Объяснение как работает JavaScript Engine с помощью визуализации
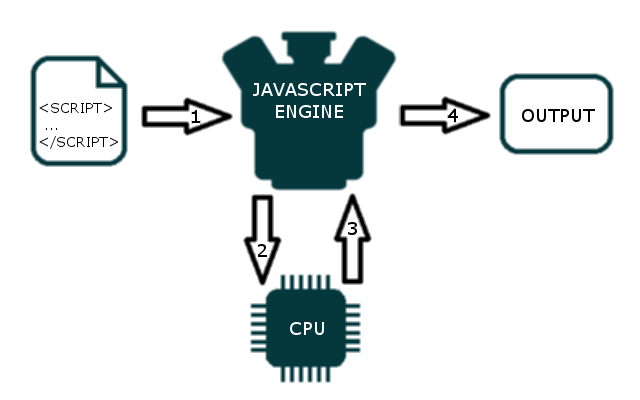
JavaScript девелоперам обычно не приходится иметь дело с компиляторами, тем не менее, будет полезно знать основы движка джаваскрипта и понимать как он обрабатывает js код.
Механизм JavaScript может быть реализован как стандартный интерпретатор или just-in-time компилятор, который компилирует JavaScript в байт-код в той или иной форме. Первые движки JavaScript были почти только интерпретаторами, но большинство современных движков используют JIT-компиляцию для повышения производительности.
Flow работы Javascript Engine
давайте рассмотрим упрощенную схему работы движка:
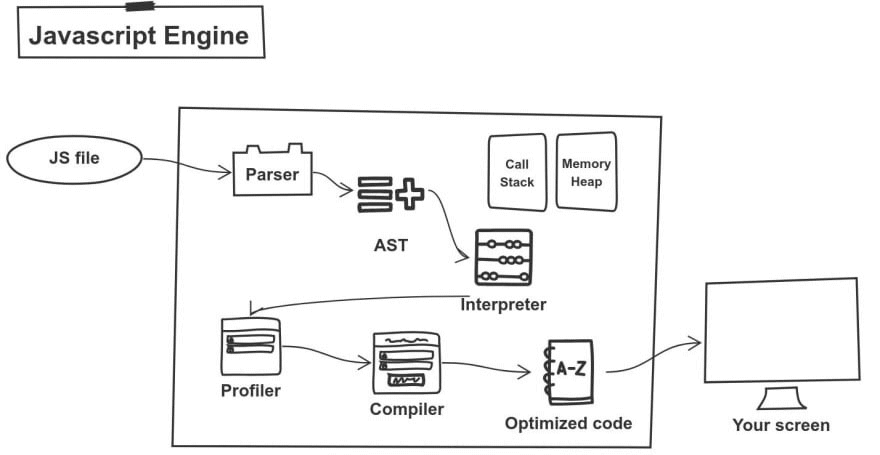
Parser
Первоначально парсер HTML обнаруживал тег скрипта с источником JavaScript. Исходный код в этом сценарии будет загружен как поток байтов UTF-16 в декодер потока байтов. Эти байты декодируются в токены, которые пересылаются синтаксическому анализатору. Движок всегда будет избегать синтаксического анализа кода, который в настоящее время не нужен, чтобы быть более эффективным.
Byte stream decoder создает токены из декодированного потока байтов.
JS engine юзает 2 парсера: pre-parser и parser. Чтобы сократить время, необходимое для загрузки веб-сайта, движок пытается избежать парсинг кода, который не нужен сразу. Pre-parser обрабатывает код, который может быть использован позже, в то время как parser обрабатывает код, который нужен немедленно. Если определенная функция будет вызвана только после того, как пользователь нажмет кнопку, нет необходимости, чтобы этот код компилировался немедленно, просто чтобы загрузить веб-сайт. Если пользователь в конечном итоге нажимает кнопку и запрашивает этот фрагмент кода, он отправляется парсеру.
AST
Анализатор создает ноды на основе токенов, которые он получает от byte stream decoder’а. С помощью этих узлов он создает абстрактное синтаксическое дерево (AST)��.
Интерпритатор
Далее, в работу включается интерпретатор. Он проходит через AST и генерирует байтовый код на основе информации, содержащейся в AST. После того, как байт-код был полностью сгенерирован, AST удаляется, освобождая место в памяти.
Profiler & Compiler
Байт код работает быстро, но всегда можно быстрее, по-этому, в js engine есть еще optimizing compiler. Он принимает байтовый код + «type feedback» и генерирует из них высоко оптимизированный машинный код. ��
JavaScript — это язык с динамической типизацией, что означает, что типы данных могут постоянно меняться. Было бы очень напряжненько, если бы движку JavaScript приходилось каждый раз проверять, какой тип данных имеет значение.
Чтобы сократить время, необходимое для интерпретации кода, оптимизированный машинный код обрабатывает только те случаи, которые engine видел раньше при выполнении байт-кода. Если мы неоднократно использовали определенный фрагмент кода, который возвращал один и тот же тип данных снова и снова, оптимизированный машинный код можно просто повторно использовать, чтобы ускорить процесс. Однако, поскольку JavaScript динамически типизирован, может случиться так, что один и тот же фрагмент кода внезапно вернет другой тип данных. Если это произойдет, машинный код будет деоптимизирован, и движок вернется к интерпретации сгенерированного байтового кода.
Скажем, определенная функция вызывается 100 раз и до сих пор всегда возвращала одно и то же значение. Предполагается, что он также вернет это значение в 101-й раз, когда вы его вызовете.
Допустим, у нас есть следующая функция sum, которая всегда вызывалась с числовыми значениями в качестве аргументов:

Эта функция вернет число 3 . В следующий раз, когда мы вызовем ее, engine предположит, что мы вызываем функцию снова с двумя числовыми значениями.
Если это так, то динамический поиск не требуется, и можно просто повторно использовать оптимизированный машинный код. В противном случае, если предположение было неверным, он вернется к исходному байтовому коду вместо оптимизированного машинного кода.
Например, в следующий раз, когда мы вызываем функцию, мы передаем строку вместо числа. Поскольку JavaScript динамически типизирован, мы можем сделать это без ошибок!

В данном случае число 2 будет преобразовано в строку, а функция вместо этого вернет строку «12» . Он возвращается к выполнению интерпретируемого байт-кода и обновлит «type feedback».
Конечно, есть много частей движка, которые я мы не рассмотрели в этом посте (JS heap, стек вызовов и т.д.), О которых мы поговорим в следующих постах. Если вас интересует внутреннее устройство JavaScript. V8 является открытым исходным кодом и имеет отличную документацию о том, как он работает под капотом, ссылки:
Введение
Чтобы разобраться в том, как работает механизм обработки кода (иначе говоря, движок JavaScript), надо понять, что происходит при выполнении кода. Такие знания помогают программистам писать лучший, более быстрый и умный код.
Движки JavaScript — это не что иное, как программы, преобразующие код на JavaScript в код более низкого уровня, который компьютер сможет понять. Эти движки встроены в браузеры и веб-серверы (Node.js), что даёт возможность выполнять код и осуществлять компиляцию во время выполнения.
Разве JavaScript — это не интерпретируемый язык?
Краткий ответ: это зависит от реализации. Обычно JavaScript относят к интерпретируемым языкам, хотя вообще-то он компилируется. Современные компиляторы JavaScript фактически выполняют JIT-компиляцию, т.е. компиляцию «на лету», которая осуществляется во время работы программы.
Движок
Существует множество разных движков. У каждого из них внутри есть что-то вроде конвейера с интерпретатором и конвейера с оптимизатором и компилятором. Интерпретатор генерирует байт-код, а оптимизатор выдаёт оптимизированный машинный код. Далее в статье в качестве примера будет использоваться движок V8.
V8 — это высокопроизводительный движок от Google с открытым исходным кодом JavaScript и WebAssembly, написанный на языке C++. Он используется в Chrome, Node.js и других платформах и реализует ECMAScript и WebAssembly (см. v8.dev).
Что внутри движка
Всякий раз, когда JavaScript-код отправляется в движок V8, он проходит ряд этапов для отображения console.log:
Парсер
Движок выполняет то, что мы называем лексическим анализом. Это первое, что происходит с файлом JavaScript при попадании в движок. Код разбивается на части, называемые токенами, для выявления их назначения, после чего мы узнаём, что код пытается сделать.
Абстрактное синтаксическое дерево (AST)
На основе этих токенов создаётся то, что мы называем AST. Синтаксическое дерево — это древовидное представление синтаксической структуры кода JavaScript, и мы можем использовать этот инструмент для анализа преобразования кода AST.
Интерпретатор
Интерпретатор читает файлы JavaScript построчно и преобразовывает их на ходу (во время работы программы, не прерывая её выполнение). На основе сгенерированного кода AST интерпретатор начинает быстро создавать байт-код. Никаких оптимизаций здесь не выполняется, так что байт-код этот неоптимизированный.
Байт-код не является таким низкоуровневым, как машинный код, но всё же может быть интерпретирован движком JavaScript для выполнения кода.
Профайлер
Профайлер отвечает за проверку кода. Он вызывает специальное средство контроля, которое отслеживает код и наблюдает за ходом его выполнения, обращая наше внимание на то, как можно оптимизировать код. Выдаёт, например, информацию о том, сколько раз код запускался, какие типы используются и как мы можем его оптимизировать?
Так что, если профайлер находит часть кода, которую можно оптимизировать, он передаёт этот код JIT-компилятору, чтобы он мог быть скомпилирован и выполнялся быстрее. Рассмотрим эти конвейеры с интерпретатором и компилятором более подробно.
Оптимизирующий компилятор
Задача оптимизирующего компилятора — определить, что делает программа, подлежащая оптимизации, и создать из неё оптимизированную программу, выполняющую всё то же самое, только быстрее.
Он не преобразует файлы на лету. Он делает свою работу заранее, создавая преобразование только что написанного кода и компилируя его в язык, понятный для компьютера.
Деоптимизация
Оптимизирующий компилятор на основе имеющихся у него данных профилирования делает определённые предположения, а затем выдаёт высокооптимизированный машинный код. Но вполне возможно, что в какой-то момент одно из предположений окажется неверным. И тогда оптимизирующий компилятор может деоптимизировать код.
Объектная модель JavaScript
JavaScript — это динамический язык программирования, а это подразумевает, что свойства могут легко добавляться или удаляться из объекта после его создания. Для написания более лучшего кода надо понимать, как JavaScript определяет объекты и как движок работает с объектами и свойствами.
- Enumerable → определяет, перечисляется ли свойство в циклах for — in .
- Value → само значение.
- Writable → определяет, можно ли свойство изменить.
- Configurable → определяет, можно ли удалить свойство.
Оптимизация доступа к свойству
В динамических языках, таких как JavaScript, для доступа к свойствам требуется ряд инструкций. Поэтому почти в каждом движке имеется оптимизация для ускорения этого доступа. Такая оптимизация в V8 реализуется скрытыми классами: V8 присоединяет скрытый класс к каждому отдельному объекту. Целью скрытых классов является оптимизация времени доступа к свойствам.
Скрытые классы работают аналогично фиксированным макетам (классам) объектов, используемым в таких языках, как Java (за исключением того, что они создаются во время выполнения). Магия здесь в том, что несколько объектов могут иметь один и тот же скрытый класс, поэтому необходимы только минимальные ресурсы, а код становится быстрее:
Выгода становится очевидной, когда объектов много. Ведь пока у них один и тот же скрытый класс, информацию приходится сохранять только один раз независимо от того, сколько всего имеется объектов!
Тема оптимизации очень обширна и может стать предметом обсуждения отдельной статьи.
Встроенные кэши
Цель встроенного кэширования в том, чтобы ускорить привязку метода времени выполнения. Происходит это за счёт запоминания результатов поиска предыдущего метода непосредственно в месте вызова. Встроенное кэширование особенно полезно для динамически типизированных языков, где большинство, если не все привязки методов происходят во время выполнения и где виртуальные таблицы методов часто не могут быть использованы.
Основная причина существования скрытых классов — концепция встроенных кэшей. Движки JavaScript используют встроенные кэши для запоминания информации о том, где найти свойства в объектах. Поэтому нет необходимости повторять дорогостоящий поиск свойств при каждом доступе к ним. Зачем каждый раз искать свойства, когда со встроенными кэшами это значительно быстрее?
Выводы
- инициализировать объекты лучше всегда одним и тем же способом, чтобы скрытые классы у них не были разными;
- с атрибутами свойств элементов массива надо быть осторожным, чтобы они могли аккуратно сохраняться, а работа с ними была эффективной.
- Как работает новый await верхнего уровня в JavaScript
- Чистый код JavaScript — Вертикальное форматирование
- Что значит this в JavaSсript?
Как работает JS: обзор движка, механизмов времени выполнения, стека вызовов
Популярность JavaScript растёт, его возможности используют на разных уровнях применяемых разработчиками стеков технологий и на множестве платформ. На JS делают фронтенд и бэкенд, пишут гибридные и встраиваемые приложения, а также многое другое.
Анализ статистики GitHub показывает, что по показателям активных репозиториев и push-запросов, JavaScript находится на первом месте, да и в других категориях он показывает довольно высокие позиции.
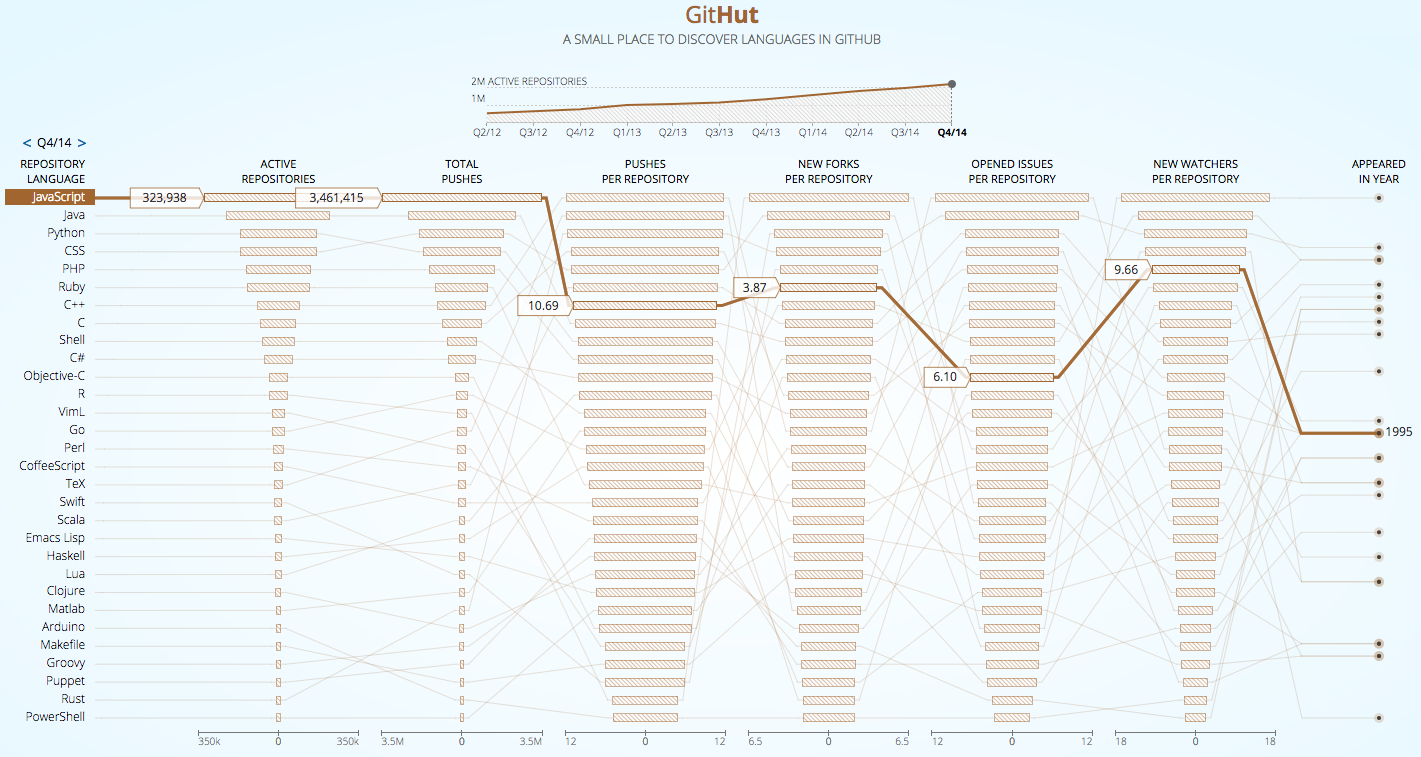
Статистические сведения по JavaScript с GitHub
С другой системой статистических сведений по GitHub можно ознакомиться здесь, она подтверждает то, что было сказано выше.
Если множество проектов плотно завязаны на JavaScript, значит, разработчикам необходимо как можно более эффективно использовать всё, что даёт им язык и его экосистема, стремясь, на пути разработки замечательных программ, к глубокому пониманию внутренних механизмов языка.
Как ни странно, существует множество разработчиков, которые регулярно пишут на JavaScript, но не знают, что происходит в его недрах. Пришло время это исправить: этот материал посвящён обзору JS-движка на примере V8, механизмов времени выполнения, и стека вызовов.
Обзор
Почти все слышали, в самых общих чертах, о JS-движке V8, и большинству разработчиков известно, что JavaScript — однопоточный язык, или то, что он использует очередь функций обратного вызова.
Здесь мы поговорим, на довольно высоком уровне, о выполнении JS-кода. Зная о том, что, на самом деле, происходит при выполнении JavaScript, вы сможете писать более качественные программы, которые выполняются без «подвисаний» и разумно используют имеющиеся API.
Если вы недавно начали писать на JavaScript, этот материал поможет вам понять, почему JS, в сравнении с другими языками, может показаться довольно-таки странным.
Если вы — опытный JS-разработчик, надеемся, этот материал поможет вам лучше понять, как на самом деле работает то, чем вы пользуетесь каждый день.
Движок JavaScript
V8 от Google — это широко известный JS-движок. Он используется, например, в браузере Chrome и в Node.js. Вот как его, очень упрощённо, можно представить:

Упрощённое представление движка V8
На нашей схеме движок представлен состоящим из двух основных компонентов:
- Куча (Memory Heap) — то место, где происходит выделение памяти.
- Стек вызовов (Call Stack) — то место, куда в процессе выполнения кода попадают так называемые стековые кадры.
Механизмы времени выполнения
Если говорить о применении JavaScript в браузере, то здесь существуют API, например, что-то вроде функции setTimeout , которые использует практически каждый JS-разработчик. Однако, эти API предоставляет не движок.
Откуда же они берутся? Оказывается, что реальность выглядит немного сложнее, чем может показаться на первый взгляд.

Движок, цикл событий, очередь функций обратного вызова и API, предоставляемые браузером
Итак, помимо движка у нас есть ещё очень много всего. Скажем — так называемые Web API, которые предоставляет нам браузер — средства для работы с DOM, инструменты для выполнения AJAX-запросов, нечто вроде функции setTimeout , и многое другое.
Стек вызовов
JavaScript — однопоточный язык программирования. Это означает, что у него один стек вызовов. Таким образом, в некий момент времени он может выполнять лишь какую-то одну задачу.
Стек вызовов — это структура данных, которая, говоря упрощённо, записывает сведения о месте в программе, где мы находимся. Если мы переходим в функцию, мы помещаем запись о ней в верхнюю часть стека. Когда мы из функции возвращаемся, мы вытаскиваем из стека самый верхний элемент и оказываемся там, откуда вызывали эту функцию. Это — всё, что умеет стек.
Рассмотрим пример. Взгляните на следующий код:
function multiply(x, y) < return x * y; >function printSquare(x) < var s = multiply(x, x); console.log(s); >printSquare(5);
Когда движок только начинает выполнять этот код, стек вызовов пуст. После этого происходит следующее:
Стек вызовов в ходе выполнения программы
Каждая запись в стеке вызовов называется стековым кадром.
На механизме анализа стековых кадров основана информация о стеке вызовов, трассировка стека, выдаваемая при возникновении исключения. Трассировка стека представляет собой состояние стека в момент исключения. Взгляните на следующий код:
function foo() < throw new Error('SessionStack will help you resolve crashes :)'); >function bar() < foo(); >function start() < bar(); >start();Если выполнить это в Chrome (предполагается, что код находится в файле foo.js ), мы увидим следующие сведения о стеке:

Трассировка стека после возникновения ошибки
Если будет достигнут максимальный размер стека, возникнет так называемое переполнение стека. Произойти такое может довольно просто, например, при необдуманном использовании рекурсии. Взгляните на этот фрагмент кода:
function foo() < foo(); >foo();
Когда движок приступает к выполнению этого кода, всё начинается с вызова функции foo . Это — рекурсивная функция, которая не содержит условия прекращения рекурсии. Она бесконтрольно вызывает сама себя. В результате на каждом шаге выполнения в стек вызовов снова и снова добавляется информация об одной и той же функции. Выглядит это примерно так:
Переполнение стека
В определённый момент, однако, объём данных о вызовах функции превысит размер стека вызовов и браузер решит вмешаться, выдав ошибку:

Превышение максимального размера стека вызовов
Модель выполнения кода в однопоточном режиме облегчает жизнь разработчика. Ему не нужно принимать во внимание сложные схемы взаимодействия программных механизмов, вроде возможности взаимной блокировки потоков, которые возникают в многопоточных окружениях.
Однако, и у исполнения кода в однопоточном режиме тоже есть определённые ограничения. Учитывая то, что у JavaScript имеется один стек вызовов, поговорим о том, что происходит, когда программа «тормозит».
Параллельное выполнение кода и цикл событий
Что происходит, когда в стеке вызовов имеется функция, на выполнение которой нужно очень много времени? Например, представьте, что вам надо выполнить какое-то сложно преобразование изображения с помощью JavaScript в браузере.
«А в чём тут проблема?», — спросите вы. Проблема заключается в том, что до тех пор, пока в стеке вызовов имеется выполняющаяся функция, браузер не может выполнять другие задачи — он оказывается заблокированным. Это означает, что браузер не может выводить ничего на экран, не может выполнять другой код. Он просто останавливается. Подобные эффекты, например, несовместимы с интерактивными интерфейсами.
Однако, это — не единственная проблема. Если браузер начинает заниматься обработкой тяжёлых задач, он может на достаточно долгое время перестать реагировать на какие-либо воздействия. Большинство браузеров в подобной ситуации выдают ошибку, спрашивая пользователя о том, хочет ли он завершить выполнение сценария и закрыть страницу.

Браузер предлагает завершить выполнение страницы
Пользователям подобные вещи точно не понравятся.
Итак, как же выполнять тяжёлые вычисления, не блокируя пользовательский интерфейс и не подвешивая браузер? Решение этой проблемы заключается в использовании асинхронных функций обратного вызова. Это — тема для отдельного разговора.
Итоги
Мы, в общих чертах, рассмотрели устройство JS-движка, механизмов времени выполнения и стека вызовов. Понимание изложенных здесь концепций позволяет улучшить качество кода.
Уважаемые читатели! Этот материал — первый в серии «How JavaScript Works» из блога SessionStack. Уже опубликован второй — посвящённый особенностям V8 и техникам оптимизации кода. Как по-вашему, стоит ли его переводить?
Как работает JavaScript
Ранее JavaScript предназначался для использования в веб-браузерах, однако ситуация изменилась с развитием Node. Мы знаем, как, где и когда его использовать. Но известно ли, что происходит за этими сценариями?
Даже если вы знаете это, то все равно сможете извлечь полезную информацию из данной статьи.
JavaScript — это высокоуровневый ЯП, а компьютер понимает только единицы и нули. Каким образом компьютер понимает написанный код? В этой статье мы рассмотрим ответ на один единственный вопрос: как работает JavaScript?
Движок JavaScript
Это главный герой, который отвечает за понимание компьютером JS-кода. Движок JavaScript принимает код и преобразует его в машиночитаемый язык. Он выполняет работу переводчика, преобразующего JS-код на понятный компьютеру язык. Как и JS, каждый ЯП также обладает движком, делающий написанный код понятным для компьютера.
У JavaScript есть множество различных движков, доступных для использования. На этой странице Википедии можно найти их список. Они также называются движками ECMAScript (подробнее об этом ниже).
Попробуем заглянуть внутрь движка, чтобы узнать, как преобразуются файлы JavaScript.
Что скрывает движок JavaScript
Движок — это язык, который разбивает код и переводит его. А V8 — это один из самых популярных движков JavaScript, который используется в Chrome и NodeJS и написан на низкоуровневом языке C++. Написать движок может кто угодно, что может привести к путанице.
Для поддержания контроля за этими механизмами был создан стандарт ECMA, который предоставляет характеристики написания движка и всех функций JavaScript. По этой причине в ECMAScript 6, 7, 8 и т. д. реализованы новые функции JavaScript, а движки обновлены для поддержки этих новых функций. Следовательно, необходимо проверять доступность расширенной функции JS в браузерах во время разработки.
Для примера возьмем движок V8, однако основные концепции остаются неизменными во всех движках.
Теперь рассмотрим с более технической точки зрения.
Так выглядит движок JS изнутри. Вводимый код проходит через следующие стадии:
- Парсер
- AST
- Интерпретатор выдает байт-код
- Профайлер
- Компилятор выдает оптимизированный код
Не волнуйтесь, подробности рассмотрим в течение нескольких минут.
Однако для начала разберем важное различие.
Интерпретатор и Компилятор
Есть два способа преобразования кода в машиночитаемый язык. Концепция, о которой мы поговорим, применима не только к JavaScript, но и к большинству ЯП, таких как Python, Java и т. д.
- Интерпретатор читает код построчно и сразу выполняет его.
- Компилятор читает весь код, выполняет оптимизации, а затем производит оптимизированный код.
Рассмотрим на примере.
function add(a, b) return a+b
>for(let i = 0; i < 1000; i++) add(1 + 1)
>
В приведенном выше примере функция add , которая добавляет два числа и возвращает сумму, вызывается 1000 раз.
- При передаче этого файла интерпретатору, он читает его построчно и сразу выполняет функцию, пока цикл не закончится. Таким образом, он просто переводит код в то, что компьютер понимает на ходу.
- При передаче этого файла компилятору, он читает всю программу, выполняет анализ действий и производит оптимизированный код на языке, который понимает машина. Это как взять X (JS-файл) и создать Y (оптимизированный код, понятный машине). Если использовать интерпретатор для Y (оптимизированный код), результат будет таким же, как при интерпретации X (JS-код).
На изображении выше показано, что байт-код — это просто промежуточный код, который необходимо интерпретировать для обработки компьютером. Как интерпретатор, так и компилятор, преобразуют исходный код в машинный код, единственное отличие состоит в том, как выполняется это преобразование.
- Интерпретатор построчно преобразует исходный код в эквивалентный машинный код.
- Компилятор сразу преобразует весь исходный код в машинный код.
Плюсы и минусы интерпретатора и компилятора
- Преимущество интерпретатора заключается в немедленном выполнении кода без необходимости компиляции, что может быть полезно для запуска JS-файлов в браузере. Однако процесс замедляется при необходимости преобразования большего количества JS-кода. Вспомните маленький фрагмент кода, в котором функция вызывалась 1000 раз. В этом случае вывод остается прежним, даже если функция add была вызвана 1000 раз. Такие ситуации замедляют работу интерпретатора.
- В таких случаях компилятор может выполнить некоторые оптимизации, заменив цикл одним числом 2 (1 + 1 добавлялось каждый раз), поскольку он остается неизменным для всех 1000 итераций. Окончательный код, который выдает компилятор, оптимизирован и выполняется намного быстрее.
Таким образом, интерпретатор сразу начинает выполнение кода, но не выполняет оптимизацию. Компилятору требуется время для компиляции кода, однако он выдает более оптимизированный код.
Теперь вернемся к основной схеме движка JS.
Итак, зная плюсы и минусы компилятора и интерпретатора, можно использовать преимущества каждого. Здесь и появляется компилятор JIT (Just In Time). Он представляет собой комбинацию интерпретатора и компилятора, и большинство браузеров теперь реализуют эту функцию для повышения эффективности. Движок V8 также использует эту функцию.
В этом процессе:
- Парсер идентифицирует, анализирует и классифицирует различные части программы. Например, устанавливает, является ли элемент функцией, переменной и т.д. с помощью ключевых слов JavaScript.
- Затем AST (абстрактные синтаксические деревья) создают древовидную структуру на основе классификации парсера. В AST Explorer можно узнать о том, как строится дерево.
- Затем дерево передается интерпретатору, который создает байт-код. Как мы узнали ранее, байт-код не является кодом самого низкого уровня, однако его можно интерпретировать. На этой стадии браузер работает с доступным байт-кодом с помощью движка V8, чтобы пользователю не приходилось ждать.
- В то же время профайлер ищет оптимизации кода, а затем передает входные данные компилятору. Компилятор выдает оптимизированный код, в то время как байт-код временно используется для рендеринга в браузере. Как только компилятор создает оптимизированный код, временный байт-код полностью заменяется новым оптимизированным кодом.
- Таким образом используются лучшие качества интерпретатора и компилятора. Интерпретатор выполняет код, в то время как профайлер ищет оптимизацию, а компилятор создает оптимизированный код. Затем байт-код заменяется оптимизированным кодом, который является кодом более низкого уровня, таким как машинный код.
Это означает, что производительность будет постепенно улучшаться, не блокируя время выполнения.
Примечание по байт-коду
Как и в случае с машинным кодом, не все компьютеры понимают байт-код. Чтобы интерпретировать его на машиночитаемый язык, необходимо промежуточное ПО, такое как виртуальная машина, или движок (например, Javascript V8). По этой причине браузеры могут выполнять этот байт-код из интерпретатора во время вышеупомянутых 5-ти стадий с помощью движков JavaScript.
В результате возникает следующий вопрос:
Является ли JavaScript интерпретируемым языком?
Да, но не совсем. На ранних этапах JavaScript Брендан Айк создал движок JavaScript ‘SpiderMonkey’. У движка был интерпретатор, который говорил браузеру, что нужно делать. Сейчас есть не только интерпретаторы, но и компиляторы, а код не только интерпретируется, но и компилируется для оптимизации. Технически все зависит от реализации.
- Прототипирование для Vue(Opens in a new browser tab)
- Как не лажать с JavaScript. Часть 1
- JavaScript async/await: что хорошего, в чём опасность и как применять?