Оконные функции
Функции, которые работают с группой строк, называемой окном, и вычисляют возвращаемое значение для каждой строки на основе группы строк. Оконные функции полезны для обработки таких задач, как вычисление скользящего среднего, вычисление совокупной статистики или доступ к значению строк с учетом относительного положения текущей строки.
Синтаксис
function OVER < window_name | ( window_name ) | window_spec >function < ranking_function | analytic_function | aggregate_function >over_clause OVER < window_name | ( window_name ) | window_spec >window_spec ( [ PARTITION BY partition [ , . ] ] [ order_by ] [ window_frame ] ) Параметры
- Функции Функция, работающая в окне. Различные классы функций поддерживают разные конфигурации спецификаций окон.
- ranking_function Любая функция окна ранжирования. Если этот window_spec должен содержать предложение ORDER BY, но не предложение window_frame.
- analytic_function Любая функция окна Аналитика.
- aggregate_function Любая из агрегатных функций. Если указано, функция не должна включать предложение FILTER.
- Раздел Одно или несколько выражений, используемых для указания группы строк, определяющих область, с которым работает функция. Если предложение PARTITION не указано, секция состоит из всех строк.
- order_by Предложение ORDER BY задает порядок строк в секции.
- window_frame Предложение рамки окна указывает скользящее подмножество строк в секции, с которой работает агрегатная или аналитическая функция.
Вы можете указать SORT BY в качестве псевдонима для ORDER BY.
Вы также можете указать DISTRIBUTE BY в качестве псевдонима для PARTITION BY. При отсутствии ORDER BY можно использовать CLUSTER BY в качестве псевдонима для PARTITION BY.
Примеры
> CREATE TABLE employees (name STRING, dept STRING, salary INT, age INT); > INSERT INTO employees VALUES ('Lisa', 'Sales', 10000, 35), ('Evan', 'Sales', 32000, 38), ('Fred', 'Engineering', 21000, 28), ('Alex', 'Sales', 30000, 33), ('Tom', 'Engineering', 23000, 33), ('Jane', 'Marketing', 29000, 28), ('Jeff', 'Marketing', 35000, 38), ('Paul', 'Engineering', 29000, 23), ('Chloe', 'Engineering', 23000, 25); > SELECT name, dept, salary, age FROM employees; Chloe Engineering 23000 25 Fred Engineering 21000 28 Paul Engineering 29000 23 Helen Marketing 29000 40 Tom Engineering 23000 33 Jane Marketing 29000 28 Jeff Marketing 35000 38 Evan Sales 32000 38 Lisa Sales 10000 35 Alex Sales 30000 33 > SELECT name, dept, RANK() OVER (PARTITION BY dept ORDER BY salary) AS rank FROM employees; Lisa Sales 10000 1 Alex Sales 30000 2 Evan Sales 32000 3 Fred Engineering 21000 1 Tom Engineering 23000 2 Chloe Engineering 23000 2 Paul Engineering 29000 4 Helen Marketing 29000 1 Jane Marketing 29000 1 Jeff Marketing 35000 3 > SELECT name, dept, DENSE_RANK() OVER (PARTITION BY dept ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS dense_rank FROM employees; Lisa Sales 10000 1 Alex Sales 30000 2 Evan Sales 32000 3 Fred Engineering 21000 1 Tom Engineering 23000 2 Chloe Engineering 23000 2 Paul Engineering 29000 3 Helen Marketing 29000 1 Jane Marketing 29000 1 Jeff Marketing 35000 2 > SELECT name, dept, age, CUME_DIST() OVER (PARTITION BY dept ORDER BY age RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cume_dist FROM employees; Alex Sales 33 0.3333333333333333 Lisa Sales 35 0.6666666666666666 Evan Sales 38 1.0 Paul Engineering 23 0.25 Chloe Engineering 25 0.50 Fred Engineering 28 0.75 Tom Engineering 33 1.0 Jane Marketing 28 0.3333333333333333 Jeff Marketing 38 0.6666666666666666 Helen Marketing 40 1.0 > SELECT name, dept, salary, MIN(salary) OVER (PARTITION BY dept ORDER BY salary) AS min FROM employees; Lisa Sales 10000 10000 Alex Sales 30000 10000 Evan Sales 32000 10000 Helen Marketing 29000 29000 Jane Marketing 29000 29000 Jeff Marketing 35000 29000 Fred Engineering 21000 21000 Tom Engineering 23000 21000 Chloe Engineering 23000 21000 Paul Engineering 29000 21000 > SELECT name, salary, LAG(salary) OVER (PARTITION BY dept ORDER BY salary) AS lag, LEAD(salary, 1, 0) OVER (PARTITION BY dept ORDER BY salary) AS lead FROM employees; Lisa Sales 10000 NULL 30000 Alex Sales 30000 10000 32000 Evan Sales 32000 30000 0 Fred Engineering 21000 NULL 23000 Chloe Engineering 23000 21000 23000 Tom Engineering 23000 23000 29000 Paul Engineering 29000 23000 0 Helen Marketing 29000 NULL 29000 Jane Marketing 29000 29000 35000 Jeff Marketing 35000 29000 0Связанные статьи
- ВЫБЕРИТЕ
- ORDER BY
- предложение window frame
- именованное окно
- Запроса
- Агрегатные функции
- Функции окна аналитики
- Функции окна ранжирования
SQL-Ex blog

Эта статья является руководством по использованию оконных функций SQL в приложениях, для которых требуется выполнять тяжелые вычислительные запросы. Данные множатся с поразительной скоростью. В 2022 в мире произведено и потреблено 94 зетабайтов данных. Сегодня у нас есть множество инструментов типа Hive и Spark для обработки Big Data. Несмотря на то, что эти инструменты различаются по типам проблем, для решения которых они спроектированы, они используют базовый SQL, что облегчает работу с большими данными. Оконные функции являются примером одной из таких концепций SQL. Это необходимо знать инженерам-программистам и специалистам по данным.
Оконные функции SQL являются мощным инструментом, который позволяет пользователям выполнять вычисления для множества строк, или «окна», в рамках запроса. Эти функции предоставляют удобный способ сложных вычислений при простом декларативном синтаксисе и могут использоваться для решения широкого диапазона проблем.
Документация PostgreSQL дает хорошее введение в эту концепцию:
Оконная функция выполняет вычисления по множеству строк таблицы, которые некоторым образом связаны с текущей строкой. Это похоже по типу с вычислениями, которые могут выполняться с помощью агрегатных функций. Но, в отличие от обычных агрегатных функций, использование оконных функций не вызывает группировку строк в единственную выходную строку — строки сохраняют свою отдельную идентичность. За кулисами оконная функция может получить доступ не только к текущей строке результата запроса.
Сравнение оконных и агрегатных функций
- AVG() — возвращает среднее значений указанного столбца.
- SUM() — возвращает сумму всех значений.
- MAX(), MIN() — возвращают максимальное и минимальное значения.
- COUNT() — возвращает общее число значений
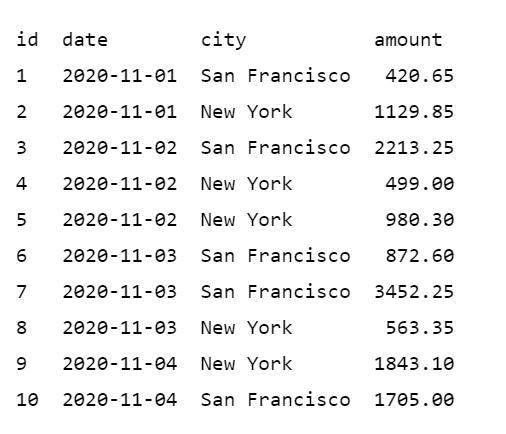
Мы хотим рассчитать среднюю величину транзакций по дням для каждого города. Чтобы это посчитать, нам нужно сгруппировать данные по дате и городу.
SELECT date, city, AVG(amount) AS avg_transaction_amount_for_city
FROM transactions
GROUP BY date, city;
Результат этого запроса показан ниже.
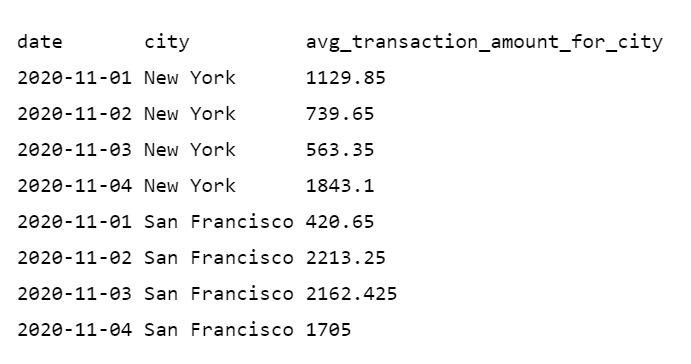
Агрегатная функция AVG() и GROUP BY дают нам среднее значение, сгруппированное по дате и городу. Если посмотреть на строки за 2-е ноября, то мы имеем две транзакции в New York, а 3-го ноября — две транзакции в San Francisco. В результирующем наборе отдельные строки свернуты в единственную строку, представляющую агрегатные значения для каждой группы.
Оконные функции, как и агрегатные функции, работают с множеством строк, называемым рамкой окна. В отличие от агрегатных функций, оконные функции возвращают единственное значение для каждой строки рассматриваемого запроса. Окно определяется с использованием предложения OVER(). Оно позволяет задать окно на основе конкретного столбца, подобно GROUP BY в случае агрегатных функций. Вы можете использовать агрегатные функции с оконными функциями, но вам нужно будет использовать их с предложением OVER().
Давайте поясним это на примере, использующем данные транзакций, приведенные выше. Мы хотим добавить столбец со средним значением ежедневных транзакций для каждого города. Оконная функция ниже дает нам требуемый результат.
SELECT id, date, city, amount,
AVG(amount) OVER (PARTITION BY date, city) AS avg_daily_transaction_amount_for_city
FROM transactions
ORDER BY id;
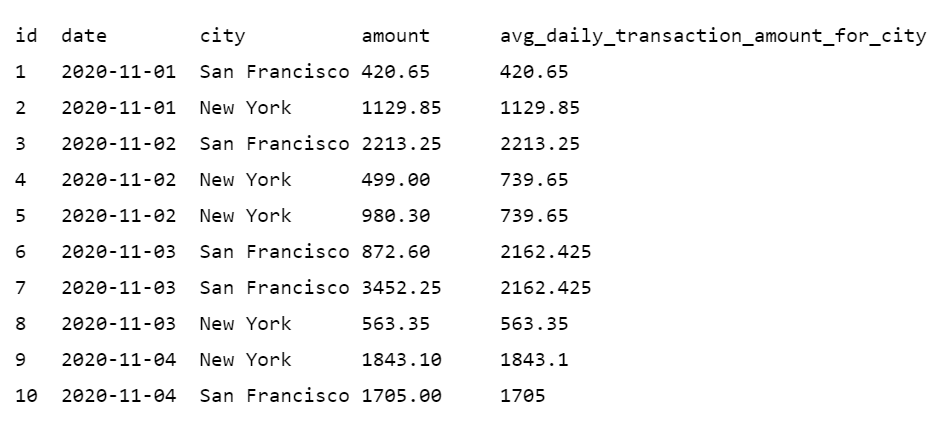
Результат:
Обратите внимание, что строки не сворачиваются. Присутствует по одной строке на каждую транзакцию и вычисленные средние значения в avg_daily_transaction_amount_for_city.
На диаграмме ниже показана разница между агрегатными и оконными функциями.
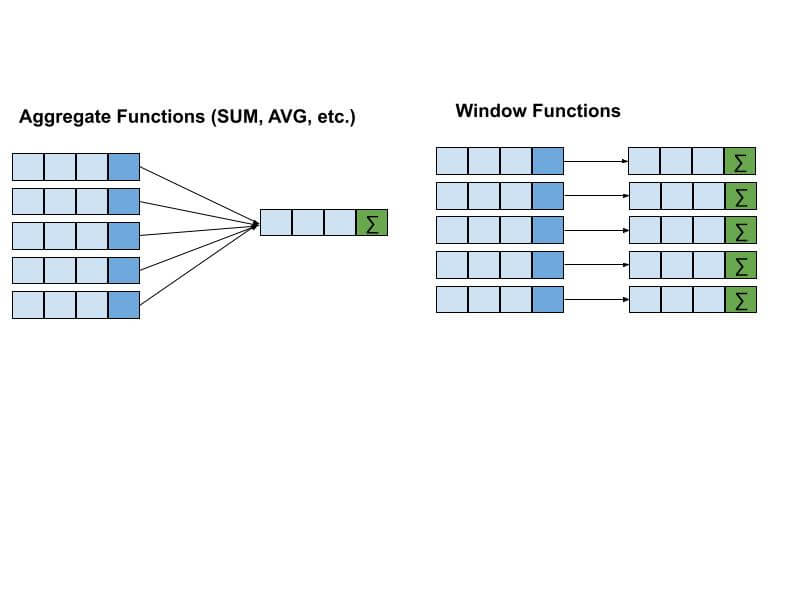
Сходство и различие между оконными и агрегатными функциями
- Работают с множеством строк
- Вычисляют агрегатные величины
- Группируют или секционируют данные по одному или нескольким столбцам
- Использование GROUP BY для определения множества строк для агрегации
- Группировка строк на основе значений столбца
- Сворачивание строк в единственную строку для каждой определенной группы
- Использование OVER() вместо GROUP BY для определения множества строк
- Использование большего числа функций в дополнение к агрегатным, например: RANK(), LAG(), LEAD()
- Могут группировать строки по их рангу, процентилю и т.д. в дополнение к значениям столбца
- Не сворачивают строки в единственную строку на группу
- Могут использовать скользящую рамку окна на основе текущей строки
Зачем использовать оконные функции?
Главное преимущество оконных функций состоит в том, что они позволяют работать как с агрегатными, так и неагрегатными значениями одновременно, поскольку строки не сворачиваются. Они также позволяют решить проблемы производительности. Например, вы можете использовать оконную функцию вместо выполнения самосоединения или декартова произведения.
Синтаксис оконной функции
Давайте пройдемся по синтаксису оконных функций на нескольких примерах. Мы будем использовать тот же, что и выше, набор данных, который я продублировал ниже.
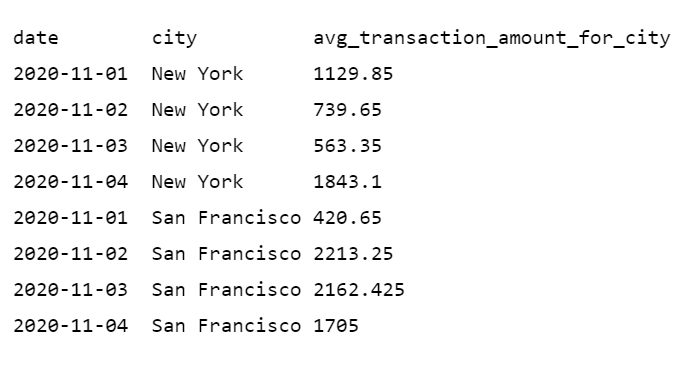
Мы хотим вычислить накопительные итоги транзакций за каждый день в каждом городе. Запрос ниже делает это.
SELECT id, city,
date,
SUM(amount) OVER
(PARTITION BY city ORDER BY date)
AS running_total
FROM transactions
Первая часть агрегата выше, SUM(amount), выглядит подобно любой другой агрегации. Добавление OVER означает, что это оконная функция. PARTITION BY сужает окно со всего набора данных до отдельных групп в рамках этого набора данных. Вышеприведенный запрос группирует данные по городу (city) и упорядочивает их по дате (date). Внутри каждой группы города данные упорядочиваются по дате и накопительные итоги суммируются от текущей строки и всех предыдущих строк группы. При изменении значения города можно заметить, что значение накопительных итогов (running_total) начинается заново для этого города. Вот результаты этого запроса:
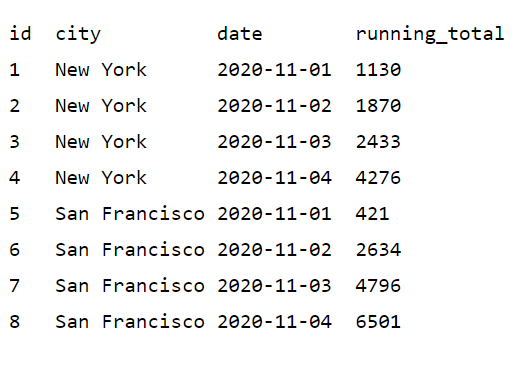
ORDER BY и PARTITION BY определяют то, что является окном — упорядоченный набор данных над которым выполняются вычисления.
Типы оконных функций
- Агрегатные функции: Эти функции вычисляют единственное значение для множества строк
- SUM(), MAX(), MIN(), AVG(), COUNT()
- RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
- LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE()
- FIRST_VALUE() and LAST_VALUE().
Еще примеры использования оконных функций
Одно из главных преимуществ использования оконных функций SQL состоит в том, что они позволяют пользователям выполнять сложные вычисления без использования подзапросов или соединения множества таблиц. Это делает запросы более лаконичными и эффективными, и может улучшить производительность базы данных.
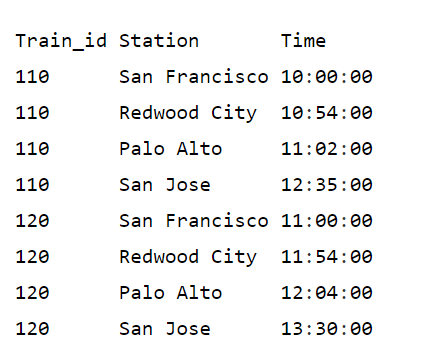
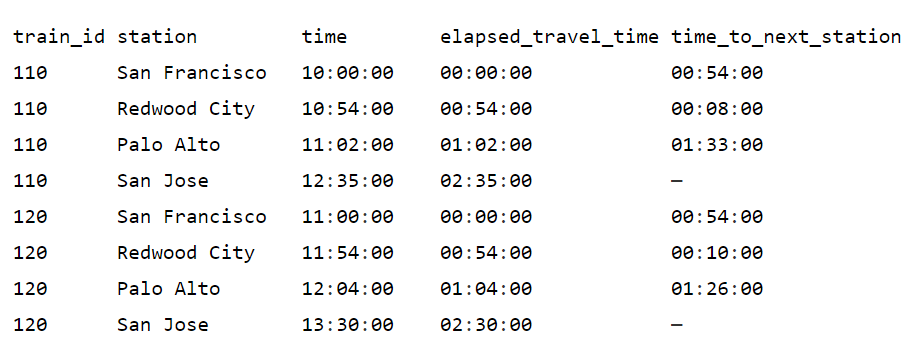
Рассмотрим несколько примеров. Таблица ниже, которая называется train_schedule содержит train_id, станцию (station) и время (time) прибытия поездов в районе залива Сан-Франциско. Нам нужно вычислить время до следующей станции для каждого поезда в расписании.
Это можно вычислить как разность времен прибытия для каждой пары соседних станций для каждого поезда. Вычисление без использования оконных функций может оказаться более сложным. Большинство разработчиков считывали бы таблицу в память и использовали логику приложения для вычисления значений. Оконная функция LEAD здорово упрощает эту задачу.
SELECT
train_id,
station,
time as "station_time",
lead(time) OVER (PARTITION BY train_id ORDER BY time) - time
AS time_to_next_station
FROM train_schedule
ORDER BY 1 , 3;Мы создаем наше окно СЕКЦИОНИРОВАНИЕМ по train_id и сортируя секцию по time (времени прибытия на станцию). Оконная функция LEAD() получает значение столбца из следующей строки в окне. Мы вычисляем время до следующей станции вычитанием из времени, полученного посредством оконной функции LEAD, времени из столбца time текущей строки. Результаты показаны ниже.
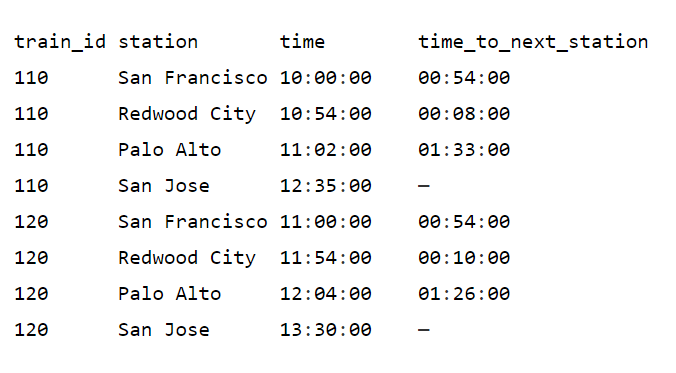
Опираясь на предыдущий пример, представим, что нам нужно вычислить полное время поездки до текущей станции. Вы можете использовать оконную функцию MIN() для получения времени отправления для каждого окна и вычесть его из текущего времени прибытия на станцию для каждой строки в окне.
SELECT
train_id,
station,
time as "station_time",
time - min(time) OVER (PARTITION BY train_id ORDER BY time)
AS elapsed_travel_time,
lead(time) OVER (PARTITION BY train_id ORDER BY time) - time
AS time_to_next_station
FROM train_schedule;Наше окно не изменилось. Мы по-прежнему выполняем разбиение по train_id и упорядочиваем окно по времени прибытия на станцию. Изменились только вычисления, которые мы выполняем для каждой строки в окне. В запросе выше мы вычитаем из времени текущей строки самое раннее время в окне, которое имеет место, когда поезд отходит от первой станции. Это дает нам время поездки для каждой станции по ходу поезда.
В заключение скажем, что оконные функции SQL предоставляют удобный и эффективный способ выполнения вычислений на множестве строк, возвращаемых запросом. Эти функции могут использоваться для решения многих задач в области анализа и манипуляции данными, а также улучшить производительность базы данных.
Ссылки по теме
1. Накопительные итоги3.5. Оконные функции
Оконная функция выполняет вычисления для набора строк, некоторым образом связанных с текущей строкой. Можно сравнить её с агрегатной функцией, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. Внутри же, оконная функция, как и агрегатная, может обращаться не только к текущей строке результата запроса.
Вот пример, показывающий, как сравнить зарплату каждого сотрудника со средней зарплатой его отдела:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
depname | empno | salary | avg -----------+-------+--------+----------------------- develop | 11 | 5200 | 5020.0000000000000000 develop | 7 | 4200 | 5020.0000000000000000 develop | 9 | 4500 | 5020.0000000000000000 develop | 8 | 6000 | 5020.0000000000000000 develop | 10 | 5200 | 5020.0000000000000000 personnel | 5 | 3500 | 3700.0000000000000000 personnel | 2 | 3900 | 3700.0000000000000000 sales | 3 | 4800 | 4866.6666666666666667 sales | 1 | 5000 | 4866.6666666666666667 sales | 4 | 4800 | 4866.6666666666666667 (10 rows)
Первые три колонки извлекаются непосредственно из таблицы empsalary, при этом для каждой строки таблицы есть строка результата. В четвёртой колонке оказалось среднее значение, вычисленное по всем строкам, имеющим то же значение depname, что и текущая строка. (Фактически среднее вычисляет та же функция avg , которую мы знаем как агрегатную, но предложение OVER превращает её в оконную, так что она обрабатывает лишь заданный набор строк.)
Вызов оконной функции всегда содержит предложение OVER, следующее за названием и аргументами оконной функции. Это синтаксически отличает её от обычной или агрегатной функции. Предложение OVER определяет, как именно нужно разделить строки запроса для обработки оконной функцией. Предложение PARTITION BY, дополняющее OVER, указывает, что строки нужно разделить по группам или разделам, объединяя одинаковые значения выражений PARTITION BY. Оконная функция вычисляется по строкам, попадающим в один раздел с текущей строкой.
Вы можете также определять порядок, в котором строки будут обрабатываться оконными функциями, используя ORDER BY в OVER. (Порядок ORDER BY для окна может даже не совпадать с порядком, в котором выводятся строки.) Например:
SELECT depname, empno, salary, rank() OVER (PARTITION BY depname ORDER BY salary DESC) FROM empsalary;
depname | empno | salary | rank -----------+-------+--------+------ develop | 8 | 6000 | 1 develop | 10 | 5200 | 2 develop | 11 | 5200 | 2 develop | 9 | 4500 | 4 develop | 7 | 4200 | 5 personnel | 2 | 3900 | 1 personnel | 5 | 3500 | 2 sales | 1 | 5000 | 1 sales | 4 | 4800 | 2 sales | 3 | 4800 | 2 (10 rows)
Как показано здесь, функция rank выдаёт порядковый номер в разделе текущей строки для каждого уникального значения, по которому выполняет сортировку предложение ORDER BY. У функции rank нет параметров, так как её поведение полностью определяется предложением OVER.
Строки, обрабатываемые оконной функцией, представляют собой «виртуальные таблицы» , созданные из предложения FROM и затем прошедшие через фильтрацию и группировку WHERE и GROUP BY и, возможно, условие HAVING. Например, строка, отфильтрованная из-за нарушения условия WHERE, не будет видна для оконных функций. Запрос может содержать несколько оконных функций, разделяющих данные по-разному с помощью разных предложений OVER, но все они будут обрабатывать один и тот же набор строк этой виртуальной таблицы.
Мы уже видели, что ORDER BY можно опустить, если порядок строк не важен. Также возможно опустить PARTITION BY, в этом случае будет только один раздел, содержащий все строки.
Есть ещё одно важное понятие, связанное с оконными функциями: для каждой строки существует набор строк в её разделе, называемый рамкой окна. По умолчанию, с указанием ORDER BY рамка состоит из всех строк от начала раздела до текущей строки и строк, равных текущей по значению выражения ORDER BY. Без ORDER BY рамка по умолчанию состоит из всех строк раздела. [1] Посмотрите на пример использования sum :
SELECT salary, sum(salary) OVER () FROM empsalary;
salary | sum --------+------- 5200 | 47100 5000 | 47100 3500 | 47100 4800 | 47100 3900 | 47100 4200 | 47100 4500 | 47100 4800 | 47100 6000 | 47100 5200 | 47100 (10 rows)
Так как в этом примере нет указания ORDER BY в предложении OVER, рамка окна содержит все строки раздела, а он, в свою очередь, без предложения PARTITION BY включает все строки таблицы; другими словами, сумма вычисляется по всей таблице и мы получаем один результат для каждой строки результата. Но если мы добавим ORDER BY, мы получим совсем другие результаты:
SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
salary | sum --------+------- 3500 | 3500 3900 | 7400 4200 | 11600 4500 | 16100 4800 | 25700 4800 | 25700 5000 | 30700 5200 | 41100 5200 | 41100 6000 | 47100 (10 rows)
Здесь в сумме накапливаются зарплаты от первой (самой низкой) до текущей, включая повторяющиеся текущие значения (обратите внимание на результат в строках с одинаковой зарплатой).
Оконные функции разрешается использовать в запросе только в списке SELECT и предложении ORDER BY. Во всех остальных предложениях, включая GROUP BY, HAVING и WHERE, они запрещены. Это объясняется тем, что логически они выполняются после обычных агрегатных функций, а значит агрегатную функцию можно вызвать из оконной, но не наоборот.
Если вам нужно отфильтровать или сгруппировать строки после вычисления оконных функций, вы можете использовать вложенный запрос. Например:
SELECT depname, empno, salary, enroll_date FROM (SELECT depname, empno, salary, enroll_date, rank() OVER (PARTITION BY depname ORDER BY salary DESC, empno) AS pos FROM empsalary ) AS ss WHERE pos < 3;
Данный запрос покажет только те строки внутреннего запроса, у которых rank (порядковый номер) меньше 3.
Когда в запросе вычисляются несколько оконных функций для одинаково определённых окон, конечно можно написать для каждой из них отдельное предложение OVER, но при этом оно будет дублироваться, что неизбежно будет провоцировать ошибки. Поэтому лучше определение окна выделить в предложение WINDOW, а затем ссылаться на него в OVER. Например:
SELECT sum(salary) OVER w, avg(salary) OVER w FROM empsalary WINDOW w AS (PARTITION BY depname ORDER BY salary DESC);
Подробнее об оконных функциях можно узнать в Подразделе 4.2.8, Разделе 9.21, Подразделе 7.2.4 и в справке SELECT.
Примечания
Пред. Начало След. Транзакции Уровень выше Наследование Оконные функции SQL

2 Май 2020 , Data engineering, 85896 просмотров, Introduction to Window Functions in SQL
Оконные функции SQL это, пожалуй, самая мистическая часть SQL для многих веб-разработчиков. Нередко встретишь и тех, кто и вовсе никогда о них не слышал. Да что греха таить, я сам продолжительное время не знал об их существовании, решая задачи далеко не самым оптимальным способом.
Оконные функции это функции применяемые к набору строк так или иначе связанных с текущей строкой. Наверняка всем известны классические агрегатные функции вроде AVG , SUM , COUNT , используемые при группировке данных. В результате группировки количество строк уменьшается, оконные функции напротив никак не влияют на количество строк в результате их применения, оно остаётся прежним.
Привычные нам агрегатные функции также могут быть использованы в качестве оконных функций, нужно лишь добавить выражение определения "окна". Область применения оконных функций чаще всего связана с аналитическими запросами, анализом данных.
Из чего состоит оконная функция
() OVER ( )Лучше всего понять как работают оконные функции на практике. Представим, что у нас есть таблица с зарплатами сотрудников по департаментам. Вот как она выглядит:
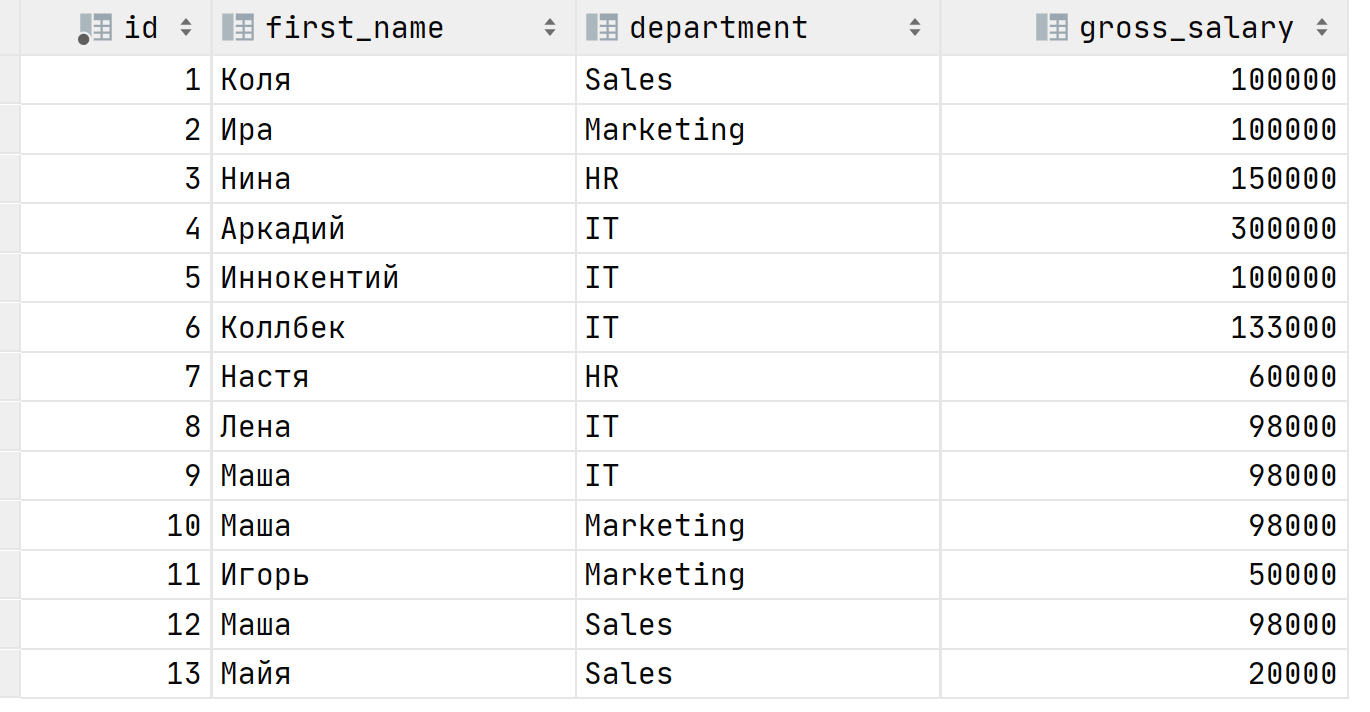
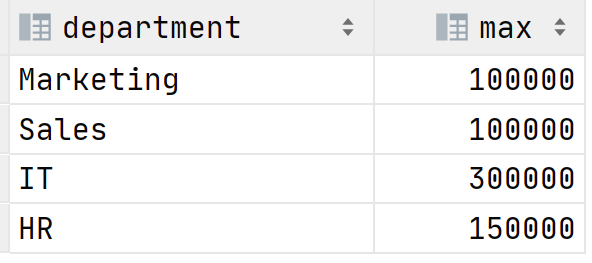
В связи с пандемией коронавируса необходимо оптимизировать расходы путем сокращения сотрудников или понижения их зарплат. Ваш вечнонедовольный директор приходит к вам с просьбой выяснить кто получает больше всего в каждом департаменте. Как поступить? Можно использовать агрегатные функции, в нашем случае MAX , чтобы выяснить максимальную зарплату в каждом отделе:
SELECT department, MAX(gross_salary) as max_salary FROM Salary GROUP BY 1;Результат выполнения запроса:
Чтобы узнать кто эти "счастливчики" на сокращение можно выделить запрос в подзапрос и объединить с исходной таблицей путём JOIN:
SELECT id, first_name, department, t.gross_salary FROM Salary JOIN ( SELECT department, MAX(gross_salary) as gross_salary FROM Salary GROUP BY 1 ) t USING(gross_salary, department);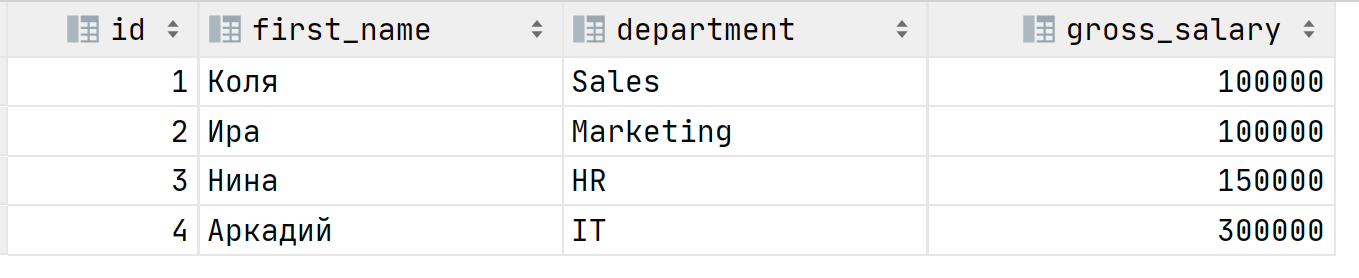
Но тут вы вспоминаете, что эту же задачу можно решить, используя оконные функции, которые вы проходили на одной из лекций по SQL в универе в бородатом году. Как? Используя всё ту же агрегатную функцию MAX , задав "окно". Окном в нашем случае будут сотрудники одного департамента (строки с одинаковым значением в колонке department).
SELECT id, first_name, department, gross_salary, MAX(gross_salary) OVER (PARTITION BY department) as max_gross_salary FROM Salary;Окно задаётся через выражение OVER (PARTITION BY ), т.е. строки мы как бы группируем по признаку в указанных колонках, конкретно в этом случае по признаку принадлежности к департаменту в компании. Результат запроса:
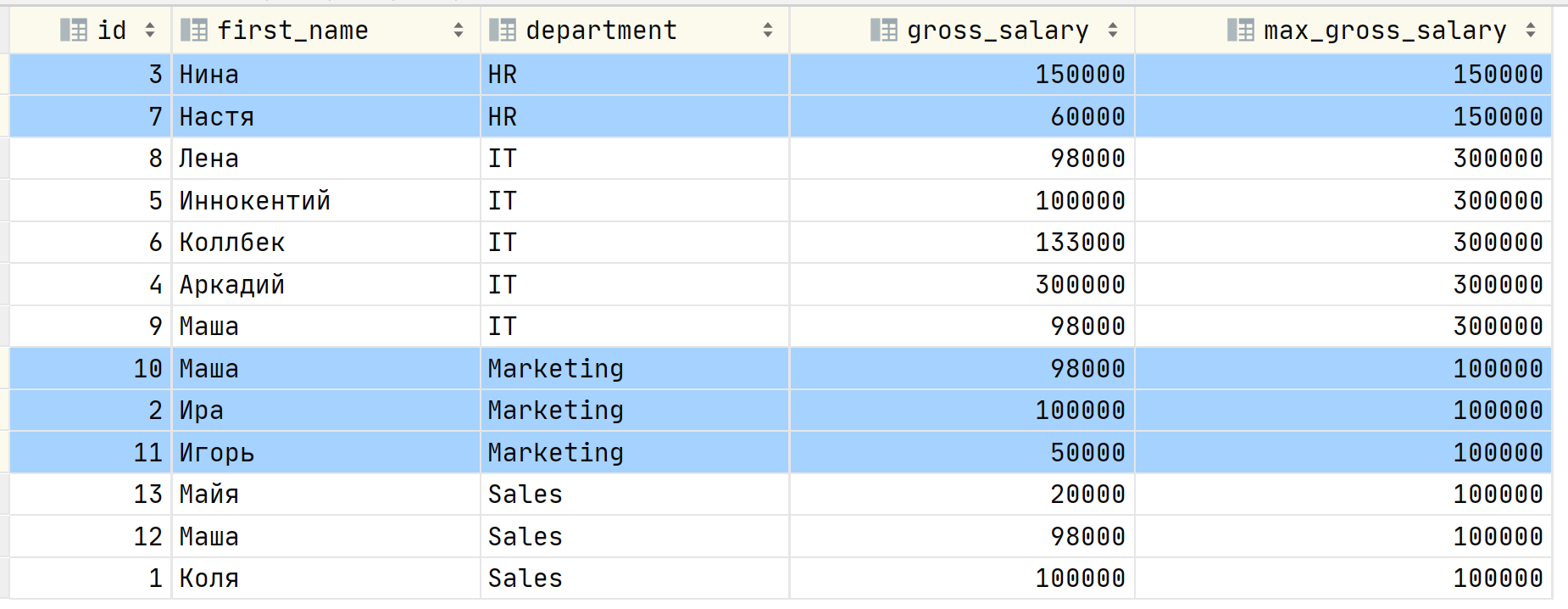
Чтобы отфильтровать потенциальных кандидатов на сокращение можно выделить запрос в подзапрос:
SELECT * FROM ( SELECT id, first_name, department, gross_salary, MAX(gross_salary) OVER (PARTITION BY department) as max_gross_salary FROM Salary ) t WHERE max_gross_salary = gross_salary ORDER BY id;Результат будет точно таким же как и при объединении. Итак, с чувством собственного величия, ощущая себя цифровым палачом вы отправляете результат своему начальнику. Он смотрит на вывод и говорит, что у Аркадия из IT отдела зарплата 300 000, но другой сотрудник в этом же отделе может получать 295 000, разница между ними будет несущественна. Покажи мне пропорцию зарплат в отделе относительно суммы всех зарплат в этом отделе, а также относительно всего фонда оплаты труда!
Как решать? Можно пойти тем же путём, используя подзапросы:
WITH gross_by_departments AS ( SELECT department, SUM(gross_salary) as dep_gross_salary FROM Salary GROUP BY 1 ) SELECT id, first_name, department, gross_salary, ROUND(CAST(gross_salary AS numeric(9, 2)) / dep_gross_salary * 100, 2) as dep_ratio, ROUND(CAST(gross_salary AS numeric(9, 2)) / (SELECT SUM(gross_salary) FROM Salary) * 100, 2) as total_ratio FROM Salary JOIN gross_by_departments USING(department) ORDER BY department, dep_ratio DESC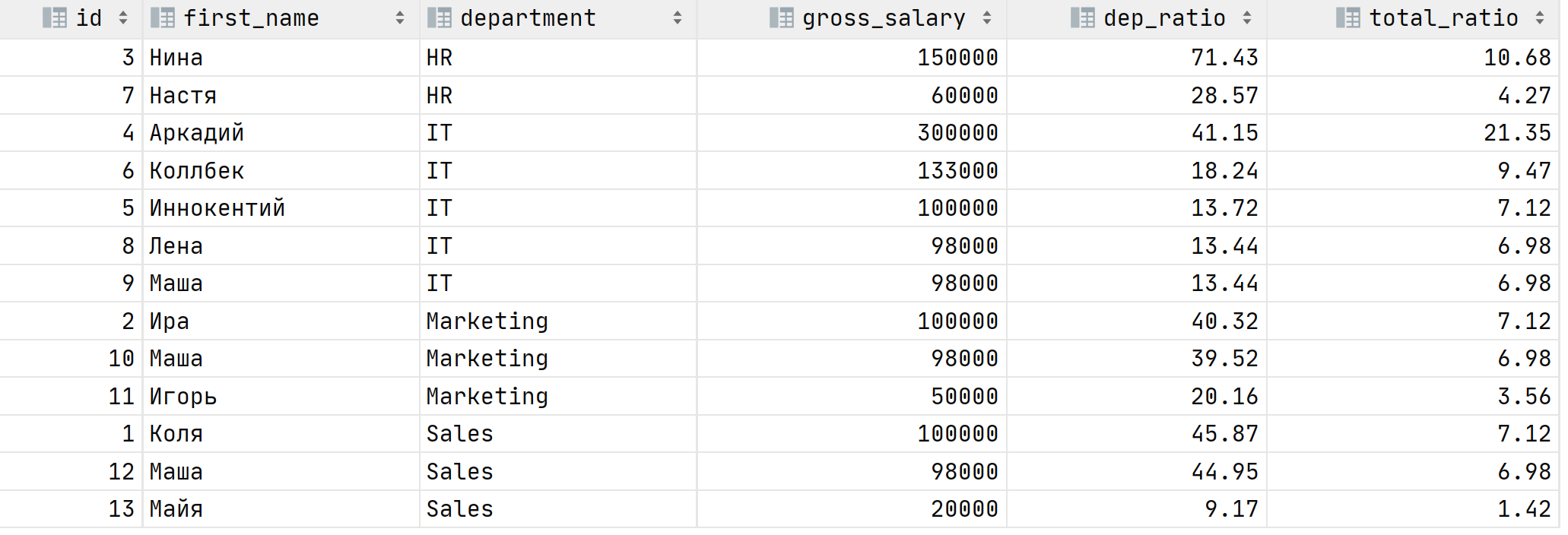
На этой таблице видно, что зарплата Нины это 71% расходов на HR отдел, но лишь 10.5% от всего ФОТ, а вот Аркадий выделился, конечно. Его зарплата это 41% от зарплаты всего IT отдела и 21% от всего ФОТ! Идеальный кандидат на сокращение �� Но не кажется ли вам, что SQL запрос малость сложный? Давайте попробуем его написать через оконные функции:
SELECT id, first_name, department, gross_salary, ROUND(CAST(gross_salary AS numeric(9,2)) / SUM(gross_salary) OVER (PARTITION BY department) * 100, 2) as dep_ratio, ROUND(CAST(gross_salary AS numeric(9,2)) / SUM(gross_salary) OVER () * 100, 2) as total_ratio FROM Salary ORDER BY department, dep_ratio DESC;Кратко, понятно, содержательно! Выражение OVER() означает, что окном для применения функции являются все строки, т.е. SUM(gross_salary) OVER() , означает что сумма будет посчитана по всем зарплатам независимо от департамента в котором работает сотрудник.
Что дальше
В примере выше мы использовали исключительно агрегатные функции как оконные, но в стандарте SQL есть исключительно оконные функции, которые невозможно использовать как агрегатные, это значит, что их невозможно применить при обычной группировке. Вот лишь часть оконных функций, доступных в PostgreSQL:
- first_value
- last_value
- lead
- lag
- rank
- dense_rank
- row_number
Со всеми доступными оконными функциями можно ознакомиться в официальной документации PostgreSQL.
Использование оконных функций
В задаче определения самого высокооплачиваемого сотрудника мы использовали агрегатные функции MAX , SUM , давайте рассмотрим чисто оконную функцию first_value . Она возвращает первое значение согласно заданного окна, т.е. применимо к нашей задаче она должна вернуть имя сотрудника у которого самая высокая зарплата в департаменте.
SELECT id, first_name, department, gross_salary, first_value(first_name) OVER (PARTITION BY department ORDER BY gross_salary DESC ) as highest_paid_employee FROM Salarylast_value делает то же самое только наоборот, возвращает самую последнюю строчку. Давайте найдём с помощью неё самого низкооплачиваемого сотрудника в департаменте.
SELECT id, first_name, department, gross_salary, last_value(first_name) OVER (PARTITION BY department ORDER BY gross_salary DESC) AS lowest_paid_employee FROM Salary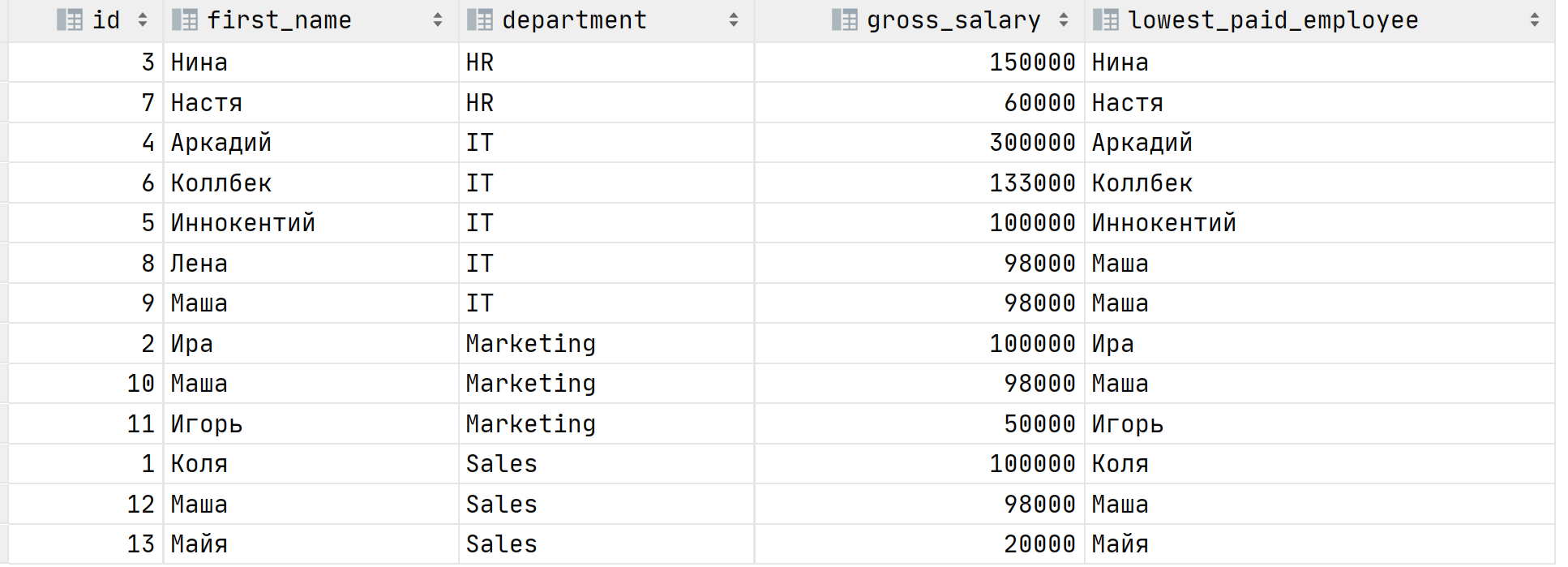
Если внимательно взглянуть на результат выполнения запроса, то можно понять, что он неверный. Почему? А потому что мы не указали диапазон/границы окна относительно текущей строки. По умолчанию, если не задано выражение ORDER BY внутри OVER , то границами окна являются все строки, если ORDER BY задан, то границей для текущей строки будут все предшествующие строки и текущая, в терминах SQL это ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW . В этом можно убедиться, если внимательно взглянуть на результат выполнения крайнего запроса.
Как исправить ситуацию? Расширить границы окна. Перепишем наш запрос, указав в качестве границ все предшествующие строки в окне и все последующие. В терминах SQL это выражение ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING :
SELECT id, first_name, department, gross_salary, last_value(first_name) OVER ( PARTITION BY department ORDER BY gross_salary DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) as lowest_paid_employee FROM SalaryВизуально это выглядит примерно как на картинке ниже.
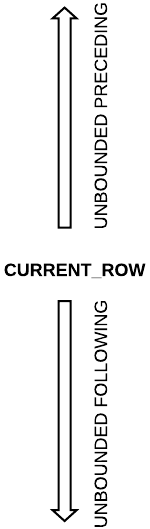
Границы можно определять рядом выражений:
- N PRECEDING, N строк до текущей строки
- CURRENT ROW, текущая строка
- UNBOUNDED PRECEDING, все строки, предшествующие текущей
- UNBOUNDED FOLLOWING, все последующие строки
- N FOLLOWING, N строк после текущей строки
Интересные записи:
- Курс Apache Airflow 2.0
- Apache Airflow и XCom
- Как стать Data Engineer
- Amazon Redshift и Python
- Строим Data Lake на Amazon Web Services
- Введение в Apache Airflow
- Введение в Data Engineering: дата-пайплайны. Курс.
- TaskFlow API в Apache Airflow 2.0