Руководство по пулу строк Java
Объект String является наиболее часто используемым классом в языке Java.
В этой быстрой статье мы рассмотрим пул строк Java — специальную область памяти, в которой JVM хранит строки .
2. Стажировка строк
Благодаря неизменности строк в Java, JVM может оптимизировать объем выделяемой для них памяти, сохраняя в пуле только одну копию каждой литеральной строки . Этот процесс называется интернированием .
Когда мы создаем переменную String и присваиваем ей значение, JVM ищет в пуле строку с равным значением.
Если он найден, компилятор Java просто вернет ссылку на свой адрес памяти, не выделяя дополнительной памяти.
Если он не найден, он будет добавлен в пул (интернирован), и его ссылка будет возвращена.
Давайте напишем небольшой тест, чтобы проверить это:
String constantString1 = "ForEach"; String constantString2 = "ForEach"; assertThat(constantString1) .isSameAs(constantString2); 3. Строки , выделенные с помощью конструктора
Когда мы создаем String с помощью оператора new , компилятор Java создаст новый объект и сохранит его в пространстве кучи, зарезервированном для JVM.
Каждая строка , созданная таким образом, будет указывать на другую область памяти со своим собственным адресом.
Давайте посмотрим, чем это отличается от предыдущего случая:
String constantString = "ForEach"; String newString = new String("ForEach"); assertThat(constantString).isNotSameAs(newString); 4. Строковый литерал против строкового объекта
Когда мы создаем объект String с помощью оператора new() , он всегда создает новый объект в куче памяти. С другой стороны, если мы создадим объект, используя синтаксис строкового литерала, например, « ForEach », он может вернуть существующий объект из пула строк, если он уже существует. В противном случае он создаст новый объект String и поместит его в пул строк для повторного использования в будущем.
На высоком уровне оба являются объектами String , но основное различие заключается в том, что оператор new() всегда создает новый объект String . Кроме того, когда мы создаем строку , используя литерал, она интернируется.
Это станет намного яснее, если мы сравним два объекта String , созданные с использованием литерала String и оператора new :
String first = "ForEach"; String second = "ForEach"; System.out.println(first == second); // True В этом примере объекты String будут иметь одну и ту же ссылку.
Далее создадим два разных объекта с помощью new и проверим, что у них разные ссылки:
String third = new String("ForEach"); String fourth = new String("ForEach"); System.out.println(third == fourth); // False Точно так же, когда мы сравниваем литерал String с объектом String, созданным с помощью оператора new() с помощью оператора ==, он вернет false:
String fifth = "ForEach"; String sixth = new String("ForEach"); System.out.println(fifth == sixth); // False В общем, мы должны использовать литеральную нотацию String , когда это возможно . Его легче читать, и он дает компилятору возможность оптимизировать наш код.
5. Стажировка вручную
Мы можем вручную интернировать строку в пуле строк Java, вызвав метод intern() для объекта, который мы хотим интернировать.
Интернирование строки вручную сохранит ее ссылку в пуле, и JVM вернет эту ссылку при необходимости.
Давайте создадим тестовый пример для этого:
String constantString = "interned ForEach"; String newString = new String("interned ForEach"); assertThat(constantString).isNotSameAs(newString); String internedString = newString.intern(); assertThat(constantString) .isSameAs(internedString); 6. Сбор мусора
До Java 7 JVM помещала Java String Pool в пространство PermGen , которое имеет фиксированный размер — его нельзя расширить во время выполнения и нельзя использовать для сборки мусора .
Риск интернирования Strings в PermGen (вместо Heap ) заключается в том, что мы можем получить ошибку OutOfMemory от JVM, если интернируем слишком много Strings .
Начиная с Java 7, пул строк Java хранится в пространстве кучи , которое является мусором , собираемым JVM . Преимущество этого подхода заключается в снижении риска ошибки OutOfMemory , поскольку строки , на которые нет ссылок , будут удалены из пула, тем самым освобождая память.
7. Производительность и оптимизация
В Java 6 единственная оптимизация, которую мы можем выполнить, — это увеличение пространства PermGen во время вызова программы с параметром JVM MaxPermSize :
-XX:MaxPermSize=1G В Java 7 у нас есть более подробные параметры для проверки и расширения/уменьшения размера пула. Рассмотрим два варианта просмотра размера пула:
-XX:+PrintFlagsFinal -XX:+PrintStringTableStatistics Если мы хотим увеличить размер пула с точки зрения сегментов, мы можем использовать параметр StringTableSize JVM:
-XX:StringTableSize=4901 До Java 7u40 размер пула по умолчанию составлял 1009 сегментов, но в более поздних версиях Java это значение претерпело некоторые изменения. Если быть точным, размер пула по умолчанию от Java 7u40 до Java 11 составлял 60013, а теперь он увеличился до 65536.
Обратите внимание, что увеличение размера пула потребует больше памяти, но имеет то преимущество, что сокращает время, необходимое для вставки строк в таблицу.
8. Примечание о Java 9
До Java 8 строки были внутренне представлены как массив символов — char[] , закодированный в UTF-16 , так что каждый символ использует два байта памяти.
В Java 9 предоставляется новое представление, называемое компактными строками. Этот новый формат выберет подходящую кодировку между char[] и byte[] в зависимости от сохраненного содержимого.
Поскольку новое представление String будет использовать кодировку UTF-16 только при необходимости, объем памяти кучи будет значительно меньше, что, в свою очередь, приведет к меньшим накладным расходам сборщика мусора на JVM.
9. Заключение
В этом руководстве мы показали, как JVM и компилятор Java оптимизируют выделение памяти для объектов String через Java String Pool.
Все примеры кода, использованные в статье, доступны на GitHub .
По каким критериям в Java строка попадает в пул строк?
По сути этот вопрос продолжает другой вопрос. Во многих статьях говорится, что при создании строк без new через литерал строка попадает в пул строк. В противном случае необходим метод intern . Как тогда объяснить поведение ниже ?
String s2 = "hello"; String s1 = "hello"; System.out.println(s1 == s2); // true System.out.println("hel" + "lo" == "hello"); // true s1 = "hello"; s2 = "hel"; String s3 = "lo"; System.out.println(s1 == s2 + s3); // false System.out.println(s2 + s3 == "hel" + "lo"); //false
Если в последнем случае s2 ссылается туда же куда и литерал «hel», и с s3 такая же история, то почему «hel» + «lo» не равно (по ссылке) s2 + s3 ?
Отслеживать
задан 6 сен 2017 в 9:12
7,708 17 17 золотых знаков 70 70 серебряных знаков 132 132 бронзовых знака
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Строка попадет в пул строк только после вызова метода intern класса String.
Детально про строковые литералы из спецификации на английском
По поводу «hel» + «lo» — это строковая константа
public static void main(String[] args)
Скомпилируем и посмотрим его декомпилятором
public static void main(String[] args)
Компилятор собрал «hel» + «lo» в одну строку, что бы доказать это, посмотрим байткод:
public static main([Ljava/lang/String;)V L0 LINENUMBER 6 L0 LDC "hel" ASTORE 1 L1 LINENUMBER 7 L1 LDC "lo" ASTORE 2 L2 LINENUMBER 9 L2 GETSTATIC java/lang/System.out : Ljava/io/PrintStream; NEW java/lang/StringBuilder DUP INVOKESPECIAL java/lang/StringBuilder. ()V ALOAD 1 INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; ALOAD 2 INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String; LDC "hello" IF_ACMPNE L3 ICONST_1 GOTO L4 L3 FRAME FULL [[Ljava/lang/String; java/lang/String java/lang/String] [java/io/PrintStream] ICONST_0 L4 FRAME FULL [[Ljava/lang/String; java/lang/String java/lang/String] [java/io/PrintStream I] INVOKEVIRTUAL java/io/PrintStream.println (Z)V L5 LINENUMBER 10 L5 RETURN L6 LOCALVARIABLE args [Ljava/lang/String; L0 L6 0 LOCALVARIABLE s2 Ljava/lang/String; L1 L6 1 LOCALVARIABLE s3 Ljava/lang/String; L2 L6 2 MAXSTACK = 3 MAXLOCALS = 3 > «hello» представлена константой, s2 + s3 собираются через StringBuilder и преобразуются в строку через toString(), соответственно это 2 разных объекта, и при сравнении указателей будет false
Бассейн со строками
Бывает так, что долго-долго собираюсь написать про какую-то тему и не нахожу на это время, а потом приходит человек и задает на эту тему вопрос (спасибо тебе, человек!), после которого находятся силы и время сделать разбор интересной темы.
Речь пойдет об организации памяти в JVM и таком явлении как String pool, а также почему нельзя так просто взять и удалить секретную информацию из памяти android приложения.
Внутри много картинок!

Очень поверхностный ликбез
Все строки в JVM являются неизменяемыми и создаются в области памяти, которая называется “куча” (heap). Внутри кучи есть еще одна область памяти, которая называется string pool. В эту область памяти, строки попадают автоматически, если создаются с помощью двойных кавычек. Строки могут быть также помещены в эту область памяти вручную при вызове метода intern() , а сам процесс помещения строк в пул называется интернированием.
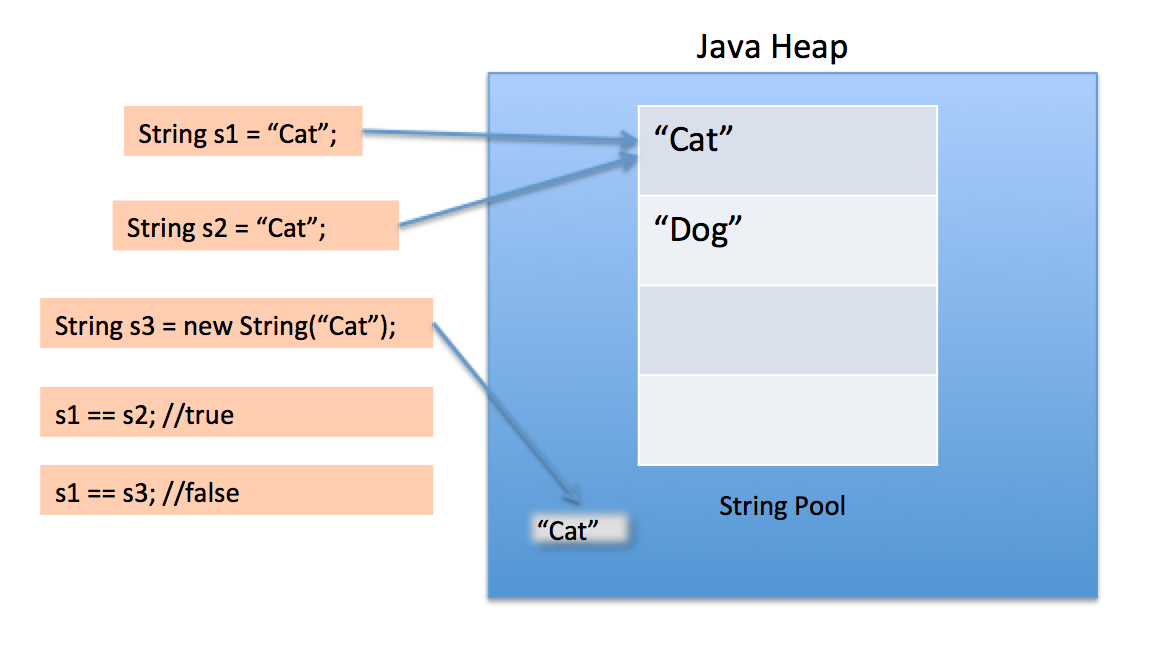
- Содержимое строк нельзя менять. При перезаписи строкового значения, будет создан новый объект, а старый ждет пока его соберет сборщик мусора.
- Сборщик мусора не собирает строки из пула
Эти оба два нюанса приводят к очень неприятным последствиям с точки зрения безопасности — невозможности гарантированно удалить строки из памяти приложения. А значит все токены, пароли и прочая конфиденциальная информация будет находиться в памяти приложения непредсказуемое количество времени. Почитать про пул строк более подробно можно по ссылке в конце статьи, а сейчас разберем на практических примерах как работает вся эта кухня и рассмотрим возможные решения этой проблемы.
Погружение в проблему

Чтобы наше путешествие в глубины JVM было удачным, нужно подготовить инструменты для создания дампов и последующего анализа памяти. Для создания дампов я использую самописный скрипт на bash:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #!/bin/bash if [ -z $1 ] then echo "Usage: ./dumper " exit fi if ! command -v adb &> /dev/null then echo "adb could not be found. Add your \$ANDROID_HOME/platform-tools to PATH" exit fi if ! command -v hprof-conv &> /dev/null then echo "hprof-conv could not be found. Add your \$ANDROID_HOME/platform-tools to PATH" exit fi DEFAULT_HPROF_FILE=dump_$(date +%s).hprof adb shell am dumpheap $(adb shell ps | grep $1 | awk '') /data/local/tmp/$DEFAULT_HPROF_FILE && adb pull /data/local/tmp/$DEFAULT_HPROF_FILE && hprof-conv -z $DEFAULT_HPROF_FILE $1.hprof && adb shell "rm /data/local/tmp/$DEFAULT_HPROF_FILE" if [[ -f $1.hprof ]] then echo "���� Dumped to: $1.hprof" else echo "�� Something went wrong!" fi А для разных этапов анализа нам понадобятся следующие инструменты:
- Утилита strings и ее ближайший друг grep
- Android Studio Memory Profiler
- Парсер hprof файлов
Как это все будет задейстовано я покажу далее, а пока начнем с очень простого и надуманного примера.
Тому, кто захочет это повторить — придется делать очень много дампов. Более ленивых людей призываю просто наслаждаться происходящим 😉
Простой, надуманный пример
var token = "super_secret_token1337" Log.d("Debug", token) token = "" System.gc() Log.d("Debug", token) Результат работы этого кода довольно предсказуем:

Был токен и не стало. Но, не все так однозначно. Давайте сделаем дамп памяти запущенного приложения и поищем в ней этот токен.
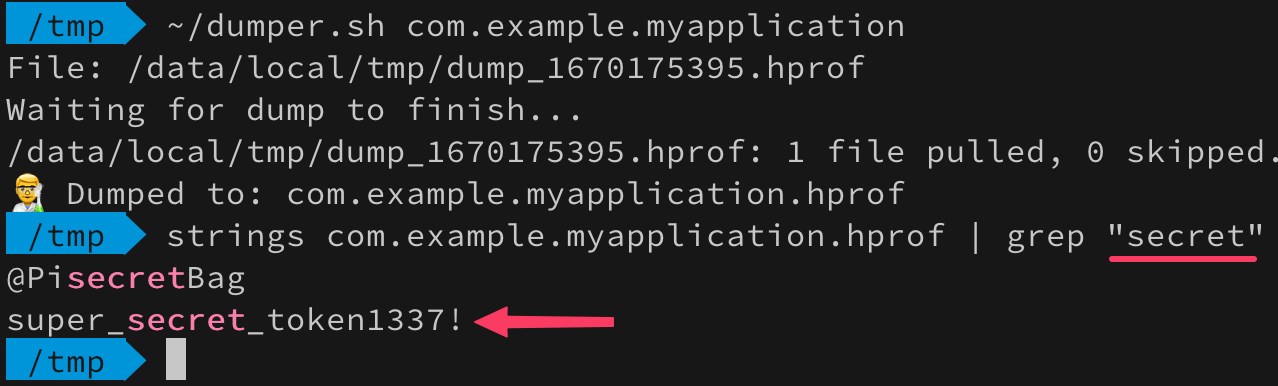
Строковый литерал предсказуемо оказался в пуле строк и даже принудительная сборка мусора не смогла его оттуда удалить. Используя знания полученные о том, что строки созданные с помощью конструктора в пул автоматически не попадают, попробуем сделать так чтобы наш секретный токен не оседал в памяти. Собирать строку будем через CharArray , чтобы вообще отказаться от строковых литералов.
var token = String( charArrayOf( 's', 'u', 'p', 'e', 'r', '_', 's', 'e', 'c', 'r', 'e', 't', '_', 't', 'o', 'k', 'e', 'n', '1', '3', '3', '7' ) ) Log.d("Debug", token) token = "" System.gc() Log.d("Debug", token) 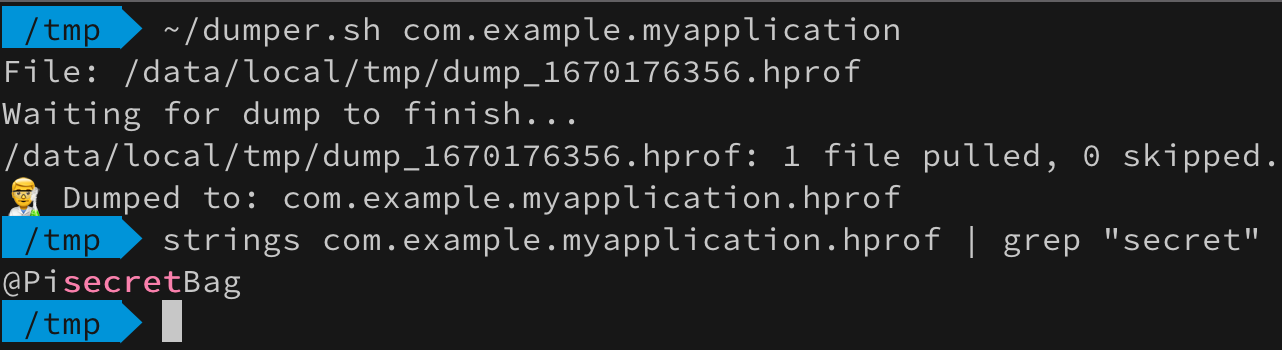
Гипотеза сработала! CharArray всех спас! На этом можно было бы закончить статью фразой “Используйте CharArray и да пребудет с вами безопасность”. Но давайте не будем торопиться с выводами. Немного модифицируем код и поменяем содержимое токена для наглядности:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 var token = String( charArrayOf( 'n', 'o', 't', '_', 's', 'o', '_', 's', 'e', 'c', 'r', 'e', 't', '_', 't', 'o', 'k', 'e', 'n', '1', '3', '3', '7' ) ) val hw = findViewByIdTextView>(R.id.hworld) hw.setOnClickListener Toast.makeText(this, "$token", Toast.LENGTH_SHORT).show() token = "" System.gc() > Запускаем приложением, нажимаем на TextView и…
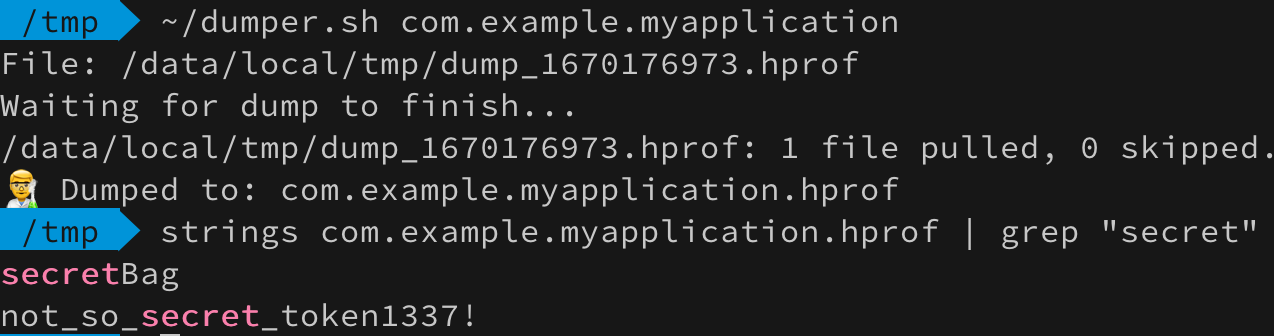
Упс… А вот и магия Хогвартса перестала работать =( Почему так произошло? Давайте разберемся. Для этого нужно загрузить дамп в профилировщик Android Studio и найти ту самую строку чтобы посмотреть ссылки на нее.
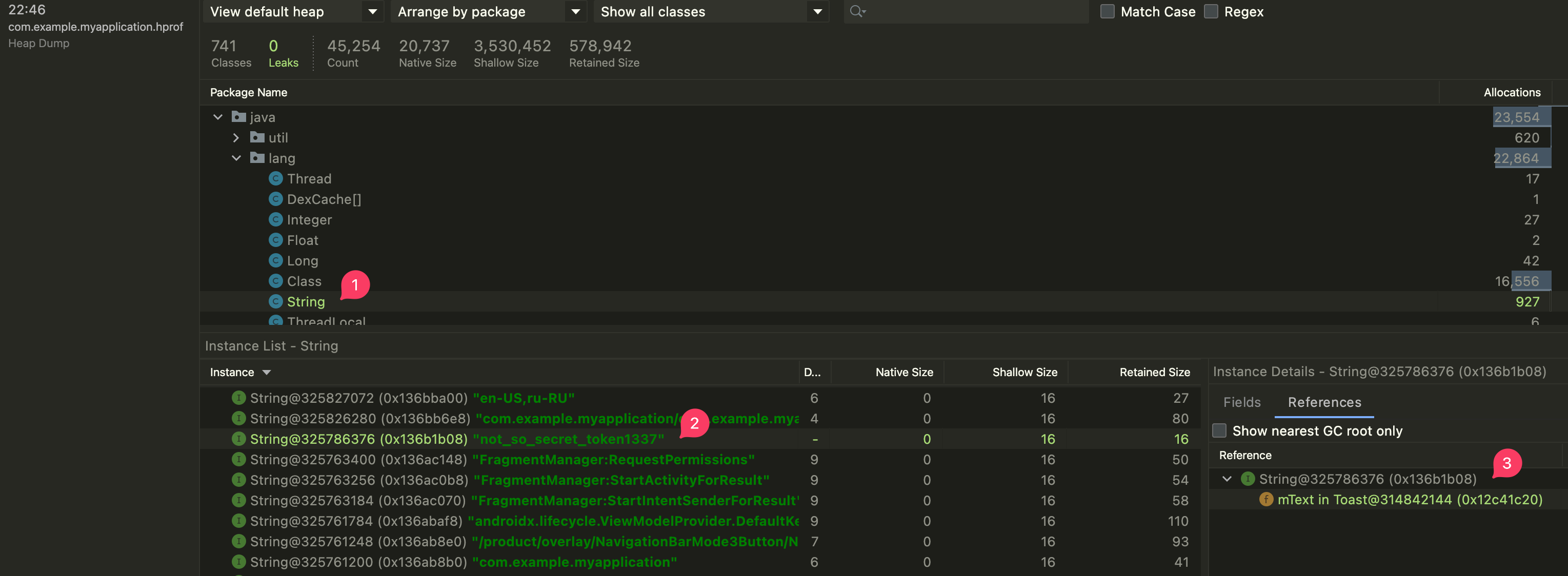
А вот и причина — строка утекла через поле mText класса Toast . Но как так вышло?! Опытные android разработчики и прочие java-джедаи уже знают ответ. Для всех остальных, я открою страшный секрет: параметры в Java всегда передаются по значению. Другими словами — методы работают с копией данных, а не с оригиналом.
Более жизненный пример
До этого строки создавались “руками”, и у вас могли появиться сомнения в адекватности проводимых исследований. Все верно. Всегда нужно сомневаться в том, что читаешь в интернете! Поэтому все дальнейшие исследования будем проводить на классическом, клиент-серверном приложении, которое получает токены от сервера по https и сохраняет их в зашифрованном виде. Приложение забирайте тут.
Основной флоу работы приложения выглядит следующим образом:
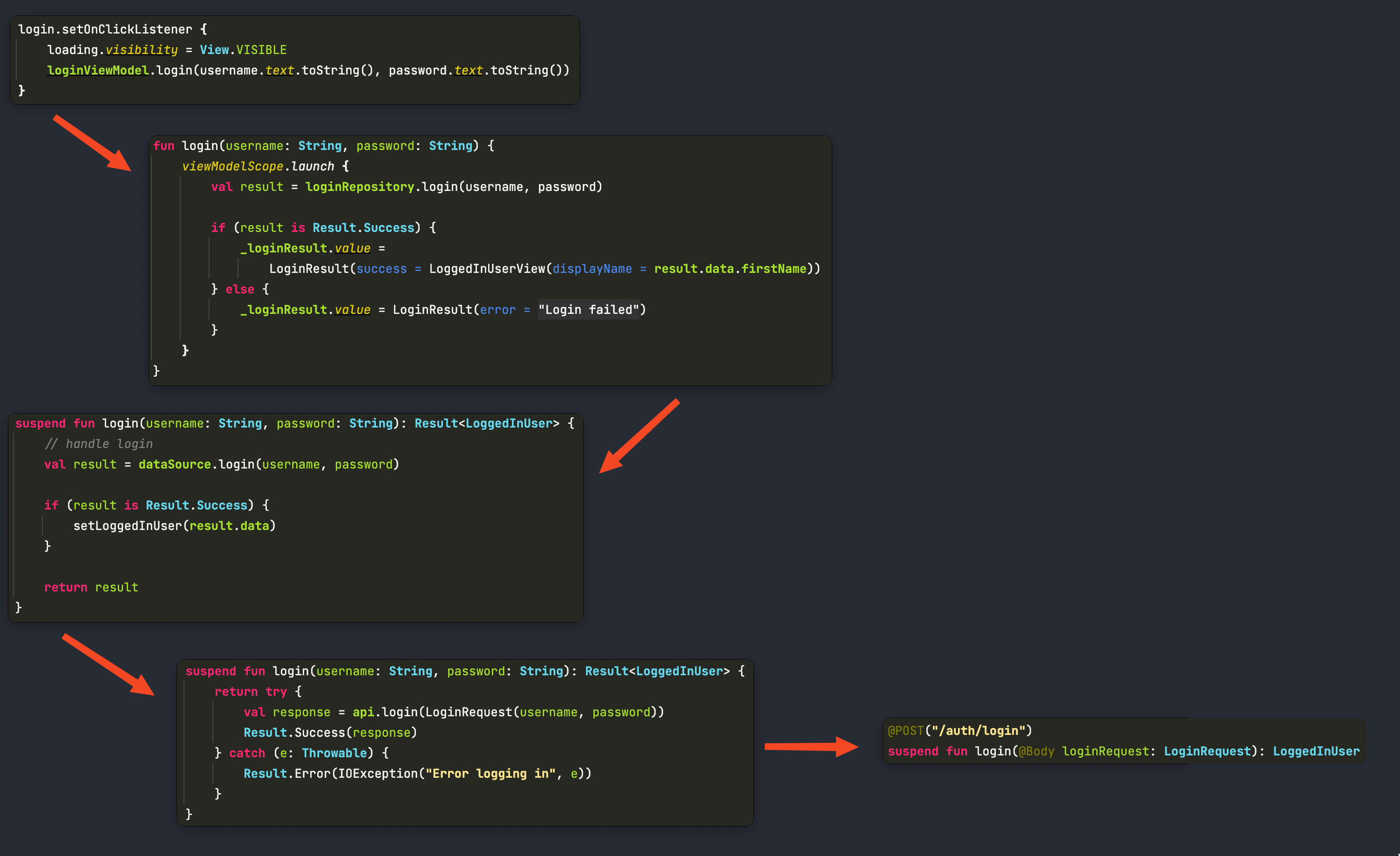
В ответ на запрос приходит модель описывающая залогиненного юзера и среди прочих данных возвращает токен для доступа к API:
1 2 3 4 5 6 7 8 9 10 "id": 15, "username": "kminchelle", "email": "kminchelle@qq.com", "firstName": "Jeanne", "lastName": "Halvorson", "gender": "female", "image": "https://robohash.org/autquiaut.png?size=50x50&set=set1", "token": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6MTUsInVzZXJuYW1lIjoia21pbmNoZWxsZSIsImVtYWlsIjoia21pbmNoZWxsZUBxcS5jb20iLCJmaXJzdE5hbWUiOiJKZWFubmUiLCJsYXN0TmFtZSI6IkhhbHZvcnNvbiIsImdlbmRlciI6ImZlbWFsZSIsImltYWdlIjoiaHR0cHM6Ly9yb2JvaGFzaC5vcmcvYXV0cXVpYXV0LnBuZz9zaXplPTUweDUwJnNldD1zZXQxIiwiaWF0IjoxNjM1NzczOTYyLCJleHAiOjE2MzU3Nzc1NjJ9.n9PQX8w8ocKo0dMCw3g8bKhjB8Wo7f7IONFBDqfxKhs" > Пройдем этот сценарий как есть, потом сделаем дамп и посмотрим где в памяти оседает токен.

Из скрина видно, что токен ссылается несколько объектов из показанной выше цепочки вызовов. Попробуем теперь “очистить память” после сохранения токена в защищенное хранилище и посмотреть, что в итоге попадет в дамп. Сначала нужно доработать метод setLoggedInUser() убрав из памяти ненужный токен:
private fun setLoggedInUser(loggedInUser: LoggedInUser) this.user = loggedInUser preferences.edit putString("accessToken", user?.token) >.also // user?.token = "" System.gc() > > 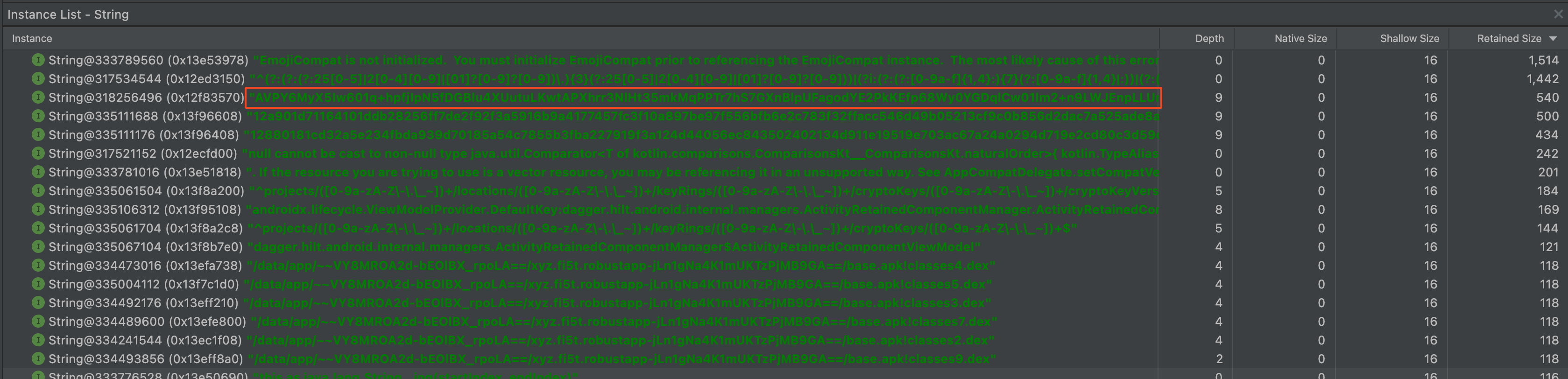
На привычном месте, среди длинных строк, токена больше нет. Только его зашифрованный вариант, который сохранился в преференсы. Неужели получилось? Спойлер: нет ��
В профилировщике студии нет поиска по строкам (или я не нашел), поэтому пройдемся по дампу утилитой strings и погрепаем jwt токены:
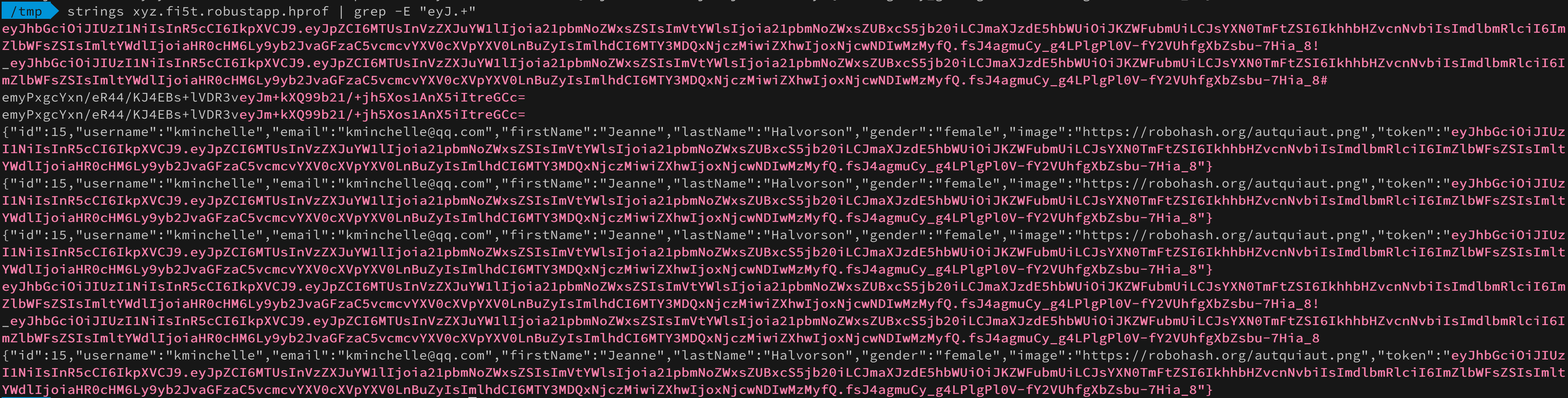
Все на месте. Пришло время погрузится в нюансы формата HPROF и выяснить в какой области памяти оказался вроде бы надежно удаленный токен.
Покопаемся в куче
К дальнейшему анализу дампов, помимо уже имеющихся инструментов, подключим парсер формата hprof. Я взял готовую реализацию отсюда и немного допилил ее напильником чтобы она вообще работала, а не валилась с ошибкой. Доработанный вариант лежит здесь(ветка research) Стоит сказать, что до того, как найти эту реализацию я начал писать свою и концепт получился даже неплохим, но в итоге я решил не изобретать велосипед и взять что-то более-менее готовое. Если кому-то захочется написать такой парсер самостоятельно, то начать нужно отсюда.
Строки в JVM представляют из себя массив символов — char[] в кодировке UTF-16. А значит искать мы будем записи с типом HPROF_GC_PRIM_ARRAY_DUMP :
HPROF_GC_PRIM_ARRAY_DUMP dump of a primitive array id array object ID u4 stack trace serial number u4 number of elements u1 element type 4: boolean array 5: char array 6: float array 7: double array 8: byte array 9: short array 10: int array 11: long array [u1]* elements Записи (records) это элементы из которых состоит hprof файл. Они делятся на records и sub-records, и имеют разную структуру в зависимости от типа, который определяется тегом (первый байт записи).
Начнем с извлечения всех записей содержащих массивы символов:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 func main() . hprofFile, err := os.Open(filename) if err != nil log.Fatalln(err) > defer hprofFile.Close() hprofParser := parser.NewParser(hprofFile) // Mandatory thing �� _, err = hprofParser.ParseHeader() . for record, err := hprofParser.ParseRecord() if err != nil if errors.Is(err, io.EOF) fmt.Println("\nComplete!") break > log.Fatalln(err) > if subRecord, ok := record.(*hprofdata.HProfPrimitiveArrayDump); ok if subRecord.ElementType == hprofdata.HProfValueType_CHAR content := decodeUTF16(subRecord.Values, binary.BigEndian) if strings.Contains(content, needle) fmt.Println(content) > > > > > Запуск парсера выдает интересные результаты. Совпадения нашлись, но их значительно меньше чем было при проходе утилитой strings . Всего два результата.

На этом месте нужно остановиться и немного подумать. Взглянув на возможные типы элементов, можно предположить, что строки также могут быть представлены как массивы байтов, а не символов. Модифицируем немного код парсера чтобы проверить эту гипотезу:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 for record, err := hprofParser.ParseRecord() if err != nil if errors.Is(err, io.EOF) fmt.Println("\nComplete!") break > log.Fatalln(err) > if subRecord, ok := record.(*hprofdata.HProfPrimitiveArrayDump); ok var elementsType string var content string switch subRecord.ElementType case hprofdata.HProfValueType_BYTE: elementsType = fmt.Sprintf("\033[35m%s\033[0m", subRecord.ElementType) content = string(subRecord.Values) case hprofdata.HProfValueType_CHAR: elementsType = fmt.Sprintf("\033[33m%s\033[0m", subRecord.ElementType) content = decodeUTF16(subRecord.Values, binary.BigEndian) > if strings.Contains(content, needle) fmt.Printf("\033[32m[*] Elements type:\033[0m %s; \033[32mContent:\033[0m %s\n", elementsType, content) > > 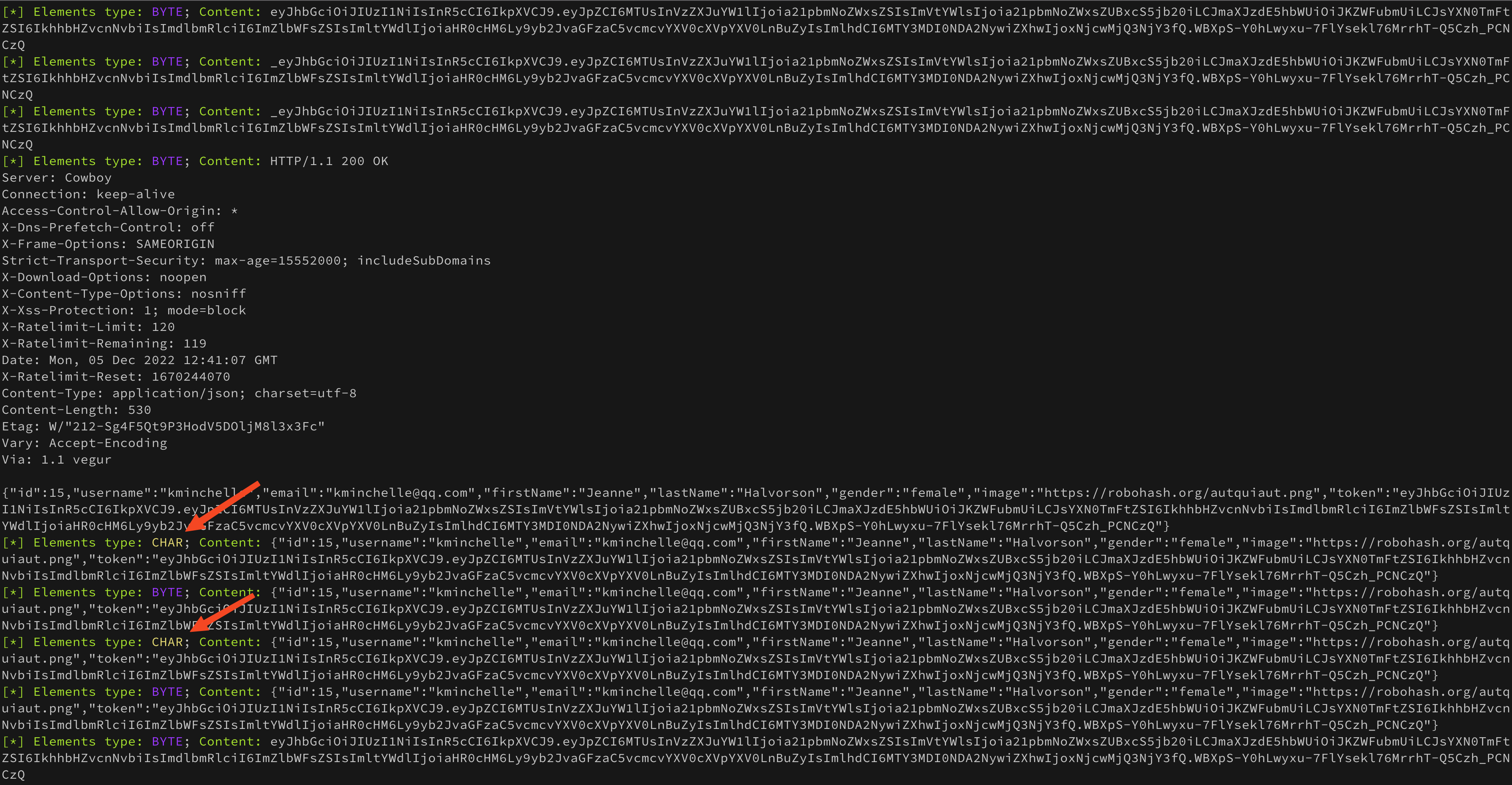
Отлично! Помимо уже имеющихся массивов символов появились байтовые массивы, которые содержат много интересных данных. Уже сейчас видно, что токен, несмотря на все наши усилия попал сразу в несколько кусков памяти, которые мы никак не контролируем.
И что теперь делать?
Порассуждаем. Токен, попал в несколько мест в куче в виде массивов двух типов, char[] и byte[] , но это прозошло неявно, т.к. никаких массивов мы в коде не создавали. Что если попробовать получить больше контроля над этими всеми процессами и вместо строк начать использовать массивы байтов? А еще, байтовые массивы не являются иммутабельными и их можно затирать. Звучит как план!
На самом деле, можно пойти еще дальше и вместо байтового массива использовать байтовый буфер ( ByteBuffer ) с прямой аллокацией памяти.
A direct buffer refers to a buffer’s underlying data allocated on a memory area where OS functions can directly access it.
Начать использовать такой буфер нужно как можно раньше (ниже?) в архитектурном смысле. Самая первая точка, где мы получаем контроль над происходящим, находится в процедуре десериализации. Все, что происходит до этого является для нас черным ящиком. Поэтому начнем с написания адаптера, который будет сериализовать токен в ByteBuffer .
1 2 3 4 5 6 7 8 9 10 11 class ByteBufferAdapter : TypeAdapterByteBuffer>() override fun write(out: JsonWriter?, value: ByteBuffer?) ... > override fun read(`in`: JsonReader): ByteBuffer return `in`.nextString().let ByteBuffer.allocateDirect(it.length).put(it.encodeToByteArray()) > > > Даже на этом уровне нам уже приходится иметь дело со строками, но будем надеятся, что они там как-нибудь сами пропадут 😉 Далее доработаем доменную модель пользователя:
1 2 3 4 5 6 7 data class LoggedInUser( ... @SerializedName("token") @JsonAdapter(ByteBufferAdapter::class) var token: ByteBuffer ) Тут уже все хорошо, никаких строк не создается и мы практически в шаге от абсолютной безопасности! Осталось только очистить буфер после его сохранения в shared preferences.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 fun ByteBuffer.wipeDirectBuffer(random: Random = Random()) if (!this.isDirect) throw IllegalStateException("Only direct-allocated byte buffers can be meaningfully wiped") val arr = ByteArray(this.capacity()) this.rewind() random.nextBytes(arr) this.put(arr) > ... private fun setLoggedInUser(loggedInUser: LoggedInUser) this.user = loggedInUser user?.let u -> preferences.edit putString("accessToken", String(u.token.array())) >.also u.token.wipeDirectBuffer() System.gc() > > > Тут мы тоже без строк не обойдемся, к сожалению. SharedPreferences.Editor просто не умеет сохранять данные в виде массива байт. Но может нам повезет и это использование строк тоже никто не заметит? Тем более строка создается через конструктор, в пул строк попасть не должна, а значит мы все еще в безопасности!
Запускаем приложение, получаем токен с сервера, делаем дамп и смотрим на результат
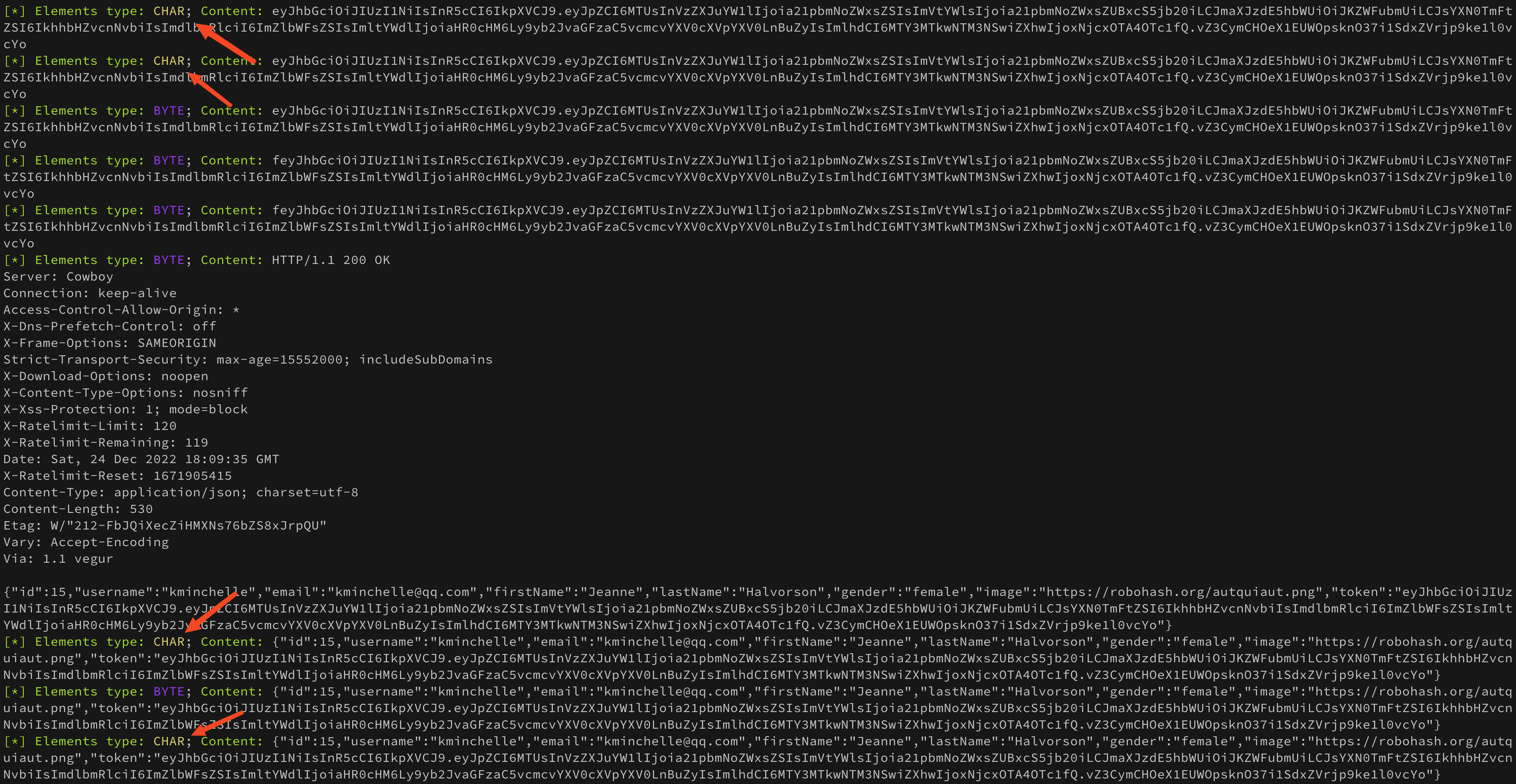
В голову сразу приходит вот эта картинка

Да, результат стал еще хуже чем был. И это еще не все данные, остальные не уместились на скриншоте. Что тут сказать… Не прокатило ��
Показанный выше способ с байтовыми буферами — вполне рабочий. Проблема не в нем. Она в том, что мы не контролируем большую часть того, что происходит с данными в приложении. Как с ними обращаются библиотеки, которые мы используем. Куда и как они их копируют и во что конвертируют. Чтобы избавиться от этой проблемы — нужно контролировать вообще все. В том числе сетевые библиотеки, сериализаторы, сохранять данные на диск в собственном формате. Все это должно быть самописным и не использовать JVM строки. Никто в здравом уме не будет этим заниматься.
Заключение
Стоило ли писать целую статью, если можно было в 3-5 предложений обрисовать ситуацию? Я считаю, что стоило. Хотябы для того чтобы прекратить поиск точки G возможностей затирать строки в памяти и сделать это осознанно. С доказательной базой, с инструментами для проверки гипотез и четким пониманием границ реализуемых механизмов. Я надеюсь, что прочитав ее вы узнали что-то новое и стали лучше понимать ту платформу с которой имеете дело в качестве разработчика или хакера.
Всех с наступающим Новым Годом! ��
Ссылки
- Руководство по String pool в Java
- Java is Pass by Value and Not Pass by Reference
- Guide to ByteBuffer
Что такое пул строк

Пул строк – это механизм в программировании, который используется для оптимизации управления строками в памяти компьютера. В языках программирования, таких как Java, C# и Python, строки являются неизменяемыми объектами, то есть после создания строку нельзя изменить. Пул строк позволяет сократить объем занимаемой памяти путем предотвращения создания дубликатов строк, записывая каждую строку только один раз.
Когда мы создаем строку в программе, она помещается в пул строк. Если в дальнейшем создается еще одна строка с тем же значением, она не создается заново, а просто возвращается ссылка на уже существующую строку из пула. Это позволяет сэкономить память и увеличить производительность программы.
Принцип работы пула строк основан на хешировании значений строк. Каждой строке в пуле строк сопоставляется уникальный хеш-код, который вычисляется на основе содержимого строки. При создании новой строки сначала проверяется, существует ли уже в пуле строк строка с таким же хеш-кодом. Если существует, то новая строка не создается, а возвращается ссылка на уже существующую строку. Таким образом, разные строки с одинаковым содержимым будут представлены одним и тем же объектом в пуле строк.
Использование пула строк может быть полезным при работе с большим количеством строк или при работе с одними и теми же строками в разных частях программы. Особенно это актуально в приложениях, где требуется эффективное использование памяти и оптимизация производительности.
Что такое пул строк?
Пул строк — это механизм в языке программирования, который оптимизирует использование памяти для строковых объектов. Вместо создания новой строки при каждом использовании, пул строк позволяет использовать уже существующие строки из общего пула.
Когда создается строковый литерал или объект, он сначала проверяется в пуле строк. Если строка с таким значением уже существует, то новая ссылка на эту строку добавляется в пул. Если же строки с таким значением нет, то создается новый объект и добавляется в пул строк.
Пул строк позволяет сэкономить память, так как он гарантирует, что одинаковые строки будут представлены единственным объектом в памяти. Это особенно полезно, когда в приложении используется много одинаковых строк, например, при работе с текстовыми данными или базами данных.
Следует отметить, что пул строк работает только для немутабельных (неизменяемых) строк. Если происходит изменение строки, то создается новый объект в памяти, а старый объект остается в пуле.
Использование пула строк также может улучшить производительность программы, так как сравнение строк может быть выполнено быстрее, если можно сравнивать ссылки на объекты в пуле, а не выполнять сравнение символов посимвольно.
Определение и назначение
Пул строк (или строковый пул) — это механизм, который используется в программировании для оптимизации работы с текстовыми данными. Он представляет собой специальную структуру данных, в которой хранятся уникальные строковые значения, используемые в программе.
Пул строк позволяет избежать создания дублирующихся строковых объектов в памяти компьютера. Вместо этого, при попытке создания новой строки, пул строк проверяет, есть ли уже в нем такая же строка. Если да, то вместо создания нового объекта, используется ссылка на уже существующий объект в пуле строк.
Назначение пула строк состоит в экономии затрат на память, ускорении работы программы и снижении нагрузки на сборщик мусора. Благодаря пулу строк, программисты могут использовать операции сравнения строк эффективно, сравнивая ссылки на объекты в пуле, а не содержимое строк символов.
В некоторых языках программирования, таких как Java и C#, пул строк является встроенной функцией языка. В других же языках программирования, пул строк может быть реализован самим программистом.
Принцип работы пула строк
Пул строк (String pool) — это механизм в языке программирования Java, который позволяет оптимизировать использование памяти при работе со строками.
Когда в программе создается строка, она помещается внутрь пула строк. В пуле строк хранятся все уникальные строки, используемые в программе. Если в программе создается строка, которая уже существует в пуле строк, то вместо создания нового объекта Java просто ссылается на уже существующий объект в пуле строк.
Такой подход позволяет избежать дублирования строк в памяти. Это особенно полезно в случае, когда в программе используются множество одинаковых строк или строк, которые не изменяются.
Принцип работы пула строк можно описать следующими шагами:
- При создании строки с помощью оператора new , Java проверяет, существует ли уже такая строка в пуле строк.
- Если строка уже существует, то Java возвращает ссылку на существующий объект в пуле строк.
- Если строка не существует, то Java создает новый объект и помещает его в пул строк.
- В результате получаем ссылку на объект в пуле строк, который можно использовать для работы с данной строкой.
Пример использования пула строк:
String s1 = «Hello»; // создание строки, которая уже существует в пуле строк
String s2 = «Hello»; // ссылка на уже существующий объект в пуле строк
System.out.println(s1 == s2); // выводит true, так как s1 и s2 ссылаются на один и тот же объект в пуле строк
String s3 = new String(«Hello»); // создание нового объекта, который находится вне пула строк
String s4 = new String(«Hello»); // создание еще одного нового объекта, который находится вне пула строк
System.out.println(s3 == s4); // выводит false, так как s3 и s4 ссылаются на разные объекты вне пула строк
Важно отметить, что использование оператора new явно указывает Java на создание нового объекта, который будет храниться вне пула строк. Поэтому при использовании оператора new строки не сравниваются по ссылке, а по значению. В приведенном выше примере переменные s3 и s4 содержат одинаковое значение «Hello», поэтому оператор сравнения выводит false.
Алгоритмы и структуры данных
Алгоритм — последовательность точно заданных правил, по которым можно получить решение для задачи. Он является базовым инструментом программиста и используется для разработки программного обеспечения.
Структура данных — организованная форма хранения и управления данными. Выбор правильной структуры данных важен для оптимизации скорости работы программы.
Одним из ключевых алгоритмов и структур данных является пул строк (string pool). Пул строк, также известный как «строковый пул» или «строковая константа», представляет собой механизм оптимизации использования памяти для строковых данных.
Принцип работы пула строк заключается в том, что каждая уникальная строка в программе хранится в единственном экземпляре, а все ссылки на эту строку указывают на один и тот же объект в памяти.
Когда строка создается, она сначала ищется в пуле строк. Если такая строка уже существует, то возвращается ссылка на нее. Если же строка не найдена, то она добавляется в пул строк и новая ссылка возвращается.
Такой подход позволяет сэкономить память, так как строки, которые повторно используются в программе, не создаются в памяти каждый раз заново.
Пул строк применяется во многих языках программирования, таких как Java, C#, Python и других. Он позволяет повысить производительность программы и сократить использование памяти.
Преимущества использования пула строк
Пул строк (или String Pool) — это механизм в языке программирования Java, который позволяет использовать одну и ту же строку несколько раз в программе без выделения дополнительной памяти. Вот некоторые преимущества использования пула строк:
- Экономия памяти: Благодаря пулу строк можно сэкономить память, так как строки, которые уже существуют в пуле, не будут создаваться заново. Вместо этого новые строки будут ссылаться на уже существующие объекты в пуле.
- Более эффективное сравнение строк: Поскольку строки в пуле существуют в единственном экземпляре, их можно сравнивать с помощью оператора «==» вместо метода equals(). Это увеличивает производительность программы, так как операция сравнения с использованием «==» выполняется намного быстрее, чем с использованием equals().
- Удобство использования: Использование пула строк делает работу со строками более удобной. Например, строку можно создать с помощью литерала (например, «Hello») и быть уверенным, что она будет существовать в пуле. Это упрощает кодирование и позволяет избегать создания дополнительных объектов.
В целом, использование пула строк в Java обеспечивает более эффективное использование памяти и упрощает работу с текстовыми данными. Оно особенно полезно при работе с большим количеством строк или при работе с неизменяемыми строками. Поэтому по умолчанию все строки в Java находятся в пуле строк и используются из него.
Примеры практического применения
Пул строк — это важная техника оптимизации при работе с большими объемами текстовых данных. Вот несколько примеров, где пул строк может быть полезен:
- Базы данных: при работе с базами данных, где хранится множество текстовых данных, использование пула строк может существенно сократить расход памяти. Вместо создания отдельных объектов String для каждой строки, использование пула строк позволяет переиспользовать уже существующие объекты, что экономит ресурсы.
- Кэширование: пул строк часто применяется в механизмах кэширования. Когда данные из какого-либо источника загружаются и сохраняются в кэш, пул строк может быть использован для оптимизации работы с этими данными. Если в кэше уже есть строка с идентичным содержимым, то вместо создания нового объекта String можно использовать уже существующий объект.
- Сравнение строк: при сравнении строк, использование пула строк может улучшить производительность. Когда две строки сравниваются, можно сначала проверить, находятся ли они в пуле строк. Если да, то можно сравнить их ссылки, что обычно гораздо более эффективно, чем сравнивать символы каждой строки.
Все эти примеры показывают, что использование пула строк позволяет сэкономить память и повысить производительность при работе с текстовыми данными. Поэтому понимание, как работает пул строк и где его можно применять, очень полезно для разработчиков программного обеспечения.
Вопрос-ответ
Что такое пул строк?
Пул строк — это механизм, который используется в языках программирования для оптимизации использования памяти. Он представляет собой область памяти, в которой хранятся строки, используемые в программе.
Как работает пул строк?
При использовании пула строк, когда мы создаем новую строку, система сначала проверяет, есть ли уже такая строка в пуле. Если есть, то вместо создания нового объекта строки система возвращает ссылку на уже существующую строку. Если же такой строки в пуле нет, то создается новый объект строки, который добавляется в пул.
Какие преимущества дает использование пула строк?
Использование пула строк позволяет экономить память, так как одинаковые строки не создаются заново, а используются уже существующие объекты. Это особенно полезно, когда в программе используется большое количество одинаковых строк.