Оптимизация обслуживания индексов позволяет повысить производительность запросов и снизить уровень потребления ресурсов
Эта статья поможет вам понять, когда и как лучше всего выполнять обслуживание индексов. Здесь рассматриваются такие понятия, как фрагментация индексов и плотность страниц, а также их влияние на производительность запросов и потребление ресурсов. Также описываются методы обслуживания индексов, в частности реорганизация индекса и перестроение индекса, и предлагается стратегия обслуживания индексов с оптимальным балансом между повышением производительности и снижением уровня потребления ресурсов, необходимых для обслуживания.
Эта статья не применяется к выделенному пулу SQL в Azure Synapse Analytics. Сведения о обслуживании индексов для выделенного пула SQL в Azure Synapse Analytics см. в статье Индексирование выделенных таблиц пула SQL в Azure Synapse Analytics.
Основные понятия: фрагментация индекса и плотность страниц
Что такое фрагментация индекса и как она влияет на производительность?
-
В индексах сбалансированного дерева (rowstore) фрагментацией называют такое состояние, когда для некоторых страниц индекса логический порядок, основанный на значении ключа, не совпадает с физическим порядком страниц индексов.
Примечание. В документации по SQL Server термин «сбалансированное дерево» обычно используется в отношении индексов. В индексах rowstore SQL Server реализует B+-дерево. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в руководстве по архитектуре и проектированию индексов SQL Sql Server и Azure.
Что такое плотность страниц (или заполненность страниц) и как она влияет на производительность?
- Каждая страница в базе данных может содержать переменное число строк. Если эти строки занимают весь объем страницы, плотность такой страницы определяется как 100 %. Если страница пуста, ее плотность определяется как 0 %. Разбивая страницу с плотностью 100 % на две страницы, например для размещения новой строки, мы получим для новых страниц значения плотности около 50 %.
- Если плотность страниц мала, то для хранения того же объема данных требуется больше страниц. Это означает, что для чтения и записи тех же данных потребуется больше операций ввода-вывода, а для кэширования — больше памяти. Если объем памяти ограничен, меньше страниц, необходимых запросу, кэшируются, что приводит к еще большему объему операций ввода-вывода диска. Как мы понимаем, низкая плотность страниц негативно влияет на производительность.
- Если ядро СУБД добавляет строки на страницу, она не заполняет страницу полностью, если коэффициент заполнения индекса имеет значение, отличное от 100 (или 0), эквивалентное этому контексту. Это приводит к уменьшению плотности страниц и увеличивает затраты на ввод-вывод, а значит, негативно влияет на производительность.
- При низкой плотности страниц может увеличиться количество промежуточных уровней в сбалансированном дереве. Это немного повышает нагрузку на ЦП и количество операций ввода-вывода при поиске страниц конечного уровня для операций сканирования и поиска по индексу.
- Когда оптимизатор запросов компилирует план запроса, он учитывает стоимость операций ввода-вывода для чтения необходимых этому запросу данных. При низкой плотности страниц потребуется считывать больше страниц, а значит, и стоимость ввода-вывода будет выше. Это может повлиять на выбор плана запроса. Например, с течением времени плотность страниц уменьшается из-за разбиений, и оптимизатор может скомпилировать для того же запроса другой план с другой профилем потребления ресурсов и другой производительностью.
Для многих рабочих нагрузок повышение плотности страниц позволяет больше повысить производительность, чем снижение фрагментации.
Чтобы не допустить излишнего снижения плотности страниц, корпорация Майкрософт не рекомендует задавать коэффициент заполнения, отличный от значения 100 (или 0), за исключением тех сценариев, в которых индексы часто подвергаются разбиению страниц, как, например, часто изменяемые индексы с ведущими столбцами, которые содержат непоследовательные значения GUID.
Измерение фрагментации индекса и плотности страниц
Как фрагментацию, так и плотность страниц важно учитывать при принятии решений о времени обслуживания индекса и предпочтительном методе обслуживания.
Фрагментация для индексов rowstore и columnstore определяется по-разному. Для индексов rowstore функция sys.dm_db_index_physical_stats позволяет узнать фрагментацию и плотность страниц для конкретного индекса, для всех индексов в таблице или индексированном представлении, для всех индексов в базе данных или для всех индексов во всех базах данных. Для секционированных индексов sys.dm_db_index_physical_stats() возвращает информацию отдельно для каждой секции.
Результирующий набор, возвращаемый sys.dm_db_index_physical_stats следующими столбцами:
| Столбец | Description |
|---|---|
| avg_fragmentation_in_percent | Логическая фрагментация (неупорядоченные страницы в индексе). |
| avg_page_space_used_in_percent | Средняя плотность страниц. |
Для сжатых групп строк в индексах columnstore фрагментация определяется как отношение числа удаленных строк к общему числу строк, выраженное в процентах. Функция sys.dm_db_column_store_row_group_physical_stats позволяет определить общее число строк и число удаленных строк отдельно для каждой группы строк в определенном индексе, во всех индексах таблицы или во всех индексах базы данных.
Результирующий набор, возвращаемый sys.dm_db_column_store_row_group_physical_stats следующими столбцами:
| Столбец | Description |
|---|---|
| total_rows | Количество строк, которые физически хранятся в группе строк. Для сжатых групп строк учитываются строки, помеченные как удаленные. |
| deleted_rows | Количество строк, физически хранящихся в сжатой группе строк и помеченных для удаления. Для групп строк в разностном хранилище это значение равно 0. |
Фрагментация сжатых групп строк в индексе columnstore можно вычислить с помощью следующей формулы:
100.0*(ISNULL(deleted_rows,0))/NULLIF(total_rows,0) Как для rowstore, так и для columnstore особенно важно проверять фрагментацию и плотность страниц для индекса или кучи после удаления или обновления большого количества строк. Кроме того, при большой частоте обновления для куч, возможно, потребуется регулярно проверять фрагментацию, чтобы избежать большого числа записей переадресации. Дополнительные сведения о кучах см. в разделе Кучи (таблицы без кластеризованных индексов).
Ознакомьтесь с примерами запросов для определения фрагментации и плотности страниц.
Методы обслуживания индекса: реорганизация и перестроение
Вы можете уменьшить фрагментацию индекса и увеличить плотность страниц с помощью любого из следующих методов:
- Реорганизация индекса
- Перестроение индекса
Для секционированных индексов оба эти метода можно применять ко всем секциям или к одной секции индекса.
Реорганизация индекса
Реорганизация индекса требует меньше ресурсов, чем его перестроение. Поэтому следует считать ее предпочтительным методом для обслуживания индекса, если нет веских причин использовать перестроение индекса. Реорганизация всегда выполняется с сохранением подключения. Это означает, что не создаются долгосрочные блокировки таблиц и запросы или обновления базовой таблицы во время выполнения операции ALTER INDEX . REORGANIZE могут продолжаться.
- Для индексов rowstore ядро СУБД дефрагментирует только конечный уровень кластеризованных и некластеризованных индексов в таблицах и представлениях путем физического переупорядочения страниц конечного уровня в соответствии с логическим порядком конечных узлов (слева направо). Кроме того, при реорганизации страницы индекса сжимаются таким образом, чтобы плотность страниц соответствовала указанному коэффициенту заполнения индекса. Увидеть коэффициент заполнения можно в таблице sys.indexes. Примеры синтаксиса см. в разделе Примеры: реорганизация индексов rowstore.
- При использовании индексов columnstore в результате большого числа операций вставки, обновления и удаления данных в разностном хранилище с течением времени может накопиться много небольших групп строк. Реорганизация индекса columnstore приводит к принудительному сохранению групп строк разностного хранения в сжатые группы строк в columnstore и объединению малых сжатых групп строк в большие группы строк. Кроме того, операция реорганизации позволяет физически удалить те строки, которые помечены в columnstore как удаленные. При реорганизации индекса columnstore могут потребоваться дополнительные ресурсы ЦП для сжатия данных, что иногда приводит к снижению общей производительности системы на время выполнения операции. Но по завершении сжатия данных производительность запросов возрастает. Примеры синтаксиса см. в разделе Примеры: реорганизация индексов columnstore.
Начиная с SQL Server 2019 (15.x), База данных SQL Azure и Управляемый экземпляр SQL Azure, перемещение кортежей помогает задачей фонового слияния, которая автоматически сжимает небольшие открытые разностные группы строк, которые существовали в течение некоторого времени, как определено внутренним пороговым значением, или объединяет сжатые группы строк, из которых было удалено большое количество строк. Это со временем повышает качество индекса columnstore. В большинстве случаев это избавляет от необходимости выдавать команды ALTER INDEX . REORGANIZE .
Если операция реорганизации отменяется пользователем или прерывается иным образом, все уже достигнутые улучшения сохраняются в базе данных. Для реорганизации больших индексов можно многократно запускать и останавливать операцию, пока не будет завершена вся работа.
Перестроение индекса
При перестроении старый индекс удаляется, и создается новый. В зависимости от типа индекса и версии ядра СУБД операция перестроения может выполняться в подключенном или автономном режиме. Перестроение индекса в автономном режиме обычно занимает меньше времени, чем с сохранением подключения, но при этом используются блокировки на уровне объектов на весь период операции перестроения, то есть запросы к таблице или представлению не выполняются.
Перестроение индекса с сохранением подключения не требует блокировок на уровне объектов до окончания операции, если есть возможность устанавливать блокировку на короткий период для выполнения перестроения. В зависимости от версии ядра СУБД перестроение индекса с сохранением подключения может запускаться как возобновляемая операция. Возобновляемое перестроение индекса можно приостановить, сохраняя ход выполнения до текущего момента. Операцию возобновляемого перестроения можно возобновить после приостановки или другого прерывания. Кроме того, ее можно отменить, если завершение перестроения больше не требуется.
Синтаксис Transact-SQL см. в разделе ALTER INDEX REBUILD. Дополнительные сведения об операциях с индексами с сохранением подключения см. в статье Выполнение операции с индексами в сети.
Если перестроение индекса выполняется с сохранением подключения, при любом изменении данных в индексируемых столбцах должна обновляться дополнительная копия индекса. Это может привести к незначительному снижению производительности для инструкций изменения данных во время перестроения с сохранением подключения.
При приостановке операция возобновляемого перестроения индекса с сохранением подключения указанное выше влияние на производительность сохраняется до тех пор, пока возобновляемая операция не будет завершена или отменена. Если вы не планируете завершать возобновляемую операцию с индексами, лучше сразу отменить ее, а не приостанавливать
В зависимости от наличия ресурсов и шаблонов рабочей нагрузки при использовании значения выше стандартного MAXDOP в инструкции ALTER INDEX REBUILD может сократиться длительность перестроения за счет более интенсивной загрузки ЦП.
- Для индексов rowstore перестроение позволяет устранить фрагментацию на всех уровнях индекса и сжать страницы до указанного (или настроенного) коэффициента заполнения. Если указано значение ALL , то все индексы в таблице удаляются и перестраиваются в ходе одной операции. При перестроении индексов с 128 или более экстентами ядро СУБД откладывает размещение страниц и получение связанных блокировок до завершения перестроения. Примеры синтаксиса см. в разделе Примеры: перестроение индексов rowstore.
- Для индексов columnstore перестроение позволяет устранить фрагментацию, переместить все строки разностного хранилища в columnstore и физически удалить строки, помеченные для удаления. Примеры синтаксиса см. в разделе Примеры: перестроение индексов columnstore.
Совет Начиная с SQL Server 2016 (13.x), перестроение индекса columnstore обычно не требуется, так как REORGANIZE выполняет основные компоненты перестроения в качестве оперативной операции.
Использование перестроения индекса для восстановления после повреждения данных
В более ранних версиях SQL Server иногда можно перестроить некластеризованный индекс rowstore, чтобы исправить несоответствия из-за повреждения данных в индексе.
Начиная с SQL Server 2008 (10.0.x), вы все равно сможете восстановить такие несоответствия в некластеризованном индексе, перестроив некластеризованный индекс в автономном режиме. Но вы не сможете устранить несоответствия в некластеризованном индексе, перестроив индекс с сохранением подключения, потому что этот механизм перестроения использует существующий некластеризованный индекс в качестве основы для перестроения, то есть все эти несоответствия сохранятся. Перестроение индекса в автономном режиме иногда может вызвать принудительную проверку кластеризованного индекса (или кучи), при которой данные с несоответствиями в некластеризованном индексе будут заменены правильными данными из кластеризованного индекса или кучи.
Чтобы в качестве источника данных применялся именно кластеризованный индекс или куча, вместо перестроения некластеризованного индекса удалите его и создайте заново. Как и в предыдущих версиях, для устранения несоответствий мы рекомендуем восстанавливать затронутые данные из резервной копии, но иногда несоответствия в некластеризованном индексе удается исправить, перестроив некластеризованный индекс в автономном режиме или создав его заново. Дополнительные сведения см. в разделе DBCC CHECKDB (Transact-SQL).
Автоматическое управление индексами и статистикой
Используйте такие решения, как средство адаптивной дефрагментации индексов, чтобы автоматически управлять дефрагментацией индексов и обновлениями статистики для одной или нескольких баз данных. Эта процедура автоматически выбирает, следует ли перестроить или реорганизовать индекс, сверяясь с уровнем фрагментации и другими параметрами, и обновляет статистику на основе линейных пороговых значений.
Вопросы, связанные с перестроением и реорганизацией индексов columnstore
Автоматическое перестроение всех некластеризованных индексов rowstore в таблице происходит в следующих случаях:
- при создании кластеризованного индекса в таблице, в том числе при повторном создании кластеризованного индекса с другим ключом в операции CREATE CLUSTERED INDEX . WITH (DROP_EXISTING = ON) ;
- удаление кластеризованного индекса, в результате которого таблица сохраняется как куча.
В следующих ситуациях автоматического перестроения всех некластеризованных индексов rowstore в таблице не происходит:
- перестроение кластеризованного индекса;
- изменение хранилища для кластеризованного индекса, например применение схемы секционирования или перемещение кластеризованного индекса в другую файловую группу.
Индекс нельзя реорганизовать или перестроить, если файловая группа, в которой он находится, не подключена к сети или доступна только для чтения. Если указано ключевое слово ALL, а один или несколько индексов размещены в файловой группе, которая находится в автономном режиме или доступна только для чтения, эта инструкция завершается ошибкой.
При перестроении индекса на физическом носителе должно быть достаточно места для хранения двух копий индекса. После завершения перестроения ядро СУБД удаляет исходный индекс.
При указании ключевого слова ALL в инструкции ALTER INDEX . REORGANIZE для таблицы выполняется реорганизация кластеризованных и некластеризованных индексов, а также XML-индексов.
Перестроение или реорганизация малых индексов rowstore не всегда позволяет снизить уровень фрагментации. Вплоть до SQL Server 2014 (12.x), sql Server ядро СУБД выделяет пространство с помощью смешанных экстентов. Поэтому страницы небольших индексов иногда хранятся в нескольких экстентах, что неявным образом делает такие индексы фрагментированными. Смешанные экстенты могут находиться в общем пользовании у восьми объектов, поэтому фрагментацию в малом индексе нельзя уменьшить путем его реорганизации или перестроения.
Вопросы, связанные с перестроением индекса columnstore
При перестроении индекса columnstore ядро СУБД считывает все данные из исходного индекса columnstore, включая разностное хранилище. Данные объединяются в новые группы строк, а группы строк сжимаются в columnstore. Ядро СУБД дефрагментирует columnstore путем физического удаления строк, помеченных как удаленные.
Начиная с SQL Server 2019 (15.x), перемещение кортежей помогает задачей фонового слияния, которая автоматически сжимает более мелкие группы строк разностного хранилища, которые существовали в течение некоторого времени, как определено внутренним пороговым значением, или объединяет сжатые группы строк, в которых было удалено большое количество строк. Со временем это повышает качество индекса columnstore. Дополнительные сведения о терминах и понятиях columnstore см. в статье «Общие сведения об индексах Columnstore».
Перестраивайте секцию, а не всю таблицу
Если индекс велик, то перестроение всей таблицы занимает много времени и на диске должно хватать места для сохранения полной копии индекса на время перестроения.
Для секционированных таблиц не требуется перестраивать весь индекс columnstore, если фрагментация есть только в некоторых секциях, например в тех секциях, где операции UPDATE , DELETE или MERGE затронули большое количество строк.
Перестроение секции после загрузки или изменения данных гарантирует, что все данные в columnstore хранятся в сжатых группах строк. Когда в процессе загрузки данные вставляются в секцию пакетами, размер которых не превышает 102 400 строк, такая секция может иметь в разностном хранилище несколько открытых групп строк. Перестроение позволяет переместить все строки разностного хранилища в сжатые группы строк в columnstore.
Вопросы, связанные с реорганизацией индекса columnstore
При реорганизации индекса columnstore ядро СУБД сжимает каждую закрытую группу строк в разностном хранилище в columnstore в виде сжатой группы строк. Начиная с SQL Server 2016 (13.x) и в База данных SQL Azure команда REORGANIZE выполняет следующие дополнительные оптимизации дефрагментации в Сети:
- Физически удаляет строки из группы строк, если логически удалено 10 % или более строк. Например, если сжатая группа строк из 1 миллиона строк содержит 100 000 строк, ядро СУБД удаляет удаленные строки и повторно сжимает группу строк с 900 000 строк, уменьшая объем хранилища.
- Объединяет одну или несколько сжатых групп строк, чтобы увеличить среднее число строк в группах строк, вплоть до максимального значения 1 048 576 строк. Например, если при операции массовой вставки добавляется пять пакетов по 102 400 строк каждый, вы получите пять сжатых групп строк. Операция REORGANIZE позволяет объединить все эти группы строк в одну сжатую группу размером 512 000 строк. Предполагается отсутствие ограничений на размер словаря или объем памяти.
- Ядро СУБД пытается объединить группы строк, в которых 10% или более строк были помечены как удаленные с другими группами строк. Предположим, что сжатая группа строк 1 содержит 500 000 строк, а сжатая группа строк 21 содержит 1 048 576 строк. В группе строк 21 помечаются как удаленные 60 % строк, после чего в ней остается всего 409 830 строк. Ядро СУБД предпочитает объединять эти две группы строк для сжатия новой группы строк с 909 830 строками.
После нескольких загрузок данных в разностном хранилище может находиться несколько небольших групп строк. Вы можете применить ALTER INDEX REORGANIZE , чтобы принудительно передать эти группы строк в columnstore, а затем объединить малые сжатые группы строк в большие сжатые группы строк. Операция реорганизации также приведет к удалению строк, которые были помечены как удаленные в columnstore.
Реорганизация индекса columnstore с помощью Management Studio объединяет сжатые группы строк вместе, но не принудительно сжимает все группы строк в columnstore. В columnstore будут сжаты только закрытые группы строк, но не открытые. Чтобы принудительно сжать все группы строк, используйте пример Transact-SQL, включающий COMPRESS_ALL_ROW_GROUPS = ON .
Что нужно оценить перед началом обслуживания индекса
Обслуживание индекса, для которого применяется метод реорганизации или перестроения, требует много ресурсов. Это приводит к значительному увеличению нагрузки на ЦП, используемой памяти и операций ввода-вывода в хранилище. При этом в зависимости от рабочей нагрузки базы данных и других факторов предоставляемые обслуживанием преимущества могут варьировать от жизненно важных до несущественных.
Чтобы избежать ненужного использования ресурсов, что может негативно влиять на рабочие нагрузки запросов, корпорация Майкрософт рекомендует не применять обслуживание индекса без предварительной оценки. Следует опытным путем оценить повышение производительности от обслуживания индексов для каждой рабочей нагрузки, используя рекомендуемую стратегию, и сопоставить его с затратами ресурсов и влиянием на рабочую нагрузку, которые потребуются для достижения этих преимуществ.
Вероятность заметного повышения производительности от реорганизации или перестроения индекса будет выше, если этот индекс сильно фрагментирован или имеет низкую плотность страниц. Но это не единственные факторы, которые нужно учитывать. Важную роль могут играть шаблоны запросов (обработка транзакций или аналитика и отчетность), поведение подсистемы хранения, доступный объем памяти и постепенное развитие ядра СУБД.
Решения по обслуживанию индекса следует принимать после оценки нескольких факторов в контексте каждой конкретной рабочей нагрузки, в том числе затрат ресурсов на обслуживание. Нельзя ограничивать критерии выбора фиксированными целевыми значениями фрагментации или плотности страниц.
Положительный побочный эффект от перестроения индекса
Клиенты часто наблюдают улучшения производительности после перестроения индексов. Но во многих случаях эти улучшения не связаны со снижением фрагментации или увеличением плотности страниц.
Перестроение индекса дает еще одно важное преимущество: позволяет обновить статистику по ключевым столбцам индекса, сканируя все строки в индексе. Это эквивалентно операции UPDATE STATISTICS . WITH FULLSCAN , которая позволяет актуализировать статистику и иногда дает более точные данные, чем обычное обновление статистики по ограниченной выборке. При обновлении статистики заново компилируются все планы запросов, которые ее используют. Если прежний план запроса не был оптимальным из-за устаревшей статистики, недостаточного объема выборки для статистики или по любой другой причине, то после повторной компиляции многие планы дают лучшие результаты.
Клиенты часто неправильно полагают, что это улучшение связано с перестроением индекса, которое снизило фрагментацию и увеличило плотность страниц. Но на практике такие же преимущества часто достигаются и менее требовательной к ресурсам операцией обновления статистики вместо перестроения индексов.
Затраты ресурсов на обновление статистики незначительны по сравнению с затратами на перестроение индекса. Эта операция часто завершается за несколько минут, тогда как для перестроения индекса может потребоваться несколько часов.
Стратегия обслуживания индекса
Корпорация Майкрософт рекомендует всем клиентам изучить и применить следующую стратегию обслуживания индексов:
- Не следует полагаться на то, что обслуживание индекса обязательно заметно повысит производительность рабочей нагрузки.
- Измерьте реальное влияние от реорганизации или перестроения индексов на производительность запросов в конкретной рабочей нагрузке. Хранилище запросов — хороший способ сравнить производительность «до обслуживания» и «после обслуживания» по методике тестирования А/Б.
- Если вы заметите, что при перестроении индексов повышается производительность, попробуйте вместо него обновить статистику. Иногда эти методы дают аналогичные улучшения. Если это справедливо для вашей системы, перестроение индексов можно выполнять реже или не выполнять совсем, заменив его периодическим обновлением статистики. Для некоторых видов статистики нужно увеличить долю выборки, используя предложения WITH SAMPLE . PERCENT и WITH FULLSCAN (это редкая ситуация).
- Отслеживайте фрагментацию индекса и плотность страниц с течением времени, чтобы оценить корреляцию между изменением этих значений и производительностью запросов. Если повышение уровня фрагментации или уменьшение плотности страниц снижает производительность до неприемлемого уровня, используйте реорганизацию или перестроение индексов. Часто бывает достаточно применить реорганизацию или перестроение для отдельных индексов, используемых в конкретных запросах, производительность которых ухудшается. Так вы сможете избежать высоких затрат ресурсов на обслуживание каждого индекса в базе данных.
- Определение корреляции между фрагментацией, плотностью страниц и производительностью также поможет выбрать правильную частоту обслуживания индексов. Не следует планировать обслуживание по фиксированному расписанию. Лучше всего постоянно контролировать уровни фрагментации и плотности страниц, чтобы выполнять обслуживание индексов по мере необходимости до неприемлемого снижения производительности.
- Если вы определили, что требуется обслуживание индекса и затраты ресурсов на такое обслуживание допустимы, выполняйте его в периоды низкой нагрузки (если это применимо), учитывая вероятность изменения тенденций по использованию ресурсов с течением времени.
Обслуживание индексов в База данных SQL Azure и Управляемый экземпляр SQL Azure
Помимо описанных выше рекомендаций и стратегий, в База данных SQL Azure и Управляемый экземпляр SQL Azure особенно важно учитывать затраты и преимущества обслуживания индекса. Клиентам следует выполнять его только в том случае, если такая потребность подтверждается фактами, и обязательно с учетом указанных ниже факторов.
- База данных SQL Azure и Управляемый экземпляр SQL Azure реализовать управление ресурсами для установки ограничений на потребление ЦП, памяти и ввода-вывода в соответствии с подготовленной ценовой категорией. Эти ограничения применяются ко всем рабочим нагрузкам пользователей, включая обслуживание индексов. Если совокупное потребление ресурсов всеми рабочими нагрузками приближается к ограничению ресурсов, операция перестроения или реорганизации может снижать производительность других рабочих нагрузок из-за конкуренции за ресурсы. Например, загрузка больших объемов данных может замедлиться, когда на запись в журнал транзакций будет израсходовано 100 % квоты на операции ввода-вывода при перестроении индекса. В Управляемый экземпляр SQL Azure это влияние можно уменьшить, выполнив обслуживание индекса в отдельной группе рабочей нагрузки регулятора ресурсов с ограниченным выделением ресурсов за счет расширения длительности обслуживания индекса.
- Для сокращения затрат клиенты часто подготавливают базы данных, эластичные пулы и управляемые экземпляры с минимальным запасом ресурсов. Ценовая категория выбирается в зависимости от рабочих нагрузок приложений. Чтобы обеспечить достаточные ресурсы для значительно более высокой нагрузки при обслуживании индексов без ухудшения производительности приложения, возможно, потребуются дополнительные подготовленные ресурсы. Это заметно повысит затраты, но не обязательно производительность приложений.
- В эластичных пулах ресурсы совместно используются всеми базами данных в пуле. Даже если конкретная база данных бездействует, обслуживание индексов в ней может повлиять на рабочие нагрузки приложений, выполняющиеся одновременно с обслуживанием в других базах данных того же пула. Дополнительные сведения см. в разделе «Управление ресурсами» в плотных эластичных пулах.
- Для большинства типов хранилища, используемых в База данных SQL Azure и Управляемый экземпляр SQL Azure, нет разницы в производительности между последовательным вводом-выводом и случайным вводом-выводом. Это снижает влияние фрагментации индексов на производительность запросов.
- При использовании реплик масштабирования для чтения или георепликации задержка поступления данных в реплики часто увеличивается в период обслуживания индексов в первичной реплике. Если геореплика подготовлена с таким количеством ресурсов, которого недостаточно для обработки возросшего числа операций с журналом транзакций при обслуживании индекса, это приведет к отставанию такой реплики от изменений в первичной реплике. В этом случае потребуется восстановить исходное состояние. При этом реплика станет недоступной до завершения восстановления. Кроме того, на уровнях служб «Премиум» и «Критически важный для бизнеса» используемые для обеспечения высокого уровня доступности реплики также могут отставать от первичной реплики в период обслуживания индекса. Если в этот период или вскоре после него потребуется отработка отказа, она может занять больше времени, чем ожидалось.
- Если в первичной реплике выполняется перестроение индекса и в это же время в доступной для чтения реплике выполняется длительный запрос, этот запрос может быть автоматически прекращен, чтобы предотвратить блокировку потока повтора в этой реплике.
Существуют конкретные, но редкие сценарии, когда может потребоваться однократное или периодическое обслуживание индекса в База данных SQL Azure и Управляемый экземпляр SQL Azure:
- Обслуживание индекса может потребоваться, чтобы увеличение плотности страниц позволило снизить объем используемого базой данных пространства и не превышать предельный размер для используемой ценовой категории. Это позволит избежать перехода на более высокую ценовую категорию с более высоким предельным размером.
- Если необходимо уменьшить файлы, перестройте или переорганизуйте индексы, прежде чем сжатие файлов увеличит плотность страниц. Это ускорит операцию сжатия, так как нужно будет перемещать меньше страниц. Дополнительные сведения см. в следующем разделе:
- Управление файловым пространством для баз данных в базе данных Azure SQL Database
- Управление пространством файлов для баз данных в Управляемый экземпляр SQL Azure
Если вы определили, что обслуживание индекса необходимо для ваших База данных SQL Azure и Управляемый экземпляр SQL Azure рабочих нагрузок, следует либо реорганизовать индексы, либо использовать перестроение индексов в сети. Это позволит запросам рабочей нагрузки использовать таблицы во время перестроения индексов.
Кроме того, выполнение операции в возобновляемом режиме позволит не начинать всю работу заново, если она будет прервана плановой или аварийной отработкой отказа базы данных. Использование возобновляемых операций с индексами особенно важно, если индексы большие.
Операции с индексами в автономном режиме обычно выполняются быстрее, чем с сохранением подключения. Их следует использовать, если в период выполнения операции не потребуется выполнять запросы к таблицам, например после загрузки данных в промежуточные таблицы в рамках последовательного процесса извлечения, преобразования и загрузки.
ограничения
Перестроение индексов rowstore с более чем 128 экстентами осуществляется в два этапа — это логическое и физическое перестроение. На этапе логического перестроения существующие единицы распределения, используемые индексом, помечаются для освобождения, строки данных копируются и сортируются, а затем перемещаются в новые единицы распределения, созданные для хранения перестроенного индекса. На этапе физического перестроения единицы распределения, ранее помеченные для освобождения, физически удаляются посредством выполняемых в фоновом режиме коротких транзакций, и многочисленные блокировки для этого не требуются. Дополнительные сведения об единицах размещения см. в статье Руководство по архитектуре страниц и экстентов.
Инструкция ALTER INDEX REORGANIZE требует, чтобы в файле данных, где содержится индекс, было свободное пространство, потому что операция может выделять временные рабочие страницы только в том же файле (а не в другом файле файловой группы, к примеру). Во время операции реорганизации пользователь может столкнуться с ошибкой 1105: Could not allocate space for object ‘###’ in database ‘###’ because the ‘###’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup , даже если в файловой группе достаточно места (например, если закончилось место для файла данных).
Индекс нельзя реорганизовать, если для ALLOW_PAGE_LOCKS задано состояние OFF.
До SQL Server 2017 (14.x), перестроение кластеризованного индекса columnstore — это автономная операция. При перестроении ядро СУБД необходимо получить монопольную блокировку таблицы или секции. Данные находятся в автономном режиме и недоступны во время перестроения, даже при использовании NOLOCK изоляции моментальных снимков с фиксацией для чтения (RCSI) или изоляции моментальных снимков. Начиная с SQL Server 2019 (15.x), кластеризованный индекс columnstore можно перестроить с помощью ONLINE = ON параметра.
Создание и перестройка невыровненных индексов для таблицы, количество секций в которой превышает 1000, возможны, но не поддерживаются. Это может привести к снижению производительности или чрезмерному потреблению памяти во время таких операций. Если количество секций превышает 1000, рекомендуется использовать только выровненные индексы.
Ограничения статистики
- Когда создается или перестраивается индекс, для него создается и обновляется статистика по данным из всех строк в таблице. Это эквивалентно использованию предложения FULLSCAN в CREATE STATISTICS или UPDATE STATISTICS . Однако начиная с SQL Server 2012 (11.x) при создании или перестроении секционированного индекса статистика не создается или обновляется путем сканирования всех строк в таблице. Вместо этого используется коэффициент выборки по умолчанию. Чтобы создать или обновить статистику секционированных индексов путем сканирования всех строк таблицы, используйте инструкции CREATE STATISTICS или UPDATE STATISTICS с предложением FULLSCAN .
- Аналогичным образом, когда возобновляется операция создания или перестроения индекса, статистика создается или обновляется с коэффициентом выборки по умолчанию. Если статистика создана или последний раз обновлена со значением ON для предложения PERSIST_SAMPLE_PERCENT , возобновляемые операции с индексами будут использовать для создания или обновления статистики сохраненный коэффициент выборки.
- Когда индекс реорганизуется, статистика не обновляется.
Примеры
Проверка фрагментации и плотности страниц индекса rowstore с помощью Transact-SQL
В приведенном ниже примере определяется средняя фрагментация и плотность страниц для всех индексов rowstore в текущей базе данных. Здесь используется режим SAMPLED для быстрого получения применимых на практике результатов. Для получения более точных результатов используйте режим DETAILED . Он потребует сканирования всех страниц индекса, что может занять много времени.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name, OBJECT_NAME(ips.object_id) AS object_name, i.name AS index_name, i.type_desc AS index_type, ips.avg_fragmentation_in_percent, ips.avg_page_space_used_in_percent, ips.page_count, ips.alloc_unit_type_desc FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips INNER JOIN sys.indexes AS i ON ips.object_id = i.object_id AND ips.index_id = i.index_id ORDER BY page_count DESC;Предыдущая инструкция возвращает результирующий набор, как показано ниже.
schema_name object_name index_name index_type avg_fragmentation_in_percent avg_page_space_used_in_percent page_count alloc_unit_type_desc ------------ --------------------- ---------------------------------------- ------------- ---------------------------- ------------------------------ ----------- -------------------- dbo FactProductInventory PK_FactProductInventory CLUSTERED 0.390015600624025 99.7244625648629 3846 IN_ROW_DATA dbo DimProduct PK_DimProduct_ProductKey CLUSTERED 0 89.6839757845318 497 LOB_DATA dbo DimProduct PK_DimProduct_ProductKey CLUSTERED 0 80.7132814430442 251 IN_ROW_DATA dbo FactFinance NULL HEAP 0 99.7982456140351 239 IN_ROW_DATA dbo ProspectiveBuyer PK_ProspectiveBuyer_ProspectiveBuyerKey CLUSTERED 0 98.1086236718557 79 IN_ROW_DATA dbo DimCustomer IX_DimCustomer_CustomerAlternateKey NONCLUSTERED 0 99.5197553743514 78 IN_ROW_DATAПроверка фрагментации индекса columnstore с помощью Transact-SQL
В приведенном ниже примере определяется средняя фрагментация для всех индексов columnstore со сжатыми группами строк в текущей базе данных.
SELECT OBJECT_SCHEMA_NAME(i.object_id) AS schema_name, OBJECT_NAME(i.object_id) AS object_name, i.name AS index_name, i.type_desc AS index_type, 100.0 * (ISNULL(SUM(rgs.deleted_rows), 0)) / NULLIF(SUM(rgs.total_rows), 0) AS avg_fragmentation_in_percent FROM sys.indexes AS i INNER JOIN sys.dm_db_column_store_row_group_physical_stats AS rgs ON i.object_id = rgs.object_id AND i.index_id = rgs.index_id WHERE rgs.state_desc = 'COMPRESSED' GROUP BY i.object_id, i.index_id, i.name, i.type_desc ORDER BY schema_name, object_name, index_name, index_type;Предыдущая инструкция возвращает результирующий набор, как показано ниже.
schema_name object_name index_name index_type avg_fragmentation_in_percent ------------ ---------------------- ------------------------------------ ------------------------- ---------------------------- Sales InvoiceLines NCCX_Sales_InvoiceLines NONCLUSTERED COLUMNSTORE 0.000000000000000 Sales OrderLines NCCX_Sales_OrderLines NONCLUSTERED COLUMNSTORE 0.000000000000000 Warehouse StockItemTransactions CCX_Warehouse_StockItemTransactions CLUSTERED COLUMNSTORE 4.225346161484279Обслуживание индексов с помощью SQL Server Management Studio
Реорганизация или перестроение индекса
- В обозреватель объектов разверните базу данных, содержащую таблицу, в которой требуется реорганизовать индекс.
- Разверните папку Таблицы.
- Разверните таблицу, в которой нужно реорганизовать индекс.
- Разверните папку Индексы.
- Щелкните правой кнопкой мыши индекс, который требуется реорганизовать, и выберите пункт Реорганизовать.
- В диалоговом окне «Реорганизовать индексы» убедитесь, что правильный индекс находится в индексах для реорганизации сетки и нажмите кнопку «ОК«.
- Установите флажок Сжать данные в столбцах больших объектов , чтобы указать, что также сжимаются все страницы, содержащие данные больших объектов.
- Нажмите ОК.
Реорганизация всех индексов в таблице
- В обозреватель объектов разверните базу данных, содержащую таблицу, в которой требуется реорганизовать индексы.
- Разверните папку Таблицы.
- Разверните таблицу, в которой нужно реорганизовать индексы.
- Щелкните правой кнопкой мыши папку Индексы и выберите команду Реорганизовать все.
- В диалоговом окне Реорганизация индексов убедитесь, что нужные индексы приведены в сетке Индексы для реорганизации. Для удаления индекса из сетки Индексы для реорганизации выделите индекс и нажмите клавишу DELETE.
- Установите флажок Сжать данные в столбцах больших объектов , чтобы указать, что также сжимаются все страницы, содержащие данные больших объектов.
- Нажмите ОК.
Обслуживание индексов с помощью Transact-SQL
Дополнительные примеры использования Transact-SQL для перестроения или реорганизации индексов см. в статье ALTER INDEX Examples — Rowstore Indexes и ALTER INDEX Examples — Columnstore Indexes.
Реорганизация индекса
В приведенном ниже примере показано, как реорганизовать индекс IX_Employee_OrganizationalLevel_OrganizationalNode в таблице HumanResources.Employee базы данных AdventureWorks2022 .
ALTER INDEX IX_Employee_OrganizationalLevel_OrganizationalNode ON HumanResources.Employee REORGANIZE;В приведенном ниже примере показано, как реорганизовать индекс columnstore IndFactResellerSalesXL_CCI в таблице dbo.FactResellerSalesXL_CCI базы данных AdventureWorksDW2022 . Эта команда заставляет все закрытые и открытые группы строк в columnstore.
-- This command forces all closed and open row groups into columnstore. ALTER INDEX IndFactResellerSalesXL_CCI ON FactResellerSalesXL_CCI REORGANIZE WITH (COMPRESS_ALL_ROW_GROUPS = ON);Реорганизация всех индексов в таблице
В приведенном ниже примере показано, как реорганизовать все индексы в таблице HumanResources.Employee базы данных AdventureWorks2022 .
ALTER INDEX ALL ON HumanResources.Employee REORGANIZE;Перестроение индекса
В следующем примере показано, как перестроить единственный индекс на таблице Employee базы данных AdventureWorks2022 .
ALTER INDEX PK_Employee_BusinessEntityID ON HumanResources.Employee REBUILD ;Перестроение всех индексов в таблице
В приведенном ниже примере показано, как перестроить все индексы, связанные с таблицей базы данных AdventureWorks2022 , используя ключевое слово ALL . Указываются три параметра.
ALTER INDEX ALL ON Production.Product REBUILD WITH (FILLFACTOR = 80, SORT_IN_TEMPDB = ON, STATISTICS_NORECOMPUTE = ON) ;Подробные сведения см. в статье ALTER INDEX (Transact-SQL).
Следующие шаги
- Руководство по архитектуре и разработке индексов SQL Server
- Выполнение операций с индексами в оперативном режиме
- ALTER INDEX (Transact-SQL)
- Адаптивная дефрагментация индексов
- CREATE STATISTICS (Transact-SQL)
- UPDATE STATISTICS (Transact-SQL)
- Производительность запросов индексов columnstore
- Начало работы с Columnstore для получения операционной аналитики в реальном времени
- Индексы сolumnstore для хранилищ данных
- Индексы columnstore и политика слияния для групп строк
Записки IT специалиста
Тестирование и исправление информационной базы — что делает и для чего нужно
- Автор: Уваров А.С.
- 22.05.2021
Существуют вещи настолько привычные, что кажется все про них знают, но это весьма обманчивое впечатление. Да, о них почти все знают, почти все используют, но мало кто представляет происходящие при этом процессы, скрытые за привычной внешней формой инструмента. При этом те, кто знает не спешат делиться, ведь это «общеизвестно», а те, кто не знает стесняются спросить по той же самой причине. Но мы не будем стесняться, а подробно расскажем о том, что делает каждая опция данного инструмента, заглянув каждый раз немного глубже простого описания.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Давно известно: как вы лодку назовете — так она и поплывет. Это в полной мере применимо к такому известному инструменту как Тестирование и исправление информационной базы, название выбрано крайне неудачно, так как предполагает, что использовать представленные в нем возможности следует при возникновении проблем с информационной базой и исправлении ошибок. На самом деле это не так. Любой имеющий опыт работы с «серьезными» СУБД найдет в этом списке привычные ему инструменты обслуживания баз данных, которые следует применять регулярно для поддержания высокой производительности сервера. Но речь сейчас не о них, а о начинающих, либо имеющих к 1С опосредованное отношение.
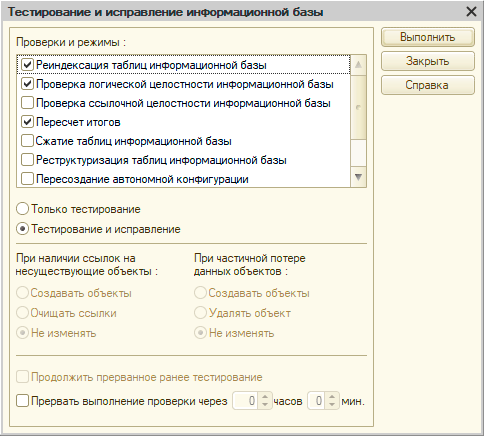
Описание этой таблички можно найти много где, но в большинстве случаем там будут стандартные абзацы вроде:
Проверка логической целостности информационной базы проверяет и исправляет логические ошибки в структурах таблиц
Что это за ошибки, откуда они берутся, чем чреваты? Кто в теме — тот знает, а кто нет? Спросить? Да как бы неудобно, это же все знают. Вот и сводится большинство «знания» к тому, как правильно расставить в этой форме галочки и не забыть перед этим обязательно сделать резервную копию, а то мало ли.
Поэтому давайте разбираться, мы специально упростили многие вопросы, постаравшись сделать их понятными даже тем, кто имеет смутное представление о структуре и принципах работы баз данных.
Реиндексация таблиц информационной базы
Начнем с того, что такое индексы и для чего они нужны. Если рассматривать базу данных логически — то это некая совокупность связанных друг с другом таблиц, которые в свою очередь содержат какие-либо данные. Физически таблицы хранятся на диске в виде страниц и чем больше размер таблицы, тем большее количество страниц она будет содержать.
Допустим у нас есть некая таблица и мы хотим получить из нее все данные, связанные с фамилией Иванов. Для этого программе нужно последовательно считать все страницы, принадлежащие данной таблице и найти в них записи, соответствующие запросу.
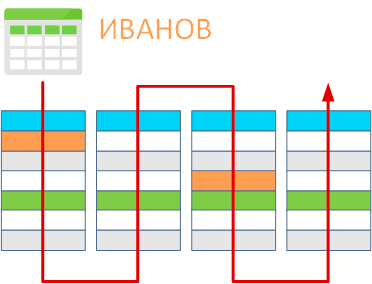
Но ведь это чудовищно неэффективно, скажет внимательный читатель и будет прав. Что же делать? К счастью, все уже давно придумано. Хранение данных в СУБД можно сравнить с библиотекой, где таблицы — это залы библиотеки, а страницы — стеллажи. И когда вам нужна какая-то книга библиотекарь ведь не обходит физически все стеллажи, а сразу идет куда надо и приносит вам то, что вы просили. Чтобы быстро искать книги в библиотеках существуют каталоги, где книги перечислены в упорядоченном виде, и каждая карточка содержит сведения о том, где именно хранится тот или иной экземпляр.
В нашем случае роль такого каталога выполняет индекс. Это — специальный набор записей, связанный с определенным ключом — полем таблицы, в нашем случае фамилией, и указывающий на каких страницах хранятся интересующие записи. После того как мы создали индекс программе больше не нужно последовательно считывать всю таблицу, потому что известно, что записи, связанные с ключом Иванов, хранятся только на первой и третьей страницах.
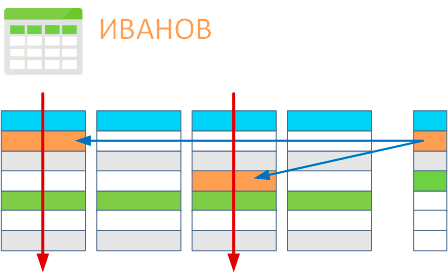
По мере работы с программой эффективность индексов снижается, особенно если вы активно удаляли или добавляли данные. Также индексы могут подвергаться фрагментации. Если снова сравнить с библиотекой, то за день работы посетители перепутали несколько ящиков, а работники библиотеки карточки новых книг поставили в конец и забыли убрать отсутствующие. Но все равно поиск по такому каталогу окажется быстрее, чем обход всех стеллажей в зале. А что нужно сделать, чтобы вернуть поиску прежнюю эффективность? Правильно, навести порядок в каталоге. Именно этим и занимается реиндексация, которая заново формирует индексы таблиц базы данных и устраняет их фрагментацию, что важно, если вы используете обычные жесткие диски или недорогие SSD.
Реиндексация — это простой и достаточно недорогой способ повысить эффективность работы с информационной базой, причем эффект может быть виден сразу, особенно в файловых базах. Поэтому реиндексацию делать нужно и желательно регулярно, включив ее в обязательный план регламентного обслуживания информационных баз.
Проверка логической целостности информационной базы
Если говорить о СУБД, то любая система управления базами данных, в том числе и та, которая используется файловой версией 1С, обеспечивает целостность данных встроенными средствами и вам вряд ли придется заниматься этим вопросом, если только, конечно, не произошло физического повреждения базы данных. Как мы уже говорили выше, база данных — это набор взаимосвязанных таблиц и самой СУБД в общем то все равно что мы храним в этих таблицах, для нее таблица Документа ничем не отличается от таблицы Справочника, кроме состава полей.
Но на уровне информационной базы 1С существует совсем иной набор объектов: Справочники, Документы, Регистры сведений и накопления и т.д. и т.п. При этом они связаны определенной внутренней логикой. Так элементы справочника могут иметь иерархическую структуру, являться подчиненными для другого справочника, а документы быть основанием для других документов, формировать проводки, записи регистров и т.д. и т.п. В процессе работы данная логика может быть нарушена, как по причине ошибок в программе, так и в результате некоторых действий пользователя.
Давайте рассмотрим следующую схему, отражающую некоторый набор бизнес-логики. У нас есть два документа: Реализация и Оплата, которые делают движения по некоторым регистрам. Так при реализации мы списываем нужное количество товара со склада и вносим в регистр взаиморасчетов задолженность покупателя. В момент оплаты мы вносим полученную сумму в регистр денежных средств и закрываем задолженность покупателя по отгрузке полностью или частично. Но как мы определим, какую именно задолженность погасил клиент? А для этого мы введем в документе оплата обязательное поле Основание, в котором будем указывать нужную реализацию.
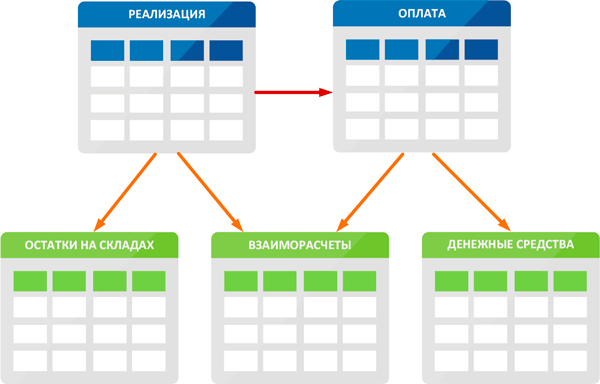
При этом документ Оплата будет являться подчиненным к документу Реализация и в случае его отмены также должен быть отменен, так как перестает существовать основание для оплаты. Теперь представим, что в результате какой-то нештатной ситуации или некорректных действий пользователя у нас в документе Оплата пропала ссылка на документ основание, т.е. нарушилась структура подчиненности. Найти такую ошибку будет не так-то просто. Потому что все записи в базе данных останутся, и каждая из них по отдельности будет верная. Так правильным останется количество товаров на складах и суммы денежных средств предприятия, а вот взаиморасчеты враз станут неверны.
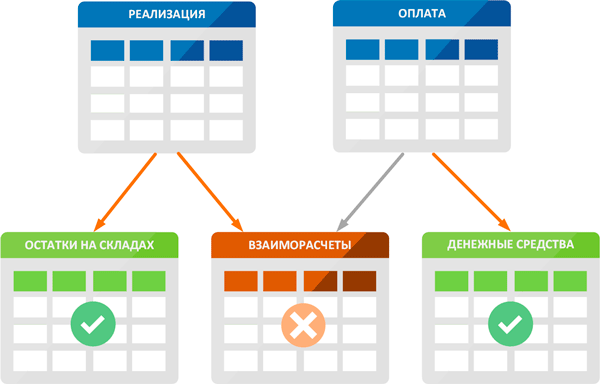
Внешне это может проявляться так: отчеты по реализациям и оплатам от контрагента совпадают, а вот отчет по взаиморасчетам или акт сверки формируется неправильно. При этом вы можете раз за разом пересчитывать суммы руками, все будет сходиться, но отчет снова и снова будет давать неверный результат.
Поэтому во всех подобных случаях, когда отчеты показывают неверные результаты или не сходятся друг с другом, следует запускать проверку логической целостности. Но не следует ожидать от нее какого-либо чуда, потому что она способна исправить только некоторые, самые очевидные ошибки (проводка без регистратора, неверный родитель элемента справочника и т.д.), в остальных случаях потребуется анализ ситуации и ручное исправление обнаруженных проблем. При этом нарушение логической целостности очень часто бывает связано с нарушением ссылочной целостности, о которой мы поговорим ниже.
Как часто нужно запускать эту проверку? Время от времени, особенно в файловых базах с обязательным изучением лога проверки, чем раньше вы узнаете о возможных проблемах в структуре данных и устраните их — тем лучше.
Проверка ссылочной целостности информационной базы
Данная проверка является одним из вариантов проверки логической целостности базы и выявляет проблемы со ссылками на отсутствующие элементы базы данных. Как мы уже говорили, база — это набор связанных между собой таблиц. В одной из них мы можем хранить контрагентов, в другой номенклатуру, в третьей — список складов, а внося запись о реализации товаров просто делаем ссылки на нужные элементы других таблиц. Например, наш условный документ Реализация может ссылаться на справочники Контрагенты, Номенклатура, Склады, выбирая и указывая в документе соответствующие значения мы не создаем дополнительных записей в таблице реализации, а даем ссылки на элементы связанных таблиц.
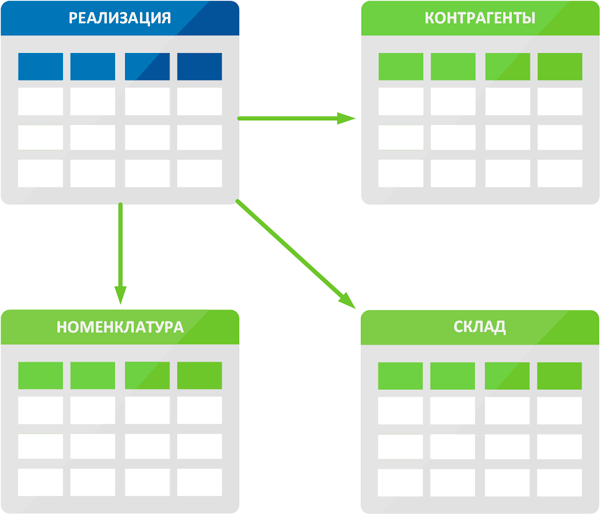
Контроль ссылочной целостности является подмножеством контроля логической целостности и осуществляется на уровне конфигурации. С ним сталкивался каждый, кто пытался удалить какой-либо объект их базы, а в ответ получал сообщение, что это невозможно, так как данный объект используется и приводился список мест использования.
Но что будет, если используемый объект все-таки удалить? Возникнет битая ссылка. Внешне она выглядит как запись со ссылкой на уникальный идентификатор отсутствующего объекта:
(95:bc09ecd68a04705d11eb44а671518376)Если подходить с чисто теоретических позиций, то битых ссылок в информационной базе быть не должно. Но не все так просто, если в базе используется РИБ, либо иные технологии обмена с другими базами и внешними источниками, то ряд второстепенных реквизитов может не передаваться. Например, сведения о подключаемом оборудовании.
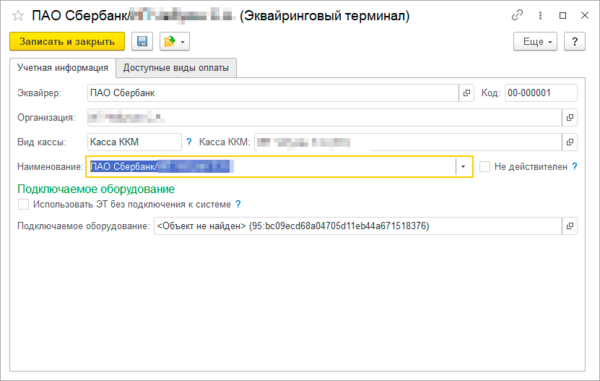
В данном случае это нормально (Конфигурация Розница 2.3), так как конкретный экземпляр оборудования подключен именно к конкретному рабочему месту и передавать эти данные куда-то еще лишено особого смысла.
Но чаще к этой ошибке приводит повреждение базы или некорректные действия пользователя, скажем, удалившего объекты без контроля ссылочной целостности. В любом случае появление битых ссылок — это серьезный симптом и повод для отдельного разбирательства, рубить с плеча здесь неуместно. Поэтому сами разработчики при активации этой проверки переводят ее в безопасный режим, устанавливая действие Не изменять, по сути проверка лишь проинформирует вас о наличии битых ссылок, не более.
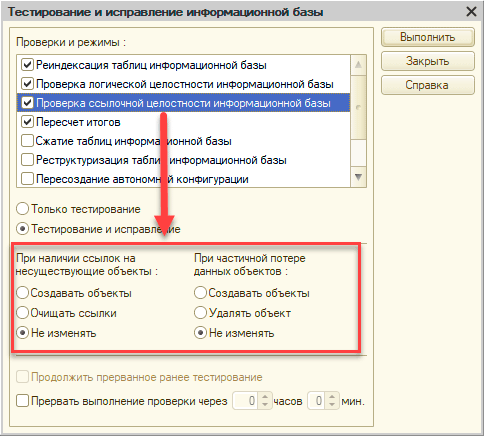
А вот после, установив сам факт их наличия следует думать. В ряде случаев, если выявленные ссылки являются второстепенными объектами подчиненных баз не нужно делать ничего. Наоборот, любая попытка «исправления» может привести к нарушению нормальной работы информационной базы. А вот в других надо предпринимать какие-либо действия.
Давайте посмотрим какие варианты у нас есть. Начнём со ссылок на несуществующие объекты. Здесь все довольно просто, мы можем или очистить ссылку, или создать новый объект нужного типа. Допустим, если запись справочника Номенклатура оказалась повреждена, но мы точно знаем по бумажным документам, что именно реализовывали, то ставим Создавать объекты, после чего переходим к ним и заполняем нужные реквизиты. Если же это какой-то второстепенный реквизит, то можем просто очистить ссылки. Второй вариант довольно часто применяется в тех случаях, когда надо быстро почистить базу и ряд объектов удаляется без контроля ссылочной целостности.
Теперь о частичной потере данных объектов. К ним могут относиться элемент подчиненного справочника без владельца или движение без регистратора. Мы можем либо удалить такие объекты, либо создать связанные с ними. Чаще всего такие объекты имеет смысл удалять, особенно если это движения, хотя если это элемент справочника, владелец которого потерян, то в ряде случаев имеет смысл создать владельца.
Внимание! Перед любыми исправлениями ссылочной целостности в базе обязательно создайте резервную копию. Помните, что данная операция необратима и может привести к полной или частичной потере данных!
Но даже имея показания к исправлению некоторых битых ссылок следует иметь ввиду, что данный инструмент применит выбранное действие ко всем ссылкам без разбора, что во многих случаях неприемлемо. Поэтому чаще всего проблему битых ссылок следует решать иными путями, один из них — выгрузка необходимых справочников или документов в XML из резервной копии и загрузка их в целевую базу в тех случаях когда просто восстановиться из бекапа невозможно.
Когда следует запускать эту проверку? В тех случаях, когда в базе не обнаружены битые ссылки или когда проверка логической целостности выявляет ошибки. Но в любом случае первый запуск следует производить с действиями Не изменять, а последующие решения принимать на основании глубокого анализа ситуации.
Пересчет итогов
В составе конфигурации 1С имеются специальные объекты — регистры, которые предназначены для хранения записей в разрезе определенных измерений. Например, регистр сведения Цены хранит сведения о ценах в разрезе измерений Номенклатура и Дата, а регистр накопления Товары хранит сведения об остатках товаров в разрезе Номенклатуры, Вида движения (расход или приход), Количества и Даты.
Начем с более простого, регистров сведения, допустим мы хотим получить действующие цены на определенную дату. Но если мы просто получим записи за этот день, то увидим, что цены менялись только для некоторых позиций номенклатуры, чтобы получить полный набор цен нам надо прочитать записи регистра на неопределенное количество дней назад, пока мы не получим последние цены для каждой позиции номенклатуры. Чтобы этого не делать регистр сведений имеет специальную виртуальную таблицу — СрезПоследних, которая содержит последние актуальные цены на каждый день. Теперь нам достаточно один раз обратиться к этой таблице, чтобы получить нужные сведения на интересующую дату.
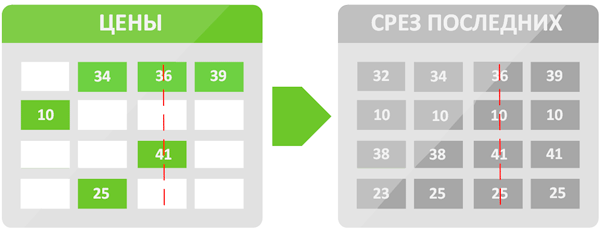
Немного сложнее с регистрами накопления, записи в них содержат только сведения о движениях, скажем, такого-то числа в такое-то время на склад пришло 10 позиций некоторой номенклатуры, затем тем же днем продали 1 шт, потом 3 шт, за ней снова 5 шт и после еще 1 шт. При этом ряд вопросов, которые могут нас интересовать гораздо шире. Нас могут интересовать остатки на произвольный момент времени, либо обороты за некоторый период.
Чтобы не делать глубоких выборок по регистрам накоплений в них предусмотрены виртуальные таблицы Остатки, Обороты, Остатки и обороты. Каждая из них содержит актуальные данные за определенный период, в нашем случае день. И если таблица остатков в особом пояснении не нуждается, то таблица оборотов на нашей схеме может вызвать вопросы, так как ее содержимое полностью совпадает со значениями регистра. На самом деле редко когда регистр содержит единственную запись за день, чаще всего там множество записей движения: утром привезли на склад товар, потом его активно продавали, затем довезли еще немного и продолжили торговлю. При этом таблица обороты отобразит общий оборот за период.
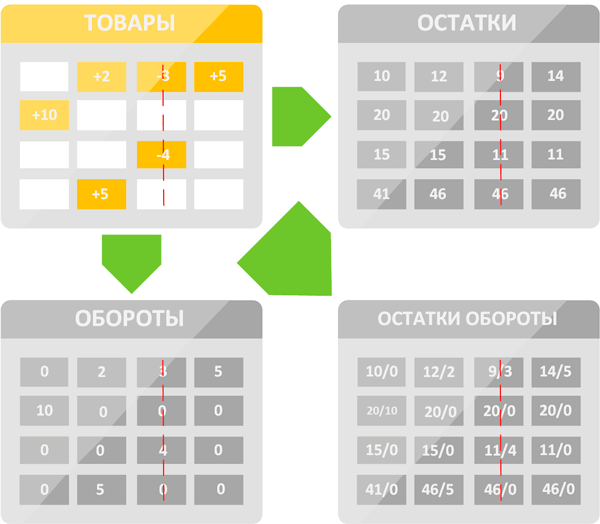
Собственно, как и индексы, итоги предназначены для ускорения получения данных из информационной базы, теперь вам не нужно считывать весь или почти весь регистр, чтобы получить данные на определенный момент времени, достаточно обратиться к одной из виртуальных таблиц. Но со временем итоги тоже начинают терять эффективность: в них могут накапливаться мусорные записи, они могут фрагментироваться. Пересчет итогов решает эту проблему, заново создавая нужные виртуальные таблицы.
Пересчет итогов, как и реиндексация, простой и эффективный способ поддержания производительности информационной базы. Следует выполнять его регулярно в рамках обслуживания, а также каждый раз после исправления ошибок логической или ссылочной целостности.
Сжатие таблиц информационной базы
По мере работы информационной базы объем добавляемых в нее данных растет, вместе с ним растет и объем файла (файлов) базы данных. Но если мы удалим из базы часть информации, то объем файла базы данных не уменьшится, просто некоторые страницы будут помечены как пустые и снова доступные для записи. Если мы хотим уменьшить физически занимаемый объем, то следует произвести операцию сжатия таблиц информационной базы. В этом случае база переместит текущие данные на место освободившихся страниц, а затем уменьшит файл базы данных на объем освободившегося пространства.
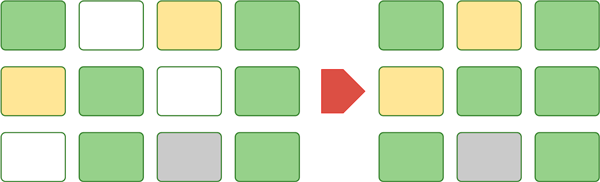
Какой практический смысл этой операции? Да особо никакого, фрагментация данных от этого не уменьшится, а скорее всего даже увеличится. Единственный смысл сжатия базы — это если вы удалили из нее значительный объем данных и теперь просто оптимизируете общее занимаемое место.
Когда следует выполнять данное действие? Только если вы удалили из базы значительный объем данных, ну или если размер файла базы для вас критичен.
Реструктуризация таблиц информационной базы
Если реиндексация только перестраивала индексы, то реструктуризация полностью перестраивает содержимое базы данных, для каждой таблицы создается копия и записывается в отдельное место на диске, затем вся база данных полностью замещается копией. В чем смысл этого действия? Фактически мы произвели дефрагментацию базы данных, если ранее данные таблицы могли быть разбросаны по диску, то теперь они будут расположены последовательно.
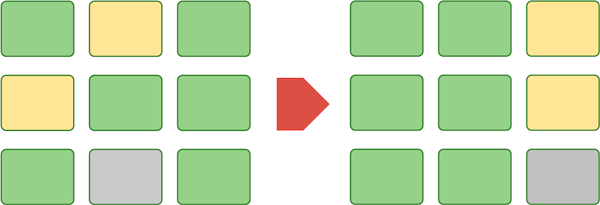
Есть ли в этом практический смысл? В общем и целом, нет, чтение из страниц таблицы носит преимущественно случайный характер, последовательно считывание все таблицы — это уже ошибка построителя запросов. Но реструктуризация все-таки имеет смысл, скажем если вы добавили в базу собственный набор реквизитов или обновили релиз конфигурации (в этом случае реструктуризация будет выполнена автоматически). В любом случае лучше, чтобы связанные данные лежали рядом. Но следует понимать, что в процессе реструктуризации придется переместить весь объем информационной базы, а это может занять весьма продолжительное время.
И как раз-таки после реструктуризации будет уместно выполнить сжатие. Так как данные перемещать уже не надо, а пустое пространство уже сосредоточено в одном месте.
Как часто следует запускать? По необходимости, в том случае если вы изменили набор метаданных.
Пересоздание автономной конфигурации
Достаточно специфическая функция и относится к мобильному клиенту с возможностью автономной работы. Потеряв связь с основной базой данных такой клиент переключается в автономный режим и начинает использовать автономную конфигурацию. Если в данном режиме автономный клиент ведет себя неадекватно, то автономную конфигурацию следует пересоздать.
Проверка логической целостности расширений конфигурации
Не так давно фирма 1С добавила еще один способ доработки конфигураций — расширения. Основное их преимущество, что нет необходимости править код основной конфигурации или снимать ее с поддержки. Но современные расширения позволяют добавлять в базу новые реквизиты, справочники, документы, регистры и организовывать логические связи между ними.
Данная проверка аналогична проверке логической целостности, только с учетом подключенных расширений, которых может быть и не одно. Если вы используете расширения, то обязательно включайте данную проверку вместе с проверкой логической целостности.
Заключение
По умолчанию фирма 1С предлагает достаточно сбалансированный набор действий: реиндексация и пересчет итогов благотворно влияют на производительность, а проверка логической целостности позволяет на ранних этапах выявить возможные проблемы. Если вы используете расширения, то добавьте туда проверку логической целостности расширений.
Остальные проверки и действия следует выполнять только при наличии необходимости. Так обнаружив ошибки в логической целостности следует выполнить проверку ссылочной целостности, а существенно изменив структуру базы данных имеет смысл выполнить реструктуризацию.
Надеемся, что данный материал окажется вам полезен, а также поможет по-новому взглянуть и глубже понять привычные действия.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:


Или подпишись на наш Телеграм-канал:
Как правильно настроить MS SQL Server для “1С”: планы обслуживания
Часто неопытные системные администраторы подразумевают перевод базы “1С” в клиент-серверный режим работы как панацею, избавляющую от всех проблем и ускоряющую “1С” во много раз. Однако, без правильной настройки, мониторинга и регулярного обслуживания базы “1С” в клиент-серверном режиме начинают работать еще “медленнее”, чем в файловом. В рамках этой статьи рассмотрим оптимальную настройку своевременных регламентных операций на уровне самой СУБД MS MSQL. Крайне важно выполнять регламентное обслуживание в системах под значительной нагрузкой, где работают больше 10-ти пользователей, ведь в подобных системах обычных действий (выполняемых СУБД MS SQL) становится недостаточно для эффективной работы.
Планы обслуживания/Maintenance Plan в MS SQL Server
Итак, “Сервер 1С:Предприятие” и SQL Server установлены и настроены, базы перенесены, пользователи работают. Ускорение “1С” и комфорт в работе получен. Но, с течением времени документы начинают открываться медленнее, подбор номенклатуры “зависает”, а отчеты формируются “целую вечность”. Чтобы этого избежать, следует настроить и автоматизировать регламентные процедуры по обслуживанию базы в SQL Server.
Вообще, планы обслуживания нужно подстраивать под конкретное оборудование и базы данных. Оставим это на усмотрение профессионалов администрирования баз данных. В общем случае, для базы данных не более 200 Гб в MS SQL Server рекомендуется выполнять следующие регламентные операции:
- Проверка целостности базы данных
- Реорганизация индекса/Восстановить индекс
- Обновление статистики
Рекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
Проверка целостности базы данных/DBCC CHECKDB
Периодичность: 1 раз в неделю.
Время запуска: в технологическом окне – во время минимальной нагрузки.
Как настроить: Microsoft SQL Server Management Studio – “Управление” – “Планы обслуживания” – правой кнопкой мыши “Мастер планов обслуживания”.
Имя – можно заполнить на свое усмотрение, например “Проверка целостности базы данных” или “CheckDB”. Для настройки расписания запуска проверки – кнопка “Изменить”. Выполняется – еженедельно; повторять – каждое воскресенье. Однократное задание, например, в 01:00.
При выборе задач по обслуживанию устанавливаем флаг “Проверка целостности базы данных”.

Выбираем необходимые базы данных для обслуживания: либо какую-то определенную, либо несколько, либо все пользовательские.
Если настройка прошла без ошибок, выйдет сообщение об успешной проверке.
Реорганизация индекса/Восстановить индекс
Что такое индексы? Индексы – это структурированные данные, которые ускоряют процесс запроса, предоставляя быстрый доступ к строкам данных в таблице, аналогично предметному указателю или оглавлению в книгах. Индексы составляют больше половины объема большинства баз “1С”. Для каждого индекса обязательно хранится его статистика.
MS SQL Server самостоятельно создает и изменяет индексы при работе с базой. С течением времени данные в индексе становятся фрагментированными, т.е. разбросанными по базе данных. Существенно фрагментированные индексы могут серьезно снижать производительность запросов и служить причиной замедления работы базы. Если фрагментация составляет от 5 до 30%, то рекомендуется ее устранить с помощью реорганизации, при фрагментации свыше 30% необходимо полное перестроение индексов.
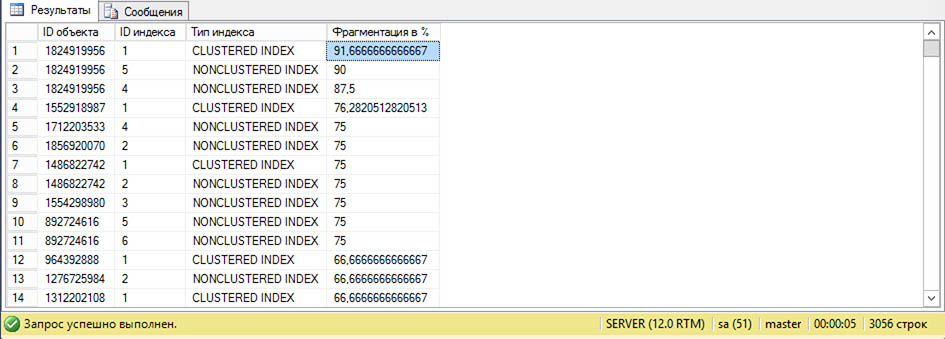
В простейшем случае получить информацию по фрагментации индексов можно с помощью кода:
DECLARE @db_id SMALLINT; SET @db_id = DB_ID(N'MyBaseSQL'); IF @db_id IS NULL BEGIN; PRINT N'Неправильное имя базы'; END; ELSE BEGIN; SELECT object_id AS [ID объекта], index_id AS [ID индекса], index_type_desc AS [Тип индекса], avg_fragmentation_in_percent AS [Фрагментация в %] FROM sys.dm_db_index_physical_stats(@db_id, NULL, NULL, NULL , 'LIMITED') ORDER BY [avg_fragmentation_in_percent] DESC; END; GO
Для выполнения кода нажимаем “Создать запрос” – вставляем код. В строке “SET @db_id = DB_ID(N’MyBaseSQL’);” вместо “MyBaseSQL” нужно указать имя своей базы данных. Кнопка “Выполнить”.
Почему регулярно стоит использовать именно реорганизацию индекса?
Дело в том, что перестроение индексов (или задача в мастере планов обслуживания “Восстановить индекс”) запускает процесс полного построения. Во время этого процесса данные недоступны (пользователи скорей всего не смогут работать), а процесс достаточно длительный. После перестроения обязательно обновляется статистика.
В свою очередь, реорганизация индексов — это серия небольших локальных перемещений страниц так, чтобы индекс не был фрагментирован. После реорганизации статистика не обновляется. Во время выполнения почти все данные доступны, пользователи смогут работать.
Важно! При использовании модели восстановления “Полная” (правой кнопкой мыши по базе данных – “Свойства” – “Параметры”), чтобы файл журнала транзакций не вырастал до неприличных размеров, необходимо выполнять “Резервное копирование базы данных (полное)” после каждой процедуры реорганизации или перестроения индекса.
Вывод: Если фрагментация более 30%, нужно выполнить разовое полное перестроение индексов (восстановить индекс). После перестроения планово использовать только реорганизацию.
Периодичность: 1 раз в сутки.
Время запуска: в технологическом окне – во время минимальной нагрузки.
Как настроить: Microsoft SQL Server Management Studio – “Управление” – “Планы обслуживания” – правой кнопкой мыши “Мастер планов обслуживания”.
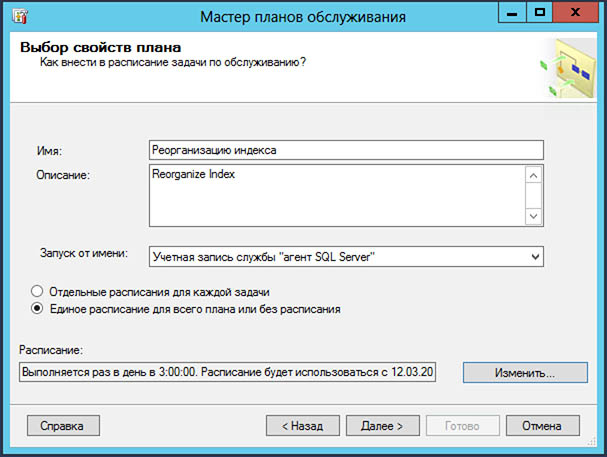
Имя – можно заполнить на свое усмотрение, например “Реорганизация индекса” или “Index Reorganize”. Для настройки расписания запуска проверки – кнопка “Изменить”. Выполняется – ежедневно; повторять – каждый 1 день. Однократное задание, например, в 02:00.
При выборе задач по обслуживанию устанавливаем флаг “Реорганизация индекса”.
Выбираем необходимые базы данных для обслуживания: либо какую-то определенную, либо несколько, либо все пользовательские.
Если настройка прошла без ошибок, выйдет сообщение об спешной проверке.
Обновление статистики
Статистика — небольшая таблица (обычно до 200 строк), в которой хранится обобщенная информация о том, какие значения и как часто встречаются в таблице. На основании статистики сервер принимает решение, как лучше построить запрос. Обычно, оптимизатор запросов создает необходимую статистику, но иногда необходимо создать дополнительные статистические данные для достижения лучших результатов.
Во время выполнения процедуры обновления статистики данные не блокируются, т.е. пользователи могут работать. Однако, следует помнить, что нагрузка во время выполнения этой процедуры на сервер SQL возрастает, а это может сказаться негативно на производительности системы. Поэтому обновлять статистику желательно в технологическом окне – времени наименьшей нагрузки на базу.
Частоту обновления статистики нужно определять экспериментальным путем в зависимости от нагрузки, но общая рекомендация для баз “1С” – один раз в сутки.
Периодичность: 1 раз в сутки.
Время запуска: в технологическом окне – во время минимальной нагрузки.
Как настроить: Microsoft SQL Server Management Studio – “Управление” – “Планы обслуживания” – правой кнопкой мыши “Мастер планов обслуживания”.
Имя – можно заполнить на свое усмотрение, например “Обновление статистик” или “Update Statistics”. Для настройки расписания запуска проверки – кнопка “Изменить”. Выполняется – ежедневно; повторять – каждый 1 день. Однократное задание, например, в 03:00.
При выборе задач по обслуживанию устанавливаем флаг “Обновление статистик”.
Выбираем необходимые базы данных для обслуживания: либо какую-то определенную, либо несколько, либо все пользовательские.
Если настройка прошла без ошибок, выйдет сообщение об спешной проверке.
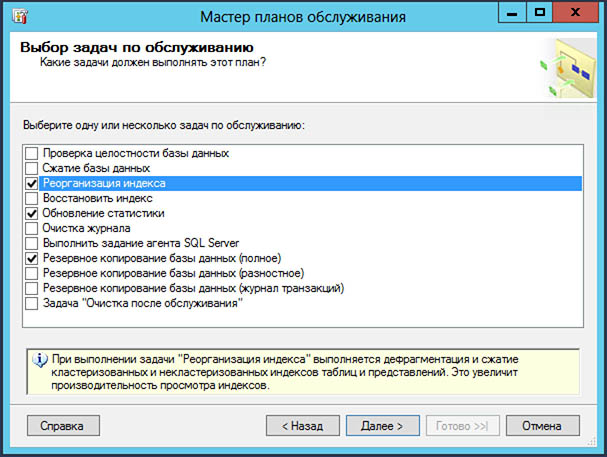
Обновление статистик и реорганизацию индекса и создание полного архива можно уместить в одну задачу, выбрав в окне выбора задач обслуживания соответствующие флаги.
Фирма “1С” в нескольких источниках (Регламентные операции на уровне СУБД для MS SQL Server) советует после обновления статистики дополнительно проводить очистку процедурного кэша. Это имело смысл для старых версий SQL Server, например версии 2005. С версии 2008 при включенной настройке “асинхронное обновление статистики” очищать процедурный кэш необязательно. При асинхронном обновлении статистики запросы компилируются с существующей статистикой, даже если она устарела. Если на момент компиляции запроса статистика оказывается устаревшей, оптимизатор запросов может выбрать неоптимальный план запроса. Запросы, которые компилируются после выполнения асинхронного обновления, будут усовершенствованы благодаря использованию обновленной статистики.
Контроль выполнения планов обслуживания
Просматривать результаты выполнения обслуживания можно нажав правой кнопкой мыши на “Управление” – “Планы обслуживания” – “Просмотр журнала”.
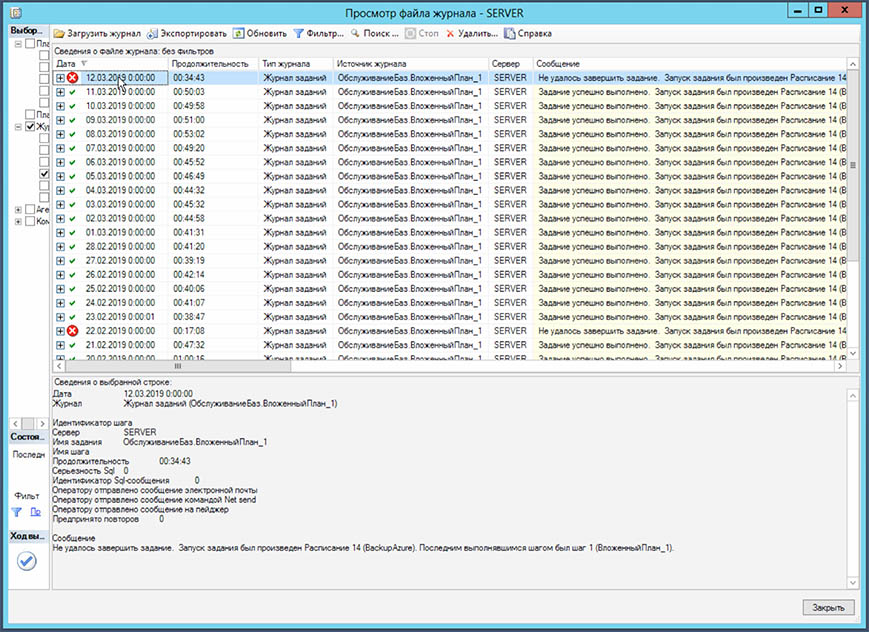
Если в журнале будут обнаружены ошибки, стоит изучить проблему и принять меры. Планы обслуживания должны отрабатывать успешно.
Почему не стоит использовать сжатие базы данных (шринк/shrink)?
Пожалуй, единственным случаем, когда есть смысл использовать сжатие базы данных – масштабные изменения в базе данных. Например: после восстановления из DT-дампа, свертки или реструктуризации информационной базы.
В остальных случаях:
- сжатие файла базы данных (MDF) приводит к увеличению индексов;
- сжатие файла журнала транзакций (LDF) не нужно при правильной настройке резервного копирования и обслуживании индексов. При использовании полной модели восстановления (Full Recovery Model) базы SQL важно делать регулярные резервные копии файла журнала транзакций и только перестроение индексов. Тогда, файл LDF будет соизмерим с размером файла базы данных и не будет бесконтрольно расти.
Ко всему прочему, практически сразу после выполнения операции “шринк/shrink” файлам приходится вновь расти. Что приводит к дополнительным операциям чтения и записи дисковой системы, которые в свою очередь замедляют работу пользователей.
Что дальше?
В будущих статьях мы рассмотрим несколько тем:
- тонкая настройка SQL Server;
- поиск узких мест в производительности связки сервер “1С:Предприятие”/MS SQL Server;
- настройка резервного копирования и возможность восстановить базу на любой момент времени.
Следите за обновлениями.
© 1995-2023 1С: Франчайзи «ПЛАСТ»
SQL Server: Лучшие советы по эффективному обслуживанию баз данных
У необслуживаемой (или плохо обслуживаемой) базы данных могут возникнуть проблемы в одной или нескольких из этих областей, что со временем может привести к плохой работе приложений или даже простоям и потере данных.
В этой статье я объясню, почему эти проблемы важны, и покажу некоторые простые пути их смягчения. Мои объяснения будут основаны на SQL Server® 2005, но я также выделю основные отличия, с которыми можно столкнуться в SQL Server 2000 и предстоящем SQL Server 2008.
Управление файлами данных и журналов
Первая область, которую я всегда рекомендую проверить при принятии управления базой данных – это параметры, связанные с управлением файлами данных и журнала (транзакций). Точнее говоре, следует убедиться, что:
- Файлы данных и журнала отделены друг от друга, а также изолированы от всего остального
- Автоматическое увеличение настроено верно
- Настроена автоматическая инициализация файлов
- Автоматическое сжатие отключено, и сжатие не является частью какого-либо плана обслуживания
Когда файлы данных и журнала (которые, в идеале, вообще должны быть на разных томах) находятся в одном томе с любым другим приложением, которое создает или расширяет файлы, возникает возможность для фрагментации файлов. В файлах данных избыточная фрагментация файлов может давать небольшой вклад в плохую работу запросов (особенно тех, что просматривают очень большие объем данных). В файлах журналов она может нанести гораздо более серьезный удар по производительности, особенно если автоматическое расширение установлено лишь на очень небольшое увеличение размера файла каждый раз, как в нем возникает потребность.
Файлы журнала внутренне разделены на разделы, именуемые виртуальными файлами журнала (Virtual Log Files – VLF), и чем выше фрагментация в файле журнала (я использую здесь единственное число, поскольку наличие нескольких файлов журнала не имеет большого смысла – в базе данных следует держать только один), тем больше число VLF. После того, как число VLF в файле журнала превышает, скажем, 200, может ухудшиться производительность связанных с журналом операций, таких как чтение журнала (скажем, для транзакционной репликации/отката), резервное копирование журнала и даже триггеров в SQL Server 2000 (реализация триггеров изменилось в SQL Server 2005 с журнала транзакций на инфраструктуру версий строк).
Что касается размеров файлов данных и журнала, лучше всего создавать их с подходящим первоначальным размером. Для файлов данных при выборе первоначального размера должна приниматься во внимание возможность добавления к базе дополнительных данных в ближайшей перспективе. Например, если первоначальный размер данных равен 50 ГБ, но известно, что в течение следующих шести месяцев будет добавлено еще 50 ГБ данных, имеет смысл сразу создать файл данных размером в 100 ГБ вместо того, чтобы выращивать его до этого размера в течение нескольких месяцев.
С файлами журналов дело, увы, обстоит несколько сложнее – необходимо учитывать такие факторы, как размер транзакции (долгосрочные транзакции не могут быть удалены из журнала до своего завершения) и частоту резервного копирования журнала (поскольку именно при нем удаляются неактивные части журнала). Дополнительные сведения приведены в «8 Steps to Better Transaction Log Throughput («8 шагов к улучшению пропускной способности журнала транзакций»)», популярной записи в блоге на SQLskills.com, написанной моей женой, Кимберли Трипп (Kimberly Tripp).
После того, как размеры файлов установлены, за ними следует наблюдать в различные моменты, и их следует заранее увеличивать вручную в подходящее время суток. Автоматическое увеличение следует оставить в качестве предосторожности на всякий случай, чтобы файлы могли расти по мере необходимости в случае какого-либо необычного события. Причина, по которой управление файлами не следует целиком оставлять автоматическому увеличению, состоит в том, что автоматическое увеличение небольшими кусками ведет к фрагментации файлов и что автоматическое увеличение может занимать много времени, тормозя работу приложения в неожиданные моменты.
Размер автоматического увеличения следует установить на определенное значение, а не на процент, чтобы ограничивать время и место, необходимые для выполнения автоматического увеличения, если оно происходит. Например, в случае 100-гигабайтного файла данных желательно зафиксировать размер автоматического увеличения как 5 ГБ, а не, скажем, 10%. Это значит, что он всегда будет увеличиваться на 5 ГБ вне зависимости от текущего размера файла, а не на объем, увеличивающийся после каждого увеличения файла (10 ГБ, 11 ГБ, 12 ГБ и так далее).
Когда журнал транзакций увеличивается (либо вручную, либо через автоматическое увеличение), он всегда инициализируется нулями. Файлы данных имеют то же поведение по умолчанию в SQL Server 2000, но начиная с SQL Server 2005 в них можно включить мгновенную инициализацию файла, которая пропускает инициализацию файлов нулями и, как следствие, делает увеличение и автоматическое увеличение практически мгновенными. В противоположность распространенным представлениям, эта функция доступна во всех выпусках SQL Server. Дополнительные сведения можно найти, введя «instant file initialization» («мгновенная инициализация файла») в указателе электронной документации для SQL Server 2005 или SQL Server 2008.
Наконец, следует позаботиться, чтобы никоим образом не было включено сжатие. Сжатие можно использовать для уменьшения размера файла данных или журнала, но это очень грубый, ресурсозатратный процесс, который вызывает широкую логическую фрагментацию просмотра в файлах данных (подробности см. ниже) и ведет к низкой производительности. Я изменил запись о сжатии в электронной документации SQL Server 2005, включив предупреждение об этом. Впрочем, сжатие отдельных файлов данных и журнала вручную может быть допустимо при особых обстоятельствах.
Автоматическое сжатие особенно вредно, поскольку оно запускается каждые 30 минут в фоновом режиме и пытается сжимать базы данных, для которых выставлен параметр автоматического сжатия. Этот процесс не вполне предсказуем в том, что он сжимает лишь базы данных с более чем 25% свободного места. Автоматическое сжатие использует массу ресурсов и вызывает понижающую производительность фрагментацию, так что оно нежелательно при любых обстоятельствах. Его всегда следует отключать с помощью:
ALTER DATABASE MyDatabase SET AUTO_SHRINK OFF;
План регулярного облуживания, включающий выдачу базе данных команды на сжатие вручную, почти столь же плох. Если обнаружится, что база данных постоянно растет после того, как план обслуживания сжимает ее, то это вызвано тем, что базе данных данное пространство нужно для работы.
Лучше всего позволить базе данных вырасти до размера стабильного состояния и избегать сжатия вообще. Дополнительные сведения о недостатках использования сжатия, а также кое-какие комментарии по новым алгоритмам в SQL Server 2005 можно найти в моем старом блоге MSDN® на blogs.msdn.com/sqlserverstorageengine/archive/tags/Shrink/default.aspx.
Фрагментация индексов
Помимо фрагментации на уровне файловой системы и внутри файла журнала, также возможна фрагментация внутри файлов данных, в структурах, хранящих данные таблиц и индексов. Внутри файла данных может произойти два базовых типа фрагментации:
- Фрагментация внутри отдельных страниц данных и индекса (порой именуемая внутренней фрагментацией)
- Фрагментация внутри структур индекса или таблиц, состоящих из страниц (именуемая логической фрагментацией просмотра и фрагментацией просмотра по экстентам)
Внутренняя фрагментация – это наличие в странице больших пустых пространств. Как показывает рис. 1 , каждая страница в базе данных имеет размер 8 КБ и 96-байтный заголовок; как следствие, страница может хранить примерно 8096 байтов данных индексов или таблиц (конкретные внутренние структуры таблиц и индексов для данных и структур строк можно найти в моем блоге по адресу sqlskills.com/blogs/paul, в категории Inside The Storage Engine («Внутри механизма хранения»)). Пустое пространство может возникнуть, если каждая таблица или запись в индексе превышают по размерам половину страницы, поскольку тогда на странице можно сохранить лишь одну запись. Исправить это очень сложно или невозможно, поскольку для исправления необходимо изменение схемы таблицы или индекса, например, путем изменения ключа индекса на что-то, что не вызывает случайные точки вставки, как это делает GUID.
Рис. 1. Структура страницы базы данных
Чаще внутренняя фрагментация вызывается изменениями данных, такими как вставки, обновления и удаления, что может оставить на странице пустые места. Неверное распоряжение коэффициентом заполнения также может способствовать фрагментации, подробности приведены в технической документации. В зависимости от схемы таблицы/индекса и характеристик приложения это пустое место может оказаться непригодным для повторного использования после его появления, что может привести к постоянному росту неиспользуемого места в базе данных.
Рассмотрим, для примера, таблицу из 100 миллионов строк, где средняя запись имеет размер 400 байтов. Со временем шаблон изменения данных приложения приведет к появлению в среднем 2800 байтов свободного пространства на страницу. Общее пространство, требуемое таблицей, составляет 59 ГБ, это выводится путем следующего расчета: 8096-2800 / 400 = 13 записей на 8-килобайтную страницу, затем делим 100 миллионов на 13, чтобы получить число страниц. Если бы пространство не пропадало, то на одной странице можно было бы уместить 20 записей, что уменьшает общее требуемое пространство до 38 ГБ. Огромная экономия!
Неиспользуемое место на страницах данных/индекса может, таким образом, привести к хранению того же объема данных на большем числе страниц. Это не только приводит к большему расходу места на диске, но и значит, что запросу надо провести больше операций ввода/вывода, чтобы прочесть тот же объем данных. И все эти дополнительные страницы занимают больше места в кэше данных, занимая тем самым память сервера.
Логическая фрагментация просмотра вызывается операцией, именуемой разбиением страницы. Это происходит, когда запись необходимо вставить на определенную страницу индекса (согласно определению ключа индекса), но на странице недостаточно места, чтобы разместить вставляемые данные. Страница разбивается пополам, и примерно 50% записей перемещаются на свежевыделенную страницу. Эта новая страница обычно не является физически смежной со старой и, следовательно, именуется фрагментированной. Концепция фрагментации просмотра по блокам аналогична. Фрагментация внутри структур таблиц/индексов влияет на возможность SQL Server выполнять эффективные просмотры как по всей таблице/индексу, таки и ограниченные предложением WHERE запроса (такие как SELECT * FROM MyTable WHERE Column1 > 100 AND Column1 < 4000).
На рис. 2 показаны свежесозданные страницы индекса со 100-процентным коэффициентом заполнения – страницы полны, и физический порядок страниц совпадает с логическим порядком. На Рис. 3 показана фрагментация, которая может происходить после случайных вставок/обновлений/удалений.
Рис. 2. Свежесозданные страницы индекса без фрагментации, страницы полны на 100%
Рис. 3 Страницы индекса, показывающие внутреннюю фрагментацию и фрагментацию логического просмотра после случайных вставок, обновлений и удалений
Фрагментацию порой можно предотвратить, изменив схему таблицы/индекса, но, как я упомянул выше, это может быть очень сложным или невозможным. Если предотвращение нереально, существуют способы устранения фрагментации после ее возникновения – в частности, путем восстановления или реорганизации индекса.
Восстановление индекса подразумевает создание новой копии индекса (аккуратно сжатой и настолько непрерывной, насколько это возможно, с последующим отказом от старой и фрагментированной). Поскольку SQL Server создает новую копию индекса перед удалением старой, ему требуется свободное место в файлах данных, приблизительно равное размеру индекса. В SQL Server 2000, восстановление индекса всегда проводилось в автономном режиме. Однако в SQL Server 2005 Enterprise Edition восстановление индекса можно выполнить в интерактивном режиме с некоторыми ограничениями. Реорганизация, с другой стороны, использует имеющийся алгоритм для сжатия и дефрагментации индекса; она требует лишь 8 КБ дополнительного пространства для выполнения – и всегда работает в интерактивном режиме. Кстати, в SQL Server 2000 я специально написал код реорганизации как интерактивную, экономящую пространство альтернативу перестройке индекса.
В SQL Server 2005 следует обратить внимание на команды ALTER INDEX … REBUILD для восстановления индексов и ALTER INDEX … REORGANIZE для их реорганизации. Этот синтаксис заменяет команды SQL Server 2000 DBCC DBREINDEX и DBCC INDEXDEFRAG, соответственно.
Между этими методами есть много различий, влияющих на выбор одного из них, таких как создаваемый объем журнала транзакций, требуемый объем свободного пространства в базе данных и возможность прервать процесс без потери выполненной работы. Технический документ, к котором обсуждаются эти различия, и прочее можно найти на microsoft.com/technet/prodtechnol/sql/2000/maintain/ss2kidbp.mspx. Этот документ основан на SQL Server 2000, но концепции хорошо переносятся на поздние версии.
Некоторые пользователи просто решают восстанавливать или перестраивать все индексы каждую ночь или каждую неделю (используя, например, вариант с планом обслуживания) вместо того, чтобы выяснять, какие индексы фрагментированы и какое преимущества даст устранение фрагментации. Хотя это может быть хорошим решением для невольного администратора базы данных, который просто желает применить какое-то решение с минимальными усилиями, это может оказаться очень плохим выбором для более крупных баз данных и систем, где ресурсы в дефиците.
Более сложный подход подразумевает использование динамического административного представления sys.dm_db_index_physical_stats (или DBCC SHOWCONTIG в SQL Server 2000) для периодического определения фрагментированных индексов и выбора того, следует ли работать на них, и если да, то как. В данном техническом документе также обсуждается использование этих более узких выборов. Вдобавок, некоторые образцы кода для выполнения этой фильтрации можно найти в примере D записи электронной документации, посвященной динамическому административному представлению sys.dm_db_index_physical_stats в SQL Server 2005 (msdn.microsoft.com/library/ms188917) или примере E записи электронной документации, посвященной DBCC SHOWCONTIG в SQL Server 2000 и далее (на msdn.microsoft.com/library/aa258803).
Какой бы метод ни использовался, настоятельно рекомендуется регулярно искать и устранять фрагментацию.
Обработчик запросов является частью SQL Server, которая решает, как следует исполнять запрос – а именно, какие таблицы и индексы использовать и какие операции выполнять на них для получения результатов; это именуется планом запросов. В число наиболее важных входных данных этого процесса принятия решений входит статистика, описывающая распределение значений данных для столбцов внутри таблицы или индекса. Очевидно, чтобы быть полезной для обработчика запросов, статистика должна быть точной и свежей, иначе могут быть выбраны непроизводительные планы запросов.
Статистика создается путем считывания данных таблицы/индекса и определения распределения данных для соответствующих столбцов. Статистика может быть построена путем проверки всех значений данных для определенного столбца (полной проверки), но ее также можно построить на основе указанного пользователем процента данных (проверки примеров). Если распределение значений в столбце является относительно равномерным, то проверки примеров может быть достаточно, и это делает создание и обновление статистики более быстрым, чем при полной проверке.
Обратите внимание, что статистику можно автоматически создавать и поддерживать, включив параметры базы данных AUTO_CREATE_STATISTICS и AUTO_UPDATE_STATISTICS, как показано на рис. 4 . Они включены по умолчанию, но тем, кто только что унаследовал базу данных, стоит проверить их, чтобы убедиться. Порой статистика может устареть – в этом случае возможно ее обновление вручную с помощью операции UPDATE STATISTICS для конкретного набора статистических показателей. В качестве альтернативы можно использовать хранимую процедуру sp_updatestats, которая обновляет всю устаревшую статистику (в SQL Server 2000 sp_updatestats обновляет всю статистику вне зависимости от возраста).
Рис. 4. Изменение параметров базы данных через SQL Server Management Studio
Если нужно обновлять статистику как часть плана регулярного обслуживания, то нужно помнить об одной хитрости. И UPDATE STATISTICS, и sp_updatestats по умолчанию используют ранее указанный уровень сбора данных (если указан какой-то) – и он может быть ниже, чем полная проверка. Восстановления индекса автоматически обновляют статистику с помощью полной проверки. В случае обновления статистики вручную после восстановления индекса можно получить еще менее точную статистику! Это может произойти, если проверка примеров из обновления вручную перепишет полную проверку, созданную восстановлением индекса. С другой стороны, при реорганизации индекса статистика вообще не обновляется.
Опять-таки, многие имеют план обслуживания, обновляющий всю статистику в какой-либо момент до или после восстановления всех индексов – и сами того не зная, они могут оказаться с менее точной статистикой. Если выбрано простое восстановление всех индексов время от времени, то оно позаботится и о статистике. Если выбран более сложный путь с устранением фрагментации, это стоит делать и для обслуживания статистики. Я предлагаю следующее:
- Проанализируйте индексы и определите, на каком индексе следует работать и как провести дефрагментацию.
- Обновите статистику для всех индексов, которые были восстановлены.
- Обновите статистику для всех неиндексированных столбцов.
Дополнительную информацию о статистике можно найти в техническом документе «Statistics Used by the Query Optimizer in Microsoft® SQL Server 2005» («Статистика, используемая оптимизатором запросов в Microsoft SQL Server 2005») (microsoft.com/technet/prodtechnol/sql/2005/qrystats.mspx).
Обнаружение повреждений
Я рассказал об обслуживании, связанном с производительностью. Теперь пора переключиться на рассказ об обнаружении повреждений и смягчении последствий.
Крайне маловероятно, чтобы в базе данных содержалась совершенно бесполезная информация, которая никого не волнует – так как же можно убедиться, что данные остаются неповрежденными и восстанавливаемыми в случае аварийной ситуации? Подробности сведения воедино полной стратегии аварийного восстановления и высокой доступности выходят за пределы темы этой статьи, но для начала можно сделать несколько простых вещей.
Подавляющее большинство повреждений вызываются «оборудованием». Почему оно в кавычках? Ну, оборудование здесь – это на самом деле условное обозначение для «что-то в подсистеме ввода-вывода, под SQL Server». Подсистема ввода/вывода состоит из таких элементов, как операционная система, драйверы файловой системы, драйверы устройств, контроллеры RAID, кабели, сеть и сами диски. Масса мест, где могут возникнуть (и возникают) неполадки.
Одной из наиболее распространенных проблем является сбой питания в момент, когда диск ведет запись на страницу базы данных. Если диск не сможет завершить запись, прежде чем у него кончится электричество (или если операции записи кэшируются и резервного источника питания не хватит для очистки кэша диска), результатом может стать незавершенный образ страницы на диске. Это может произойти, поскольку 8-килобайтная страница базы данных на деле состоит из 16 смежных 512-байтных секторов диска. Неполная запись могла записать некоторые из секторов из новой страницы, но оставить некоторые из секторов из образа предыдущей страницы. Такая ситуация называется разорванной страницей. Как можно обнаружить, когда это случается?
У SQL Server есть механизм для обнаружения такой ситуации. В него входят сохранение нескольких битов из каждого сектора страницы и запись определенного шаблона на их месте (это происходит непосредственно перед записью страницы на диск). Если при считывании страницы шаблон изменился, то SQL Server знает, что страница «порвана», и выдает ошибку.
В SQL Server 2005 и более поздних версиях доступен более полный и способный определить любые повреждения на странице механизм, именуемый контрольными суммами страниц. В него входят запись контрольной суммы всей страницы на страницу прямо перед ее записью и затем ее проверка при считывании только что записанной информации, точно так же, как при обнаружении порванных страниц. После включения контрольных сумм страниц страницу необходимо прочитать из буферного пула, изменить каким-либо образом и записать на диск снова, чтобы она стала защищена контрольной суммой страницы.
Так что лучше всего включить контрольные суммы страниц начиная с SQL Server 2005 и далее, а для SQL Server 2000 включить обнаружение разорванных страниц. Чтобы включить контрольные суммы страниц, используйте следующий оператор:
ALTER DATABASE MyDatabase SET PAGE_VERIFY CHECKSUM;
Чтобы включить обнаружение разорванных страниц для SQL Server 2000, используйте следующий оператор:
ALTER DATABASE MyDatabase SET TORN_PAGE_DETECTION ON;
Эти механизмы позволяют обнаружить наличие повреждений на странице, но только при чтении страницы. Как можно легко организовать чтение всех распределенных страниц? Лучшим методом для выполнения этого (и обнаружения повреждений любого другого рода) является использование команды DBCC CHECKDB. Вне зависимости от указанных вариантов эта команда всегда будет читать все страницы в базе данных, таким образом заставляя проверять все контрольные суммы страниц или обнаружение порванных страниц. Следует также установить предупреждения, чтобы можно было узнать, когда пользователи сталкиваются с повреждениями при выполнении запросов. Пользователь также может быть уведомлен о всех вышеописанных проблемах, используя предупреждение о ошибках уровня серьезности 24 ( рис. 5 ).
Рис. 5. Установка предупреждения для всех ошибок серьезности 24
Так что другой хорошей рекомендацией является регулярное выполнение DBCC CHECKDB на базах данных для проверки их целостности. Существует много вариантов этой команды и вопросов о том, как часто ее следует выполнять. Увы, технического документа, в котором это бы обсуждалось, сейчас не существует. Однако, поскольку DBCC CHECKDB была основной частью кода, которой я написал SQL Server 2005, я много писал о ней в блогах. См. категорию моего блога «CHECKDB From Every Angle» («CHECKDB со всех сторон»)(sqlskills.com/blogs/paul), в которой имеется много подробных статей, посвященных проверке целостности, рекомендациям и практическим советам. Для невольных администраторов баз данных хорошим правилом является выполнение DBCC CHECKDB после каждого полного резервного копирования базы данных. Я рекомендую выполнять следующую команду:
DBCC CHECKDB ('MyDatabase') WITH NO_INFOMSGS, ALL_ERRORMSGS;Если эта команда что-то выдает, DBCC нашел повреждения в базе данных. Тогда вопрос превращается в: «Что делать, если DBCC CHECKDB находит повреждения?». Здесь-то на сцене и появляются резервные копии.
При возникновении повреждения или иного сбоя наиболее эффективным способов восстановления является восстановление базы данных из резервных копий. Конечно, это предполагает наличие таковых копий и то, что сами они не повреждены. Слишком часто пользователи хотят знать, как заставить серьезно поврежденную базу данных работать вновь, когда у них нет резервной копии. Простой ответ состоит в том, что это невозможно, во всяком случае без потери данных, способной исковеркать всю бизнес-логику и реляционную целостность данных.
Так что регулярное резервное копирование весьма рекомендуется. Тонкости использования резервного копирования и восстановления выходят далеко за пределы этой статьи, но позвольте мне дать краткую инструкцию по созданию стратегии резервного копирования.
Во-первых, следует регулярно выполнять полное резервное копирование базы данных. Это дает единое состояние на момент времени, до которого затем можно восстанавливать. Полную резервную копию базы данных можно сделать, используя команду BACKUP DATABASE. Примеры имеются в электронной документации. Для дополнительной защиты можно использовать параметр WITH CHECKSUM, который проверяет контрольные суммы (если они есть) читаемых страниц и вычисляет контрольную сумму для всей резервной копии. Следует выбрать частоту, отражающую потерю данных или работ, которую можно себе позволить. Например, резервное копирование всей базы данных раз в день означает, что в случае сбоя может быть потеряна дневная работа в данных. В случае использования лишь полного резервного копирования базы данных следует быть в модели восстановления SIMPLE (обычно именуемой режимом восстановления), чтобы избежать сложностей, связанных с управлением ростом журнала транзакций.
Во-вторых, держите резервные копии по нескольку дней на случай, если одна из них будет повреждена – старая резервная копия лучше, чем никакой. Также следует проверять целостность своих резервных копий, используя команду RESTORE WITH VERIFYONLY (опять же, см. электронную документацию). Если при создании резервной копии был использован параметр WITH CHECKSUM, при использовании команды проверки будет проверено, верна ли еще контрольная сумма резервной копии, а также контрольные суммы страниц внутри нее.
В-третьих, если ежедневное полное копирование базы данных может привести к недопустимому для компании уровню потерь данных/сделанной работы, возможно, стоит заглянуть в разностные резервные копии базы данных. Разностная резервная копия базы данных основана на полной резервной копии базы данных и содержит запись всех изменений с момента создания последней полной копии (часто считается, что разностные резервные копии являются добавочными – это не так). В качестве примера стратегии можно привести ежедневное снятие полной резервной копии с созданием разностной копии каждые четыре часа. Разностная копия предоставляет вариант восстановления к состоянию на дополнительный момент времени. В случае использования только полного и разностного резервного копирования баз данных также следует использовать модель восстановления SIMPLE.
Наконец, наилучшие возможности по восстановлению предоставляет резервное копирование журналов. Оно доступно лишь в моделях восстановления FULL (и BULK_LOGGED) и предоставляет резервные копии всех записей журнала, созданных с момента последнего резервного копирования журнала. Поддержание набора резервных записей журнала, а также периодическое проведение полного (и, возможно, разностного) резервное копирования позволяет восстановить состояние на любой момент времени с точностью до минуты. Платить за это приходится тем, что журнал транзакций растет, пока его не «освобождают», создав резервную копию. В качестве примера стратегии здесь можно привести ежедневное снятие полной резервной копии с созданием разностной копии каждые четыре часа и резервной копии журнала каждые полчаса.
Выбор стратегии резервного копирования и организация ее применения могут быть непростыми. Как минимум, следует регулярно выполнять полное резервное копирование базы данных, чтобы убедиться в наличии как минимум одного момента времени, состояние базы данных на который может быть восстановлено.
Как можно увидеть, обеспечение работоспособности и доступности базы данных требует выполнения нескольких обязательных задач. Вот мой последний контрольный список для невольных администраторов баз данных, которым досталось управление базами:
- Удалите избыточною фрагментации файла журнала транзакций.
- Верно установите автоматическое увеличение.
- Отключите любые запланированные операции сжатия.
- Включите мгновенную инициализацию файлов.
- Создайте регулярный процесс обнаружения и удаления фрагментации индекса.
- Включите AUTO_CREATE_STATISTICS и AUTO_UPDATE_STATISTICS и создайте регулярный процесс для обновления статистики.
- Включите контрольные суммы страниц (или, как минимум, обнаружение порванных страниц на SQL Server 2000).
- Убедитесь в наличии регулярного процесса для выполнения DBCC CHECKDB.
- Убедитесь в наличии регулярного процесса для выполнения полного резервного копирования базы данных, а также разностного резервного копирования и копирования журнала для восстановления состояния на момент времени.
Я привел в статье команды T-SQL, но многое можно сделать и из Management Studio. Надеюсь, что я дал вам кое-какие полезные указания по эффективному обслуживанию баз данных. Если у вас есть комментарии или вопросы, отправьте их мне —paul@sqlskills.com.