement. If the statement uses an alias for the table, then use the alias rather than the table name in the hint. The table name within the hint should not include the schema name if the schema name is present in the statement.
For access path hints, Oracle ignores the hint if you specify the SAMPLE option in the FROM clause of a SELECT statement.
Oracle Database SQL Language Reference for more information on the SAMPLE option
16.1.2.3 Hints for Query Transformations
Each of the following hints instructs the optimizer to use a specific SQL query transformation:
16.1.2.4 Hints for Join Orders
The following hints suggest join orders:
16.1.2.5 Hints for Join Operations
Each of the following hints instructs the optimizer to use a specific join operation for a table:
Use of the USE_NL and USE_MERGE hints is recommended with any join order hint. See "Hints for Join Orders". Oracle uses these hints when the referenced table is forced to be the inner table of a join; the hints are ignored if the referenced table is the outer table.
16.1.2.6 Hints for Parallel Execution
The hints that follow instruct the optimizer about how statements are parallelized or not parallelized when using parallel execution:
Oracle Database Data Warehousing Guide for more information on parallel execution
16.1.2.7 Additional Hints
The following are several additional hints:
16.2 Specifying Hints
Hints apply only to the optimization of the block of a statement in which they appear. A statement block is any one of the following statements or parts of statements:
- A simple SELECT , UPDATE , or DELETE statement
- A parent statement or subquery of a complex statement
- A part of a compound query
For example, a compound query consisting of two component queries combined by the UNION operator has two blocks, one for each component query. For this reason, hints in the first component query apply only to its optimization, not to the optimization of the second component query.
The following sections discuss the use of hints in more detail.
- Specifying a Full Set of Hints
- Specifying a Query Block in a Hint
- Specifying Global Table Hints
- Specifying Complex Index Hints
16.2.1 Specifying a Full Set of Hints
When using hints, in some cases, you might need to specify a full set of hints in order to ensure the optimal execution plan. For example, if you have a very complex query, which consists of many table joins, and if you specify only the INDEX hint for a given table, then the optimizer needs to determine the remaining access paths to be used, as well as the corresponding join methods. Therefore, even though you gave the INDEX hint, the optimizer might not necessarily use that hint, because the optimizer might have determined that the requested index cannot be used due to the join methods and access paths selected by the optimizer.
In Example 16-1, the LEADING hint specifies the exact join order to be used; the join methods to be used on the different tables are also specified.
Example 16-1 Specifying a Full Set of Hints
SELECT /*+ LEADING(e2 e1) USE_NL(e1) INDEX(e1 emp_emp_id_pk) USE_MERGE(j) FULL(j) */ e1.first_name, e1.last_name, j.job_id, sum(e2.salary) total_sal FROM employees e1, employees e2, job_history j WHERE e1.employee_id = e2.manager_id AND e1.employee_id = j.employee_id AND e1.hire_date = j.start_date GROUP BY e1.first_name, e1.last_name, j.job_id ORDER BY total_sal;
16.2.2 Specifying a Query Block in a Hint
To identify a query block in a query, an optional query block name can be used in a hint to specify the query block to which the hint applies. The syntax of the query block argument is of the form @ queryblock , where queryblock is an identifier that specifies a query block in the query. The queryblock identifier can either be system-generated or user-specified.
- The system-generated identifier can be obtained by using EXPLAIN PLAN for the query. Pre-transformation query block names can be determined by running EXPLAIN PLAN for the query using the NO_QUERY_TRANSFORMATION hint.
- The user-specified name can be set with the QB_NAME hint.
In Example 16-2, the query block name is used with the NO_UNNEST hint to specify a query block in a SELECT statement on the view.
Example 16-2 Using a Query Block in a Hint
CREATE OR REPLACE VIEW v AS SELECT e1.first_name, e1.last_name, j.job_id, sum(e2.salary) total_sal FROM employees e1, ( SELECT * FROM employees e3) e2, job_history j WHERE e1.employee_id = e2.manager_id AND e1.employee_id = j.employee_id AND e1.hire_date = j.start_date AND e1.salary = ( SELECT max(e2.salary) FROM employees e2 WHERE e2.department_id = e1.department_id ) GROUP BY e1.first_name, e1.last_name, j.job_id ORDER BY total_sal;
After running EXPLAIN PLAN for the query and displaying the plan table output, you can determine the system-generated query block identifier. For example, a query block name is displayed in the following plan table output:
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY(NULL, NULL, 'SERIAL')); . Query Block Name / Object Alias (identified by operation id): ------------------------------------------------------------- . 10 - SEL$4 / E2@SEL$4
After the query block name is determined it can be used in the following SQL statement:
SELECT /*+ NO_UNNEST( @SEL$4 ) */ * FROM v;
16.2.3 Specifying Global Table Hints
Hints that specify a table generally refer to tables in the DELETE , SELECT , or UPDATE query block in which the hint occurs, not to tables inside any views referenced by the statement. When you want to specify hints for tables that appear inside views, Oracle recommends using global hints instead of embedding the hint in the view. Table hints described in this chapter can be transformed into a global hint by using an extended tablespec syntax that includes view names with the table name.
In addition, an optional query block name can precede the tablespec syntax. See "Specifying a Query Block in a Hint".
Hints that specify a table use the following syntax:
- view specifies a view name
- table specifies the name or alias of the table
If the view path is specified, the hint is resolved from left to right, where the first view must be present in the FROM clause, and each subsequent view must be specified in the FROM clause of the preceding view.
For example, in Example 16-3 a view v is created to return the first and last name of the employee, his or her first job and the total salary of all direct reports of that employee for each employee with the highest salary in his or her department. When querying the data, you want to force the use of the index emp_job_ix for the table e3 in view e2 .
Example 16-3 Using Global Hints Example
CREATE OR REPLACE VIEW v AS SELECT e1.first_name, e1.last_name, j.job_id, sum(e2.salary) total_sal FROM employees e1, ( SELECT * FROM employees e3) e2, job_history j WHERE e1.employee_id = e2.manager_id AND e1.employee_id = j.employee_id AND e1.hire_date = j.start_date AND e1.salary = ( SELECT max(e2.salary) FROM employees e2 WHERE e2.department_id = e1.department_id) GROUP BY e1.first_name, e1.last_name, j.job_id ORDER BY total_sal;
By using the global hint structure, you can avoid the modification of view v with the specification of the index hint in the body of view e2 . To force the use of the index emp_job_ix for the table e3 , you can use one of the following:
SELECT /*+ INDEX(v.e2.e3 emp_job_ix) */ * FROM v; SELECT /*+ INDEX(@SEL$2 e2.e3 emp_job_ix) */ * FROM v; SELECT /*+ INDEX(@SEL$3 e3 emp_job_ix) */ * FROM v;
The global hint syntax also applies to unmergeable views as in Example 16-4.
Example 16-4 Using Global Hints with NO_MERGE
CREATE OR REPLACE VIEW v1 AS SELECT * FROM employees WHERE employee_id < 150; CREATE OR REPLACE VIEW v2 AS SELECT v1.employee_id employee_id, departments.department_id department_id FROM v1, departments WHERE v1.department_id = departments.department_id; SELECT /*+ NO_MERGE(v2) INDEX(v2.v1.employees emp_emp_id_pk) FULL(v2.departments) */ * FROM v2 WHERE department_id = 30;
The hints cause v2 not to be merged and specify access path hints for the employee and department tables. These hints are pushed down into the (nonmerged) view v2 .
16.2.4 Specifying Complex Index Hints
Hints that specify an index can use either a simple index name or a parenthesized list of columns as follows:
- table specifies the name
- column specifies the name of a column in the specified table
- The columns can optionally be prefixed with table qualifiers allowing the hint to specify bitmap join indexes where the index columns are on a different table than the indexed table. If tables qualifiers are present, they must be base tables, not aliases in the query.
- Each column in an index specification must be a base column in the specified table, not an expression. Function-based indexes cannot be hinted using a column specification unless the columns specified in the index specification form the prefix of a function-based index.
The hint is resolved as follows:
- If an index name is specified, only that index is considered.
- If a column list is specified and an index exists whose columns match the specified columns in number and order, only that index is considered. If no such index exists, then any index on the table with the specified columns as the prefix in the order specified is considered. In either case, the behavior is exactly as if the user had specified the same hint individually on all the matching indexes.
For example, in Example 16-3 the job_history table has a single-column index on the employee_id column and a concatenated index on employee_id and start_date columns. To specifically instruct the optimizer on index use, the query can be hinted as follows:
SELECT /*+ INDEX(v.j jhist_employee_ix (employee_id start_date)) */ * FROM v;
16.3 Using Hints with Views
Oracle does not encourage the use of hints inside or on views (or subqueries). This is because you can define views in one context and use them in another. Also, such hints can result in unexpected execution plans. In particular, hints inside views or on views are handled differently, depending on whether the view is mergeable into the top-level query.
If you want to specify a hint for a table in a view or subquery, then the global hint syntax is recommended. See "Specifying Global Table Hints".
If you decide, nonetheless, to use hints with views, the following sections describe the behavior in each case.
- Hints and Complex Views
- Hints and Mergeable Views
- Hints and Nonmergeable Views
16.3.1 Hints and Complex Views
By default, hints do not propagate inside a complex view. For example, if you specify a hint in a query that selects against a complex view, then that hint is not honored, because it is not pushed inside the view.
If the view is a single-table, then the hint is not propagated.
Unless the hints are inside the base view, they might not be honored from a query against the view.
16.3.2 Hints and Mergeable Views
This section describes hint behavior with mergeable views.
Optimization Approaches and Goal Hints in Views
Optimization approach and goal hints can occur in a top-level query or inside views.
- If there is such a hint in the top-level query, then that hint is used regardless of any such hints inside the views.
- If there is no top-level optimizer mode hint, then mode hints in referenced views are used as long as all mode hints in the views are consistent.
- If two or more mode hints in the referenced views conflict, then all mode hints in the views are discarded and the session mode is used, whether default or user-specified.
Access Path and Join Hints on Views
Access path and join hints on referenced views are ignored, unless the view contains a single table (or references an Additional Hints view with a single table). For such single-table views, an access path hint or a join hint on the view applies to the table inside the view.
Access Path and Join Hints Inside Views
Access path and join hints can appear in a view definition.
- If the view is an inline view (that is, if it appears in the FROM clause of a SELECT statement), then all access path and join hints inside the view are preserved when the view is merged with the top-level query.
- For views that are non-inline views, access path and join hints in the view are preserved only if the referencing query references no other tables or views (that is, if the FROM clause of the SELECT statement contains only the view).
Parallel Execution Hints on Views
PARALLEL , NO_PARALLEL , PARALLEL_INDEX , and NO_PARALLEL_INDEX hints on views are applied recursively to all the tables in the referenced view. Parallel execution hints in a top-level query override such hints inside a referenced view.
Parallel Execution Hints Inside Views
PARALLEL , NO_PARALLEL , PARALLEL_INDEX , and NO_PARALLEL_INDEX hints inside views are preserved when the view is merged with the top-level query. Parallel execution hints on the view in a top-level query override such hints inside a referenced view.
16.3.3 Hints and Nonmergeable Views
With nonmergeable views, optimization approach and goal hints inside the view are ignored; the top-level query decides the optimization mode.
Because nonmergeable views are optimized separately from the top-level query, access path and join hints inside the view are preserved. For the same reason, access path hints on the view in the top-level query are ignored.
However, join hints on the view in the top-level query are preserved because, in this case, a nonmergeable view is similar to a table.
Заметки Дмитрия Пилюгина о Microsoft SQL Server

USE HINT и новые указания запросов в SQL Server 2016 SP1
Published on 01.02.2017 by Dmitry Pilugin in SQL Server (все заметки), оптимизатор
«Query Hints» в документации переводится как «указания запросов», кто-то называет их «подсказками», но чаще говорят просто «хинты». Я буду использовать в заметке именно последнее выражение, т.к. оно более распространено в повседневной жизни и сразу дает понять, о чем идет речь. Эта публикация — введение, она открывает цикл заметок по новым хинтам, которые появились в SQL Server 2016 SP1.
Существуют разные мнения по поводу использования хинтов в запросах от «никогда их не используйте» до «если что-то работает плохо, все решается хинтом».
Я придерживаюсь мнения, что хинт – это прежде всего инструмент, и, если его использовать к месту, то он может быть полезен, если же использовать его бездумно, то может навредить. В своей практике я прибегаю к хинтам при соблюдении двух условий. Первое – мне полностью понятна причина плохого плана, второе – других способов устранить эту причину нет.
Кроме того, важно помнить, что хинты, в плане ограничения свободы оптимизатора, бывают более жесткие и менее жесткие. По возможности, лучше использовать менее жесткие. Например, для ограничения типов соединений, лучше использовать хинт запроса, чем хинт в соединении, т.к. последний ограничивает еще и порядок соединений.
Хинтов запроса существует довольно много, но мы остановимся на тех, что появились в SQL Server 2016 SP1, и которые можно использовать при помощи ключевого слова USE HINT. Они могут быть получены при помощи нового представления sys.dm_exec_valid_use_hints. Ниже приведена таблица доступных хинтов с кратким описанием.
Hint Описание TF DISABLE_OPTIMIZED_NESTED_LOOP Отключает оптимизацию batch sort в соединении вложенными циклами 2340* FORCE_LEGACY_CARDINALITY_ESTIMATION Включает «старый» механизм оценки (версия 70, применялся до SQL Server 2014) 9481 ENABLE_QUERY_OPTIMIZER_HOTFIXES Включить исправления оптимизатора 4199 DISABLE_PARAMETER_SNIFFING Отключить прослушивание параметров 4136 ASSUME_MIN_SELECTIVITY_FOR_FILTER_ESTIMATES При оценке комплексных предикатов использовать предположение минимальной селективности 4137 ( <2014)
9471 (>=2014)ASSUME_JOIN_PREDICATE_DEPENDS_ON_FILTERS Включает зависимость селективности соединения от предикатов по таблицам 9476 ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS Включить автоматическое дополнение гистограммы статистики при оценке предиката по колонке, вне зависимости возрастания/убывания ее значений 4139 DISABLE_OPTIMIZER_ROWGOAL Отключить механизм учета целевого числа строк при построении плана запроса 4138 FORCE_DEFAULT_CARDINALITY_ESTIMATION Установить версию модели оценки, соответствующую уровню совместимости БД Чтобы применить хинт к запросу, необходимо в предложении OPTION указать ключевое слово USE HINT и в скобках перечислить один или несколько хинтов, например:
select name from sys.all_columns option( use hint( 'FORCE_LEGACY_CARDINALITY_ESTIMATION', 'ENABLE_QUERY_OPTIMIZER_HOTFIXES' ) );
Многое из того что позволяют делать хинты USE HINT было ранее доступно при помощи флагов трассировки, они перечислены в последнем столбце таблицы. Минус подходов с флагами это – слабая самодокументированность (нужно помнить, какой номер флага за что отвечает), и необходимость привилегий SA, и, хотя для последнего есть обходной путь, это не очень удобно.
Из краткого описания в документации может быть трудно понять, на что влияют эти хинты, поэтому, в дальнейших заметках, мы разберем что означает каждый из них и как он влияет на план запроса.
В следующей заметке, мы поговорим про хинт DISABLE_OPTIMIZED_NESTED_LOOP.