Почему SQL одерживает верх над NoSQL, и к чему это приведет в будущем

SQL пробуждается и наносит ответный удар силам тьмы — NoSQL
С самого начала компьютерной эры человечество собирает экспоненциально растущие объемы данных, и вместе с этим растут требования к системам хранения, обработки и анализа данных. Из-за этого в последнее десятилетие разработчики ПО отказались от SQL как от устаревшей технологии, которая не могла масштабироваться вместе с растущими объемами данных — и в результате появились базы данных NoSQL: MapReduce и Bigtable, Cassandra, MongoDB и другие.
Однако сейчас SQL возрождается. Все основные поставщики облачных услуг предлагают популярные управляемые сервисы реляционных баз данных: Amazon RDS, Google Cloud SQL, база данных Azure для PostgreSQL (запущена буквально в этом году) и другие. Если верить компании Amazon, ее совместимая с PostgreSQL и MySQL база данных Aurora стала «самым быстрорастущим сервисом в истории AWS». Не теряют популярности и SQL-интерфейсы поверх платформ Hadoop и Spark. А в прошлом месяце поддержку SQL запустила и Kafka. Авторы статьи скромно признаются, что и сами разрабатывают новую базу данных временных рядов, которая полностью поддерживает SQL.
В этой статье мы попробуем разобраться, почему маятник качнулся назад в сторону SQL и чего ждать специалистам по разработке и анализу баз данных.
Переведено в Alconost
Часть 1. Новая надежда
Чтобы понять, почему SQL возвращается, давайте вернемся в самое начало и разберемся, почему эта технология вообще появилась.
Как и все хорошие истории, наша начинается в 70-е
Эта реляционная база данных родилась в подразделении IBM Research в начале 70-х гг. В то время языки запросов основывались на сложной математической логике и не менее сложной нотации. Два свежеиспеченных кандидата наук, Дональд Чемберлин и Раймонд Бойс, впечатлились реляционной моделью данных, но при этом увидели, что используемый язык запросов будет препятствовать ее распространению. Они решили разработать новый язык запросов, который, по их словам, будет «более удобным для пользователей, не прошедших курс математики или компьютерного программирования».

Языки запросов до SQL (пп. А, Б) в сравнении с SQL (источник)
Просто представьте себе: еще не было ни Интернета, ни персональных компьютеров, «Cи» только-только вышел в свет, а два молодых специалиста в области вычислительных систем уже поняли, что «успех компьютерной отрасли в большей степени зависит от развития категории пользователей, а не категории обученных компьютерных специалистов». Им нужен был язык запросов, который читается так же легко, как английский, но при этом дает возможность администрировать базы данных и работать с ними.
В результате появился SQL, впервые представленный миру в 1974 году, и в следующие несколько десятилетий он станет очень популярным. Поскольку в отрасли ПО обосновались реляционные базы данных (например, System R, Ingres, DB2, Oracle, SQL Server, PostgreSQL, MySQL и многие другие), SQL широко распространился как язык взаимодействия с БД и стал общепринятым в экосистеме, которая становилась все более конкурентной.
(К сожалению, Раймонду Бойсу не удалось увидеть успех SQL: он умер от аневризмы мозга через месяц после одного из первых докладов по SQL — в возрасте всего 26 лет; у него остались жена и маленькая дочь.)
Некоторое время казалось, что SQL выполнил свою задачу и все идет хорошо… Но тут появился Интернет.
Часть 2. NoSQL наносит ответный удар
Разрабатывая SQL, Чемберлин и Бойс не знали, что в Калифорнии работают над другим перспективным проектом, который впоследствии широко распространится и станет угрожать существованию SQL. Этот проект — ARPANET, дата его рождения — 29 октября 1969 г.

Создатели сети ARPANET (не все), которая в итоге превратилась в современный Интернет (источник)
Некоторое время SQL вел спокойное существование — пока в 1989 году еще один инженер не изобрел Всемирную паутину.

Физик, изобретший Интернет (источник)
Веб и Интернет росли и распространялись, как сорняк, бесчисленными способами меняя привычный мир, но у специалистов по базам данных появилась вполне конкретная головная боль: новые источники, генерирующие данные в гораздо больших объемах и намного быстрее, чем раньше.
С ростом сети Интернет разработчики ПО обнаружили, что реляционные базы данных не могут справиться с такой нагрузкой. Произошло возмущение в Силе, как будто миллионы баз данных вскрикнули от ужаса и так же внезапно умолкли, перегруженные.
Затем два новых интернет-гиганта совершили прорыв — разработали собственные распределенные нереляционные системы, предназначенные для решения проблемы с возрастающими объемами данных: MapReduce (публикация 2004 г.) и Bigtable (публикация 2006 г.) от компании Google и Dynamo (публикация 2007 г.) от компании Amazon. Упав на благодатную почву, опубликованные статьи дали хороший урожай нереляционных баз данных: Hadoop (на основе статьи по MapReduce, 2006 г.), Cassandra (авторы вдохновлялись статьями по Bigtable и Dynamo, 2008 г.), MongoDB (2009 г.) и др. Новые системы были написаны преимущественно с чистого листа, поэтому они тоже не использовали SQL, что привело к росту «движения NoSQL».
Творение компаний Google и Amazon распространилось, похоже, гораздо шире, чем предполагали сами авторы. И понятно, почему так случилось: NoSQL-системы были в новинку; они обещали масштабирование и мощь; казалось, что это — быстрый путь к успешной разработке. И тут начали вылезать проблемы.
Разработчик, поддавшийся искушению NoSQL. Не делайте так.
Вскоре разработчики обнаружили, что отсутствие SQL на самом деле существенно ограничивает. У каждой базы данных NoSQL был собственный уникальный язык запросов, а это означало следующее: нужно было изучать больше языков (и обучать своих коллег); подключать эти базы данных к приложениям было сложнее, что заставляло писать тонны неустойчивого связующего кода; отсутствие сторонней экосистемы — а значит, компаниям приходилось разрабатывать собственные инструменты для визуализации и работы с БД.
Языки NoSQL только появились, поэтому их нельзя было назвать полными и завершенными: в реляционных БД, к примеру, многие годы работали над добавлением в SQL необходимых функций (JOIN, например). Такая незрелость означала бо́льшую сложность на уровне приложения. Отсутствие операторов JOIN также приводило к денормализации, итогом чего было «раздувание» данных и недостаток гибкости.
Некоторые базы данных из лагеря NoSQL добавили собственные SQL-подобные языки запросов — например, CQL в БД Cassandra. И часто становилось только хуже: использование интерфейса, который почти совпадает с чем-то более распространенным, по факту требовало больше умственных усилий, ведь в этом случае заранее неизвестно, какие из знакомых функций поддерживаются, а какие — нет.
SQL-подобные языки запросов — это как «Праздничный спецвыпуск» для «Звездных войн». Избегайте подражания. (И ни в коем случае не смотрите «Праздничный спецвыпуск».)
Кое-кто из специалистов уже на раннем этапе видел проблемы в NoSQL (например, ДеВитт и Стоунбрейкер — в 2008 г.). С течением времени к ним присоединялось все больше разработчиков ПО, которые прочувствовали эти проблемы на собственном горьком опыте.
Часть 3. Возвращение SQL
Соблазнившись поначалу «темной стороной», разработчики ПО вскоре узрели свет и понемногу начали возвращаться к SQL.
Сначала поверх платформ Hadoop и (чуть позже) Spark появились SQL-интерфейсы, благодаря чему в отрасли под «NoSQL» начали понимать «не только SQL» (хорошая попытка, ага).
Затем появились NewSQL — «новые SQL», масштабируемые базы данных с полной поддержкой SQL. Одной из первых масштабируемых БД с оперативной обработкой транзакций (OLTP) стала H-Store (публикация 2008 г.) Массачусетского технологического института и Брауновского университета. И снова не обошлось без разработок Google: своей первой статьей про Spanner (публикация 2012 г., среди авторов есть и создатели MapReduce) компания возглавила движение в сторону георепликационных БД с SQL-интерфейсом, и за ней последовали другие пионеры — например, CockroachDB (2014 г.).
В это же время начало возрождаться сообщество PostgreSQL: появились важные улучшения, например, тип данных JSON (2012 г.), а также винегрет из новых функций — в версии PostgreSQL 10: улучшенная встроенная поддержка секционирования и репликации, поддержка полнотекстового поиска для JSON и многое другое (вышла в октябре этого года). Другие разработчики, например, CitusDB (2016 г.) и авторы этих строк (TimescaleDB, выпущена в этом году) нашли новые способы масштабирования PostgreSQL для специализированных рабочих нагрузок.

Дорога, по который мы шли, разрабатывая TimescaleDB, очень похожа на путь отрасли в целом. В ранних внутренних версиях TimescaleDB имела собственный SQL-подобный язык запросов «ioQL» — да, темная сторона соблазнила и нас: казалось, что собственный язык запросов — это огромное преимущество. Поначалу это не казалось сложным, но вскоре мы поняли, что работы на самом деле предстоит намного больше, чем мы ожидали: например, нужно было определиться с синтаксисом, разработать «соединители», обучить этому языку пользователей и т. д. А еще обнаружилось, что мы — в собственноручно разработанном языке! — постоянно ищем правильный синтаксис для запросов, которые можем спокойно выразить через SQL.
Таким образом, однажды мы поняли, что разрабатывать собственный язык запросов — бессмысленно. Это привело нас к переходу на SQL и оказалось одним из лучших сделанных нами технологических решений: нам открылся совершенно новый мир. Сегодня нашей БД нет еще и 5 месяцев, а пользователи уже могут применять ее в работе и сразу «из коробки» иметь множество замечательных возможностей: инструменты визуализации (Tableau), соединители для популярных ORM, множество инструментов и вариантов резервного копирования, руководства и подсказки по синтаксису и т. д.
Не обязательно верить на слово нам — давайте посмотрим, что делает Google.

Более десятка лет компания Google находится, без сомнений, на переднем крае разработок в области разработки баз данных и соответствующей инфраструктуры. Поэтому следует уделять пристальное внимание тому, что они делают.
Взглянув на вторую крупную публикацию Google по БД Spanner, которая вышла совсем недавно (Spanner: Becoming a SQL System — «Spanner становится SQL-системой», май 2017 г.), вы обнаружите, что она подтверждает выводы, к которым мы пришли самостоятельно.
К примеру, инженеры Google начал надстраивать свою систему над Bigtable, но обнаружили, что отсутствие SQL создает сложности:
«Эти системы давали некоторое преимущество как базы данных, однако им не хватало многих традиционных функций БД, на которые часто полагаются разработчики приложений. Ключевой пример — отсутствие продуманного языка запросов, из-за чего разработчикам приложений для обработки и агрегирования данных приходилось писать сложный код. В итоге мы решили превратить Spanner в полнофункциональную SQL-систему, в которой выполнение запросов тесно связано с другими архитектурными особенностями БД (например, строгая согласованность и глобальная репликация)».
Далее в статье они подробнее обосновывают переход от NoSQL к SQL:
«У исходного API-интерфейса базы данных Spanner были методы NoSQL для точечного поиска и поиска по диапазонам отдельных и перемежающихся (англ. «interleaved») таблиц. Методы NoSQL упрощали запуск системы и по-прежнему удобны в простых задачах поиска, однако у SQL есть значительные преимущества при записи более сложных шаблонов доступа к данным и вычислениях на данных».
В статье также рассказывается, что переход на SQL не остановился на проекте Spanner, а по сути распространился на остальные технологии компании, где сегодня общий диалект SQL используется в нескольких системах:
«SQL-ядро БД Spanner использует «стандартный SQL» совместно с несколькими другими системами Google, в число которых входят и внутренние (среди них — F1 и Dremel), и внешние системы (например, BigQuery)…
Для пользователей внутри компании такой подход снижает барьер при работе с несколькими системами. Разработчик или специалист по анализу данных, который пишет SQL-запросы в Spanner, может использовать свои навыки в системе Dremel, не беспокоясь о тонкостях синтаксиса, обработке NULL и т. д.».
Успех такого подхода говорит сам за себя. Сегодня Spanner является платформой для основных систем Google, в числе которых AdWords и Google Play, и при этом «потенциальные клиенты облачных платформ в подавляющем большинстве заинтересованы в использовании SQL».
Весьма примечательно, что компания Google, которая помогла родиться движению NoSQL, сегодня возвращается в лоно SQL. (Поэтому кое-кто задался вопросом: «Разработчики Google сбили отрасль «больших данных» с истинного пути на 10 лет?»)
Будущее отрасли обработки данных: SQL как узкое место
В компьютерных сетях существует такое понятие, как «узкое место».
Эта идея возникла для решения главной задачи, которую можно сформулировать следующим образом. Возьмем какое-либо сетевое устройство и представим себе своеобразный «пирог» из слоев оборудования снизу и слоев программного обеспечения сверху. Сетевые устройства могут быть самыми разными; так же бывает и множество различных приложений и ПО. Задача состоит в том, чтобы ПО имело возможность подключаться к сети, какое бы оборудование не использовалось; а сетевое оборудование должно знать, как обрабатывать запросы сети, независимо от ПО.
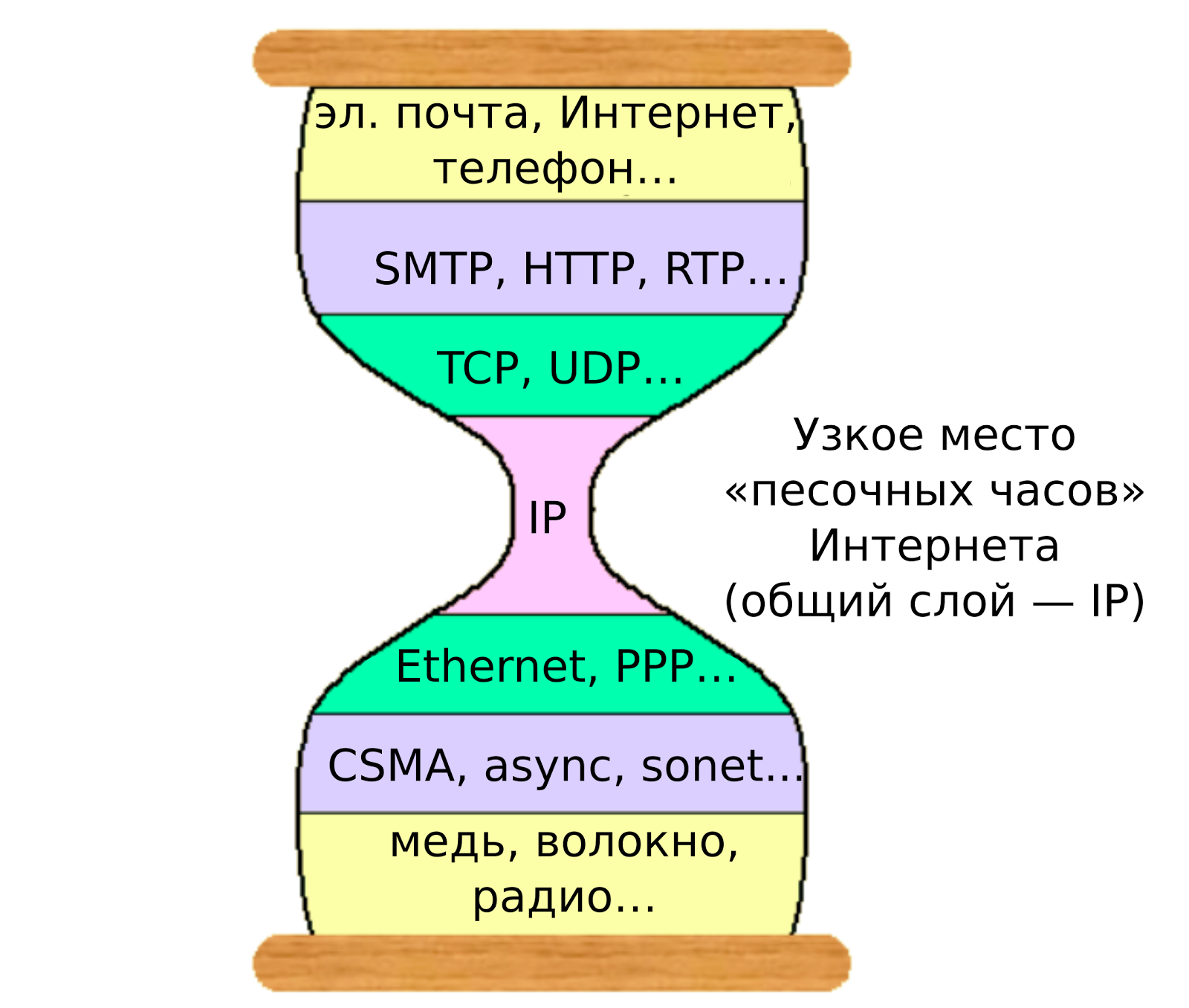
«Узкое место» сетевых технологий (источник)
В сетях узкое место — протокол IP: он выступает в качестве общего интерфейса между сетевыми протоколами низкого уровня, предназначенными для локальной сети, и прикладными и транспортными протоколами высокого уровня. (Вот одно неплохое разъяснение.) И, если упрощать, этот интерфейс стал общепринятым для компьютерных систем: он позволяет объединять сети и обмениваться данными между устройствами. И эта «сеть сетей» превратилась в многогранный, полный различной информации Интернет, каким мы его знаем сегодня.
Авторы этой статьи полагают, что SQL стал узким местом в анализе данных.
Мы живем в эпоху, когда данные становятся «самым ценным ресурсом в мире» (The Economist, май 2017 г.). В результате мы имели удовольствие наблюдать «кембрийский взрыв» специализированных БД (OLAP, базы данных временных рядов, БД для документов, графов и т. д.), инструментов обработки данных (Hadoop, Spark, Flink), шин передачи данных (Kafka, RabbitMQ) и т. д. Появилось и большое число приложений, которые работают на такой инфраструктуре данных, будь то сторонние инструменты визуализации (Tableau, Grafana, PowerBI, Superset), веб-фреймворки (Rails, Django) или специально разработанные приложения, использующие БД.
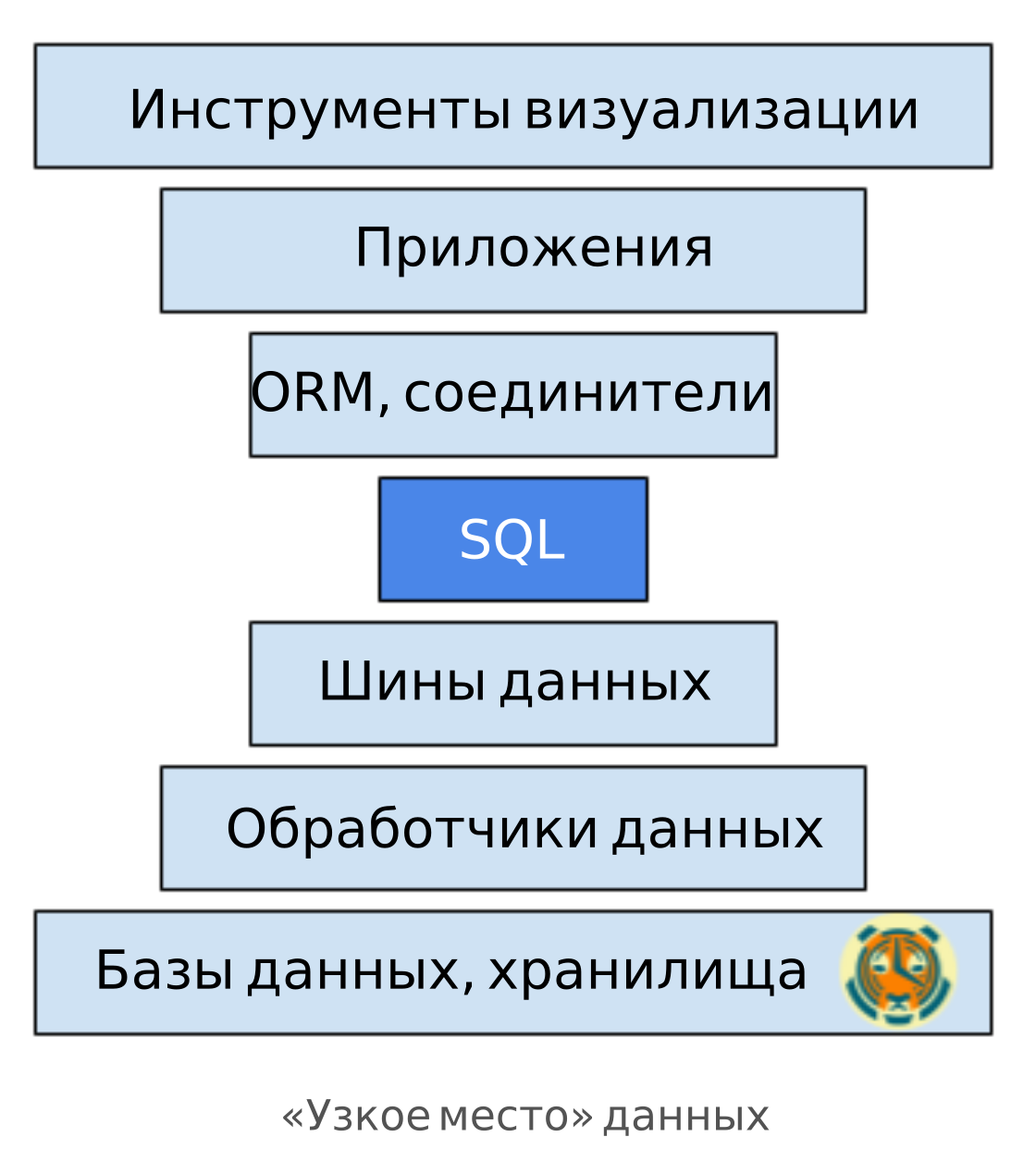
Как и в случае компьютерных сетей, у нас есть сложный «пирог» с инфраструктурой в самом низу и приложениями вверху. Как правило, чтобы этот пирог работал, нам приходится писать много связующего кода. Но такой код ненадежен: его нужно старательно поддерживать.
Необходим общий интерфейс, который позволит частям этого пирога друг с другом взаимодействовать. Лучше всего — что-то, что уже является стандартом в отрасли. Что-то, что позволит менять местами различные слои с минимальными усилиями.
И здесь как раз самое место для SQL: как и IP, SQL — это общий интерфейс.
Но SQL все же универсальнее протокола IP: данные приходится анализировать и людям, а запросы на языке SQL, как и было задумано, могут быть прочитаны человеком.
Безупречен ли SQL? Нет. Но именно этот язык знаком большинству специалистов по базам данных. Конечно, где-то уже ведутся работы над интерфейсом, в большей степени ориентированным на естественный язык, но к чему будут подключаться такие системы? К SQL.
Таким образом, на самой вершине пирога есть еще один слой, и этот слой — мы.
SQL возвращается
SQL возвращается — и главная причина этого не в том, что писать связующий код для подключения NoSQL-инструментов надоедает. И не в том, что обучать специалистов множеству новых языков — это сложно. И не в том, что стандарты должны быть продуманными.
Главная причина в том, что наш мир полон данных: они окружают нас, связывают нас. Когда-то мы для их обработки полагались на собственные органы чувств и нервную систему. Теперь же и наши аппаратные системы и ПО становятся достаточно умными, чтобы помогать нам. Мы хотим лучше понимать окружающий мир, и для этого собираем все больше и больше данных — поэтому сложность систем хранения, обработки, анализа и визуализации этих данных будет только расти.
Мастер обработки данных Йода
У нас есть выбор: жить в мире хрупких систем и миллионов интерфейсов — или вернуться к SQL и восстановить нарушенное равновесие Силы.
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 68 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
Рейтинг востребованности языков программирования

Java — самый популярный язык программирования. Об этом говорится в совместном исследовании «Нетологии» и международного коммуникационного агентства Zecomms Agency, которое было опубликовано в июле 2023 года.
Согласно данным экспертов, весной 2023-го более четверти — 26% — всех открытых вакансий в сфере ИТ приходилось на специалистов, владеющих Java. На втором месте оказался язык запросов к базам данных SQL: 24% от общего числа объявлений, причём бoльшая часть из них — в Европе, Азии и на Ближнем Востоке.

Замыкает тройку Python: его доля составила 23% всех предложений на рынке. Особенно востребован этот язык в Азии и на Ближнем Востоке, поскольку упоминался в большинстве открытых вакансий в регионе.
JavaScript занял четвёртую строчку: знание этого языка требовали в 22% объявлений. Язык описания внешнего вида документа CSS и фреймворк React получили равные доли от общего числа вакансий — по 13%.
Следом идёт объектно-ориентированный язык программирования C#: 12% всех предложений. Ещё по 11% пришлось на вакансии для специалистов со знанием языка для структурирования и представления содержимого HTML5, а также фреймворков .NET и Angular.
Исследование проводилось на базе данных сервиса Indeed. Для анализа были взяты 817 259 вакансий в сфере ИТ, актуальных в период с марта по май 2023 года в Европе, США, Латинской Америке, Азии и на Ближнем Востоке.
Сервис DevJobsScanner также определил самых востребованных языков программирования, проанализировав более 12 млн вакансий разработчиков. К началу 2023 года список составленный DevJobsScanner рейтинг выглядит следующим образом: JavaScript/TypeScript (31% вакансий), Python (20%), Java (15,2%). В топ-10 вошли такие языки программирования, как C#, PHP, C/C++, Ruby, Go, SQL, Scala.
Python и Java стали самыми популярными языками программирования в России
25 мая 2023 года учебный центр IBS опубликовал результаты исследования, посвященного самым популярным языкам программирования в России. Рейтинг оказался следующим:
- Python (30%);
- Java (27%);
- Java Script (21%);
- Golang (7%);
- Kotlin (6%).

Самыми популярными языками программирования в России стали Python и Java
В рамках исследования были опрошены ИТ-специалисты. Они также назвали главные профессиональные навыки для программистов: глубокое знание профильного языка программирования, а также знания SQL-, DevOps-инструментов (Docker, Kubernetes и др.), инструментов автоматизации и управления тестированием (Selenium, Pytest, Test IT и др.).
Бизнес-аналитики отмечают среди ключевых профессиональных навыков понимание основных методов интеграции систем и сервисов, а также знание нотаций и других инструментов для описания бизнес-процессов и сервисов, наиболее актуальные из которых BPMN и UML. Многие аналитики указали, что особенно активно используют платформу Camunda. Системные аналитики считают самым важным навык проектирования интеграционных взаимодействий, а самыми востребованными стандартами и технологиями — REST API, SOAP, gRPC, MQ и WSDL.
Также специалисты учебного центра IBS выяснили, какие навыки ИТ-специалисты считают самыми полезными и важными в своей работе. Первое место занял тайм-менеджмент, его выбрали 32% опрошенных. На втором месте — умение правильно расставлять приоритеты (31%), тройку замыкает способность четко и понятно формулировать свои мысли (27%). Кроме того, важными являются умение работать в команде (24%) и выстраивание коммуникации как внутри команды, так и с внешними партнерами (21%).
2022
Назван топ-5 самых популярных языков программирования
10 ноября 2022 года веб-сервис для хостинга IT-проектов и их совместной разработки GitHub опубликовал отчёт Octoverse, в котором в числе прочего приводится рейтинг самых востребованных в 2022 году языков программирования.
Аудитория GitHub достигла 94 млн разработчиков, увеличившись на 27 % по сравнению с 2021 годом: платформа привлекла приблизительно 20,5 млн участников в течение 12 месяцев. Говорится, что 90 % компаний сейчас используют открытый исходный код, а 90 % компаний из списка Fortune 100 представлены на GitHub. В течение 2022 года пользователи разместили на платформе 85,7 млн новых репозиториев — на 20 % больше по сравнению с 2021 годом.

Назван топ-5 самых популярных языков программирования
Самым популярным языком программирования на GitHub является JavaScript. Далее идут Python, Java, Typescript и C#. На шестой позиции располагается C++, сместивший на седьмую строку язык PHP. Кроме того, в первую десятку входят Shell, C и Ruby. Наиболее высокие темпы роста продемонстрировал Hashicorp Configuration Language (HCL) — плюс 56 % по сравнению с 2021 годом. На 50,5 % поднялась популярность Rust, на 37,8 % — TypeScript. В Тор-10 самых быстрорастущих языков также вошли Lua, Go, Shell, Makefile, C, Kotlin и Python. В целом, разработчики GitHub применяют без малого 500 самых разных языков программирования.
Количество пользователей GitHub растёт практически во всех регионах, за исключением Антарктиды и острова Норфолка. Наиболее активно аудитория платформы расширяется в США, Индии, Китае и Бразилии. Примерно 7,3 % от общего количества новых разработчиков подключились в 2022 году с территории России. За 12 месяцев суммарное количество изменений в проектах, представленных на платформе, превысило 3,5 млрд. Число защищённых проектов выросло с 13 млн в 2021 году до 18 млн в 2022 году. [2]
Названы 3 самых популярных языка программирования в России
В конце августа 2022 года в «Сколково» назвали самые популярные языки программирования в России. Данные получены по результатам опроса 1566 разработчиков, проведенного аналитиками платформы All Cups от VK, Фондом «Сколково» и IT_One в рамках чемпионата IT_One Cup. Java.
Среди востребованных языков программирования опрошенные респонденты также выделили PHP (12%), JavaScript (9%) и C (5%). Более трети опрошенных (39%) считают, что Java всегда будет востребован. Каждый четвертый разработчик отмечает, что этот язык программирования развивается активнее остальных.

Названы 3 самых популярных языка программирования
Более половины участников исследования (54%) считают, что заработок ИТ-специалиста зависит от количества и состава изученных языков программирования. Каждый третий респондент (36%) отмечает, что определяющими факторами в финансовом состоянии разработчика являются уровень знаний и уникальность работника. А каждый второй респондент отметил, что Java-специалисты получают в среднем от 100 до 300 тысяч рублей в месяц.
Вопреки мнению, что Python является популярным мостиком в IT-отрасль, респонденты отметили, что начинали программировать с языка Java (37%). Лишь 25% специалистов ответили, что первым изучали Python. По данным опроса, ИТ-специалисты рекомендуют погружаться в процесс разработки с Java (42%). Каждый пятый считает C++ хорошим стартом, а 18% респондентов советуют PHP. При этом 35% респондентов считают Java-разработчиков универсальными специалистами, которые могут выполнять разноплановые задачи.
В мировом рейтинге самых популярных языков программирования Tiobe ситуация следующая: в августе 2022 года первое место было у Python, второе у С, третье у Java, тогда как С++ и C# занимали четвертую и пятую строчки соответственно. [3]
2021: Рейтинг самых востребованных языков программирования
В конце декабря 2021 года появился анализ, который подготовила компания Emsi Burning Glass о том, какие технические навыки преобладали в 2021 году, с точки зрения работодателей. Исследование показало наиболее востребованные на рынке языки программирования.
Emsi Burning Glass, которая собирает и анализирует миллионы объявлений о вакансиях со всего США и некоторых других стран. Основываясь на этих данных, специалисты компании выделили основные технические навыки, которые требовались работодателям в 2021 году для найма ИТ-специалистов.
Доминирование SQL над сверхпопулярными и широко используемыми языками, такими как Python, Java и JavaScript, может показаться неожиданным. Но есть простая причина, по которой так много компаний требуют от ИТ-специалистов знания SQL, ведь данный язык программирования для управления реляционными базами данных и запросов к ним, что делает его основой важных операций с данными во многих организациях, как крупных, так и средних.

Определены самые востребованные языки программирования: JavaScript, Python, Java и др.
Постоянная популярность JavaScript в веб-приложениях и бэкенд-приложениях поддержала его позицию самого популярного языка программирования в 2021 годe. Хотя это и не является неожиданностью, JavaScript уже несколько лет является самым используемым языком в мире. Это столько же, сколько вся пользовательская база Swift или объединенные сообщества Rust и Ruby. Данные по JavaScript также включают производные языки TypeScript и CoffeeScript. Медианная зарплата от $100 тыс. для программистов более высокого уровня от $150 тыс.
Python, возможно, и не занимает близкого второго места, но его популярность впечатляет ведь по данным, на декабрь 2021 года данный язык используют около 11,3 млн программистов, в основном в области науки о данных, машинного обучения и IoT-приложений. Python приобрел огромную популярность, обогнав Java. Язык по-прежнему используется в мобильных и настольных приложениях. Медианная зарплата от $130 тыс. для ИТ-специалистов более высокого уровня от $175 тыс.
Согласно данным Emsi Burning Glass, медианная компенсация за работу, связанную с SQL, составляет $92 тыс., а при правильном сочетании навыков и опыта заработная плата возрастает до $122 тыс. и выше. Около 89% вакансий, требующих навыков работы с SQL, также предполагают наличие степени бакалавра, так что для начала карьеры в сфере, ИТ-специалистам не потребуется никакой степени.
Медианная зарплата менеджера проектов составляет $80 тыс., заработная плата растет с ростом навыков и опыта в том числе. Если вам интересна карьера менеджера проектов, начните с освоения таких методов управления проектами, как Agile, Scrum, Kanban и Waterfall. Управление проектами также требует солидного сочетания технических и мягких навыков. Соискателям нужно не только принимать сложные решения о технологиях, но и управлять заинтересованными сторонами во всей компании, включая высшее руководство.
Рейтинг языков программирования:
2020
Рейтинг самых высокооплачиваемых языков программирования
В августе 2021 года появились результаты опроса Stack Overflow среди более 83 тыс. разработчиков из разных стран мира, по итогам которого был составлен рейтинг наиболее высокооплачиваемых языков программирования.
Опрос, в котором наиболее активно принимали участие программисты из США, Индии, Германии, Великобритании, Канады, показал, что наибольшую медианную зарплату получают разработчики, которые владеют языком Clojure, — $95 тыс. в год. Это в 1,5 раза больше медианы таких языков программирования, как Python ($59 тыс.) и JavaScript ($54 тыс.), которые пользуются популярностью среди работодателей и разработчиков. На втором месте — F# ($81,077), на третьем — Elixir ($80,077). На четвертой позиции рейтинга Erlang ($80 тыс.), на пятом Ruby — ($80 тыс.). В ТОП-10 вошли также: Scala ($77,832), Rust ($77,530), Go ($75,669), LISP ($75,669).

Рейтинг наиболее высокооплачиваемых языков программирования
Почти 60% респондентов учились программировать на онлайн-ресурсах, в том числе на онлайн-курсах, форумах и других современных решениях для получения знаний. Респонденты старшего возраста учились программированию в школах (53%), университетах, и с помощью книг (40%). 45% респондентов используют для работы операционную систему Windows, 25,32% предпочитают Linux, а 25,19% выбирают MacOS. 53% опрошенных написали свою первую строку кода в возрасте 11-17 лет, 24% в возрасте 18-24 лет, 14% — в возрасте 5-10 лет, 5% — в возрасте 25-34 лет.

Рейтинг разработчиков по специализации
Почти половина опрошенных являются фулстек-разработчиками, 43,73% — бэкенд-разработчиками и 27,45% фронтенд-разработчиками.
Согласно результатам опроса Stack Overflow, среди наиболее популярных баз данных у ИТ-специалистов: MySQL, PostgreSQL, SQLite, MongoDB, Microsoft SQL Server (в порядке убывания). Среди наиболее популярных облачных систем: AWS, Google Cloud Platform, Microsoft Azure, Heroku, DigitalOcean. [5]
GitHub назвал самые популярные языки программирования
В начале декабря 2020 года сервис совместной разработки ИТ-проектов GitHub опубликовал рейтинг самых популярных языков программирования, с которыми работают пользователи платформы. Развиваемый Microsoft проект TypeScript стремительно набирает популярность.
Первое место сохранил JavaScript. Следом расположился Python, третье место занимает Java. На четвертое место поднялся TypeScript. Пятое пятую строчку занял С#. Далее идут PHP, C++, C, Shell и Ruby. Состав первой десятки с 2017 года сохраняется без изменений, но PHP и Ruby, находившиеся на вершине списка пять лет назад, продолжают терять популярность.

Рейтинг самых популярных языков программирования
Как отмечает издание ZDNet, до 2016 году TypeScript не входят в десятку самых востребованных языков программирования на GitHub, но в 2018-м он поднялся на седьмую позицию, а в 2020-м взобрался на три строчки вверх, опередив C#, PHP и C ++.
Один из создателей TypeScript Андерс Хейлсберг, технический сотрудник Microsoft и «отец C#», в разговоре с ZDNet признался, что ему пришлось продать идею языка с открытым исходным кодом руководителям Microsoft в 2010 году, когда компания, будучи под руководством Стива Баллмера, весьма негативно была настроена в отношении сообщества Open Source.
Соучредитель аналитической фирмы RedMonk Джеймс Говернор считает, что популярность TypeScript в последние годы растет потому, что этот язык программирования удовлетворяет потребности разработчиков JavaScript в «безопасности типов». Рост популярности на GitHub указывает на то, что TypeScript останется надолго, уверен эксперт.
В публикации ZDNet сказано, что TypeScript стал популярен среди веб-разработчиков, обладающих обширной кодовой базой JavaScript. Среди них – Slack, Airbnb и Bloomberg. Microsoft также написала на TypeScript свой популярный кроссплатформенный редактор кода с открытым исходным кодом Visual Studio Code. [6]
2019
За знания каких инструментов программистам платят больше всего. 7 технологий
Портал Stack Overflow, который называет себя крупнейшим и пользующимся наибольшим доверием сообществом для разработчиков (каждый месяц сайт посещают более 50 млн уникальных пользователей), провел исследование, чтобы выяснить, за знания каких инструментов программистам платят больше всего. В конце декабря 2019 года был проведён опрос, по результатам которого названы семь главных технологий, который увеличивают зарплаты ИТ-специалистов.

Популярный сайт для программистов Stack Overflow опросил пользователей об их заработке, образовании, рабочем опыте и инструментах, которые они используют
Elasticsearch (бонус к зарплате — $2-3 тыс.)
Elasticsearch — это поисковая и аналитическая система для работы с большими данными (Big Data). Это проект с открытым исходным кодом, поэтому можно бесплатно использовать, загружать или изменять. Поддержкой этого проекта и развитием коммерческих возможностей для него занимается компания Elastic.
React (бонус к зарплате — $2-3 тыс.)
React — это библиотека JavaScript, используемая для разработки веб- и мобильных приложений. Технология применяется при создании дизайна веб-сайтов и приложений, а также для взаимодействия пользователей с ними. React также является проектом Open Source. Он был запущен в Facebook, где использовался для популярных функций, таких как кнопка «Нравится» и управление рекламой. К концу декабря 2019 года сообщество сторонников React достигло огромных объёмов. Технологией нашла применение в сервисах Twitter, Pinterest, Asana, Uber и Airbnb.
Apache Spark (бонус к зарплате — $1-5 тыс.)
Apache Spark — это открытый проект, предназначенный для обработки и анализа больших объёмов сложных данных. Разработчики используют этот инструмент, потому что он быстрый, может быть запущен где угодно и работает с популярными языками программирования, такими как Python и Java, отмечает издание Business Insider.
В 2019 году компании как никогда активно переходят на использование облачной инфраструктуры Amazon Web Services, Microsoft Azure или Google Cloud. В результате, знание того, как перемещать и запускать приложения в облаке, является востребованным. Эти навыки работы с облаком также часто полезны в DevOps — области для объединения разработки программного обеспечения и операций, чтобы помочь оптимизировать процесс производства.

Stack Overflow назвал 7 навыков, за которые работодатели готовы платить больше всего.
Go (бонус к зарплате — $4-6 тыс.) Go — это язык программирования с открытым исходным кодом, который появился в Google и был специально оптимизирован для написания крупномасштабного программного обеспечения. Go похож на язык C, который часто используется для создания операционных систем. Судя по данным портала GitHub, Go входит в число самых быстрорастущих языков программирования с точки зрения использования.
Redis (бонус к зарплате — $5-6 тыс.)
Redis — популярная база данных с открытым исходным кодом. По результатам опроса Stack Overflow Redis, она оказалась самой любимой разработчиками базой данных.
«Redis — это инструмент, который просто работает, — говорит Джулия Силдж. — Люди, которые занимаются такой работой, являются опытными разработчиками, идущими по особому пути».
Scala (бонус к зарплате — $7-10 тыс.)
Scala — язык программирования, используемый в приложениях для работы с большими данными. Scala пользуются инженеры по работе с данными, которые пользуются на рынке труда большим спросом. [7]
10 лучших языков программирования для машинного обучения — GitHub
В январе 2019 года сервис для хостинга ИТ-проектов и их совместного развития GitHub опубликовал рейтинг самых популярных языков программирования, используемых для машинного обучения (МО). Список составлен на основе количества репозиториев, авторы которых указывают, что в их приложениях используются МО-алгоритмы.

Для разработки программ, основанных на алгоритмах машинного обучения, чаще всего применяются Python и C++
Самым популярным языком программирования среди разработчиков МО-программ в GitHub назвали Python во многом за набор предварительно настроенных инструментов для внедрения МО-моделей и алгоритмов. Благодаря этому программисты могут задействовать Python для реализации машинного обучения без глубоких познаний в нем и создания, например, чат-ботов с нуля.
Это стало возможным после появления отлично документированной библиотеки Scikit-Learn, в которой предусмотрено большое количество алгоритмов машинного обучения. Также отмечается присутствие библиотеки ChatterBot, предназначенной для обработки речи и обучения на наборах данных в формате диалогов.
C++ занял второе место среди языков программирования, применяемых пользователями GitHub для машинного обучения. Высокая позиция обусловлена созданием МО-библиотеки Google Google TensorFlow, в которой акцент сделан на нейросетях. Хотя основная часть разработчиков и исследователей, которые используют TensorFlow, работают в Python, иногда бывает необходимо отказаться от этой схемы. Например, когда необходимо использовать обученную модель в мобильном приложении или роботе.
Кроме того, популярность C++ на GitHub обусловлена развитием распределенной высокопроизводительной платформы для градиентного бустинга Microsoft LightGBM (повышает скорость и эффективность обучения МО-модели) и библиотеки Turi Create (упрощает разработку пользовательских моделей машинного обучения для начинающих разработчиков).
Тройку лидеров в рейтинге GitHub замкнул JavaScript. У него есть WYSIWYG-редактор, который позволяет создавать модели машинного обучения путем простого перетаскивания объектов. Кроме того, на пользу JavaScript в рейтинге сыграл проект ml5.js, призванный сделать машинное обучение пригодным для использования художниками и студентами нетехнических специальностей, предлагая доступ к алгоритмам и моделям машинного обучения в браузере.
На Java создан такой популярный проект, как Smile (Statistical Machine Intelligence and Learning Engine). Это быстрая комплексная система, предназначенная для реализации машинного обучения, НЛП, линейной алгебры, графа, интерполяции и визуализации в Java и Scala.
Еще одним популярным репозиторием на GitHub, в котором код написан на Java, является H20. Эта библиотека машинного обучения предназначена как для локальных вычислений, так и с использованием кластеров, создаваемых непосредственно средствами H2O или же работая на кластере Spark и Hadoop.

Обладая доступом к библиотекам, не так уж сложно разрабатывать основанные на ML программы на любом языке программирования
Одним из самых популярных МО-проектов, написанных на C#, на GitHub является ML Agents. Этот открытый плагин для игрового движка Unity, который позволяет играм и моделированным пространствам выступать в качестве сред для обучения интеллектуальных агентов.
Здесь наиболее популярными проектами являются MachineLearning.jl, MLKernels.jl и LightML.jl.
У этого языка программирования стоит отметить скрипты Dl-machine, предназначенные для настройки графического процессора для вычислений с использованием CUDA с библиотеками для глубокого обучения.
Язык программирования R популярен в МО-проектах благодаря большому сообществу и библиотек для анализа данных.
9. TypeScript
TypeScript — это надмножество JavaScript, то есть, любой код на JS является правильным с точки зрения TypeScript. Однако TypeScript обладает некоторыми дополнительными возможностями, которые не входят в JavaScript
В GitHub есть несколько репозиториев, способствующих популяризации Scala. Среди них — Microsoft Machine Learning for Apache Spark. [8]
2018: Самые популярные языки программирования — Tiobe
В декабре 2018 года портал Tiobe опубликовал регулярный рейтинг языков программирования, основанный на подсчете результатов поисковых запросов, содержащих название языка.
Обозреватели ZDNet обращают внимание на пятое место языка Visual Basic .Net, который Microsoft выпустила в 2001 году. Его рейтинг оказался самым большим за время ведения подсчетов Tiobe — 7,127%. В конце 2017 года Visual Basic .Net находился на седьмой строчке списка с результатом в 2,467%.
ZDNet пишет, что Visual Basic .Net продолжает возрождаться, несмотря на то, что в 2017 году Microsoft объявила о прекращении совместного развития Visual Basic и C#, чтобы сосредоточиться на «ключевых сценариях и доменах», в которых Visual Basic .Net наиболее популярен. В результате компания бросила больше ресурсов за пределы C#.
Аналитики Tiobe назвали пятое место Visual Basic .Net в рейтинге «очень удивительным». Этот проект уступает лишь C++, Python, C и Java. Список наиболее востребованных языков программирования к декабрю 2018 года представлен ниже.

Рейтинг популярности языков программирование, данные Tiobe
По мнению экспертов, Visual Basic .Net «рано или поздно зачахнет», однако к концу 2018 года он остается популярным для создания специализированных офисных приложений для малого и среднего бизнеса. Этот язык все еще широко используется разработчиками во многому потому, что его легко освоить.
По данным Microsoft, у Visual Basic .Net насчитывается «сотни тысяч» сторонников против «миллионов» у C#. Компания стремится к лидерству C# в области создания технологий для облачных, мобильных и передовых вычислений, а в Visual Basic .Net видит акцент на разработку для Windows-компьютеров.
�Новая стратегия Microsoft вызвала тревогу у работающих с Visual Basic .Net программистов, которые опасались, что компания может свернуть этот язык. Также разработчики были разочарованы тем, что Microsoft предложила поддержку Xamarin в C#, но не сделала это в отношении Visual Basic .Net. [9]
2014: Рейтинг ITmozg.ru
Портал по поиску работы в сфере высоких технологий и телекоммуникаций ITmozg.ru составил в 2014 году рейтинг востребованности языков программирования, а также сравнил его с данными мирового рейтинга, который ежемесячно публикуется компанией TIOBE software [10] .
Для составления рейтинга специалисты ITmozg.ru проанализировали более 30 тыс. вакансий в IT-сфере.
Рейтинг языков по версии ITmozg.ru возглавил PHP, который с большим отрывом опередил C и C++, находящиеся на 1 и 4 месте мирового рейтинга соответственно. Вакансии, в которых упоминается PHP, составляют почти 22% от общего числа вакансий разработчиков, опубликованных за рассматриваемый период. В зарубежном рейтинге PHP занял лишь 6 место.
Рейтинг востребованности языков программирования по состоянию на конец 2013 года

Среди других отличий, которые можно отметить – более высокий спрос на Delphi, Visual Basic и .NET и, наоборот, более низкую востребованность Objective-C, т.е. разработку под устройства компании Apple.
Любопытно, что если включить в рассмотрение такой специализированный язык, как встроенный язык программирования 1С, то именно он станет абсолютным и доминирующим победителем рейтинга более чем с 37%-ми от общего числа вакансий. Работа с именно этим предварительно компилируемым языком высокого уровня, позволяющим вносить изменения в программные решения на базе 1С и конфигурировать их под потребности конкретных предприятий, пользуется сейчас в России гораздо большим спросом, чем другие виды разработки.
Рейтинг языков программирования (с учетом 1C)
.jpg)
Смотрите также
- Средства разработки приложений — каталог продуктов и проектов
- Программист
- Agile software development
- День программиста
- Кладбища программистов. Почему не все ИТ-шники хотят работать в корпорациях
- Разработчики сайтов (контакты программистов)
- Рейтинг программистов HackerRank
- Себестоимость часа работы программиста
- ↑Самый популярный язык программирования в 2023 году
- ↑Programming languages: C++ overtakes PHP, but JavaScript, Python and Java still rule
- ↑Российские разработчики назвали самый востребованный язык программирования
- ↑SQL, Project Management Topped Most-Demanded Tech Skills in 2021
- ↑Developer Survey 2021
- ↑Programming languages: Microsoft TypeScript leaps ahead of C#, PHP and C++ on GitHub
- ↑These 7 programming skills can increase your salary by thousands, according to the megapopular developer hub Stack Overflow
- ↑GitHub: The top 10 programming languages for machine learning
- ↑Microsoft’s Visual Basic .Net dead? No, it’s fifth most popular programming language
- ↑ Рейтинг TIOBE software – рейтинг, оценивающий популярность языков программирования, на основе подсчета результатов поисковых запросов, содержащих название языка (запрос вида +» programming»). Для формирования индекса используется поиск в нескольких наиболее посещаемых (по данным Alexa) порталах: Google, Blogger, Wikipedia, YouTube, Baidu, Altaba (ранее Yahoo), Bing, Amazon. Проект подразумевает, что может существовать корреляция между количеством найденных страниц и количеством инженеров, курсов и вакансий.
SQL: история, стандарты и перспективы языка

Сегодня SQL является стандартным языком управления базами данных. Что это означает? Как SQL стал стандартом? Какую роль играет официальный стандарт SQL? Насколько он поддерживается и почему, несмотря на стандарт, имеются диалекты SQL? Насколько сильно SQL влияет на различные сегменты компьютерного рынка? Чтобы ответить на эти вопросы, в настоящей статье прослеживается история развития SQL и рассказывается о его нынешней роли на рынке компьютерных технологий.
SQL и эволюция управления базами данных
Одной из основных задач вычислительной системы является хранение и обработка данных. В конце 1960-х-начале 70-х годов стали появляться специализированные компьютерные программы для решения этой задачи, известные под названием системы управления базами данных (СУБД). СУБД помогала пользователям компьютеров организовывать и структурировать данные и позволяла вычислительной системе играть более активную роль в обработке данных. Хотя изначально СУБД использовались на больших ЭВМ (мэйнфреймах), их популярность быстро распространилась на мини-компьютеры, а затем и на рабочие станции, персональные компьютеры и специализированные серверы.
Системы управления базами данных играли ключевую роль в стремительном развитии компьютерных сетей и Интернета. Ранние СУБД работали в крупных монолитных вычислительных комплексах, где данные, программное обеспечение СУБД и прикладные программы, осуществлявшие доступ к базе данных, работали в единой системе. В 1980-x-l 990-х годах получила распространение архитектура «клиент/сервер», в которой пользователь персонального компьютера или прикладная программа посредством локальной сети выполняли обращение к базе данных, расположенной в другой системе. В конце 90-х годов растущая популярность Интернета и Веб оказала влияние на архитектуру управления данными. Сегодня пользователю зачастую достаточно иметь лишь веб-браузер, чтобы получить доступ к базам данных, расположенным не только в его организации, но и в любой точке земного шара. Такие интернет-архитектуры обычно включают три и более компьютерных систем: одна, где работает веб-браузер, обеспечивает взаимодействие с пользователем и подключена через Интернет ко второй — серверу приложений,— где работает прикладное программное обеспечение, а та, в свою очередь, подключена к третьей системе, где работает СУБД.
Сегодня рынок СУБД — это очень большой бизнес. Независимые компании по производству программного обеспечения и крупные поставщики продают программы для управления базами данных па миллиарды долларов ежегодно. Практически все компьютерные приложения уровня предприятия, поддерживающие деятельность крупных компаний и иных организаций, используют базы данных. Эти приложения включают некоторые быстрорастущие категории приложений, такие как ERP (Enterprise Resource Planning, управление ресурсами предприятия), CRM (Customer Relationship Management, система управления взаимосвязями с клиентами и партнерами), SCM (Supply Chain Management, управление цепочками поставок), SFA (Sales Force Automation, автоматизация процесса продаж), а также финансовые приложения. Специализированные высокопроизводительные серверы, оптимизированные для работы большинства популярных баз данных, образуют многомиллиардный рынок, и еще большие миллиарды добавляет рынок дешевых серверов. Базы данных работают «за сценой» большинства транзакционно-ориентированных веб-сайтов и используются для хранения и анализа пользовательских транзакций. Таким образом, управление данными пронизывает все сегменты компьютерного рынка.
С конца 1980-х годов произошел стремительный взлет популярности СУБД конкретного типа — системы управления реляционными базами данных (СУРБД). С тех пор реляционная база данных стала, по сути, стандартом баз данных. Информация в реляционной базе данных хранится в простом табличном виде, что дает реляционным базам данных много преимуществ по сравнению с базами данных более ранних разработок. SQL предназначен, в первую очередь, для работы именно с реляционными базами данных.
Краткая история SQL
История SQL тесно связана с развитием реляционных баз данных. В табл. 1 перечислены основные вехи его сорокалетней истории. Понятие реляционной базы данных было введено доктором Э. Ф. Коддом (Edgar Frank «Ted» Codd), научным сотрудником компании IBM. В июне 1970 года доктор Кода опубликовал в журнале Communications of the Association for Computing Machinery статью «Реляционная модель для больших банков совместно используемых данных» («A Relational Model of Data for Large Shared Data Banks»), в которой в общих чертах была изложена математическая теория хранения данных в табличной форме и их обработки. От этой статьи и берут свое начало реляционные базы данных и SQL.
Год
Событие
Доктор Кода создает модель реляционной базы данных
Начинается разработка проекта System/R компании IBM
Первая статья с описанием языка SEQUEL
Опытная эксплуатация проекта System/R
Появляется первая коммерческая СУРБД компании Oracle
Компания Relational Technology выпускает СУБД Ingres
Компания IBM создает СУБД SQL/DS
ANSI формирует комитет по стандартизации языка SQL
Компания IBM объявляет о создании СУБД DB2
ANSI принимает стандарт SQL1
Компания Sybase создает СУРБД для обработки транзакций
ISO одобряет стандарт SQL1
Компании Ashton-Tate и Microsoft объявляют о выпуске СУБД SQL Server для операционной системы OS/2
Опубликован первый тест производительности ТРС (ТРС-А)
Опубликован тест производительности ТРС-В
Консорциум SQL Access Group публикует спецификацию доступа к базам данных
Компания Microsoft публикует спецификацию протокола ODBC
ANSI принимает стандарт SQL2 (SQL-92)
Опубликован тест производительности ТРС-С (OLTP)
Первые поставки систем обслуживания хранилищ данных
Первые поставки программных продуктов, поддерживающих протокол ODBC
Коммерческие поставки серверов баз данных, поддерживающих параллельную обработку
Первый выпуск СУРБД с открытым кодом MySQL
Опубликован стандарт API-функций для доступа к базам данных OLAP и тест производительности OLAP-систем
Компания IBM выпускает СУБД DB2 Universal Database, унифицировав ее архитектуру для работы на платформах других поставщиков
Ведущие поставщики СУБД объявили о поддержке Java-технологий
Компания Microsoft выпустила СУБД SQL Server 7, обеспечив поддержку корпоративных баз данных для платформы Windows NT
Выпущена СУБД Oracle 8i, ознаменовавшая отход от архитектуры «клиент/сервер” и обеспечившая интеграцию баз данных с Интернетом
Первый выпуск базы данных, полностью размещающейся в оперативной памяти
J2EE стандартизовал JDBC-доступ к базам данных со стороны серверов приложений
Первые годы
Статья доктора Кодда вызвала волну исследований в области реляционных баз данных, включая большой исследовательский проект компании IBM. Цель этого проекта, названного System/R, заключалась в том, чтобы доказать работоспособность реляционной модели и приобрести опыт реализации реляционной СУБД. Работа над проектом System/R началась в середине 70-х годов в лаборатории Санта-Тереза компании IBM в городе Сан-Хосе, штат Калифорния.
В 1974-1975 годах, на первом этапе выполнения проекта System/R, был создан минимальный прототип реляционной СУБД. Кроме разработки самой СУБД, в рамках проекта System/R проводилась работа над созданием языков запросов к базе данных. Один из этих языков был назван SEQUEL (Structured English Query Language— структурированный английский язык запросов). В 1976-1977 годах разработанный прототип проекта System/R был полностью переделан, и в 19781979 годах новая реализация проекта System/R была установлена на компьютерах нескольких заказчиков компании IBM для опытной эксплуатации. Эта эксплуатация принесла пользователям первый реальный опыт работы с СУБД System/R и ее языком базы данных, который по юридическим соображениям был переименован в SQL. В 1979 году исследовательский проект System/R завершился, и IBM сделала заключение, что реляционные базы данных не только вполне работоспособны, но и могут служить основой для создания коммерческих программных продуктов.
Первые реляционные СУБД
Проект System/R и созданный в его рамках язык работы с базами данных под названием SQL были подробно описаны в технических журналах 1970-х годов. Семинары по технологии баз данных характеризовались дебатами о достоинствах новой «еретической» реляционной модели. Уже в 1976 году было ясно, что IBM стала энтузиастом реляционной технологии баз данных и прилагает значительные усилия для развития языка SQL.
Сообщения о проекте System/R привлекли внимание группы инженеров из города Менлоу Парк, штат Калифорния, которые решили, что исследования компании IBM предвещают значительный рынок сбыта для реляционных баз данных. В 1977 году они организовали компанию Relational Software, Inc., чтобы создать реляционную СУБД, основанную на SQL. Поставки этой СУБД, названной Oracle, начались в 1979 году. Oracle стала первой реляционной СУБД на компьютерном рынке. Она на целых два года опередила появление первой реляционной СУБД компании IBM и предназначалась для мини-компьютеров VAX компании Digital, которые были дешевле больших ЭВМ компании IBM. Эта компания агрессивно продвигала новый реляционный стиль управления базами данных и в конечном счете в качестве нового имени приняла название своей разработки. Сегодня Oracle Corporation является ведущим поставщиком реляционных СУБД с годовым оборотом свыше десяти миллиардов долларов.
Профессора из компьютерных лабораторий Калифорнийского университета (город Беркли) также исследовали реляционные базы данных в середине 1970-х годов. Подобно исследовательской группе компании IBM, они создали прототип реляционной СУБД и назвали свою систему Ingres. Проект Ingres включал в себя язык запросов QUEL, который был более «структурированным», но менее похожим на английский, чем язык SQL. Многие специалисты по базам данных, разработчики и основатели компаний, работающих в этой области, начинали свою деятельность с проекта Ingres.
В 1980 году несколько профессоров покинули Беркли и основали компанию Relational Technology, Inc., чтобы создать коммерческую версию системы Ingres, поставки которой на рынок начались в 1981 году. Ingres и Oracle сразу же вступили в острую конкурентную борьбу, но это соперничество лишь привлекло внимание к технологии реляционных баз данных. Несмотря на техническое превосходство во многих областях, Ingres вскоре стала сдавать свои позиции, не выдержав конкуренции с возможностями, предлагаемыми языком SQL, а также по причине агрессивной маркетинговой политики компании Oracle. В 1986 году первоначальный язык запросов QUEL был заменен на SQL. Это являлось свидетельством того, что стандарт SQL стал важным рыночным фактором. В середине 90-х годов технология Ingres была продана компании Computer Associates, ведущему производителю программного обеспечения для мэйнфреймов (которая продала свою долю в Ingres в 2005 году).
Продукты IBM
В то время как Oracle и Ingres становились коммерческими продуктами, компания IBM также предпринимала усилия по превращению проекта System/R в коммерческую разработку, получившую название SQL/Data System (SQL/DS). В 1981 году IBM объявила о создании СУБД SQL/DS, а в 1982 году начала ее поставки на рынок. В 1983 году IBM анонсировала версию SQL/DS для операционной системы VM/CMS, часто используемой на больших ЭВМ компании IBM в корпоративных информационных центрах.
В 1983 году IBM разработала еще одну реляционную СУБД для своих больших ЭВМ — Database 2 (DB2). Эта СУБД функционировала под управлением операционной системы MVS, которая являлась «рабочей лошадкой» в крупных центрах по обработке данных на мэйнфреймах. Поставки на рынок первой версии DB2 начались в 1985 году, и представители компании IBM назвали ее своим стратегическим программным продуктом. С этого времени DB2 стала флагманом реляционных СУБД компании IBM. Благодаря значительному влиянию IBM на рынок вычислительных систем, язык SQL этой СУБД фактически стал стандартом языка управления базами данных. Технология, реализованная в DB2, затем была использована в программных продуктах всех направлений компании IBM, от персональных компьютеров до сетевых серверов и мэйнфреймов. В 1997 году IBM пошла еще дальше, объявив о создании версий DB2 для компьютерных систем своих конкурентов— компаний Sun Microsystems и Hewlett-Packard. DB2 для мэйнфреймов остается центральным элементом стратегии IBM в области баз данных.
Коммерческое признание
В течение первой половины 1980-х годов поставщики реляционных баз данных боролись за коммерческое признание своих продуктов. По сравнению с традиционными архитектурами баз данных, реляционные программные продукты имели несколько недостатков. Производительность реляционных баз данных была ниже, чем традиционных. За исключением продуктов компании IBM, реляционные базы данных поставлялись на рынок мелкими, начинающими, поставщиками. И, опять же, за исключением продуктов IBM, реляционные базы данных предназначались для мини-компьютеров, а не для мэйнфреймов.
Однако у реляционных продуктов было большое преимущество. Реализованные в них языки реляционных запросов (SQL, QUEL и другие) позволяли выполнять запросы к базе данных без написания программ и немедленно получать результаты. В результате реляционные базы данных постепенно стали использоваться в качестве инструментов для поддержки принятия решений. В мае 1985 года компания Oracle с гордостью объявила о том, что количество инсталляций реляционных продуктов ее производства превысило одну тысячу. Ingres к тому времени также была инсталлирована на сравнимом количестве компьютеров. Постепенно начали получать признание и продукты DB2 и SQL/DS, общее число инсталляций которых тоже превысило тысячу.
Во второй половине 1980-х годов реляционные базы данных уже стали считаться технологией баз данных будущего. Резко увеличилась производительность реляционных баз данных. В частности, каждая новая версия Ingress и Oracle превосходила предшественницу в два-три раза. На увеличении этого показателя сказался и общий рост быстродействия компьютеров.
В конце 1980-х годов росту популярности SQL начали способствовать и рыночные тенденции. Компания IBM продвигала на рынок систему DB2 как лучшее решение 1990-х годов. Опубликование в 1986 году стандарта SQL, принятого ANSI/ISO, официально придало SQL статус стандартного языка баз данных. Кроме того, SQL стал стандартом для компьютерных систем на базе UNIX, популярность которых также росла ускоренными темпами в конце 1980-х годов. По мере увеличения мощности персональных компьютеров и объединения их в локальные сети возникла необходимость в более сложных СУБД. Поставщики таких СУБД при создании систем нового поколения для персональных компьютеров взяли за основу SQL, а поставщики СУБД для мини-компьютеров, чтобы выдержать конкуренцию со стороны персональных компьютеров, вышли на зарождающийся рынок локальных вычислительных сетей.
В начале 1990-х годов усовершенствование реализаций SQL и резкое возрастание мощи процессоров сделали SQL практичным решением для приложений обработки транзакций. И наконец, SQL стал ключевой частью архитектуры «клиент/сервер», использующей персональные компьютеры, локальные сети и сетевые серверы для построения дешевых систем обработки информации. С развитием Интернета для SQL нашлась новая роль — в качестве языка баз данных для интернет-приложений и электронной коммерции.
Однако SQL не испытывал и недостатка в конкуренции. К началу 1990-х годов объектно-ориентированное программирование зарекомендовало себя как наиболее перспективный метод разработки приложений, особенно для персональных компьютеров и в области пользовательских графических интерфейсов. Объектная модель данных, со своими объектами, классами, методами и наследованием, плохо соотносилась с реляционной моделью таблиц, строк и столбцов данных. Ранние «объектные базы данных» включали Gemstone от Servio Logic, Gbase от Graphael и Vbase от Ontologic. В средине 1990-х годов выросло новое поколение компаний, рассчитывавших на то, что объектные базы данных вытеснят с рынка реляционные базы данных и их производителей, так же как в свое время SQL поступил с нереляционными базами данных. Здесь можно упомянуть такие продукты, как ITASCA от Itasca Systems, Jasmine от Fujitsu, Matisse от Matisse Software, Objectivity/DB от Objectivity, ONTOS от Ontos, Inc. (переименованного из Ontologic), 02 от 02 Technology, а также с полдесятка других. Ho SQL и реляционная модель более чем устояли перед этим натиском. Некоторые из упомянутых продуктов остались на рынке и сегодня, но большинство было просто куплено или сгинуло во мгле времени. Например, 02 Technology постигла судьба некоторых других компаний, купленных Informix, a Informix, в свою очередь, позже был приобретен IBM. Общие годовые доходы объектно-ориентированных баз данных измеряются миллионами долларов, в то время как рынок SQL, СУРБД, соответствующих инструментов и служб оценивается в десятки миллиардов долларов в год.
По мере развития SQL этот язык стал применяться для решения множества задач, связанных с управлением данными, и постепенно, к концу 90-х годов, рынок баз данных перестал быть монолитным, разделившись на ряд специализированных сегментов. Одним из наиболее быстрорастущих среди них стал сегмент хранилищ данных, где базы данных применяются для анализа огромных объемов информации на предмет выявления скрытых тенденций и моделей развития. Другим направлением является внедрение в SQL новых типов данных (в частности, мультимедийных) и объектно-ориентированных принципов. Третий важный сегмент — это «мобильные» базы данных для переносных персональных компьютеров, взаимодействующие с централизованными базами данных как в оперативном, так и в автономном режиме. Еще одним сегментом оказываются базы данных, работающие с оперативной памятью, разрабатывающиеся как очень высокопроизводительные, ориентированные на работу с потоком базы данных, предназначенные для управления сетевыми потоками данных.
Несмотря на появление различных сегментов рынка, SQL по-прежнему остается их общим знаменателем. И через сорок лет после его возникновения позиции SQL так же сильны, как и ранее. SQL остается стандартом в области баз данных. Всегда будут появляться новые проблемы — например, сейчас это необходимость включения поддержки XML и его иерархической модели данных, а также необходимость поддержки огромных массивов данных в масштабе Интернета. Но история последних сорока лет дает все основания рассчитывать на то, что SQL и реляционная модель обладают изрядным запасом сил и способны справиться с новыми требованиями к управлению данными.
Стандарты SQL
Одним из наиболее важных шагов на пути к признанию SQL на рынке стало появление стандартов этого языка. Обычно при упоминании «стандарта SQL» имеют в виду официальный стандарт, утвержденный Американским национальным институтом стандартов (American National Standards Institute, ANSI) и Международной организацией по стандартизации (International Standards Organization, ISO). Однако существуют и другие важные стандарты, включая стандарт де- факто, каковым является SQL, реализованный в семействе продуктов DB2 компании IBM, и Oracle-диалект SQL, доминирующий на рынке.
Стандарты ANSI/ISO
Работа над официальным стандартом SQL началась в 1982 году, когда ANSI поставил перед своим комитетом ХЗН2 задачу по созданию стандарта языка управления реляционными базами данных. Вначале в комитете обсуждались преимущества различных предложенных языков. Однако, поскольку к тому времени на рынке стандартом де-факто стал SQL, комитет ХЗН2 остановил свой выбор на нем и занялся его стандартизацией.
Разработанный в результате стандарт в большей степени был основан на диалекте SQL системы DB2, хотя и содержал в себе ряд существенных отличий от этого диалекта. После нескольких доработок в 1986 году стандарт был официально утвержден как стандарт ANSI номер Х3.135, а в 1987 году — в качестве стандарта ISO. Затем стандарт ANSI/ISO был принят правительством США как федеральный стандарт США в области обработки информации (Federal Information Processing Standard, FIPS). Этот стандарт, незначительно пересмотренный в 1989 году, обычно называют стандартом SQL1 или SQL-89.
Многие из членов комитетов ANSI и ISO представляли фирмы-поставщики различных СУБД, в каждой из которых был реализован собственный диалект SQL. Как и диалекты человеческого языка, диалекты SQL были, в основном, похожи друг на друга, однако несовместимы в деталях. Во многих случаях комитет просто обошел существующие различия и не стандартизировал некоторые части языка, определив, что они реализуются по усмотрению разработчика. Этот подход позволил объявить большое число реализаций SQL совместимыми со стандартом, однако сделал сам стандарт относительно слабым.
Чтобы заполнить эти пробелы, комитет ANSI продолжил свою работу и создал проект нового, более жесткого, стандарта SQL2. В отличие от стандарта 1989 года, проект SQL2 предусматривал возможности, выходящие за рамки возможностей, уже реализованных в реальных коммерческих продуктах. А для следующего за ним стандарта SQL3 были предложены еще более глубокие изменения. Кроме того, была предпринята попытка официально стандартизировать те части языка, на которые давно существовали «собственные» стандарты в различных СУБД. В результате предложенные стандарты SQL2 и SQL3 оказались более противоречивыми, чем исходный стандарт. Стандарт SQL2 прошел процесс утверждения в ANSI и был окончательно принят в октябре 1992 года. В то время как первый стандарт 1986 года занимает не более ста страниц, стандарт SQL2 (официально называемый SQL-92) содержит около шестисот.
Существенным нововведением стало официальное утверждение трех уровней совместимости со стандартом SQL2. На самом нижнем, начальном, уровне (Entry Level) от СУБД требуются лишь минимальные дополнительные возможности в сравнении со стандартом SQL-89. Промежуточный уровень (Intermediate Level) представляет собой значительный шаг вперед по отношению к стандарту SQL-89, хотя и не затрагивает наиболее сложных и системно-зависимых аспектов языка SQL. Третий, самый высокий, уровень (Full Level) требует от СУБД реализации всех возможностей стандарта SQL2. В самом стандарте определение каждой возможности сопровождается описанием того, как она должна быть реализована на каждом из трех уровней. Сегодня специализированные базы данных, такие как используемые во встраиваемых приложениях или в приложениях с открытым кодом, в ряде областей обладают начальным уровнем соответствия стандарту SQL, но все основные базы данных уровня предприятия полностью поддерживают стандарт SQL-92.
После принятия SQL-92 работа над стандартами SQL шла в разных направлениях. Единый комитет разделился на ряд подкомитетов, каждый из которых работал над различными расширениями языка. Некоторые из них, например сохраняемые процедуры, уже имелись во многих коммерческих SQL-базах данных. Другие, такие как предложенные объектные расширения SQL, пока что не были широко доступны или полностью реализованы. Новые версии стандарта были выпущены в 1999, 2003, 2006 и 2008 годах. Стандарт 2006 года включал существенные дополнения к XML-части стандарта.
В процессе работы стандарт ANSI/ISO был разделен на 14 частей. Одни из них после некоторой активности в данном направлении оказались заброшены, некоторые вошли в другие части, а над остальными продолжается активная работа.
- Часть 1 — SQL/Framework содержит общие определения и служит «оглавлением» для других частей.
- Часть 2 — SQL/Foundation представляет собой наибольшую часть и содержит определения основных инструкций SQL для определения структуры базы данных и управления данными. Это потомок версий SQL-89 и SQL-92 стандарта. Данная часть существенно расширена путем включения структур для бизнес-анализа.
- Часть 3 —SQL/CLI (Call Level Interface, интерфейс уровня вызовов) описывает интерфейс уровня вызова процедур, хорошо известный как стандарт Microsoft ODBC. Он появился в 1995 году.
- Часть 4—SQL/PSM (Persistent Stored Modules, постоянные хранимые модули) описывает процедурные расширения SQL, аналогичные возможностям, имеющимся в популярных процедурных SQL-языках наподобие PL/SQL в Oracle.
- Часть 5—SQL/Bindings описывает встраивание SQL в другие процедурные языки. Эта часть была объединена с частью 2 в версии SQL:2003 стандарта.
- Часть 6 —SQL/Transaction была посвящена вопросам распределенных транзакций, но затем работа в данном направлении была остановлена.
- Часть 7 —SQL/Temporal была посвящена расширениям SQL для работы с календарными и временными данными, но затем работа в данном направлении была прекращена.
- Часть 8—SQL/Objects в процессе работы над SQL3 содержала объектно-ориентированные расширения SQL. Эти расширения были внесены в часть 2 в стандарте SQLil
- Часть 9 —SQL/MED (Management of External Data, управление внешними данными) добавляет в язык возможности по работе с нереляционными источниками данных; появилась в стандарте SQL:2003.
- Часть 10—SQL/OLB (Object Language Bindings, связи с объектными языками) описывает обращение к SQL из языка программирования Java. Она связана с JDBC и SQL, встроенным в Java, и появилась в стандарте SQL:2003.
- Часть 11 —SQL/Schemata содержит стандарты для »каталога базы данных», или таблиц с самоописывающей базу данных системной информацией. Эта спецификация находилась в стандарте SQL:1999 в части 2, но была вынесена в отдельную часть в стандарте SQL:2003.
- Часть 12 —SQL/Replication изначально определяла стандарты копирования из одной SQL-базы данных в другую, но затем работа в данном направлении была прекращена.
- Часть 13—SQL/JRT (Java Routines and Types, подпрограммы и типы Java) описывает подпрограммы и типы, используемые языком программирования Java для доступа к SQL-базам данных; впервые появилась в стандарте SQL:2003.
- Часть 14—SQL/XML описывает интеграцию XML (Extensible Markup Language, расширяемый язык разметки) в язык Впервые появилась в стандарте SQL:2003 и с тех пор была значительно расширена.
С нескольких сотен страниц, описывающих базовые возможности языка SQL в 1986 году, стандарт ANSI/ISO SQL значительно вырос— как по объему, так и в смысле сложности и охвата различных тем. «Реальный» стандарт SQL, конечно, представляет собой SQL, реализованный в продуктах, занимающих важное место на рынке. Программисты и пользователи, как правило, предпочитают придерживаться тех частей языка, которые одинаковы у большинства продуктов. Большинство новых расширений SQL начинаются как новшества крупных производителей баз данных. Некоторые из них так и не получают поддержку и со временем исчезают из языка. Другие годами остаются в языке с единственной целью обеспечить обратную совместимость. Третьи же, наиболее удачные в коммерческом смысле, попадают «в струю», широко распространяются среди баз данных и в конечном счете оказываются в официальном стандарте.
Другие ранние стандарты SQL
Хотя стандарт ANSI/ISO наиболее широко распространен, он не был единственным стандартом SQL во времена его становления. Европейская группа поставщиков X/OPEN также приняла SQL в качестве одного из своих стандартов для среды переносимых приложений на основе UNIX. Стандарты группы X/OPEN играли важную роль на европейском компьютерном рынке, где ключевой задачей являлась переносимость приложений между компьютерными системами различных производителей.
Компания IBM также включила SQL в свою спецификацию Systems Application Architecture (архитектуры прикладных систем) в 1990-х годах и пообещала, что все ее продукты в конечном счете будут переведены на этот диалект SQL. Хотя данная спецификация и не оправдала надежд на унификацию линии продуктов компании IBM, движение в сторону унификации IBM SQL продолжается. Система DB2 остается основной СУБД компании IBM для мэйнфреймов, однако компания выпустила реализацию DB2 и для OS/2, собственной операционной системы для персональных компьютеров, и для линии серверов и рабочих станций RS/6000, работающих под управлением UNIX. Распространение DB2 (не только на разные аппаратные системы, но и для разных типов данных) воплотилось в названии одной из последних реализаций DB2 — Universal Database (универсальная база данных, UDB).
ODBC и консорциум SQL Access Group
В технологии баз данных существует важная область, которую не затрагивали ранние официальные стандарты. Это взаимодействие баз данных — методы, с помощью которых различные базы данных могут обмениваться информацией, обычно по сети. В 1989 году несколько производителей программного обеспечения сформировали консорциум SQL Access Group специально для решения этой проблемы. В 1991 году консорциум опубликовал спецификацию RDA (Remote Database Access, удаленный доступ к базам данных). К сожалению, эта спецификация была тесно связана с сетевыми протоколами OSI, которые проиграли сетевую битву протоколам TCP/IP, поэтому она никогда не была широко реализована.
Второй стандарт от SQL Access Group повлиял на рынок существенно сильнее. В результате настойчивых требований компании Microsoft консорциум SQL Access Group обратил свое внимание на интерфейс уровня вызовов. Спецификация CLI (Call Level Interface, интерфейс уровня вызовов), основанная на разработках компании Microsoft, увидела свет в 1992 году. В этом же году был опубликован и протокол ODBC (Open Database Connectivity, открытый доступ к базам данных) компании Microsoft, основанный на спецификации CLI. Благодаря рыночному влиянию Microsoft и благословению, полученному «открытым стандартом» от SQL Access Group, ODBC оказался стандартом де-факто для интерфейсов доступа к SQL-базам данных на персональных компьютерах. Весной 1993 года компании Apple и Microsoft объявили о соглашении относительно поддержки ODBC в Macintosh и Windows, что закрепило за этим протоколом статус промышленного стандарта в обеих популярных средах с графическим пользовательским интерфейсом. Вскоре появилась реализация ODBC для платформы UNIX. В 1995 году, с публикацией стандарта SQL/Call-Level Interface, интерфейс ODBC стал стандартом ANSI/ISO.
В течение последних десяти лет ODBC продолжает развиваться, но существенно медленнее. Microsoft продолжает поддерживать ODBC, но основные усилия перенесены в область создания более высокоуровневых, объектно-ориентированных интерфейсов для универсального доступа к базам данных. Тем не менее ODBC продолжает играть главную роль в обеспечении переносимости баз данных для приложений уровня предприятия и инструментария баз данных. Достаточно распространена ситуация, когда инструментарий базы данных или приложение уровня предприятия поддерживает «драйвер», оптимизирующий непосредственный доступ к базам данных Oracle, DB2 или SQL Server с помощью их специфических интерфейсов уровня вызова. Такое приложение обычно включает дополнительный драйвер, использующий в качестве способа поддержки широкого диапазона других баз данных ODBC. Поскольку этот подход принят очень многими приложениями и инструментами, практически все производители баз данных предоставляют доступ с применением ODBC, иногда в качестве основного интерфейса уровня вызовов, а иногда как дополнение к высокопроизводительному интерфейсу, специфичному для данной базы данных.
JDBC и серверы приложений
Стремительный рост популярности Интернета привел к дальнейшему развитию стандартов обращения к базам данных, с тем чтобы они поддерживали работу с объектно-ориентированным языком программирования Java. Java стал, по сути, стандартным языком для создания интернет-приложений, работающих на серверах приложений на базе Java. Компания Sun Microsystems, разработчик Java, приложила немалые усилия по стандартизации применения Java для серверов приложений в спецификации Java2 Enterprise Edition (J2EE). J2EE включает Java Database Connectivity (JDBC) в качестве стандарта доступа к реляционным базам данных из Java. В отличие от доступа к базам данных из языка программирования С, где ODBC многие годы предшествовали интерфейсы уровня вызовов конкретных баз данных, стандарт JDBC был разработан относительно рано, на пике роста популярности Java. В результате частные интерфейсы для подключения к Java так и не появились, и единственным стандартом SQL-доступа со стороны Java стал JDBC.
SQL и переносимость
Появление стандарта SQL вызвало довольно много восторженных заявлений о переносимости SQL и использующих его приложений. Для иллюстрации того, как любое приложение, используя SQL, может работать с любой СУБД на основе SQL, часто приводят диаграммы, подобные изображенной на рис. 1. На самом деле различия между существующими диалектами SQL достаточно значительны, так что при переводе приложения под другую СУБД его, как правило, приходится модифицировать. Со временем ядро языка становится все более стандартным, но в то же время производители баз данных добавляют в язык новые возможности, часто с расширениями, специфичными для конкретной базы данных. Рассмотрим примеры областей, в которых возникают такие отличия.
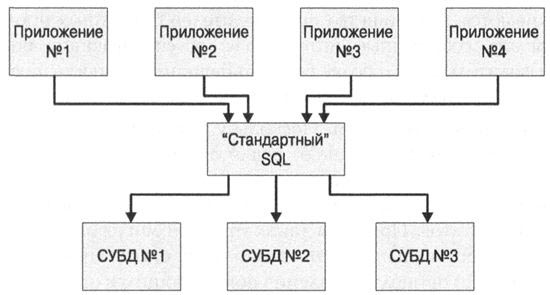
Рис. 1. Миф о переносимости SQL
- Типы данных. В стандарте SQL определен достаточно широкий набор типов данных, однако производители постоянно добавляют новые типы. Даже старые типы данных могут помешать переносимости — например, специфичный для Oracle тип данных NUMBER широко используется для представления числовых данных в базах данных Oracle, — и при этом только в них.
- Обратная совместимость. Не такая уж редкость встретить приложение уровня предприятия, работающее один-два десятка лет после того, как оно было написано, когда все программисты, создававшие его, давно уволены (или уволились). Такие программы становятся «неприкасаемыми», поскольку детальное знание о том, как они функционируют, оказывается утраченным. Большие разделы этих программ могут зависеть от старых, специфичных для данной базы данных, свойств SQL, так что производители баз данных вынуждены поддерживать обратную совместимость, иначе имеется риск, что старые приложения перестанут работать. Такие увековеченные отличия диалектов препятствуют переносимости.
- Системные таблицы. В стандарте SQL описание системных таблиц, в которых содержится информация о структуре самой базы данных, появилось только в версии SQL-92. Поэтому каждый производитель создавал собственные системные таблицы, которые продолжают развиваться и эволюционировать и зачастую содержат информацию, которая выходит за указанные в стандарте пределы. Приложения, использующие такие специфичные для конкретной базы данных системные таблицы, непереносимы.
- Программный интерфейс. В раннем стандарте SQL определен абстрактный способ использования SQL в приложениях, написанных на таких языках программирования, как COBOL, С, FORTRAN и другие, который не был широко принят сообществом программистов. Стандарт SQL/CLI 1995 года окончательно определил программный доступ к SQL, но к тому времени коммерческие СУБД уже популяризовали собственные интерфейсы и внедрили их в сотни тысяч пользовательских приложений и прикладных пакетов. Хотя в настоящее время стандартные API и широко поддерживаются, большинство производителей баз данных продолжают предоставлять собственные интерфейсы, обеспечивающие более высокую производительность и более богатую функциональность, побочным действием которых является привязка к конкретной базе данных.
- Семантические отличия. Поскольку некоторые элементы определены в стандартах как зависящие от реализации, может возникнуть ситуация, когда в результате выполнения одного и того же запроса в двух отвечающих стандарту реализациях SQL будут получены два различных набора результатов. Примеры таких отличий могут быть найдены, например, в обработке значений NULL, в разных статистических функциях и в несовпадении процедур удаления повторяющихся строк.
- Репликация и зеркальное копирование данных. Многие промышленные базы данных содержат таблицы, которые дублируются в двух или большем количестве географически разнесенных баз данных, чтобы обеспечить высокую степень доступности или восстановления после аварий, для распределения нагрузки или снижения задержек при работе в сети. Методы, используемые для определения таких схем репликации и управления ими, у каждой базы данных свои, и от попыток стандартизовать процессы репликации пришлось отказаться.
- Коды ошибок. Коды, возвращаемые инструкциями SQL при возникновении ошибок, появились в стандарте SQL-92, но все популярные СУБД к настоящему времени давно используют собственные коды ошибок. Даже при использовании режима со стандартными кодами ошибок расширения в конкретных базах данных могут генерировать собственные коды, выходящие за рамки, определенные стандартом.
- Структура базы данных. В стандарте SQL-89 определен язык SQL, который используется уже после того, как база данных открыта и подготовлена к работе. Детали наименования баз данных и установки первоначального подключения к тому времени уже сильно отличались. Стандарт SQL-92 в некоторой степени унифицирует этот процесс, но не может полностью скрыть детали реализации.
Несмотря на перечисленные отличия, в начале 1990-х годов стали появляться (и популярны по сей день) коммерческие инструменты для работы с базами данных, реализующие переносимость между рядом различных СУБД. На практике такие программы всегда включают специальные драйвера для работы с определенными СУБД. Эти драйвера генерируют код в соответствии с определенным диалектом SQL, выполняют преобразования типов данных, трансляцию кодов ошибок и т.д.
SQL и сети
Резкий рост компьютерных сетей в 1990-х годах оказал большое влияние на управление базами данных и придал SQL новые возможности. По мере распространения сетей, приложения, которые традиционно работали на центральном мини-компьютере или мэйнфрейме, переводятся на серверы и рабочие станции ЛВС. В таких сетях SQL играет важнейшую роль и связывает приложение, выполняющееся на рабочей станции с графическим пользовательским интерфейсом, и СУБД, управляющую совместно используемыми данными на сервере. Рост популярности Интернета и Веб еще больше усилил влияние SQL в сфере сетевых технологий. С появлением трехуровневой архитектуры Интернета язык SQL стал связующим звеном между прикладной логикой (работающей на среднем уровне, сервере приложений или веб-сервере) и базой данных (третий уровень). В следующих подразделах мы поговорим о развитии архитектур сетевого управления базами данных и о роли, которую SQL играет в каждой из них.
Централизованная архитектура
На рис. 2 изображена традиционная централизованная архитектура баз данных, использовавшаяся в DB2 и первоначальных базах данных для миникомпьютеров, таких как Oracle и Ingres. В этой архитектуре и СУБД, и сами физические данные размещаются на центральном мини-компьютере или мэйнфрейме вместе с приложением, принимающим входную информацию с пользовательского терминала и отображающим на нем же данные. Прикладная программа «общается» с СУБД с помощью SQL.
Рис. 2. Управление базами данных в централизованной архитектуре
Предположим, что пользователь вводит запрос, который требует последовательного просмотра базы данных (например, запрос на вычисление среднего значения суммы сделок по всем заказам). СУБД получает этот запрос, просматривает базу данных, выбирая с диска каждую запись, вычисляет среднее значение и отображает результат на экране. Приложение и СУБД работают на одном компьютере, так что этот тип запросов (как и всех прочие) выполняется весьма эффективно.
Недостатки централизованной архитектуры проявляются при масштабировании. Поскольку система обслуживает много различных пользователей, каждый из них ощущает снижение быстродействия по мере увеличения нагрузки на систему.
Архитектура файлового сервера
Появление персональных компьютеров и локальных вычислительных сетей привело к разработке архитектуры файлового сервера (рис. 3). При такой архитектуре приложение, выполняемое на персональном компьютере, может получить прозрачный доступ к файловому серверу, на котором хранятся совместно используемые файлы. Когда приложение, работающее на персональном компьютере, запрашивает данные из такого файла, сетевое программное обеспечение автоматически считывает требуемый блок данных с сервера. Архитектура файловых серверов поддерживалась первыми СУБД для персональных компьютеров, такими как dBASE и позднее Microsoft Access, при этом на каждом персональном компьютере работала своя копия СУБД.
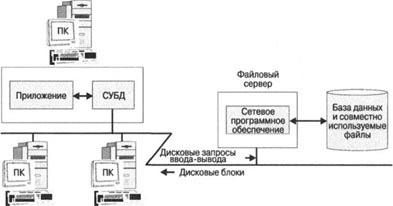
Рис. 3. Управление базами данных в архитектуре файлового сервера
При выполнении типичных запросов, когда требуется получение одной или небольшого количества строк из базы данных, эта архитектура обеспечивает великолепную производительность, поскольку в распоряжении каждой копии СУБД находятся все ресурсы персонального компьютера. Однако рассмотрим запрос из приведенного выше примера. Поскольку запрос требует последовательного просмотра базы данных, СУБД постоянно запрашивает новые записи из базы данных, которая физически расположена на сервере. В конечном счете СУБД запросит и получит по сети все блоки файла. Очевидно, что при выполнении запросов такого типа эта архитектура создает слишком большую нагрузку на сеть и уменьшает производительность работы.
Архитектура “клиент/сервер”
На рис. 4 изображена очередная стадия эволюции сетевых баз данных — архитектура клиент/сервер. В этой схеме персональные компьютеры объединены в локальную сеть, в которой имеется сервер баз данных, хранящий общие базы данных. Функции СУБД разделены на две части: пользовательские программы, такие как приложения для формирования интерактивных запросов, генераторы отчетов и прикладные программы, выполняются на клиентском компьютере, а ядро базы данных, которое хранит данные и управляет ими, работает на сервере. В этой архитектуре, популярность которой существенно возросла в течение 1990-х годов, SQL стал стандартным языком, обеспечивающим взаимодействие между пользовательскими программами и ядром базы данных.
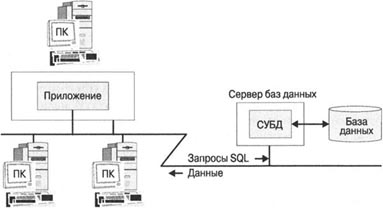
Рис. 4. Управление базами данных в архитектуре “клиент/сервер”
Давайте еще раз рассмотрим пример с вычислением средней стоимости заказа. При архитектуре «клиент/сервер» запрос передается по сети на сервер баз данных в виде SQL-запроса. Ядро базы данных на сервере обрабатывает запрос и просматривает базу данных, которая также расположена на сервере. После вычисления результата ядро базы данных посылает его обратно по сети клиентскому приложению, которое отображает его на экране персонального компьютера.
Архитектура «клиент/сервер» снижает сетевой трафик и распределяет процесс загрузки базы данных. Функции для работы с пользователем, такие как обработка ввода и отображение данных, выполняются на персональном компьютере пользователя. Функции для работы с данными, такие как дисковый ввод-вывод и выполнение запросов, выполняются сервером баз данных. Наиболее важно то, что SQL обеспечивает четко определенный интерфейс между клиентской и серверной системами, эффективно передавая запросы на доступ к базе данных.
Преимущества данной архитектуры сделали ее наиболее популярной схемой при разработке новых приложений в середине 1990-х годов. Все ведущие СУБД — Oracle, Informix, Sybase, SQL Server, DB2 и многие другие — стали предлагать клиент-серверные возможности. Многие компании начали выпускать средства разработки приложений «клиент/сервер». Некоторые из них разрабатывались производителями баз данных, иные — сторонними производителями.
У архитектуры «клиент/сервер», как и у всех остальных, есть свои недостатки. Наиболее серьезный из них— проблема управления прикладным программным обеспечением, расположенным на тысячах персональных компьютеров, а не на одной центральной машине. Обновление какого-либо приложения одновременно на тысяче персональных компьютеров в крупной компании требовало от его информационного подразделения огромных усилий. Все становилось еще хуже, если изменения в прикладной программе должны были быть синхронизированы с изменениями в других приложениях или в самой СУБД. Кроме того, пользователи часто самостоятельно инсталлировали вспомогательное программное обеспечение и настраивали установленные программы на свой манер, что, безусловно, в значительной степени усложняло задачу администрирования. Компании разрабатывали специальные стратегии борьбы с этими проблемами, но все равно к концу 1990-х годов возникла необходимость пересмотреть концепции управления приложениями «клиент/сервер» в больших распределенных системах.
Многоуровневая архитектура
С развитием Интернета и особенно Веб архитектура сетевого управления базами данных получила дальнейшее развитие. Поначалу WWW являлась средой просмотра статических документов и развивалась независимо от рынка СУБД. Но когда веб-браузеры получили широкое распространение, разработчики пришли к выводу, что это очень удобный способ обеспечения доступа к корпоративным базам данных. Предположим, к примеру, что торговая компания располагает собственным веб-сайтом, на котором клиенты могут найти информацию о товарах, выпускаемых компанией, включая текстовое и графическое их описание. Естественным следующим шагом будет предоставление клиентам доступа к информации о наличии выбранного товара на складе, причем посредством того же интерфейса веб-браузера. Для этого требуется связать последний с базой данных, хранящей такую (постоянно меняющуюся) информацию.
Методы связывания веб-серверов и СУБД стремительно развивались в конце 1990-х-начале 2000-х годов, и в итоге это вылилось в трехуровневую сетевую архитектуру, показанную на рис. 5. Интерфейсом пользователя является веб-браузер, работающий на персональном компьютере или некотором другом «тонком клиенте», например таком, как смартфон. Браузер взаимодействует с веб-сервером на прикладном уровне. Если пользователь запрашивает нечто большее, чем просто статические веб-страницы, веб-сервер переадресует запрос серверу приложений, роль которого заключается в применении бизнес-логики, необходимой для обработки запроса. Зачастую запрос включает обращение к старой системе, работающей на мэйнфрейме, либо к корпоративной базе данных. Это серверный уровень модели.
Как и в случае архитектуры «клиент/сервер», SQL является стандартным языком баз данных для обмена информацией между сервером приложений и серверами баз данных. Все программные продукты прикладного уровня для обращения к базам данных оснащены API на основе SQL. Поскольку большинство коммерческих серверов приложений использует стандарт Java2 Enterprise Edition (J2EE), ведущим API для доступа сервера приложений к базе данных является Java Database Connectivity (JDBC).
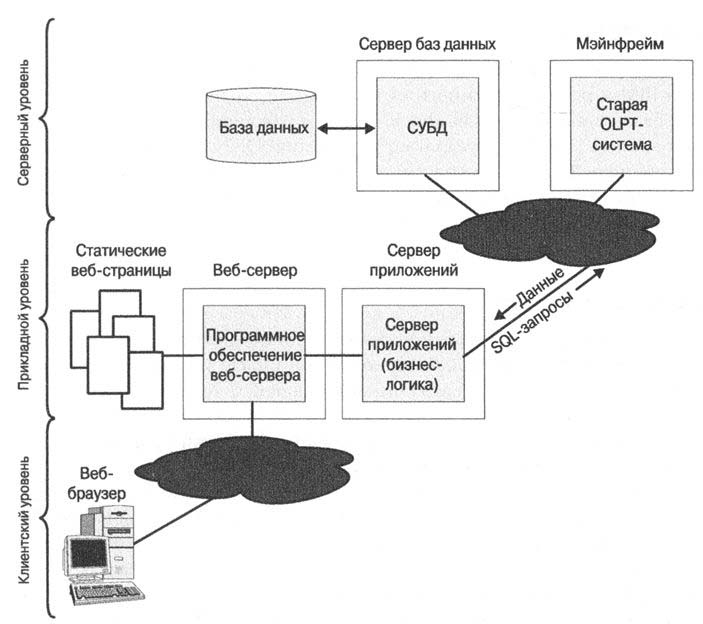
Рис. 5. Управление базами данных в трехуровневой интернет-архитектуре
Влияние SQL на ИТ-индустрию и рынок
Будучи стандартным языком доступа к реляционным базам данных, SQL оказывает большое влияние на все сегменты компьютерного рынка. SQL-база данных IBM DB2 доминирует в области управления данными на мэйнфреймах. База данных Oracle контролирует рынок компьютерных систем и серверов под управлением UNIX. SQL Server от Microsoft — ведущая SQL-база данных для серверных операционных систем Windows для рабочих групп и ведомственных приложений. MySQL доминирует на рынке баз данных с открытым кодом. SQL принят в качестве технологии для оперативной обработки транзакций (online transaction processing, OLTP), что полностью опровергает мнение 1980-х годов о том, что реляционные базы данных никогда не станут достаточно производительны для применения в приложениях обработки транзакций. Хранилища данных и приложения для извлечения информации на базе SQL используются для изучения пользовательского спроса, с тем чтобы предоставлять продукты и услуги, в большей степени соответствующие требованиям рынка. В Интернете базы данных на основе SQL служат основой для более персонализированных продуктов, служб и информационных сервисов, что является ключевым преимуществом электронной коммерции.
SQL и мэйнфреймы
Хотя иерархическая база данных IMS от IBM все еще предлагается для мэйнфреймов IBM и работает со многими высокопроизводительными приложениями, ведущей базой данных для мэйнфреймов уже более чем два десятилетия является SQL-база данных DB2. IBM предлагает реализации DB2 для разных архитектур, но DB2 для мэйнфреймов можно рассматривать как «плавбазу для всей эскадры» баз данных IBM. Любые новые разработки баз данных для мэйнфреймов используют DB2, укрепляя доминирующую роль SQL в области обработки данных на мэйнфреймах.
SQL и мини-компьютеры
Сегмент рынка реляционных СУБД для мини-компьютеров начал развиваться одним из первых. Первые продукты компаний Oracle и Ingres предназначались для мини-компьютеров VAX/VMS компании Digital. С тех пор обе СУБД были перенесены на множество других платформ. СУБД компании Sybase, появившаяся позднее и предназначавшаяся для оперативной обработки транзакций, работала на нескольких платформах, включая VAX.
Кроме того, на протяжении 1980-х годов поставщики мини-компьютеров разрабатывали собственные реляционные СУБД на основе SQL. Компания Digital на каждую систему VAX/VMS устанавливала собственную СУБД Rdb/VMS. Компания Hewlett-Packard поставляла Allbase— СУБД, поддерживающую как HPSQL (диалект SQL от компании Hewlett-Packard), так и нереляционный интерфейс. Компания Data General поменяла свои старые нереляционные базы данных на СУБД DG/SQL. К тому же многие из поставщиков мини-компьютеров перепродавали реляционные СУБД независимых поставщиков. Все это помогло языку SQL утвердиться в качестве важной технологии в системах среднего уровня.
Со средины 1990-х годов SQL-продукты поставщиков мини-компьютеров, в основном, исчезли, уступив место мультиплатформенным разработкам компаний Oracle, Informix, Sybase и др. Oracle приобрела Rdb компании Digital; другие продукты постепенно оказались заброшены. Одновременно с этим угасло и влияние специализированных операционных систем для мини-компьютеров— всех их заменила операционная система UNIX. Вчерашний рынок реляционных продуктов для мини-компьютеров стал сегодняшним рынком серверов баз данных для платформы UNIX.
SQL и UNIX
SQL был однозначно признан лучшим решением в области управления данными для компьютерных систем на базе платформы UNIX. Операционная система UNIX, которая изначально была разработана в Bell Laboratories, в 1980-х годах стала стремительно завоевывать популярность как независимая от производителя стандартная операционная система. Она работает на разнообразных компьютерных системах, начиная от рабочих станций и заканчивая мэйнфреймами, и стала стандартной операционной системой для высококачественных серверных систем, включая серверы баз данных.
В начале 1980-х годов были доступны четыре большие СУБД для UNIX-систем. Две из них, производства компаний Oracle и Ingres, были UNIX-версиями продуктов для мини-компьютеров компании DEC. Две другие СУБД, Informix и Unify, были созданы специально для UNIX. Вначале ни одна из них не предлагала поддержку SQL, но к 1985 году Unify ввела эту поддержку в свою СУБД, a Informix полностью переписала свою СУБД, предложив Informix-SQL с полной поддержкой SQL.
На сегодняшний день в данном сегменте рынка лидирует СУБД Oracle, доступная для всех ведущих серверных платформ UNIX. Компания Informix была приобретена IBM, которая продолжает предлагать продукты для своих собственных и чужих UNIX-систем. Серверы баз данных на базе UNIX (и все в большей степени на базе Linux) являются ведущим звеном в архитектуре «клиент/сервер» и в трехуровневой архитектуре Интернета. Требования к повышению производительности реляционных баз данных являлись одной из основных движущих сил на пути развития аппаратного обеспечения для платформы UNIX. Сюда можно отнести принятие симметричной мультипроцессорности (Symmetric Multiprocessing, SMP) в качестве базовой серверной архитектуры, разработку многоядерных микропроцессоров (что можно рассматривать как SMP на уровне микросхемы), а также использование RAID (Redundant Array of Independent Disk, избыточный массив недорогих дисков), технологии, обеспечивающей резкое повышение производительности ввода-вывода.
SQL и персональные компьютеры
С появлением первых моделей IBM PC базы данных стали приобретать популярность на рынке персональных компьютеров. СУБД dBASE компании AshtonTate была инсталлирована более чем на миллионе персональных компьютеров, работавших под управлением MS DOS. Хотя в большинстве СУБД для персональных компьютеров данные хранились в табличной форме, эти СУБД не обладали полной мощью реляционных баз данных и не поддерживали SQL. Первые СУБД для персональных компьютеров представляли собой соответствующим образом переработанные версии известных СУБД для мини-компьютеров и с трудом «умещались» на персональных компьютерах. Например, система Professional Oracle для IBM PC, анонсированная в 1984 году, требовала двух мегабайтов памяти — намного больше типичных для того времени 640 Кбайт.
С появлением в апреле 1987 года операционной системы OS/2, созданной компаниями IBM и Microsoft, начался рост популярности SQL на персональных компьютерах. Кроме стандартной версии OS/2, компания IBM выпустила собственную расширенную редакцию OS/2 (OS/2 Extended Edition, OS/2 ЕЕ) со встроенной поддержкой SQL-базы данных и коммуникаций. Сделав SQL частью операционной системы, компания IBM тем самым вновь подтвердила свою приверженность этому языку.
Появление OS/2 ЕЕ стало проблемой для компании Microsoft. Поскольку она была разработчиком стандартной OS/2 и продавала ее другим производителям персональных компьютеров, потребовалась альтернатива OS/2 ЕЕ. Ответом Microsoft стала покупка лицензии на СУБД компании Sybase, разработанной для VAX, и перенос этой СУБД в систему OS/2. В январе 1988 года Microsoft и AshtonTate (в то время — лидер рынка баз данных для персональных компьютеров со своей dBASE) неожиданно объявили, что они будут совместно продавать новую СУБД, получившую название SQL Server. Компания Microsoft станет поставлять SQL Server вместе с OS/2 производителям компьютеров, а компания Ashton-Tate займется распространением SQL Server по розничным каналам пользователям персональных компьютеров. В сентябре 1989 года компания Lotus Development (еще один член большой тройки производителей программного обеспечения для персональных компьютеров того времени) внесла свой вклад в SQL Server, сделав инвестицию в компанию Sybase. В том же году компания Ashton-Tate отказалась от исключительных прав на распространение этой СУБД и продала свою долю компании Lotus.
Хотя успех СУБД SQL Server для OS/2 был ограниченным (как, к сожалению, и успех самой весьма неплохой операционной системы), компания Microsoft в типичном для нее стиле продолжала вкладывать деньги в эту СУБД и перенесла ее на платформу Windows NT. В течение некоторого времени компании Microsoft и Sybase оставались партнерами: первая сосредоточила свои усилия на рынке персональных компьютеров, ЛВС и Windows NT, а вторая — на рынке миникомпьютеров и UNIX-серверов. Но по мере того как Windows NT и UNIX становились конкурентами в качестве платформ для серверов баз данных, взаимоотношения между компаниями начали переходить из области сотрудничества в область конкуренции. В конце концов пути компаний окончательно разошлись. Теперь они предлагают совершенно разные продукты, хотя некоторые сходные SQL- расширения (например, хранимые процедуры) выдают в них общее прошлое.
На сегодняшний день СУБД SQL Server является ведущей СУБД для серверов под управлением Windows. Новые версии этой СУБД выходят каждые два-три года, причем с большими изменениями и дополнениями в таких областях, как работа с XML, специальные данные, полнотекстовый поиск, хранилища и анализ данных и высокая доступность. В то время как на очень больших серверах баз данных доминируют UNIX и Oracle, благодаря SQL Server серверы под управлением Windows смогли занять нишу систем среднего уровня.
SQL и обработка транзакций
В процессе своего развития SQL и реляционные базы данных почти не применялись в приложениях, предназначенных для оперативной обработки транзакций (Online Transaction Processing, OLTP). Поскольку в реляционных базах данных упор делается на запросы, такие базы данных традиционно использовались в приложениях, служащих для поддержки принятия решений, и в приложениях с малым объемом транзакций, где их низкое быстродействие не было недостатком. В области оперативной обработки транзакций, когда требовалось обеспечить одновременный доступ к данным сотням пользователей и время ожидания каждого из них не должно было превышать доли секунды, доминировала нереляционная СУБД IMS (Information Management System, система управления информацией) компании IBM.
В 1986 году компания Sybase, новичок на рынке СУБД, представила реляционную СУБД, предназначенную специально для оперативной обработки транзакций. СУБД компании Sybase работала на мини-компьютерах VAX/VMS и рабочих станциях Sun и обеспечивала уровень быстродействия, необходимый для обработк и больших объемов транзакций. Вскоре вслед за этим компании Oracle Corporation и Relational Technology объявили, что также выпустят версии своих продуктов Oracle и Ingres для оперативной обработки транзакций. На рынке UNIX-систем компания Informix анонсировала OLTP-версию своей СУБД под названием Informix-Turbo.
В апреле 1988 года компания IBM присоединилась к поставщикам реляционных СУБД для OLTP, выпустив систему DB2 Version 2. Тесты показали, что на больших мэйнфреймах эта система могла обрабатывать до 250 транзакций в секунду. Компания IBM утверждала, что теперь быстродействие DB2 позволяет использовать ее во всех OLTP-приложениях, кроме наиболее требовательных к быстродействию, и поощряла клиентов устанавливать ее вместо IMS. После этого тесты OLTP стали стандартным маркетинговым инструментом для реляционных СУБД, вопреки серьезным сомнениям в том, насколько они отражают быстродействие реальных приложений.
Развитие реляционных технологий и появление более мощных компьютеров привели к тому, что роль SQL в OLTP-приложениях резко возросла, как возросли и показатели производительности СУБД. Теперь поставщики СУБД начали позиционировать свои продукты в зависимости от показателей OLTP-производительности, и на несколько лет рынок баз данных погрузился в войну тестов производительности. Независимая организация Transaction Processing Council (ТРС, совет по средствам обрабо тки транзакций) опубликовала серию собственных тестов (ТРС-А, ТРС-В и ТРС- С), чем только подогрела интерес к данной области со стороны поставщиков.
В начале 2000-х годов реляционные базы данных на базе SQL на UNIX-серверах высокого класса преодолели рубеж 1000 транзакций в секунду. Системы «клиент/сервер», включающие реляционные СУБД, стали признанной архитектурой для реализации OLTP-приложений. Таким образом, рассматриваемый ранее как «непригодный для оперативной обработки транзакций», язык SQL вырос до промышленного стандарта в области построения OLTP-приложений.
SQL и базы данных для рабочих групп
Стремительный рост популярности локальных сетей на базе персональных компьютеров в 1980-е-90-е годы создал предпосылки для распространения новой архитектуры систем управления базами данных масштаба подразделений, или «рабочих групп». Первоначально СУБД, предназначенные для этого сегмента рынка, работали под управлением операционной системы OS/2 компании IBM. Даже СУБД SQL Server, ныне играющая ключевую роль в стратегии компании Microsoft, связанной с платформой Windows, в свое время дебютировала как продукт для OS/2. В середине 90-х годов фирма Novell тоже изо всех сил старалась сделать свою сетевую операционную систему NetWare привлекательной платформой для серверов баз данных рабочих групп. На заре эры локальных сетей NetWare прочно утвердилась в качестве доминирующей операционной системы для файл/серверов и серверов печати. Объединившись с Oracle и другими разработчиками, Novell рассчитывала распространить свое лидерство и на серверы рабочих групп.
Однако появление операционной системы Windows NT, специализированной версии Windows для применения на серверах, вызвало настоящий переворот. Если в качестве файл/сервера NetWare явно превосходила NT по производительности, то NT имела более надежную и универсальную архитектуру, во многом подобную архитектуре операционных систем для мини-компьютеров. Microsoft успешно позиционировала NT как более привлекательную платформу для работы приложений рабочих групп (в качестве сервера приложений) и баз данных рабочих групп. SQL Server компании Microsoft продавался (а часто просто встраивался) с NT в качестве тесно интегрированной платформы разработки приложений для рабочих групп. Поначалу информационные отделы компаний отнеслись к этой пока еще новой и непроверенной технологии с большой осторожностью, но предложение было слишком уж заманчивым: комбинация Windows NT и SQL Server позволяла различным подразделениям разрабатывать собственные небольшие проекты, не прибегая к помощи центрального информационного отдела компании. Поэтому она не только была принята, но и стимулировала интенсивный рост всего сегмента рынка баз данных для рабочих групп.
Сегодня SQL стал общепризнанным стандартом в качестве языка работы с базами данных для рабочих групп. В дополнение к Windows, популярной платформой для серверов рабочих групп стал Linux. Большая часть рынка поделена между Microsoft SQL Server и Oracle, но в последнее время достаточно сильным (и дешевым) конкурентом для них начинает становиться база данных с открытым кодом MySQL. Еще одним участником гонки можно назвать другую базу данных с открытым кодом — Postgres, разработанную в Калифорнийском университете в Беркли.
SQL, хранилища данных и интеллектуальные ресурсы предприятия
Несколько лет усилий по внедрению технологии SQL в сферу разработки OLTP-приложений сделали свое дело, и реляционные базы данных стали цениться не только за удобство выполнения запросов и поддержку принятия решений. Тесты производительности и отчаянное соперничество между ведущими СУБД переместились в область простых транзакций, таких как добавление новых заказов в базу данных или определение баланса счетов клиента. Благодаря мощи реляционной модели те же базы данных, которые используются для выполнения текущих деловых операций, могут служить и для анализа растущих объемов накапливаемых данных. На профессиональных конференциях менеджеров информационных служб предприятий часто можно было услышать о том, что накопленные деловые данные (разумеется, хранящиеся в реляционных базах данных) должны рассматриваться как один из ценнейших активов предприятия и служить повышению эффективности принятия деловых решений.
Хотя теоретически реляционные базы данных без труда можно использовать и для оперативной обработки транзакций, и для поддержки принятия решений, на практике возникает ряд очень важных проблем. Рабочая нагрузка OLTP-систем состоит из множества коротких транзакций, выполняемых с большой частотой, причем важным фактором является малое время реакции системы. В противоположность этому запросы, связанные с принятием решений (например, «Какова средняя стоимость заказов для данного региона?» или «Насколько увеличился сбыт продукции по сравнению с аналогичным периодом прошлого года?»), могут требовать сканирования огромных таблиц и выполняться минутами или даже часами. Если экономист-аналитик попытается выполнить подобный запрос во время пика деловых транзакций, это может вызвать серьезное снижение производительности всей системы, что для оперативной обработки транзакций просто недопустимо. Еще одну проблему составляет размещение данных, необходимых для получения ответов на вопросы из области делового анализа: они могут быть распределены между многими базами данных, причем, как правило, еще и поддерживаемыми разными СУБД и на разных компьютерных платформах.
Необходимость в полноценном использовании информационного потенциала предприятия, т.е. накопленных им данных, а также практические проблемы, связанные с производительностью OLTP-систем, породили новое технологическое решение, получившее название «хранилище данных» (data warehouses). Идею хранилища данных иллюстрирует схема на рис. 6. Бизнес-данные извлекаются из OLTP- систем предприятия, форматируются, проверяются и помещаются в отдельную базу данных, предназначенную исключительно для делового анализа («хранилище»). Извлечение и форматирование данных можно выполнять на периодической основе в пакетном режиме во время наименьшей загрузки системы. В идеале из транзакционных баз данных извлекаются только новые и измененные данные, что позволяет сократить общее количество данных, обрабатываемых во время ежемесячной, еженедельной или ежедневной операции обновления хранилища. Таким образом, длительные запросы, связанные с деловым анализом, адресуются только к хранилищу данных и не требуют участия систем оперативной обработки транзакций.
Рис. 6. Концепция хранилищ данных
Благодаря своей гибкости в обработке запросов, реляционные СУБД идеально подходили для организации хранилищ данных. Появились новые компании, взявшиеся за разработку программных средств для извлечения данных из OLTP- систем, их преобразования, загрузки в хранилище и последующего выполнения запросов к хранилищу. Не тратили времени зря и производители СУБД, сконцентрировавшие свое внимание на типичных запросах делового анализа. Эти запросы, как правило, бывают большими и сложными, как, например, анализ десятков или сотен миллионов отдельных операций оплаты товара для выявления наиболее распространенных схем оплаты, и часто связаны с обработкой хронологических данных — скажем, анализ ежемесячного изменения объема продаж или доли компании в своем сегменте рынка. Кроме того, в таких запросах чаще всего фигурируют статистические результаты — суммарный объем продаж, средняя стоимость заказов, процент роста и т.п., а не отдельные элементы данных.
Для удовлетворения специфических потребностей приложений, работающих с хранилищами данных и часто называемых приложениями для оперативной аналитической обработки данных (Online Analytical Processing, OLAP), стали появляться специализированные СУБД. Их производительность оптимизирована для выполнения сложных запросов, связанных только с чтением данных. Они поддерживают расширенный набор статистических функций и имеют встроенные средства для других распространенных типов анализа данных, например хронологического. За счет заблаговременного вычисления статистических данных эти СУБД могут существенно ускорять получение средних и суммарных величин. Среди специализированных СУБД есть некоторое количество таких, которые не используют язык SQL, но большинство использует именно его, благодаря чему получил распространение еще один сопутствующий термин — реляционная оперативная аналитическая обработка данных (Relational Online Analytical Processing, ROLAP).
Эволюция рынка хранилищ данных привела к тому, что новым важным сегментом рынка стали инструменты для работы с хранилищами, часто именуемые интеллектуальными ресурсами (business intelligence). Три ведущие компании в этой области достигли немалого успеха на рынке до того, как были куплены промышленными гигантами. Компания Business Objects была приобретена SAP, ведущим производителем приложений уровня предприятия. Компания Hyperion досталась Oracle, a Cognos — IBM. Как и во многих других сегментах рынка, достоинства SQL в качестве стандарта сделали его важным фактором развития и обеспечили закрепление на рынке SQL-хранилищ данных и аналитического инструментария.
SQL и интернет-приложения
В конце 1990-х годов основной движущей силой развития Интернета стал Веб. Первоначально Веб использовался для распространения информации в форме текста и графики и практически не применялся в области управления данными. Однако в средине 1990-х годов большая часть содержимого на корпоративных вебсайтах была из корпоративных SQL-баз данных. Например, на коммерческом вебсайте страницы содержат информацию о товарах, ценах, доступности товара на складе, специальных предложениях и т.п., причем обычно такие страницы создаются по запросу, на основе данных, выбранных из SQL-базы данных. Подавляющее большинство страниц на сайтах аукционов или туристических агентств также основано на информации из SQL-баз данных, преобразованной в формат HTML- страниц. Осуществляется поток информации и в другом направлении, когда введенные пользователем данные в формы на веб-страницах вносятся в SQL-базы данных, являющиеся частью архитектуры веб-сайта.
В начале 2000-х годов технологии Интернета стали применяться для соединения компьютерных приложений друг с другом. Такие архитектуры распределенных приложений получили широкое распространение под общим названием вебслужб (web services). В соответствии с давними неписаными правилами компьютерной индустрии, появление новой технологии сопровождается появлением двух лагерей с различными стандартами и языками для их реализации. В данном случае это лагерь, возглавляемый Microsoft под флагом .NET Framework, и лагерь сторонников Java и J2EE-cepверов приложений. Обе архитектуры признают ключевую роль XML, стандарта обмена структурированными данными наподобие тех, что находятся в SQL-базах данных.
В ответ на поворот к веб-службам масса продуктов анонсировала поддержку XML в SQL-базах данных. Разработчики баз данных объявили о выпуске новых продуктов с поддержкой XML, доказывая, что именно в их базе данных идеально реализована встроенная возможность обмена данными в XML-формате через Интернет. На это откликнулись известные производители реляционных баз данных, добавляя в свои продукты возможность ввода-вывода в формате XML и соответствующие типы данных. Тесная интеграция XML и SQL остается областью активных исследований всех основных производителей баз данных.
Подход Интернета к масштабируемости также оказывает большое влияние на программное обеспечение баз данных. Многие элементы программного обеспечения в Интернете используют горизонтальное масштабирование, когда рабочая нагрузка распределяется между десятками или сотнями недорогих серверов. Поисковый механизм Google может служить одним из наиболее выдающихся примеров такой архитектуры, когда даже один простой запрос может быть распределен между десятками серверов, а общий объем поиска — десятки тысяч серверов в Интернете. Имеется масса трудностей при применении такого подхода к управлению базами данных, и в настоящее время в этой области ведутся активные исследовательские работы.
Заключение
В этой статье было описано развитие SQL и его роль в качестве стандартного языка управления реляционными базами данных.
- SQL был разработан научными сотрудниками компании IBM, и поддержка языка со стороны IBM является главной составляющей его успеха.
- Существуют официальные стандарты SQL, утвержденные ANSI/ISO, которые существенно выросли как по сложности, так и по количеству охватываемых тем со времени первой версии 1986 года.
- Вопреки наличию стандартов, имеется множество коммерческих диалектов SQL. Ни один из них не соответствует в точности другому.
- SQL стал стандартным языком управления базами данных в широком диапазоне компьютерных систем и приложений, включая мэйнфреймы, рабочие станции, персональные компьютеры, системы оперативной обработки транзакций, системы «клиент/сервер», хранилища данных и Интернет.
Stack Overflow назвал самые любимые и популярные языки у разработчиков за 2023 год
Stack Overflow опубликовал свежие результаты ежегодного опроса Developer Survey. В 2023 году в нём приняло участие более 90 тысяч разработчиков.
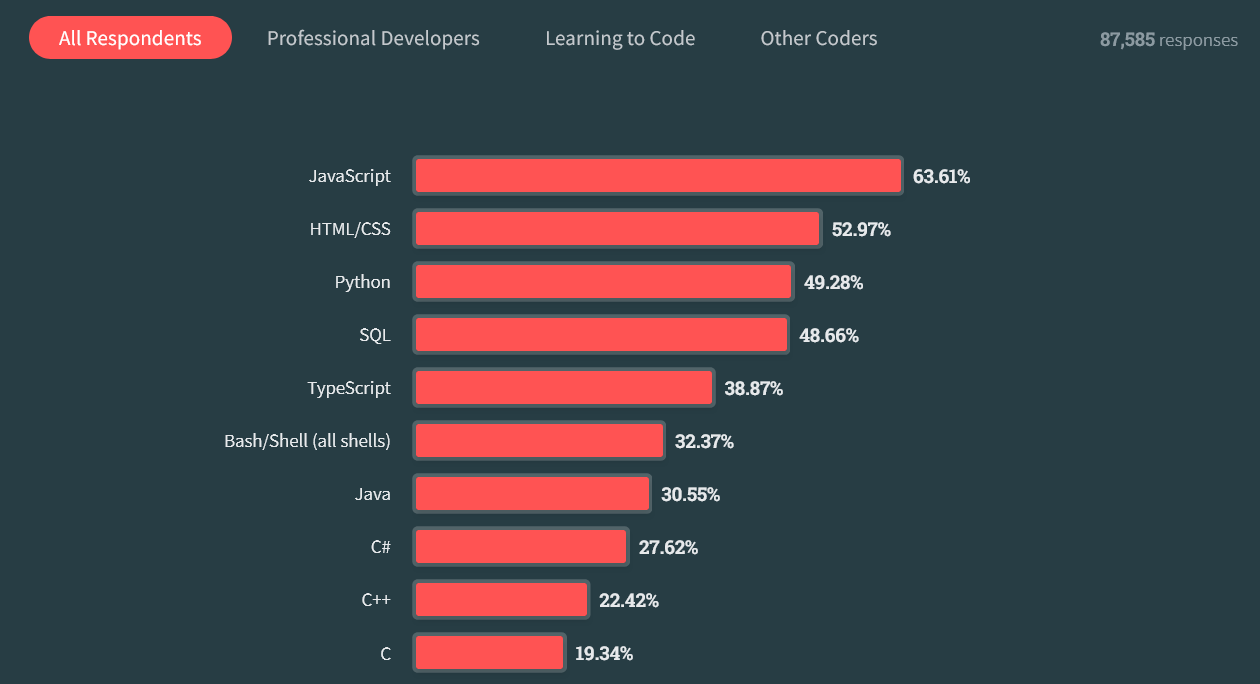
В этом году исследователи несколько изменили способ отображения языков, с которым разработчикам нравится работать больше всего. На новой визуализации на одну шкалу нанесён процент тех, кто хотел бы использовать тот или иной язык, и тех, кто уже использует его и планирует делать это в дальнейшем.
Так, самый популярный язык JavaScript хотят использовать 40,15% разработчиков, а уже используют и хотят продолжать — 57,83%. Rust хотят использовать и дальше 84,66% разработчиков — он лидирует по этому показателю и становился «любимым» 7 предыдущих раз подряд. Также среди любимчиков — TypeScript, Elixir, Zig, Closure и Raku. Меньше всего разработчикам импонирует MATLAB: продолжать использовать его желают лишь 18,33% текущих пользователей.
Самым высокооплачиваемым языком стал Zig, прошлогодний победитель Clojure «подешевел» на 10%. Больше всего медианная зарплата увеличилась по Dart и SAS — более чем на 20% по сравнению с 2022 годом.

Самая распространенная облачная платформа — Amazon Web Services (49%), на втором месте — Microsoft Azure (26%), на третьем — Google Cloud (24%).
Также в докладе появился новый раздел, посвященный ИИ. Около 70% респондентов уже используют или в ближайшем времени планируют применять искусственный интеллект в работе. 77% одобряют использование ИИ в разработке. Среди основных преимуществ ИИ-инструментов они называют повышение производительности, скорости обучения и эффективности. В основном они задействуются при написании (83%) и отладке кода (49%). При этом полностью доверяют им лишь 3% опрошенных, склонны больше доверять, чем нет, ещё 39%. Рейтинги самых популярных и любимых инструментов поиска на базе ИИ с огромным отрывом возглавляет ChatGPT.

Полную версию исследования можно посмотреть по ссылке.