Что это ibm
Built to handle mission-critical workloads while maintaining security, reliability and control of your entire IT infrastructure
Download the ITIC Reliability Report

Cut complexity with IBM servers as your foundation
With highly compatible enterprise-class servers at the foundation of your IT infrastructure strategy, you can integrate with your cloud of choice, deploy and move workloads where you want — on-prem or in the cloud. Develop an approachable, low-risk path that doesn’t disrupt existing IT infrastructure, yet paves the way for innovation.
Cyber resiliency
By combining your mainframe and storage, you can unlock the true power of a resilient and secure solution with exceptional cloud and data privacy capabilities.
Seamless integration
Improve data protection and privacy across your entire IT ecosystem by encrypting each stage of the data’s lifecycle, transmission, storage and processing.
Flexibility with control
Take control of your hybrid cloud strategy with enterprise servers that offer flexibility and choice, allowing you to adapt and evolve with a modern IT infrastructure.
Scalable servers
Scale up and out with industry-leading performance, unmatched uptime, instant recovery and flexible consumption to achieve faster insights.
Mainframes
Transform your application and data portfolio with accelerated AI, security and resiliency capabilities – all delivered through a hybrid cloud.
Linux servers
Optimize and secure your IT infrastructure — on-premises and in the cloud — with the flexibility and control that comes with open source development.
Gain new insights plus speed, resilience, compliance and sustainability with IBM z16 mainframe scale-up server that runs z/OS®, Linux®, z/VM® and z/TPF.
Powerful Linux scale-up server that delivers sustainability, security, hybrid cloud and cyber resilience.
IBM Power® E1080
A scale-up server that runs IBM® AIX®, IBM i or Linux, designed to tackle challenges with new levels of performance, core-to-cloud data protection and streamlined automation and insights.
IBM Power E1050
A high performance 4-socket rack scale-up server that runs IBM® AIX, or Linux, optimized for data-intensive applications and hybrid cloud deployments.
IBM Power S1024
A 2-socket, 4U Power10-based scale-out server that runs on IBM AIX, IBM i or Linux, with pay-as-needed capabilities, end-to-end data security, superior reliability and shared resources across systems.
IBM Power S1022
A 2-socket, 2U scale-out server that runs IBM AIX, IBM i or Linux. Workloads can be consolidated on fewer servers, thereby reducing software licensing, electrical and cooling costs.
IBM Power S1014
A 1-socket, 4U Power10-based scale-out server that runs IBM® AIX, IBM i or Linux, designed for business-critical workloads.
Cutting costs, floor space and energy consumption
Compuware saved millions of dollars and accelerated DevOps by shrinking its data center footprint and creating a two-platform IT strategy across on-prem and cloud resources.
Read the case study Protecting customer data for app-driven banking
BankZero relies on IBM LinuxONE security features to safeguard data, while delivering exceptional customer experiences and sub-millisecond response times for mobile banking.
Read the case study Getting to market faster, with lower costs
DeepZen gains a competitive advantage by launching its innovative emotive speech technology four months ahead of schedule, with lower costs and overhead.
Read the case study
Are You Getting the Most from Your Hybrid Cloud?
Learn how today’s top enterprises are modernizing apps and deploying workloads to innovate and meet customer needs.
What is IT infrastructure?
If an IT infrastructure is flexible, reliable and secure, it can help an enterprise meet its goals and provide a competitive edge in the market. Learn more about what companies can do with a scalable IT infrastructure.
What is data storage?
Today, organizations and users require data storage to meet today’s high-level computational needs like big data projects, artificial intelligence (AI), machine learning and the internet of things (IoT).
Что такое эффективное управление

Не нужно быть семи пядей во лбу для того, чтобы четко уяснить простую вещь: чем более интегрированными и совместимыми являются системы и инструменты управления всеми процессами, услугами, оборудованием и ремонтом на предприятии, тем более четко можно контролировать все процессы, протекающие внутри и извне бизнеса, а значит и конечный продукт, или услуга, будут высококачественными.
Так почему же тогда мы до сих пор пытаемся уповать на хваленых «антикризисных менеджеров» и «управленцев высокого класса», единственная задача которых — хорошо понимать бизнес в виде единого целого и живого организма, где все взаимосвязано, а качество работы уборщика отражается на производительности топ-менеджеров? Ведь по-сути единственное, что нужно сделать — это интегрировать и запустить такую систему информационной поддержки решений и управления физическими активами, которая сможет определить роль каждого ее участника, выдать ему порцию обязанностей и следить за их исполнением. Это легко сказать и гораздо сложнее реализовать, особенно если мы говорим о крупных, транс-национальных компаниях и корпорациях, которые редко специализируются на «выпуске карандашей». Энергетика, логистика, банковское дело сегодня усложнилось до такой степени, что руководству требуются специфические инструменты для того, чтобы адекватно (по времени и силам) и эффективно руководить операционной, то есть текущей, деятельностью.
Но для того, чтобы рассуждать на эту тему, ее нужно подкрепить фактами. Поэтому именно с этого я и начну — с фактов.
Факт первый — физические активы
Физические активы, или фонды — это то, что используется предприятием для получения конечного продукта, который поступает потребителям. В нефтяной отрасли это нефтяные вышки и нефтеперерабатывающие заводы; в логистике — это средства транспорта, пути и способы сообщения (самолеты, поезда, автомобили). В общем смысле, для большинства компаний и различных видов бизнеса, физическими активами являются наличность, оборудование, запасы на складе, а также собственность, принадлежащая бизнесу. Их противоположностью, являются, соответственно, нематериальные активы — интеллектуальная собственность, ПО, соглашения, а также ваш интеллектуальный капитал, используемый для того, чтобы весь бизнес приносил ощутимый результат, то есть прибыль.
Это кажется на первый взгляд очевидным, но мне важно подчеркнуть различие между физическими активами (в дальнейшем — фонды) и бухгалтерскими активами, то есть левой стороной баланса активов/пассивов. Теперь, когда каждый понимает, что из себя представляют фонды, можно идти дальше.
Факт второй — интегрированные фонды
Представьте себе ситуацию, в которой вы, человек из плоти и крови, пытались бы использовать интеллект другого человека, как свой собственный, не привлекая этого самого стороннего человека к непосредственной работе. Фантастика? Более чем.
Но на самом деле примерно так выглядит пример неумелого использования физических активов. Когда компания, в чьем распоряжении находятся заводы, цехи, склады, оборудование, служба доставки и т.д. пытается выстроить работу каждого из этих элементов не формируя единой цепочки, это напоминает именно попытку создать что-то, о чем никто не имеет понятия. Другой пример из той же серии — это команда высококлассных специалистов, каждый из которых говорит на своем языке (уже более реальная ситуация). До тех пор, пока они не интегрируются, то есть не выработают один нормативный язык общения, работа не начнется.
Теперь вы понимаете, почему интегрированные фонды лучше распределенных, с точки зрения управления ими. От их надежного функционирования в бизнесе зависит абсолютно все: качество продукта, своевременность его выпуска и поставки и выполнение других требований. Это и есть та причина, по которой в современной экономике огромная роль уделяется дисциплине управления фондами и информационными системами, за счет которых они существуют (в современном бизнесе большая часть фондов представляет собой именно информацию, данные первостепенной важности).
Факт третий — единая система управления интегрированными фондами
Кроме интеграции у большинства фондов есть еще одно уязвимое место — это управление ими. Представьте, что вы генеральный директор нефтедобывающей компании, чьи месторождения разбросаны по всей площади огромного государства, такого как Российская Федерация — именно так это и выглядит в реальности. Вам нужно создать централизованную систему управления распределенными активами для того, чтобы в режиме реального времени следить за производительностью каждой отдельной части общей цепочки. При этом критически важно, чтобы не было задержек производства, лишние шаги были извлечены из схемы поставок, а качество продукта было неизменно высоким.
Это комплексная и сложная проблема, над решением которой бьются самые светлые умы, но только в последние десятилетия начало появляться решение, сегодня доступное любому желающему. Желающему сократить издержки, в первую очередь, и строить бизнес нацеленный не только на получение прибыли, но и на выживание в любых условиях.
Западные исследователи из США и Великобритании, проводившие исследования в этой области, говорят следующее: разумное и эффективное построение процессов техобслуживания снизит простои оборудования на 5-20% в зависимости от отрасли, срок его полезного использования увеличится на 5-30%, а производительность персонала на 5-50(!)%. В полтора раза больше работы значит в полтора раза больше прибыли.
Еще одна причина, по которой сегодня очень востребованы системы управления фондами, заключается в современных экологических нормах и стандартах, а также своевременном обнаружении критических проблем безопасности. Никто не хочет повторения Чернобыльской истории, или второй Саяно-Шушенской ГЭС, никому не нужна еще одна шахта «Распадская». Увеличение надежности активов и увеличение их жизненного цикла — еще один фактор, вытекающий из эффективного использования фондов.
При чем здесь IBM?
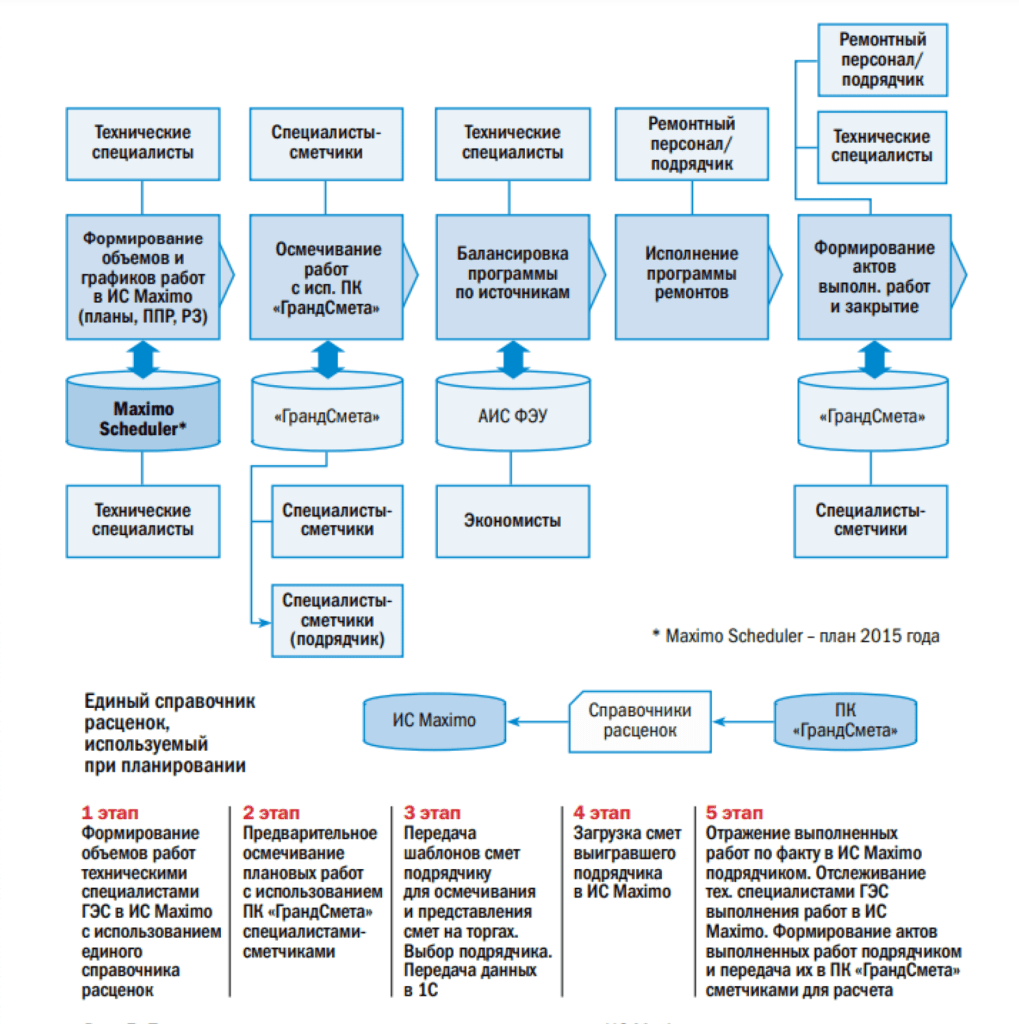
Все просто: компания IBM уже не один год занимается разработкой EAM-систем (Enterprise Asset Management — управление корпоративными фондами). Все началось с приобретения компании MRO Software в 2006 году, после чего IBM включила собственные разработки в продукцию MRO и с тех пор является лидером на рынке систем эффективного управления активами (данные Gartner за 2010 год). Для того, чтобы понять, почему решение IBM выгодно отличается на фоне всех конкурентов, я, пожалуй, приложу картинку.

Платформа Maximo обладает одним очень важным качеством — она представляет из себя конструктор, включающий в себя все подсистемы и компоненты необходимые для организации единой системы управления физическими активами. Это единое решение для всех типов фондов: производственных, транспортных, энергетических, инфраструктурных, коммунальных и, конечно же, ИТ-активов.
Схема подключения необходимых модулей позволяет достигнуть двух целей:
1. Исключить ненужные элементы
2. Включить необходимые элементы
Это кажется логичным до банальности, но на самом деле далеко не все аналогичные платформы позволяют совершать эти две элементарные операции, вследствие чего люди, которым приходится работать с этими инструментами, путаются в их функционале и назначении, а порой вообще не понимают, «зачем все это нужно».
IBM Maximo состоит из четырех основных компонентов: I. единого интерфейса; II. единых средств конфигурации; III. единых процессов и IV. единой подсистемы данных. Все инструменты работают в рамках единой системы, где не требуется интеграция внутренних механизмов. Добавление нового модуля не требует специальной настройки, а значит экономит время и деньги.
IBM пошла революционным путем, представив управление фондами в виде управления сервисами (потому что работа физического актива, по-сути, и представляет собой сервис, то есть службу).
Интерфейс Maximo построен на базе архитектуры J2EE, а значит не требует установки клиентского ПО или оборудования в системе — пользователи работают с системой с помощью браузера, что убирает узкие проблемы совместимости.
Принцип «ролевого доступа» — еще один интересный момент, который IBM интегрировала в свой продукт. Каждому пользователю системы присваивается определенная роль в общей работе, а интерфейс программы подстраивается под эту роль, предоставляя именно тот объем функционала, который необходим для выполнения обязанностей.
Объединяя все вышесказанное, можно констатировать последний факт:
Факт четвертый — программный продукт, представляющий собой единый инструмент автоматизации всех процессов управления физическими активами, обеспечивающий полную интеграцию и взаимодействие пользователей в рамках текущих процессов, поддерживает единую модель безопасности и реализует эскалацию экстренных мер в случае появления проблем, будет близким к идеальному продукту, одно внедрение и обучение работы с которым начнет приносить ощутимую пользу всему бизнесу.
Я уже рассказывал о том, как в голландском аэропорту Схипхол организовали эффективную систему управления и транспортировки багажа на базе RFID меток, но на самом деле платформа Maximo позволяет гораздо большее: увидеть всю информацию, поступающую из фондов, в реальном времени и понять, что нужно сделать для того, чтобы оптимизировать производственную цепочку или повысить эффективность многих процессов.
Приведу еще один пример — концепция «разумного здания», которая сегодня очень активно развивается во всем мире и содержит в себе не один десяток основополагающих принципов (экологичность, энергоэффективность и т.д.), подразумевает интеграцию всех систем в единую информационную систему с централизованной точкой «выхода» информации — это IBM Maximo. Эта платформа позволяет привязать разнородную информацию к активам и рассмотреть их взаимную связь, то есть влияние, друг на друга. Например, кондиционер, установленный в таком здании, будет является частью системы кондиционирования, компонентом системы энергообеспечения и энергосбережения. Вы увидите все роли, которые выполняет тот, или иной, актив — еще недавно подобные данные были сильно искажены, а если точнее, то данные получаемые из подобных систем, были очень узкими.
Зачем необходима подобная интеграция? Для получения более четкой картины происходящего, основываясь на аналитических системах и инструментах информационной поддержки принятия решений. Я думаю, что это очевидно — чем больше вы знаете о том, какую роль играет та, или иная деталь, в работе единого механизма, тем больше вы понимаете о всем механизме в целом. Именно это и является конечной целью создания и существования таких платформ, как Maximo.
Напоследок — небольшая success story, а в следующей публикации я расскажу о примерах реального внедрения платформы на российских предприятиях и о том, какой результат это принесло бизнесу, как взаимосвязанному организму.
Информационная система управления фондами и активами ОАО «РусГидро» на базе IBM Maximo
Рассмотрен опыт работ по внедрению и тиражированию на все станции федеральной гидрогенерирующей компании системы Maximo.
У нас в компании внедрена система Maximo, это продукт компании IBM. Хочу сразу сказать, мы к Maximo относимся просто как к одному из элементов системы УФАП — это система управления фондами и активами. УФАП — это больше, чем просто Maximo, и сегодня я расскажу только непосредственно про Maximo, она у нас в общей системе комплексных информационных систем «РусГидро».
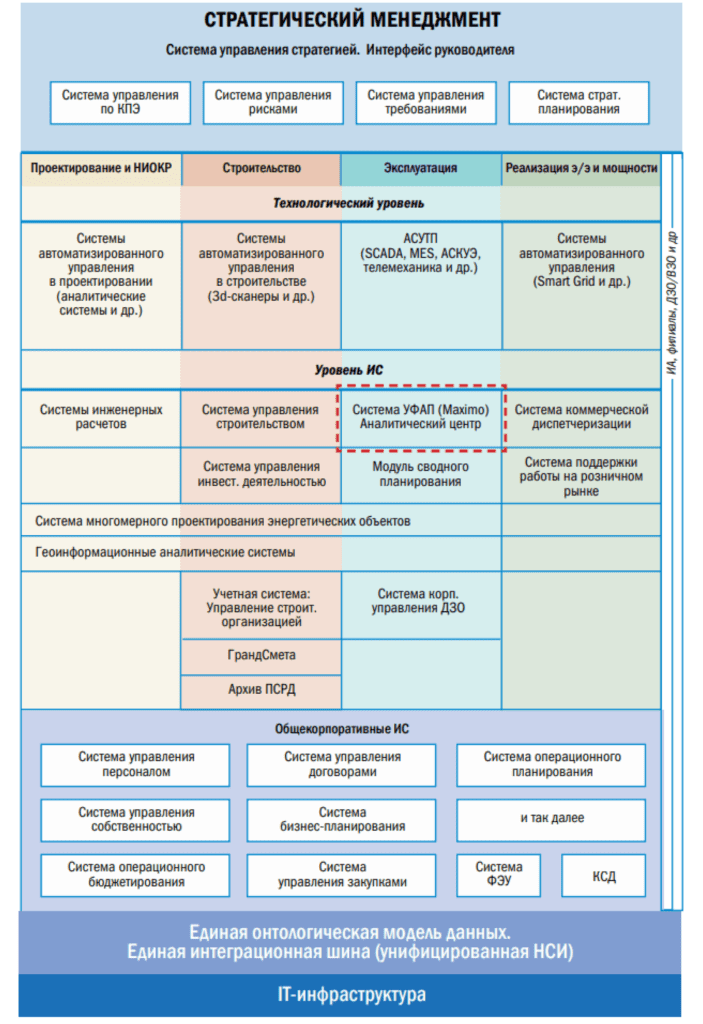
В каких-то направлениях деятельности компании что-то автоматизировано, что-то нет. Это параметры проекта Maximo, этапы, на которые мы условно разделяем весь проект. Первый этап был в 2004—2007 годах, когда Maximo внедрялась на станции Волжско-Камского каскада (тогда еще КВГЭК) Начиная с 2007 года пошел второй этап — тиражирование на все остальные станции федеральной гидрогенерирующей компании. Третий этап внедрения УФАП, вернее, непосредственно Maximo — это мы переходили со старой версии Maximo 5.2 на версию 7. Сразу скажу, изменения были: в целом по процессу, наверное, нет, но филиалы ощутили этот переход. Не скажу, что он был болезненным, он был менее болезненным, чем внедрение самой системы, потому что станциям некоторым по 70 лет, а система новая, и привыкать к чему-то новому очень сложно. Но за два года мы управились.
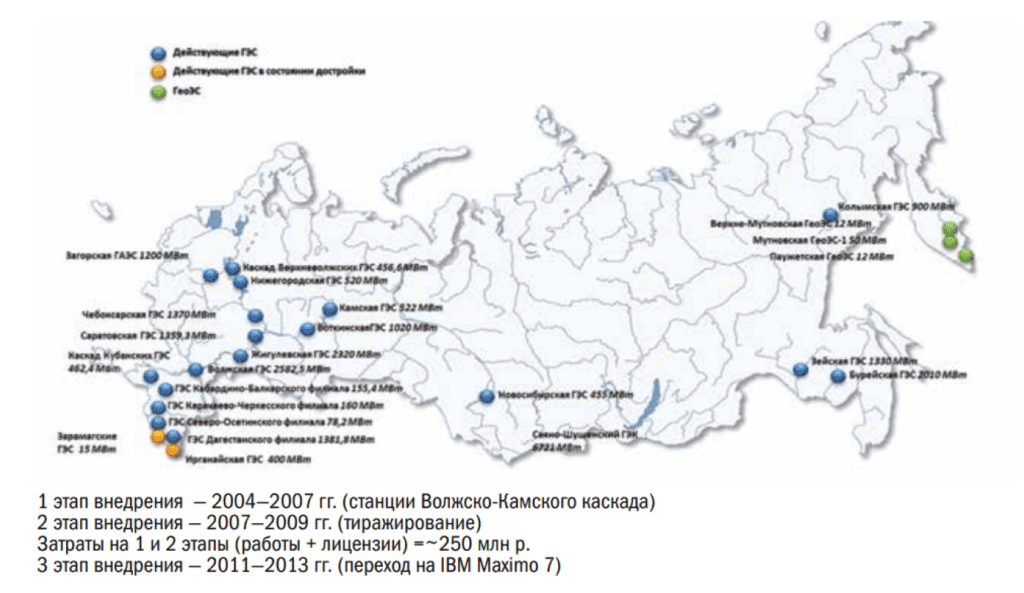
Любая система базируется на каких-то справочниках. В частности, в данном случае справочник выглядит как модуль оборудования, то есть где у нас расписано всё. Во-первых, заложен классификатор. Расписаны активы. Расписаны местоположения, где они расположены. И здесь справа в колонке я представил процент использования данного функционала (рис. 3).
Сразу скажу, что это моя экспертная оценка. В данном случае мы используем эти модули на 70%, потому что так получается, мы особое внимание уделяем основному оборудованию, вокруг которого, условно говоря, крутится наш бизнес. Мы очень много лет занимаемся оценкой состояния именно основного оборудования, вот поэтому я написал 70%, потому что у нас в системе, конечно, заведено вспомогательное оборудование, но оно просто не паспортизировано. Я всегда это открыто говорю. Основное оборудование мы знаем, всю его историю, вплоть до паспортов. По вспомогательному оборудованию паспорта, конечно же, есть, но системно эта работа не проводилась. Так получилось, в первую очередь, потому что станций много, станции разные, соответственно, не дошли еще руки до того, чтобы «причесать», так сказать, привести к единому виду паспорта вспомогательного оборудования.
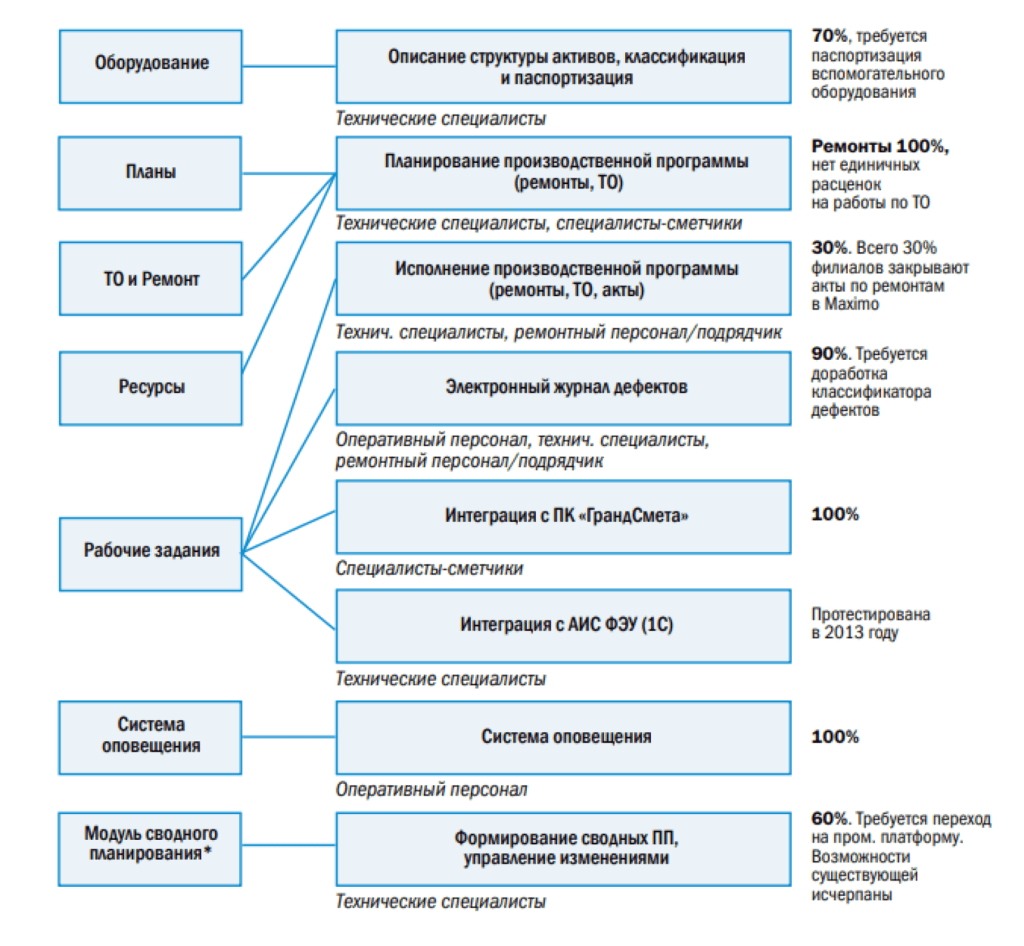
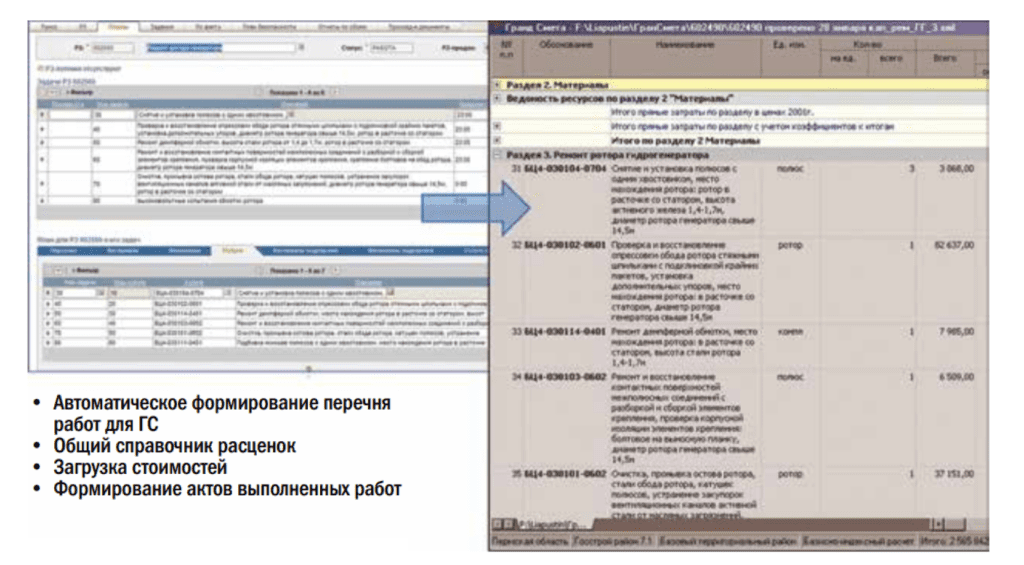
Следующий модуль, который у нас используется, — это модуль «Планы», посредством его мы планируем производственные программы ремонтов и технического обслуживания в Maximo, именно в Maximo у нас ведутся программы ремонта и технического обслуживания. Функционал в части ремонтов в Maximo задействован на 100%. В Maximo возможно спланировать программу ремонтов по услугам, материалам. Сразу скажу, у нас ресурсы не планируются, т.к. у нас 95% ремонтной программы — это подрядный способ, то есть мы людьми не управляем.
При этом в системе у нас формируется рабочее задание, в системе мы можем посредством интеграции с «ГрандСметой» получить стоимость ремонтных работ и на основании загруженных смет, как по плану, так и по сметам подрядчиков, формировать акт выполненных работ, причем утвержденный по форме КС-2. Этот функционал у нас полностью готов, и мы им пользуемся.
Однако не все филиалы этим функционалом пользуются. Здесь больше организационный момент, когда все зависит от главного инженера конкретного филиала. Когда ему это нужно, как на Саяно-Шушенской ГЭС, Новосибирской ГЭС, то главный инженер ставит подрядчику условие: «Я не подписываю акты, выгруженные не из Maximo!» Ему подрядчик другие акты и не приносит. На других филиалах главный инженер таких условий не ставит, ему приносят акт выполненных работ, сформированный в той же «ГрандСмете», он его подписал — и дело с концом, сдали в бухгалтерию.
В планировании производственных программ у нас есть модуль «ТО и Ремонт», это, по сути, так называемый модуль ППР. Модуль «Рабочие задания» влияет, соответственно, на функционал исполнения. Есть электронный журнал дефектов, четкое планирование, интеграция с «ГрандСметой». Что касается журнала дефектов, тут мы были, не побоюсь этого слова, первыми: мы первая энергокомпания в России, которая перешла на электронный журнал дефектов, причем перешла официально. В 2011 году мы подписали соответствующий протокол с Ростехнадзором. У нас в компании нет бумажного журнала дефектов. Если вы услышите, что на какой-то станции «РусГидро» (именно «РусГидро», не холдинга) ведется журнал дефектов, это значит, что на этой станции занимаются саботажем. То есть у нас официально отменен бумажный журнал дефектов, и Ростехнадзор, приезжая на станцию, требует выгрузку из системы. В части «ГрандСметы» налажена интеграция уже лет шесть: планы по услугам и материалам, которые мы планируем, рабочие задания мы выгружаем в «ГрандСмету», там все осмечено, загружаем обратно, и у нас получается работа с ее ценами.
Вернусь к электронному журналу дефектов. Мы понимаем, что нам необходимо перерабатывать классификатор дефектов. Электронный журнал дефектов выполняет тупую функцию — это фиксировать дефект и его устранение. Какую-то аналитику очень сложно построить по существующему классификатору дефектов. Поэтому мы сейчас ресурсами нашего аналитического центра, который создан в компании, пытаемся немножко переструктурировать, создать даже заново классификатор дефектов, чтобы можно было проводить аналитику по дефектам, которые возникают на оборудовании.
Последние два модуля — «Система оповещения» и Модуль сводного планирования.
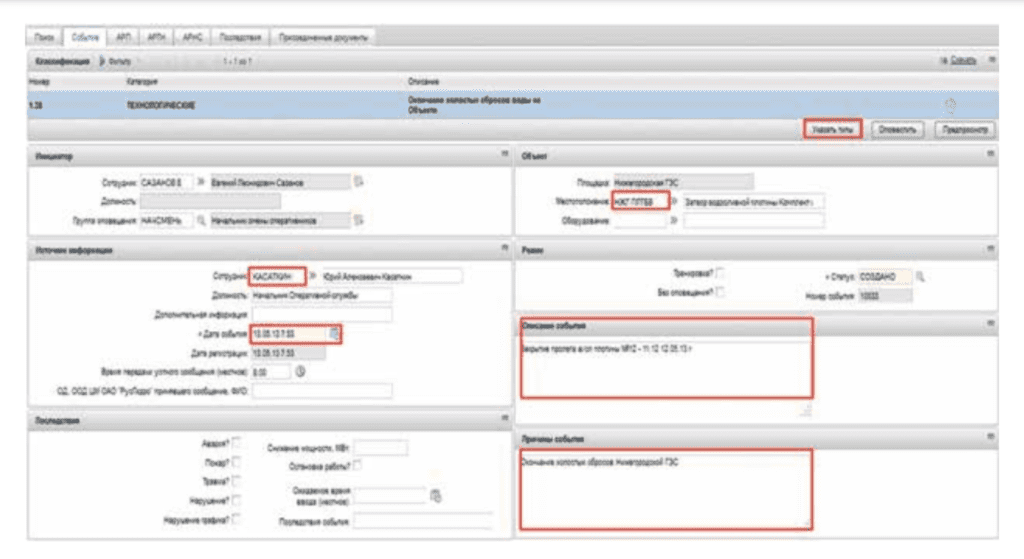
Система оповещения используется:
- для регистрации события и своевременного оповещения ответственных лиц о возникновении аварии (чрезвычайной ситуации);
- для объединения всей информации о событии — причин, последствий, мероприятий, актов расследования, оборудования и персонала, связанного с ситуацией.
Оперативники фиксируют возникающие на станции чрезвычайные ситуации, все классифицируется персоналом, и делается рассылка на электронную почту руководству компании. Все оповещения привязываются конкретно к единице оборудования, то есть в истории по каждой единице оборудования мы видим в том числе и оповещения.
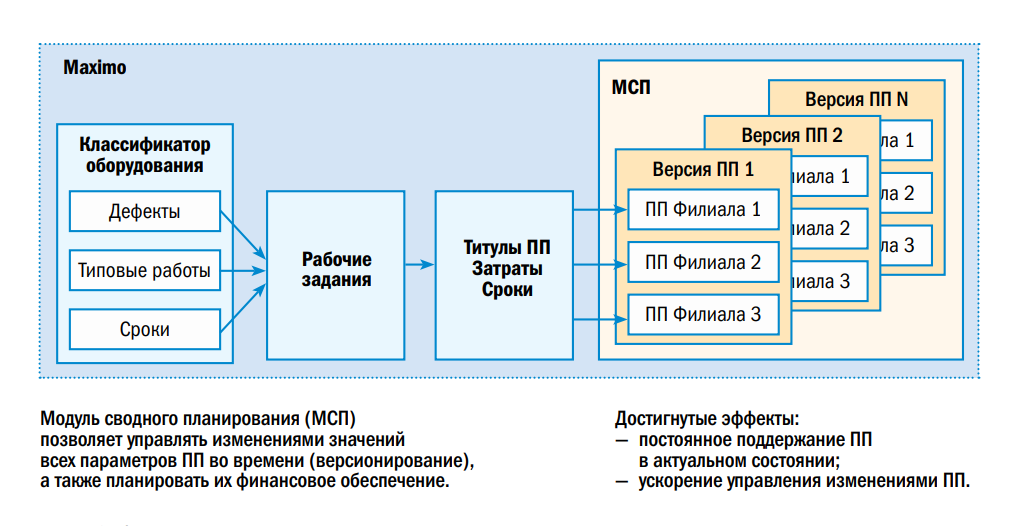
Модуль сводного планирования.
Разработка существующего Модуля сводного планирования была произведена по заказу компании в 2009 году. Это было обусловлено отсутствием на рынке промышленных систем, позволяющих решить поставленные задачи, в частности, обеспечить версионирование данных. В настоящее время на рынке представлены промышленные решения, на базе которых возможно реализовать функционал Модуля сводного планирования.
Дело в том, что в IBM Maximo хранится самая последняя версия, а модуль сводного планирования нам позволяет делать версии различные (т.е. была такая, стала такая, потом изменилась, а потом проводить аналитику между версиями). К сожалению, в Maximo версионность не поддерживается.
Появляется все больше и больше требований к данному модулю, и его платформа большего не позволяет, мы хотим перейти на промышленную платформу и там и закрыть все наши потребности.
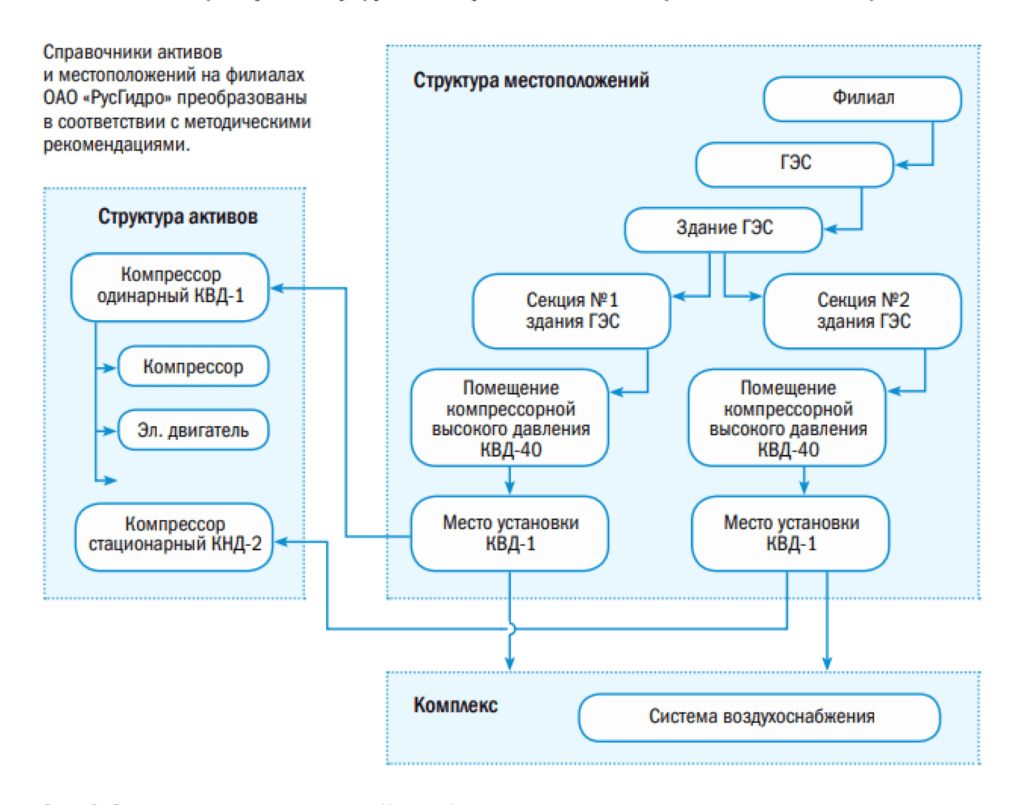
И теперь непосредственно по самой системе. Подобным образом у нас расписаны все справочники, начиная с филиала (у нас есть филиалы как дистанционные, так и не дистанционные). В подобном графике мы расписали структуру активов, структуру местоположений, что-то определили в комплексах. Например, систему пожаротушения, она может быть разбросана, оборудования может быть много. В процессе планирования и исполнения производственной программы ремонтов Maximo на первом этапе специалисты формируют объем работ, проставляют сроки. В Maximo 7 появился модуль Scheduler, имеющий много преимуществ. В чем его удобство: не нужно ничего никуда перегружать. Подтягивается вся программа, все рабочие задания, открывается диаграмма Ганта, и можно подвигать вправо-влево соответствующие рабочие задания, выставить нужные сроки, сохранить все, сроки автоматом меняются в рабочем задании. Т.е. нет необходимости в рабочие задания заходить и менять там сроки, они меняются автоматом.
В этом модуле можно строить различные сценарии программы. Т.е. можно не применять данные графиков ремонта, которые получаются, а можно его сохранить в виде сценария. Создать другой, посмотреть, какой больше нравится, и в нужный момент применить тот, на котором остановился. И все сроки на рабочем задании поменяются в соответствии с этим сценарием.
Специалисты наши технические планируют, формируют объем и график работ. Дальше специалисты-сметчики у нас эти работы при помощи «ГрандСметы» осмечивают. Все это уходит в виде программ уже в блок, которые занимается бюджетированием. Все это запланировали в финансовоэкономическом плане. Дальше заключается договор. И на этапе исполнения программы в Maximo загружаются сметы по договору, т.е. сметы подрядчика. На основании смет подрядчика у нас происходит формирование и закрытие актов выполненных работ.
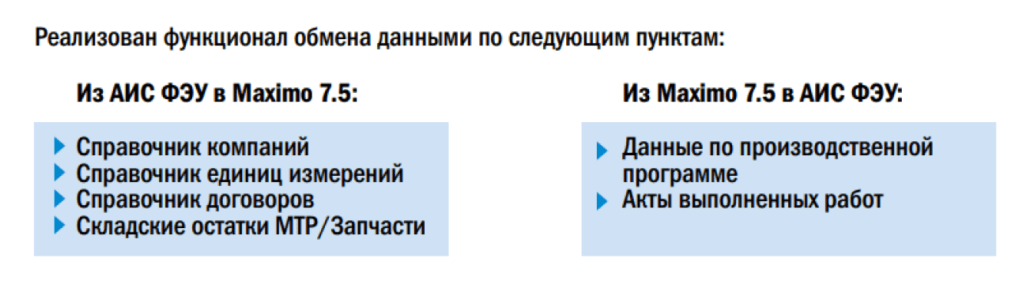
Также на этапе исполнения идет интеграция с «ГрандСметой»: просто механически идет пересохранение актов выполненных работ из Maximo и обратно, т.е. там никакие расчеты не производятся, это делается для того, чтобы все эти коэффициенты как надо подвязались. Вот такой процесс.
Наше ближайшее развитие, то, что я вижу в виде обозримого будущего.
- Управление МТР в части аварийного запаса;
- Модуль календарно-сетевого планирования;
- Модуль сводного планирования;
- Модуль мониторинга;
- Мобильное решение.
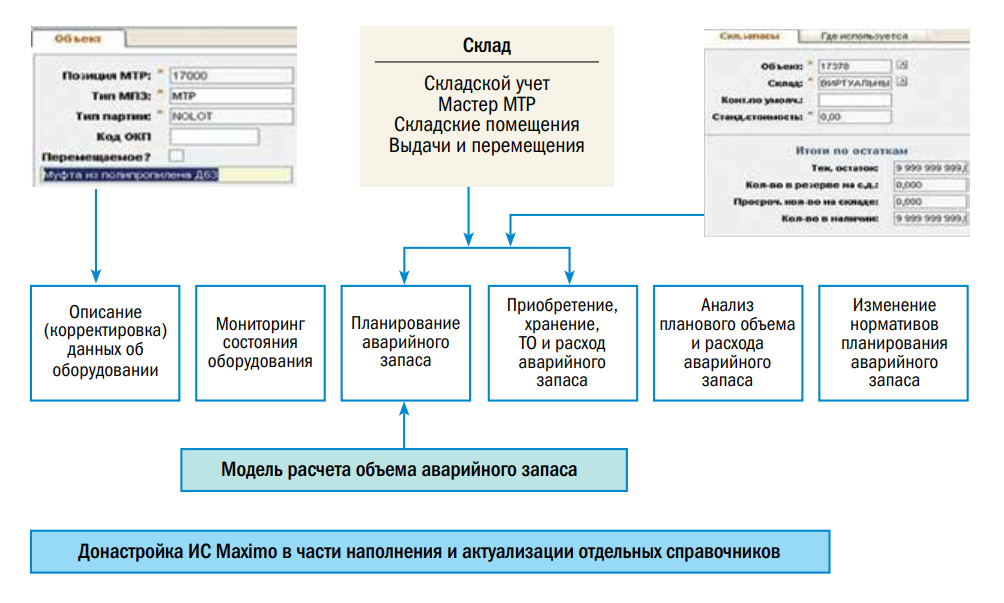
Управления МТР в части аварийного запаса. У нас есть стандарты. В соответствии с этими стандартами мы и ведём всю свою деятельность. Аварийный запас рассчитывается в разработанных расчетных модулях, в зависимости от состояния оборудования у
нас планируется необходимое количество аварийных запасов, которые должны быть на складе. И в системе мы реализовали механизм загрузки потребностей, сравнение с тем, что есть на складе, получение актуального перечня потребностей.
Управление МТР в части аварийного запаса:
• методология закреплена корпоративным стандартом;
- перечень и количество позиций аварийного и минимального неснижаемого запаса утверждено главным инженером;
- требуется разработка механизма поддержания в актуальном состоянии аварийного и минимального неснижаемого запаса на базе информационного продукта Maximo.
Следующим этапом будет механизм обслуживания аварийного запаса: есть запчасти, которые лежат на складе, их нужно обслуживать. Этот запас всё время должен меняться, потому что он не должен пролежать всю жизнь на складе.
Модуль мониторинга. Его задачи — упростить работу с данными, снизить риски, связанные с несвоевременным или некорректным потоком данных. Как уже говорилось, в компании создан аналитический центр, который занимается оценкой состояния основного оборудования. И для оценки состояния основного оборудования аналитическому центру всегда требуется информация об активах.
Информацию об активах можно получить тремя способами: 1) АСУ ТП, 2) во время капитальных ремонтов проводить какие-то испытания и замеры, 3) проводить ежедневные, периодические обходы, осмотры.
Модуль мониторинга мы готовы были запустить в эксплуатацию, но решили посмотреть, как изменится жизнь наших работников. Получилось следующее: оперативник берет журнал или бумажку и пошел по маршруту. Прошел, записал, сел и начинает заносить всё это в систему. То есть, по сути, делает двойную работу: сначала бумажка, потом система. Поэтому мы решили, что запустим модуль мониторинга одновременно с внедрением мобильного решения. Тогда у нас оперативный персонал будет ходить в обходы не с бумажкой, а с планшетом, и будет на месте регистрировать те значения параметров, которые необходимо снять.
Данное мобильное решение будет использоваться службой мониторинга, которая будет проводить испытания при капитальных ремонтах. Они прямо в систему будут заносить соответствующие результаты измерений. Логика расчетов достаточно простая и закладывается в систему, чтобы, придя на свое рабочее место, сотрудник распечатал соответствующие протоколы, соответствующие акты, подписал и положил в соответствующую документацию. Таким образом мы исключаем ошибки при переносе данных и двойной ввод.
Основные преимущества внедрения ИС Maximo
- Единый подход к планированию программ ремонтов.
- Повышение качества планирования программ ремонтов на будущий период за счет использования типовых технологических карт.
- Единые справочники услуг, материалов и запасных частей.
- Единые требования, предъявляемые в адрес подрядных организаций по вопросам отражения исполнения программ ремонтов.
- Возможность формирования оперативной отчетности по исполнению программы ремонтов на основе выполненных подрядчиком и принятых заказчиком в ИС Maximo работ.
- Возможность формирования тренда затрат по каждой единице оборудования для принятия корректных управленческих решений в будущем.
- Единые требования к организации сбора данных о состоянии производственных активов.
В результате внедрения мы повысили качество планирования программ ремонта на будущий период за счет использования типовых ведомостей, что позволяет прогнозировать бюджет.
У нас единый справочник услуг, материалов и запасных частей. Каждый может видеть, что лежит на соседнем складе, в соседнем филиале. По большому счету здесь речь идет о создании аварийных запасов. Возможность формирования тренда затрат по каждой единице оборудования в принципе делается, когда оборудование станций более-менее соответствует друг другу, как на Волжской и Жигулевской ГЭС. К примеру, был выявлен перекос в части ремонтного бюджета между Жигулевской и Волжской ГЭС, то есть там приблизительно одинаковый возраст станций, станции работают одинаково, однако затраты на ремонт одного агрегата у них отличались в два раза. Когда стали выяснять, оказалось, одни делали слишком много работ, другие слишком мало. В итоге сбалансировали, и сейчас стоимость ремонта за один агрегат на Волжской и Жигулевской ГЭС приблизительно одинакова. По остальным станциям такое сравнение можно сделать в рамках одной станции, а между двумя станциями нельзя. Единые требования к организации сбора данных о состоянии производственных активов. Это то, что сейчас предлагается в модуле мониторинга. Для того чтобы, условно говоря, провести оценку состояния различных генераторов на различных станциях, нужно предъявить единые требования филиалам, чтобы они эту информацию дали. Наша компания старается унифицировать все подходы для того, чтобы можно было в рамках унифицированной линии принимать экономические решения.

Журнал Prostoev.NET № 3(12) 2017
Автор: Рамазан Абакаров, департамент планирования и ремонтов технических сооружений и реконструкций ОАО «РусГидро»
Главная страница » Журнал «Простоев.НЕТ» » Информационная система управления фондами и активами ОАО «РусГидро» на базе IBM Maximo
Архитектура PlayStation 3, часть 1: Cell

Оригинальная статья глубоко описывает техническое строение консоли PlayStation 3, начиная с процессора, и заканчивая описанием борьбы с пиратством. В итоге статья вышла достаточно содержательной, но огромной по объему текста. Поэтому полностью публиковать перевод всей статьи не имеет практического смыла.
Вместо этого, перевод будет разбит на несколько частей, каждая из которых описывает одну большую или небольших тем из оригинала. Часть 1 описывает устройство процессора Cell. Если Вам данный цикл переводов будет интересен, то будут выложены и следующие части. А пока, приятного чтения!
1. Краткое введение
В 2006 году Sony выпустила долгожданную игровую консоль «следующего поколения». Это блестящая (хоть и тяжелая) машина, чья базовая аппаратная архитектура развивает идеи Emotion Engine из PS2, то есть фокусируется на векторных вычислениях для достижения высокой производительности, даже ценой сложности. И в то же время, их новый «суперпроцессор», Cell Broadband Engine, был разработан в эпоху кризиса инноваций. Он должен будет идти в ногу с развитием тенденций в области мультимедиа.
В этой статье подробно рассматривается совместный проект Sony, IBM, Toshiba и Nvidia, а также его реализация и влияние на индустрию.


1.1. О длине статьи
Я боюсь, что эта статья не будет из тех, которые я обычно пишу про другие консоли в данной серии статей. Если вы заинтересованы узнать про каждый технический аспект PlayStation 3, то вас ждёт увлекательное путешествие! Стоит отметить, что эта работа охватывает ~6 лет исследований и разработок, проведенных бесчисленным количеством инженеров. Поэтому я не ожидаю, что вы сможете переварить всё это за один раз. Пожалуйста, не торопитесь при чтении (и делайте перерывы при необходимости). Если в конце вам захочется ещё, то проходите в раздел «Источники»!
2. CPU
Время познакомится с самой узнаваемой и инновационной частью данной консоли.
2.1. Введение
Процессор PS3 сложно устроен, но он — удивительная инженерная работа, в которой пересекаются сложные потребности и необычные решения, выдающиеся в эпоху перемен и экспериментов. Итак, прежде чем мы перейдем к внутренностям процессора PS3, я написал следующие абзацы, чтобы привнести в статью некоторый исторический контекст. Следовательно, мы сможем разложить чип по кусочкам так, чтобы не только понимать, как он работает, но и почему были приняты те или иные главные конструкторские решения.
2.1.1. Состояние прогресса
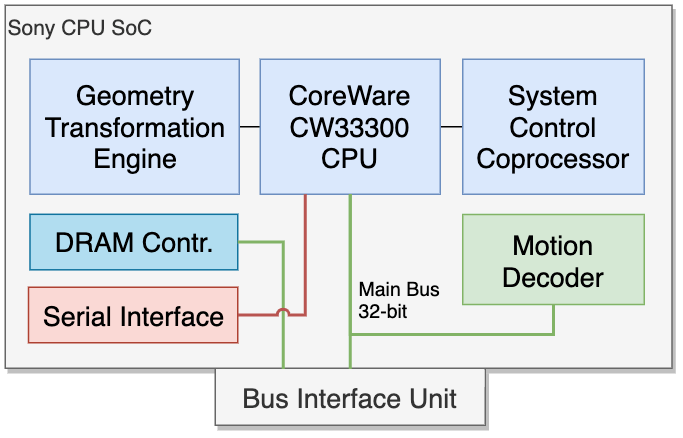
Прошло почти десять лет после выхода оригинальной PlayStation на процессоре MIPS, и мы находимся в начале 2000-х. В это время дела у SGI/MIPS шли не очень хорошо. Nintendo недавно отказалась от них в пользу бюджетного ядра PowerPC от IBM, в то время как Microsoft, будучи новичком на этом рынке, выбрала Intel и их доминирующую x86.
Ранее Sony брала существующие бюджетные решения (дешевые ядра MIPS) и модифицировала их так, чтобы получить приемлемую производительность в 3D при сниженных затратах. В этот процесс включались другие компании, будь то LSI (для процессора PS1) или Toshiba (для Emotion Engine). Эта методология использовалась до 2004 года с выпуском PlayStation Portable . Итак, какой новый MIPS-агрегат они собирались создать для PlayStation 3?
Оказывается, что разработка PlayStation 3 предшествует разработке PlayStation Portable [1]. В 2000 году, через месяцы после выхода PS2, Sony сформировала альянс совместно с IBM и Toshiba под названием «STI». Единственная цель альянса — создать чип, который мог бы работать в следующем поколении суперкомпьютеров [2]. Если это звучит недостаточно экстравагантно, то будущий чип также будет использоваться в преемнике PS2. В конце 2004 года IBM представила процессор Cell Broadband Engine (также известный как «Cell BE» или просто «Cell») [3].
2.1.2. Новые конструкторские решения
Чтобы понять радикальные решения в Cell, мы должны описать проблемы, которые были актуальны в данную эпоху (конец 90-х — начало 00-х).

С каждым годом потребители требуют всё больших скоростей. Это было всегда. Однако, последний подход, призванный это решить (конвейер данных и увеличение частот), теперь не справляется с масштабированием. Архитектура NetBurst от Intel не смогла развиваться дальше, а обещанный преемник так и не появился. Аналогично, IBM в своем PowerPC 970/G5 не смогла предоставить ни обещанных «3 ГГц», ни низкое энергопотребление (а значит, Apple не может поставлять ноутбуки с этим процессором) [4]. В общем, похоже, что инженеры столкнулись с новым кризисом масштабируемости.
Поэтому, фокус сместился на распределенные вычисления [5]. Другими словами, зачем увеличивать производительность одной машины, если вместо этого можно использовать несколько небольших машин, распределяющих рабочую нагрузку? Напротив, этот подход не является чем-то новым, поскольку все консоли, проанализированные на этом веб-сайте, содержат более одного процессора. Однако именно разработка «единого процессора с несколькими ядрами» открывает новые возможности для проектирования процессоров (которые могут использоваться не только в консолях).
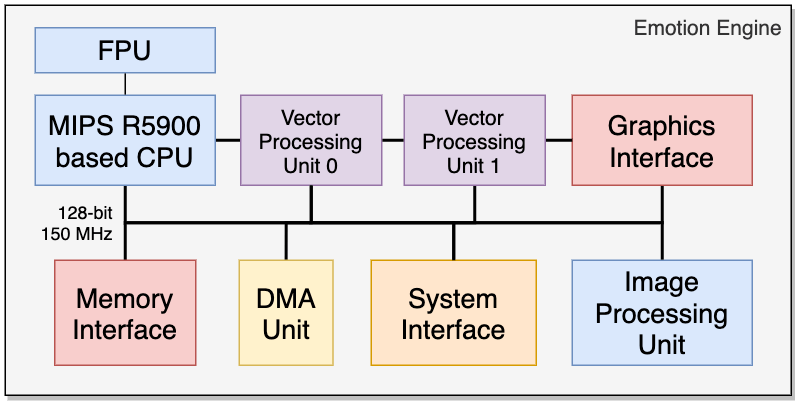
Следовательно, Cell является частью этой новой волны исследований и разработок. Новый процессор сочетает в себе многоядерный дизайн с особым акцентом на векторные вычисления. Если помните, векторные вычисления являются оптимальными для симуляций (физика, освещение и подобное). Эту задачу ранее выполняли Geometry Transformation Engine или два блока Vector Unit. Но вы также увидите, почему дизайн Cell является большим шагом вперед по сравнению с двумя предыдущими решениями.
2.1.3. Новая эра многоядерности
Если задуматься, то и процессор PS1, и Emotion Engine уже были многоядерными. Тогда почему же вокруг Cell было так много шума? Ну, два предыдущих чипа состояли из одного универсального ядра и нескольких ядер для конкретных задач (аудио-процессор, декомпрессия изображений). Эти ядра сочетали различные архитектуры, в которых универсальное ядро управляло другими ядрами.
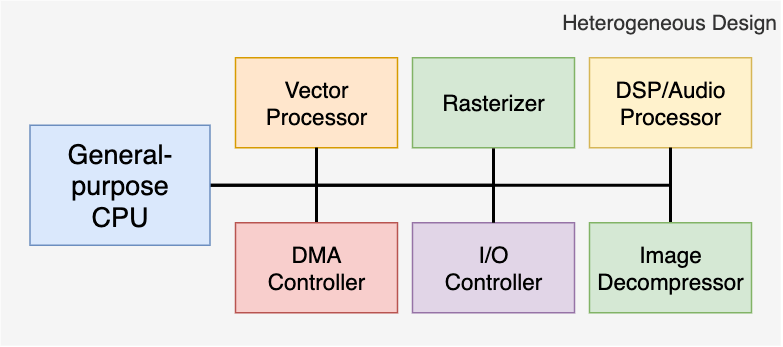
Этот тип архитектуры процессора относят к Гетерогенным вычислениям, и он являлся де-факто выбором для создания машин, которые предназначены для выполнения конкретных задач (в данном случае, игр). Аналог в виде Гомогенных вычислений более преобладает на рынке ПК, где процессоры должны выполнять более широкий круг задач (и все они имеют одинаковый приоритет). Поэтому, в последнем типе может быть несколько ядер одного и того же типа.
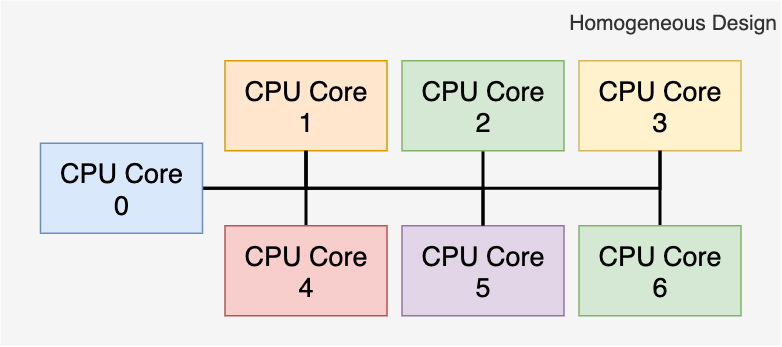
Возвращаясь назад к теме, Cell сочетает обе модели: в этом процессоре одно универсальное «главное» ядро и 8 векторных «вспомогательных» ядер. Эти векторные ядра могут принимать различные роли, и при этом они выполняют те предыдущие задачи, которые первоначально решались с помощью гетерогенных конструкций.
Поскольку ядра Cell не ограничиваются одним типом задач, то они обеспечивают гибкость гомогенных компьютеров. В целом, данный дизайн не идеален и содержит некоторые компромиссы, но на протяжении этой статьи вы увидите различные проблемы, которые попытается решить Cell, и как ему это удалось.
2.2. Взгляд на Cell
Рассказав всю эту историю и теорию, думаю, что мы готовы представить нашего главного героя этого раздела. Знакомьтесь, Cell:
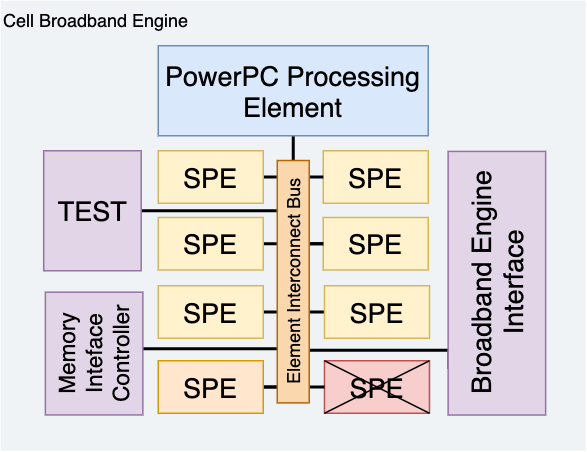
К концу этого раздела вы будете знать, что делает каждый компонент.
2.2.1. Общая архитектура
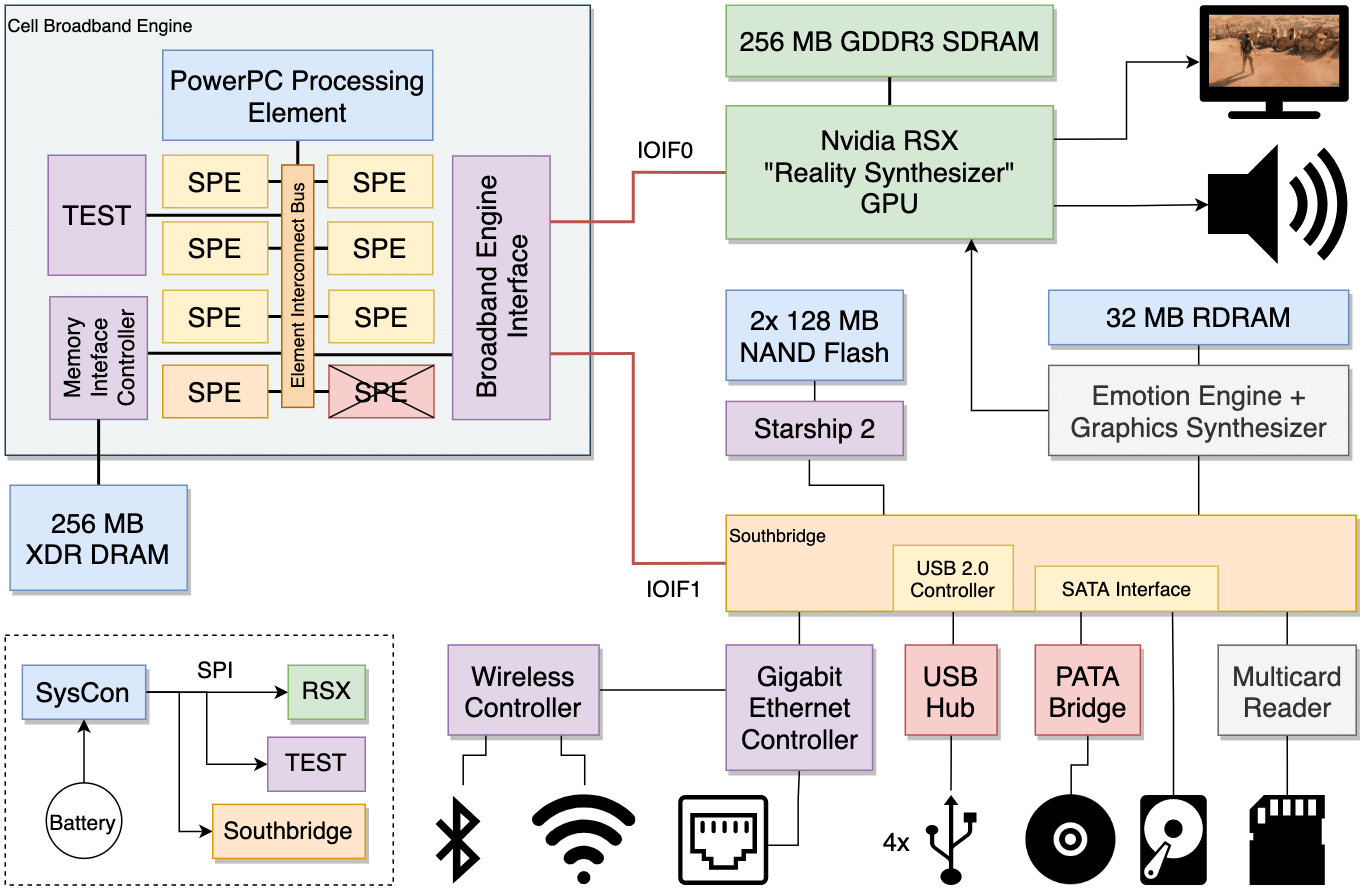
Cell работает на частоте в 3.2 ГГц и состоит из множества компонентов. Итак, для целей этого анализа этот процессор можно разделить на три основные части [6]:
- Управляющая: это часть Cell управляет остальной частью схемы. Здесь мы находим элемент под названием Power Processing Element (PPE).
- Вспомогательная: эта часть столь же важна, как и PPE, но возможности её элементов ограничены ролью помощника или ускорителя. Эта часть состоит из 8 элементов Synergistic Processing Element (SPE).
- Интерфейсная: так как потребность в пропускной способности растет экспоненциально, то внедряются новые интерфейсы для перемещения данных без создания узких мест. В этой группе мы находим несколько протоколов: шина Element Interconnect Bus (EIB), блок Broadband Engine Interface Unit (BEI), контроллер Memory Interface Controller (MIC) и шина Flex I/O.
Эта информация будет более подробно позже рассмотрена в статье, поэтому вам пока не нужно запоминать эти имена. Основная цель этого раздела — дать читателю мысленное представление о природе Cell и ознакомить со всеми компонентами, которые мы будем обсуждать в подходящее время.
2.2.2. Как организовано это исследование
Видя эту структуру, мне пришлось организовать её так, чтобы вам не надоело от большого количества информации. Поэтому мы собираемся проанализировать Cell путем изучения каждого его компонента в следующем порядке:
- Шина Element Interconnect Bus (EIB), которая соединяет все компоненты.
- PowerPC Processing Element (PPE) и его основной элемент PowerPC Processing Unit (PPU).
- Какая память общего назначения доступна в этой консоли.
- Блоки Synergistic Processing Element (SPE) и их основной элемент Synergistic Processing Unit (SPU).
- Модель программирования, разработанная для эффективного программирования под Cell.
Учитывая это, давайте приступим к настоящему анализу.
2.3. Cell изнутри: Сердце
С момента своего анонса Cell упоминается как сеть на кристалле (Network-on-Chip, NoC) [7] вместо стандартного определения «системы на кристалле» (System-On-Chip, SoC). Это связанно с неортодоксальной шиной данных чипа Element Interconnect Bus (EIB). До сих пор мы видели, насколько требовательными могут быть компоненты процессора, если учитывать, в какой степени система подвержена узким местам. Чтобы решить эту проблему в одиннадцатый раз, IBM разработала новый дизайн … и задокументировала его, используя термины, аналогичные дорожному движению.
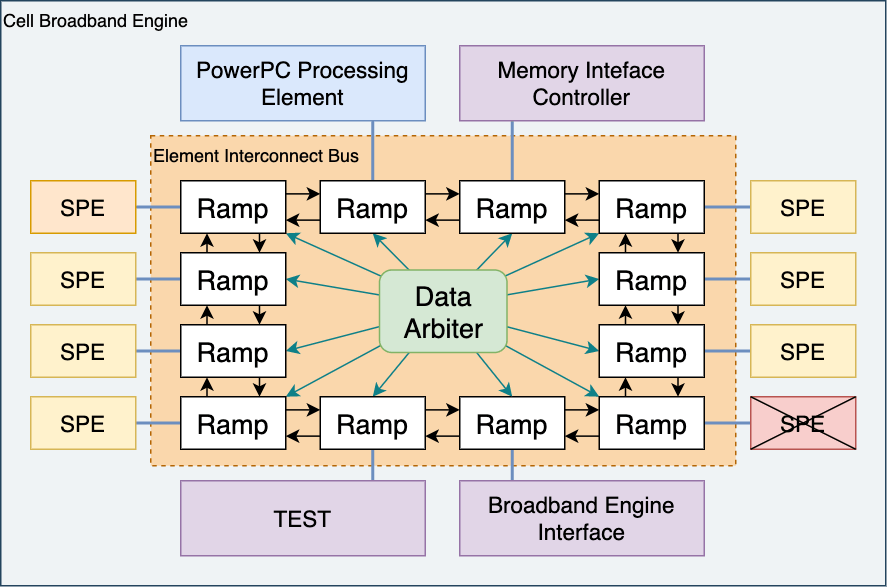
Шина EIB состоит из 20-ти узлов (рампы), каждый из которых соединяет один компонент Cell. Рампы соединены между собой с помощью четырех шин, две из которых работают по часовой стрелке, а другие две — прочив часовой. Каждая шина (или канал) имеет ширину в 128 бит. При этом вместо того, чтобы повторять топологию с одной шиной (как это делали в Emotion Engine и его предшественник), рампы соединены между собой по топологии «маркерного кольца» (token ring). В ней пакеты данных должны пройти через все соседние узлы, пока они не достигнут места назначения (прямого пути нет). Учитывая, что шина EIB предоставляет четыре канала связи, то для пакетов существуют четыре возможных маршрута (кольца).
Теперь вы можете подумать, в чем смысл маркерного кольца, если данные могут проходить более длинные пути (по сравнению с одной прямой шиной)? Ну, одна шина довольно сильно подвержена перегрузками данных. Поэтому инженеры шины EIB решили использовать эту топологию, чтобы обеспечить большой объем параллельного трафика (читайте дальше, если хотите узнать, как помогло данное кольцо).
Данные передаются в виде 128-битных пакетов [8]. Каждое кольцо может осуществлять до трех передач одновременно при условии, что пакеты не пересекаются. Шина EIB работает с использованием командных кредитов. Другими словами, всякий раз, когда компоненту нужно начать передачу, он отправляет запрос арбитру данных (Data Arbiter), который управляет трафиком внутри колец.
После утверждения запроса пакеты вводятся в кольцо и получают «маркер», который арбитр данных использует в качестве метаданных для контроля передачи. Кроме того, некоторые компоненты имеют более высокий приоритет, чем другие, например, контроллер Memory Interface Controller (MIC), в котором находится ОЗУ. Наконец, арбитр данных никогда не будет размещать пакеты в кольцах, путь которых длиннее половины кольца.
Каждая рампа участвует в передаче. Она читает адрес назначения пакета, чтобы знать, отправлять ли данные в свой компонент или передать их следующей рампе. Во время каждого тактового цикла рампы могут одновременно принимать и отправлять пакеты размером в 128 бит (16 байт). Итак, если учитывать наличие четырех каналов и частоту шины EIB в 1.6 ГГц (половина частоты Cell), то теоретическая максимальная скорость передачи составляет:
16 байт х 2 передачи/такт х 4 кольца х 1.6 ГГц = 204.8 ГБ/с
Конечно, это значение слишком оптимистичное, и есть много других внешних факторов (путь отправления или назначения, состояние шины), определяющих производительность. В любом случае, во многих исследовательских работах, выполненных IBM и другими авторами, были получены более реалистичные скорости с использованием практических экспериментов [9].
Теперь, когда вы увидели, как каждый компонент Cell связан между собой, пришло время рассмотреть первый компонент этого чипа.
2.4. Cell изнутри: Лидер
Здесь мы посмотрим на «главную часть» Cell. Это часть чипа, которая отвечает за управление остальной частью. Имя компонента — PowerPC Processing Element (PPE), и и его можно рассматривать как MIPS R5900 в Emotion Engine.
2.4.1. Состав PPE
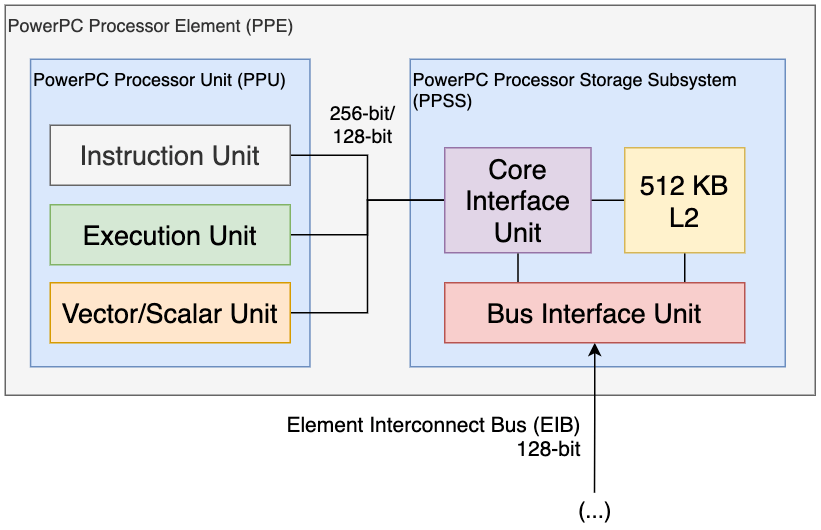
Помните, как я ранее разделил Cell на разные области? То же самое можно сделать с PPE. IBM использует термин «элемент» для описания независимой машины [10], но, описывая её изнутри, использует термин «юнит», чтобы отделить основную схему от интерфейсов, которые взаимодействуют с остальной частью Cell.
Исходя из вышесказанного, PowerPC Processing Element неожиданно состоит из двух частей:
- PowerPC Processing Unit (PPU): это логическая часть PPE («ядро» процессора). Не забывайте, что это не PPU от Nintendo! (хоть и они состоят из одних и тех же букв латинского алфавита. в том же самом порядке. ).
- PowerPC Processor Storage Subsystem (PPSS): большой интерфейс, который соединяет PPU с остальной частью Cell. Кроме того, он содержит огромный кэш L2 размером в 512 КБ.
Как вы можете видеть, архитектура PPE (и остального Cell) довольно модульная, что соответствует принципам архитектуры RISC. Вы скоро увидите, что модульность применяется даже внутри PPU.
2.4.2. PowerPC Processing Unit
Сейчас мы рассмотрим внутренности PPU. Напоминаю, мы сначала погрузились в Cell, потом в PPE, а затем в PPU. Мы проанализируем PPU так же, как и любое другое ядро процессора.
2.4.2.1. Знакомая архитектура
Начнем с того, что PPU не создан с нуля, а cтроится на основе существующей архитектуры PowerPC. Однако, в отличие от предыдущих итераций, когда IBM брала существующий процессор и немного обновляла его для соответствия новым требованиям, PPE не является преемником какого-либо предыдущего дизайна процессора.
Вместо этого IBM создала новый процессор, который реализует спецификацию PowerPC версии 2.02 (это последняя спецификация PowerPC перед ребрендингом в «Power ISA»). Суммируя вышесказанное, можно сказать, что с этого времени вы не найдете такой же дизайн PPU ни в одном существующем чипе того времени. Но он имеет те же машинные коды, что и в других чипах PowerPC.
Тем не менее, почему IBM выбрала архитектуру PowerPC для разработки высокопроизводительного чипа? Просто, PowerPC — это зрелая платформа [11], которая в течение 10 лет тестировалась на пользователях Macintosh и постоянно обновлялась. Она соответствует всем требованиям Sony, и, если возникнет такая необходимость, её можно адаптировать к различным средам.
Последнее, но тем не менее важное: использование хорошо известной архитектуры является благоприятным для существующих компиляторов и кодовых баз, что для новой консоли — большое стартовое преимущество.
Стоит отметить, что IBM была одним из автором первых чипов PowerPC совместно с Motorola и Apple (вспомните об альянсе AIM). Как бы то ни было, к началу 00-х годов так называемые участники альянса уже работали отдельно, где Motorola/Freescale разрабатывали отличную от IBM серию PowerPC.
2.4.2.2. Отличительные особенности
PPU имеет общую историю с PowerPC 970 (Apple называла его G5). Оба являются потомками POWER4, предшественника PowerPC, который в основном использовался в рабочих станциях и суперкомпьютерах. Это станет более очевидным, когда я скоро покажу вам модульные исполнительные устройства. Это радикальное изменение по сравнению с процессором линейки 750 в GameCube, который имел значительный вклад от Motorola, но затем был слегка изменен IBM.
Возвращаясь к теме, PPU — полноценный 64-битный процессор. Это означает, что:
- Размер машинного слова — 64 бита.
- Наличие 64-битных регистров общего назначения (всего их 32).
- Шина данных, как минимум, шириной в 64 бита. В следующих главах статьи вы увидите она гораздо длиннее, но пока имеете в виду, что передача 64-битных слов не снижает производительность.
- Адресная шина имеет ширину в 64 бита. В теории, процессор может адресовать до 16 экзабайт памяти. На практике это очень дорого обходится, если машина не вмещает всю эту память. Поэтому современные процессоры делегируют адресацию блоку управления памятью (Memory Management Unit, MMU), чтобы обеспечить больше возможностей для использования адресной шины.
Наконец, PPU реализует набор инструкций PowerPC версии 2.02, включая опциональные опкоды для квадратного корня с плавающей точкой [12]. Ядро также было расширено группой SIMD-инструкций, называемых Vector/SIMD Multimedia Extension (VMX). С другой стороны, в первоначальной спецификации нет некоторых элементов, в частности, режима little-endian (Cell работает только в режиме big-endian) и нескольких опкодов.
2.4.3. Строительные блоки PPU
Применяя «микроскопический» вид к PPU, мы можем видеть, что это устройство состоит из различных блоков или подблоков, выполняющие независимые операции (загрузка значений из памяти, выполнение арифметики и так далее). Возможности PPU определяются тем, что и как может делать каждый блок:
2.4.3.1. Инструкции
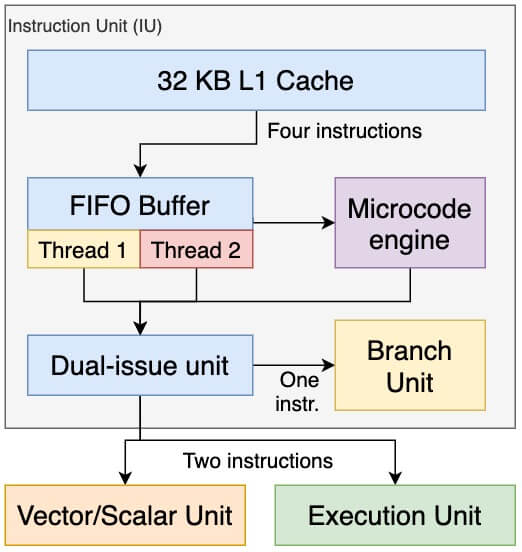
Первый блок называется блоком команд (Instruction Unit, IU). Как следует из названия, он берёт инструкции из кэша L2 и даёт сигналы другим устройствам для выполнения запрошенной операции. Как и в современниках i686, часть набора инструкций интерпретируется при помощи микрокода (для этого IU включает в себя небольшой ROM). Наконец, в IU также размещен кэш L1 размером в 32 КБ для инструкций.
Обработка инструкции осуществляется с помощью 12-уровневого конвейера, хотя на практике общее количество уровней будет сильно различаться в зависимости от типа инструкции. Например, модуль предсказания переходов может пропустить большую часть конвейера. Если мы объединим IU с соседними блоками, то финальное число уровней часто приближается к 24 (да, это большое число, но помните, что Cell работает на частоте 3.2 ГГц).
Теперь самое интересное: IU имеет двойную обработку (dual-issue): в некоторых случаях IU может обработать до двух инструкций за такт, что значительно повышает пропускную способность. На практике, однако, существует множество условий для того, чтобы это работало, поэтому программисты или компиляторы отвечают за оптимизацию своих процедур, чтобы их последовательность инструкций могла использовать преимущества этой функции.
Кстати, двойная обработка реализована и в других процессорах, и этот термин может различаться между производителями. Поэтому я использовал определение от IBM.
В довершение всего, IU также многопоточный, то есть блок может одновременно выполнять две разные последовательности инструкций (называемых «потоками»). За кулисами, IU просто чередуется между двумя потоками за такт, создавая иллюзию многопоточности. По какой-то причине это поведение похоже на то, что в данный момент Intel определяет как hyper-threading. Возможно, что последнее ещё не было придумано. Тем не менее, многопоточность от IBM смягчает нежелательные эффекты, такие как остановка конвейера, поскольку процессор больше не будет блокироваться всякий раз, когда одна инструкция блокирует поток.
Чтобы достичь многопоточности, инженеры IBM продублировали внутренние ресурсы IU, включая регистры общего назначения (ранее я говорил, что регистров 32, но это для одного потока. В реальности их всего 64!). Однако ресурсы, которые не относятся спецификации PowerPC (например, кэш L1 или L2, интерфейсы), по-прежнему общие для потоков. Такие образом, ресурсы — однопоточные.
В общем, объединяя два потока с двойной обработкой, IU способен выполнять до четырех инструкций за такт. Несмотря на то, что это «наилучший сценарий», он все ещё предоставляет возможности оптимизации, которые пользователи в конечном итоге заметят в частоте кадров игры!
2.4.3.2. Управление памятью
Следующие блоки дают PPU возможность выполнения инструкций загрузки/сохранения и осуществлять управление памятью.
Начнем с того, что блок загрузки/сохранения (Load-Store Unit, LSU) выполняет опкоды «load» и «store», используя 32 КБ кэша данных L1. Как следствие, этот блок имеет прямой доступ к памяти и регистрам.
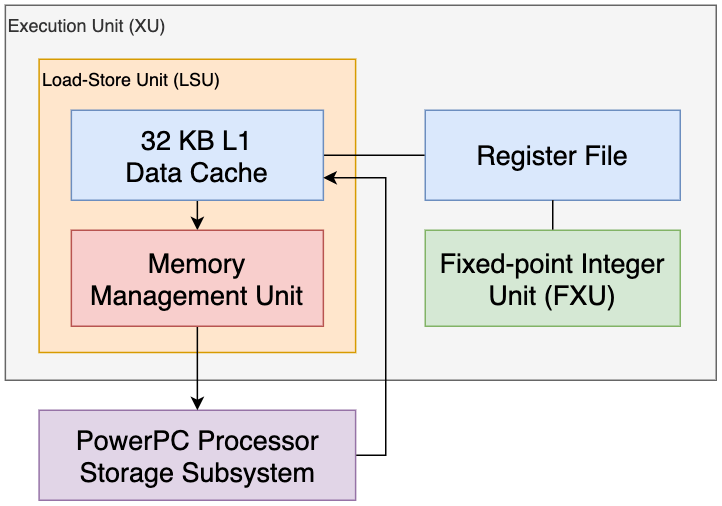
Кроме того, LSU содержит Memory Management Unit (MMU), который является обычным явлением в современном оборудовании. Короче говоря, MMU занимается адресацией памяти с помощью таблицы виртуальных адресов в сочетании с защитой памяти. Для улучшения последней MMU, в частности, оснащен сегментным блоком, который группирует адреса памяти, используя диапазоны под названием «сегменты». Также, что предотвратить снижение производительности в процессе работы, были включены Translation Lookaside Buffer (TLB) (кэширует преобразованные адреса) и Segment Lookaside Buffer (SLB) (кэширует сегменты).
2.4.3.3. Арифметика
Осталось объяснить всего два блока PPU, которые вычисляют математику, необходимую для любой игры.
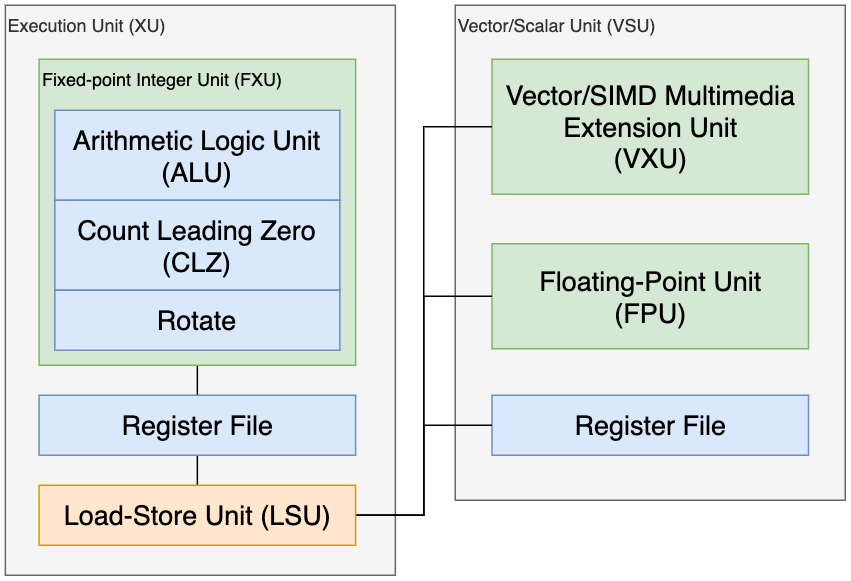
Первый блок — традиционное АЛУ Fixed-Point Integer Unit (FXU). Оно осуществляет целочисленные вычисления: деление, умножение, циклический сдвиг (схоже с обычным сдвигом, только уходящие биты возвращаются с конца) и нахождение ненулевого бита (например, оно полезно для нормализации координат вершины). Его конвейер длиной в 11 уровней.
Если вы посмотрите на диаграмму, вы увидите, что FXU, LSU и MMU объединены в один блок под названием исполнительный блок (Execution Unit, XU). Это потому, что они имеют один и тот же регистровый файл.
Второй блок куда более интересный. Vector/Scalar Unit (VSU) выполняет операции с числами с плавающей точкой и векторами. Он состоит из 64-битного блока FPU (на основе стандарта IEEE 754) и блока Vector/SIMD Multimedia Extension (VXU), который исполняет набор SIMD-инструкций под названием VMX. Эти вектора длиной в 128 бит состоят из двух или трех 8/16/32-битных значений.
Возможно, вы уже слышали об расширении «VMX» раньше. Оно также называется «Altivec» у Motorola или «Velocity Engine» у Apple (да здравствуют торговые марки). И наоборот, конкурентные возможности SIMD в Cell можно найти и в другом процессоре, так что пока не расслабляйтесь!
2.4.4. Суммируя PPE
Вы только что видели, как работает PPE и что было сделано, но что это всё значит для разработчика?
В конце концов, PowerPC Processing Element — единственный процессор общего назначения на чипе. Но есть одно но: он не должен работать в одиночку. Помните ту широкую главную шину (EIB)? IBM разработала PPE так, чтобы инженеры могли совмещать его с другими процессорами для ускорения конкретных задач (высокопроизводительные вычисления, 3D-графику, научные симуляции, работа с сетями, обработка видео). Так как эта статья о PlayStation 3, то вы увидите, что остальная часть Cell отвечает за обработку графики и физики, поэтому в дальнейшем мы будем описывать эту часть.
2.5. Cell снаружи: Основная память
Давайте немного уйдем в сторону от Cell. Не столь важно то, насколько хорош PPE, если у нас нет подходящего рабочего пространства (памяти), чтобы заставить его работать.
Поэтому Sony добавила ОЗУ в виде XDR DRAM памяти объемом 256 МБ. Но опять-таки, что это всё значит? Для ответа на это, на нужно взглянуть на то, как работают блоки памяти и как они подключаются к Cell.

Прежде всего, тип установленной памяти называется Extreme Data Rate (XDR). Вы можете думать о XDR DRAM, как о преемнике прóклятой RDRAM, установленной в Nintendo 64 и PlayStation 2. Но пока не спешите с выводами!
Rambus, как и любая другая компания, совершенствует свои изобретения. Их третья версия (XDR) теперь передает за такт 8 бит (это в 4 раза больше, чем у DDR DRAM) [13]. Задержка больше не создает проблем. Если мы посмотрим на данные одного из производителей, то задержка XDR составляет от 28 до 32 наносекунд [14], что почти в 10 раз быстрее, чем первое поколение чипов RDRAM.
Первая ревизия материнской платы PlayStation 3 содержит 4 чипа по 64 МБ, которые обрабатываются парами. XDR подключен к Cell, используя две 32-битных шины, по одной на каждую пару. Поэтому когда PPU записывает слово (64-битные данные), оно разделяется между двумя чипами XDR.
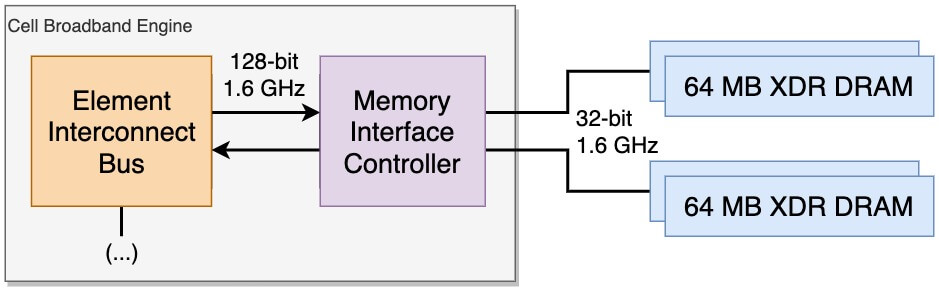
Cell соединяется с чипами XDR при помощи Memory Interface Controller (MIC), другой компонент внутри Cell (как и PPE). Дополнительно, MIC буферизирует передачи памяти для улучшения пропускной способности, но имеет одно ограничение: выравнивание больших байтов.
По сути, при передаче наименьший размер данных MIC составляет 128 байт, что хорошо работает для последовательного чтения и записи. Но если данные меньше, чем 128 байт, или требуется чередование между записью и чтением, то возникают проблемы с производительностью.
Тем не менее, является ли MIC узким местом или нет? Вы должны взглянуть на это в перспективе того, что оптимизация пропускной способности имеет решающее значение в системах, которые зависят от данных. В прошлом мы видели такие решения, как write-gather pipe или write back buffer. Поэтому MIC — просто новое предложение по решению повторяющейся проблемы.
Как бы то ни было, Sony утверждает, что скорость передачи данных составляет 25.6 ГБ/с. Однако на практике существует слишком много факторов, которые будут определять конечную скорость (вы видели, насколько сложно перемещать данные из одного места в другое в Cell).
Это все, что касается ОЗУ, но есть ещё больше памяти в другом месте: жесткий диск. PS3 позволяет играм использовать 2 ГБ на внутреннем жестком диске в качестве рабочей области (аналогично тому, что было в оригинальном Xbox) [15].
2.6. Cell изнутри: Помощники
Мы уже видели ранее, что Sony всегда добавляет к процессору общего назначения (в данном случае, PPE) дополнительные ускорители для достижения приемлемой производительности в играх (блоки VPU и IPU в случае с PS2; или GTE и MDEC с PS1).
Это обычная практика для аппаратного обеспечения игровых консолей, поскольку универсальный процессор может выполнять широкий спектр задач, при этом ни на чем не специализируясь. Консолям требуется лишь некоторый набор навыков (например, физика, графика и аудио), поэтому сопроцессоры позволяют им справляться с этими задачами.
[PPE] — это версия, которую урезали для снижения энергопотребления. Поэтому у неё нет тех лошадиных сил, как, например, у Pentium 4. Если взять код, который работает сейчас на Intel и AMD, независимо от мощности, и перекомпилировать его для Cell, то он будет работать — ну, может вам придется изменить одну, две библиотеки. Но полученный код будет примерно на 50-60% медленнее, и люди будут кричать «Боже мой! Этот процессор Cell ужасен!» Но это потому, что вы используете только одну его часть [16].
– Доктор Майкл Перроне, менеджер Отдела по разработке Cell, Исследовательский Центр IBM TJ Watson
Ускорители, входящие в состав Cell на PS3, это элементы Synergistic Processor Element (SPE). В Cell их восемь, однако один элемент отключается во время запуска консоли. Это связано с тем, что производство микросхем требует исключительной точности (изначально Cell создавался при техпроцессе в 90 нм), а оборудование не является совершенным.
Поэтому вместо того, чтобы выбрасывать схемы, которые оказались бракованными менее чем на 10%, Cell включает один запасной SPE. Таким образом, если один из них выходит из строя, весь чип не отбраковывается. Теперь этот запасной SPE всегда будет отключен, независимо от того, хорошо ли это или нет (у Sony не может быть две PS3 с разными версиями процессора на рынке).
2.6.1. Состав SPE
Двигаясь дальше, Synergistic Processor Element (SPE) — крошечный независимый компьютер внутри Cell, управляемый PPE. Помните, что я рассказывал ранее о принятии элементов из гомогенных вычислений?
Что ж, эти сопроцессоры в некоторой степени универсальны и не ограничиваются одним приложением, поэтому они смогут помогать в решении широкого круга задач, то есть до тех пор, пока разработчики смогут их правильно запрограммировать.
Как и в случае с PPE, мы рассмотрим SPE поподробнее. Это будет кратко, поэтому, если в конце вы хотите узнать больше о SPE, ознакомьтесь с разделом «Источники» в конце статьи. Итак, давайте начнем.
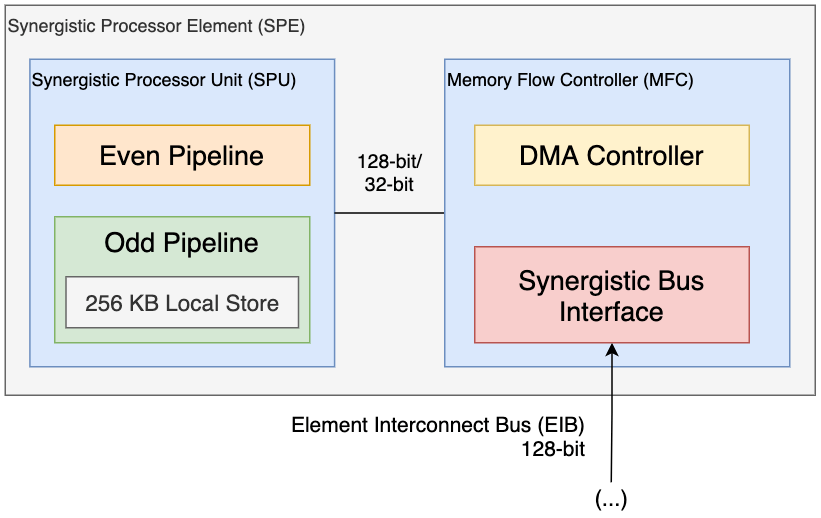
SPE — это процессор, который похож структурно на PPE, состоит из 2 частей: Memory Flow Controller и Synergistic Processor Unit.
2.6.1.1. Memory Flow Controller
Memory Flow Controller (MFC) — это блок, который находится между ядром и остальной частью Cell. Он является аналогом PowerPC Processor Storage Subsystem (PPSS) в PPE. Основная задача MFC — перемещать данные между локальной памятью SPU и основной памятью Cell, а также синхронизировать SPU со его соседями.
Для выполнения своих обязанностей MFC содержит в себе контроллер DMA, чтобы поддерживать связь между шиной EIB и локальной памятью SPU. Кроме того, MFC содержит другой компонент под названием Synergistic Bus Interface (SBI), который находится между шиной EIB и контроллером DMA.
Это довольно сложная схема для обобщения, но она в основном интерпретирует команды и данные, полученные извне, и подает сигналы внутренним блокам SPE. Являясь входной дверью для Cell, SBI работает в двух режимах: ведущая шина (master) (где SPE адаптирован для запросов данных снаружи) и ведомая шина (slave) (где SPE настроен на прием запросов извне).
Любопытный факт: если учитывать ограничение пакетов EIB (длиной до 128 бит), то в MFC блок DMA может перемещать только до 16 КБ данных за такт, иначе EIB вызовет исключение «Bus Error» во время выполнения [17].
2.6.1.2. Synergistic Processor Unit
Блок Synergistic Processor Unit (SPU) — это часть SPE, в котором находится основной процессор, аналогично «PPU» в PPE.
В отличии от PPU, SPU изолирован от остальной части Cell. Следовательно, между PPU или другими блоками SPU нет общей памяти. Вместо этого SPU содержит локальную память, используемую в качестве рабочей области. Однако, содержимое локальной памяти можно перемещать туда и обратно с помощью MFC.
Что касается функциональности, то SPU гораздо более ограничены, чем PPU. Например, SPU не включает в себя никаких функций управления памятью (трансляция адресов или защита памяти) и даже самых современных функций (динамическое предсказание переходов). Тем не менее, он исключительно хорошо выполняет векторные вычисления.
Для программирования этого блока разработчики используют PPU для вызова процедур, предоставляемых ОС PlayStation 3. Эти процедуры загружают исполняемый файл, специально написанный для SPU, в выбранный SPU и дают ему сигнал начать выполнение. После этого PPU сохраняет ссылку на поток SPU для дальнейшей синхронизации [18].
2.6.2. Архитектура SPU
Как и любой процессор, Synergistic Processor Unit (SPU) имеет собственную архитектуру набора команд (ISA). Оба SPU и PPU следуют методологии RISC, однако, в отличии от PPU (который реализует архитектуру PowerPC), архитектура SPU — проприетарная и в основном состоит из инструкций SIMD-типа.
В результате, в SPU есть 128 128-битных регистров общего назначения, которые хранят вектора из 32/16-битных целочисленных чисел или чисел с плавающей точкой. С другой стороны, чтобы сэкономить память, инструкции SPU маленькие, длиной 32 бита. Первая часть содержит код операции, а остальные могут ссылаться на три операнда, которые вычисляются параллельно.
Это очень похоже на предыдущий блок Vector Floating Point Unit из PS2, но с тех пор многое что изменилось. Например, SPU не требует, чтобы разработчики изучали новый проприетарный язык ассемблера. IBM и Sony предоставляли инструментарий для программирования на SPU, используя C или C++.
В плане архитектуры этот процессор не выполняет все инструкции, используя один и тот же блок. Вместо этого выполнение делится на две части или «конвейер исполнения», один из которых называется нечётный конвейер, а другой — чётный конвейер. Эти два конвейера выполняют различные типы инструкций, позволяя SPU обрабатывать две инструкции за такт когда это возможно. С другой стороны, SPU никогда не будет работать с двумя инструкциями, которые зависят друг от друга, и, таким образом, смягчая потенциально возможные конфликты данных.
Давайте теперь посмотрим на два конвейера [19]:
2.6.2.1. Нечётный конвейер
Нечетный конвейер выполняет большинство инструкций, кроме арифметических. Прежде всего, вы найдете в SPU блок загрузки/сохранения (SLS), который делает три важные вещи:
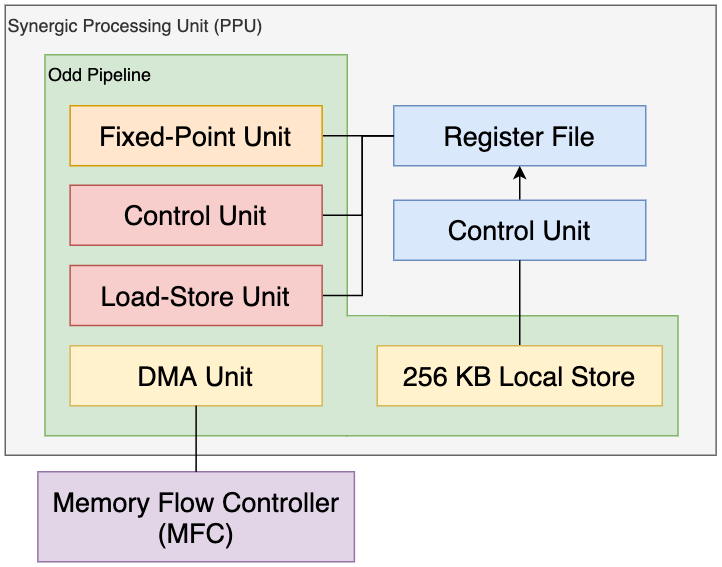
- Содержит локальную память в 256 КБ для хранения инструкций и данных. Тип встроенной памяти однопортовый (учитывая, что это критическая область, немного разочаровывает, что они не использовали двухпортовые чипы. ). Кроме того, адресная шина длиной в 32 бита.
- Выполняет загрузку и хранение инструкций.
- Передает инструкции другому блоку для обработки.
Обратите внимание, что для хранения программы доступно только 256 КБ. Учитывая, что программы SPU могут быть скомпилированы с помощью C/C++, трудно предсказать, насколько велика будет программа. По этой причине рекомендуется, чтобы программы думали, что имеется только половина доступной памяти (128 КБ) [20]. Это оставляет достаточно места, чтобы скомпилированный код занимал столько места, сколько ему нужно, хотя это и происходит за счет хранилища и эффективности.
Наконец, есть также блок SPU Channel and DMA Transport (SCC), который контроллер Memory Flow использует для заполнения и/или получения локальной памяти, и хилый АЛУ Fixed-Point Unit, который умеет только перемешивать и поворачивать вектора.
2.6.2.2. Чётный конвейер

Четный конвейер отличается своими арифметическими возможностями. Здесь мы находим настоящий блок АЛУ Fixed-point Unit (FXU), который выполняет основные арифметические, логические операции (И, ИЛИ и другие), битовые сдвиги.
И последнее, но не менее важное: есть математический блок Floating-point Unit (FPU), который выполняет операции с числами одинарной точности (32-битные float ), двойной точности (64-битные double ), а также с целыми числами (32-битные int ). Это соответствует стандарту IEEE с некоторыми отклонениями (значения float ведут себя аналогично в PS2.
2.7. Cell изнутри: Стили программирования
Поскольку мы дошли до конца Cell, вы можете спросить — как разработчики должны работать с этим монстром? Аналогично предыдущим моделям программирования, разработанным для Emotion Engine, IBM предложила следующие подходы [21]:
2.7.1. Подходы, ориентированные вокруг PPE
Эти подходы представляют собой набор паттернов программирования, которые возлагают основные обязанности на PPE и оставляют SPE для разгрузки. Есть три возможных паттерна:
- Модель многоуровневого конвейера: PPE поручено отправлять работу одному SPE, который, в свою очередь, выполняет необходимые вычисления и передает результаты следующему SPE. Это продолжается до тех пор, пока последний SPE в цепочке не отправит обработанные данные обратно в PPE.
- По очевидным причинам IBM не предлагает данный подход для основных задач, так как для него требуется значительной пропускной способности, и его, как правило, трудно поддерживать.

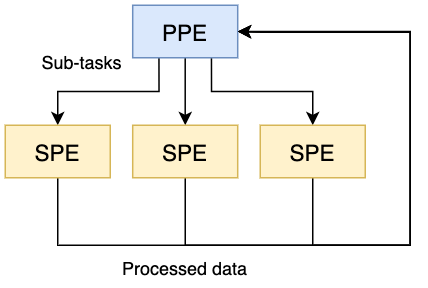
- Модель параллельных уровней: PPE разделяет свою главную задачу на независимые подзадачи и отправляет каждую из них разным SPE. Затем каждый SPE возвращает обработанные данные в PPE после их завершения, и в конце PPE объединяет их для получения конечного результата.
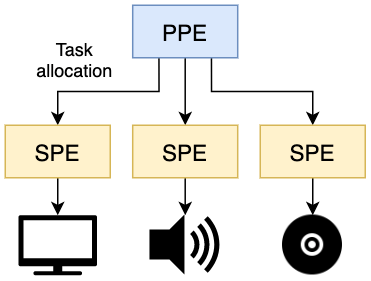
- Модель сервисов: каждому SPE назначается одна задача ( декодирование MPEG, стриминг аудио, перспективная проекция, вершинное освещение и прочее), а PPE отвечает за отправку необработанных данных конкретному SPE. В ожидании результата PPE выполняет другие функции.
- Хоть это и подразумевает, что у каждого SPE будет одна задача, они не должны исполнять её вечно. PPE должен переопределять другие задачи на лету по мере изменения потребностей программы.
2.7.3. Подходы, ориентированные вокруг SPE
Вместо того, чтобы использовать блоки SPE для обслуживания PPE, есть другой подход. Используя внутренний DMA, блоки SPE получают и выполняют задачи, хранящиеся в основной памяти, в то время как PPE ограничивается управлением ресурсами.

Эта модель гораздо более радикальна, чем остальные, в том смысле, что предыдущие модели ближе к традиционным и похожи на парадигму «универсальный процессор со сопроцессорами», применяемую в ПК. Поэтому кодовые базы, реализующие алгоритмы вокруг SPE, может быть сложнее перенести на другие платформы.
2.8. Вывод
Как вы можете себе представить, в то время как многоядерная архитектура Cell ускоряет появление новых технологий, таких как процедурная генерация, ни одна из этих архитектур не особо проста в реализации. Также нужно учитывать, что игровые студии предпочитают такие кодовые базы, которые могут быть общими для разных платформ.
Для примера, разработчики движка Unreal Engine 3 (Epic Games) демонстрировали ограничения SPU, пытаясь реализовать свою систему обнаружения коллизий [22]. Их реализация опирается на двоичном разбиении пространства (Binary Space Partitioning, BSP), алгоритм, который сильно зависит от сравнений (ветвлений).
Поскольку блоки SPU не обеспечивают динамические предсказания переходов, как PPU, их реализация разочаровала пользователей PlayStation 3 по сравнению с другими платформами (Xbox 360 или i386) на ПК, оба из которых обеспечивают продвинутые техники предсказания во всех своих ядрах). Следовательно, Epic Games пришлось прибегать к дальнейшим оптимизациям, совместимыми только с Cell.
Я полагаю, что для разработчиков ПО полностью раскрыть потенциал Cell — это вопрос времени, терпения и большого объема знаний. Однако история показала, что это возможно не для каждой студии. Это заставляет меня задуматься, не в этом ли причина того, нынешнее железо консолей (по состоянию на 2021 год) так сильно гомогенизировалось.
Источники про Cell
- ibm.com, The Cell Broadband Engine. ↩︎
- Sandeep Koranne, Practical Computing on the Cell Broadband Engine. ↩︎ Page 5 ↩︎, Page 62 ↩︎,
- Arevalo et al., Programming the Cell Broadband Engine™ Architecture. IBM Redbooks. Page 8 ↩︎,
- IBM Research, The Cell architecture. Archived. ↩︎
- H. Peter Hofstee, Ph.D, Shared-Memory Heterogeneous Computing.
- Jim Dalrymple and Peter Cohen, New G5s announced; no 3GHz or G5 laptops ‘any time soon’. Macworld. ↩︎
- Samsung Electronics, K4Y5016(/08/04/02)4UC datasheet — Version 0.3. Page 2 ↩︎,
- Thomas Chen et. al., Cell Broadband Engine Architecture and its first implementation — A performance view. Archived. ↩︎
- International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation, Software Development Kit for Multicore Acceleration — Programming Tutorial — Version 3.0. Page 13 ↩︎, Page 23 ↩︎,
- Rosquete, Daniel & Pérez, José & Futrillé, Daniel & Larrazabal, German, HPC on Playstation 3?. 2009. ↩︎ Page 4 ↩︎,
- Sony Computer Entertainment, Cell Broadband Engine Architecture — Version 1.01. 2006. ↩︎ Page 183 ↩︎, Page 32 ↩︎,
- The Associated Press, IBM unveils long-awaited ‘Cell’ chip. 2005. ↩︎
- MIT OpenCourseWare, L2: Introduction to Cell Processor. ↩︎
- Newcastle University, Lesson 1 — Introduction to SPU programming. ↩︎
- Anand Lal Shimpi & Derek Wilson, Microsoft’s Xbox 360, Sony’s PS3 — A Hardware Discussion. ↩︎
- Euss Et al., Files on the PS3. PS3 Developer Wiki. ↩︎
- Prof. Hyesoon Kim, Design and Programming of Game Console. ↩︎
- Jack Robertson, Rambus discloses details of new XDR DRAM interface. EETimes, 2003. ↩︎
- игровые консоли
- playstation
- emotion engine
- cell
- playstation 2
- playstation 3