Неформальное введение в Python
В приведенных далее примерах, ввод и вывод различаются присутствием и отсутствием приглашений соответственно (приглашениями являются >>> и . ): чтобы воспроизвести пример — вам нужно ввести всё, что следует за приглашением, после его появления; строки, не начинающиеся с приглашений являются выводом интерпретатора. Обратите внимание, что строка, в которой содержится лишь вспомогательное приглашение («. ») означает, что вам нужно ввести пустую строку — этот способ используется для завершения многострочных команд.
Большинство примеров в этом руководстве — даже те, которые вводятся в интерактивном режиме — содержат комментарии. Комментарии в Python начинаются с символа решетки # — и продолжаются до физического конца строки. Комментарии могут находиться как в начале строки, так и следовать за пробельными символами или кодом — но не содержаться внутри строки. Символ решётки в строке остаётся лишь символом решётки. Поскольку комментарии предназначены для того, чтобы сделать код более понятным, и не интерпретируются Python — при вводе примеров они могут быть опущены.
# это первый комментарий spam = 1 # а это второй комментарий # . а сейчас третий! text = "# Это не комментарий, потому что он внутри кавычек."
Использование Python в качестве калькулятора
Давайте опробуем несколько простых команд Python. Запустите интерпретатор и дождитесь появления основного приглашения — >>> . (Это не должно занять много времени).
Числа
Поведение интерпретатора сходно поведению калькулятора: вы вводите выражение, а в ответ он выводит значение. Синтаксис выражений привычен: операции + , — , * и / работают также как и в большинстве других языков (например, Паскале или C); для группировки можно использовать скобки ( () ). Например:
>>> 2 + 2 4 >>> 50 - 5*6 20 >>> (50 - 5*6) / 4 5.0 >>> 8 / 5 # деление всегда возвращает число с плавающей точкой 1.6
Целые числа (например, 2 , 4 , 20 ) имеют тип int, те, что с дробной частью, (e.g. 5.0 , 1.6 ) имеют тип float. Мы узнаем больше о числовых типах далее в руководстве.
Деление ( / ) всегда возвращает float. Чтобы сделать целочисленное деление (отметая дробную часть) вы можете использовать оператор // ; чтобы посчитать остаток от деления, вы можете использовать % :
>>> 17 / 3 # классическое деление возвращает float 5.666666666666667 >>> >>> 17 // 3 # floor division discards the fractional part 5 >>> 17 % 3 # the % operator returns the remainder of the division 2 >>> 5 * 3 + 2 # result * divisor + remainder 17
С помощью Python можно использовать оператор ** для возведения в степень [1]:
>>> 5 ** 2 # 5 squared 25 >>> 2 ** 7 # 2 to the power of 7 128
Знак равенства ( = ) используется для присвоения значения переменной. После этого действия в интерактивном режиме ничего не выводится:
>>> width = 20 >>> height = 5 * 9 >>> width * height 900
Если переменная не «определена» (ей не присвоено значение), то попытка использовать ее выдаст ошибку:
>>> n # try to access an undefined variable Traceback (most recent call last): File "", line 1, in NameError: name 'n' is not defined
Присутствует полная поддержка операций с плавающей точкой; операции над операндами смешанного типа конвертируют целочисленный операнд в число с плавающей запятой:
>>> 3 * 3.75 / 1.5 7.5 >>> 7.0 / 2 3.5
В интерактивном режиме последнее распечатанное выражение присваивается переменной _ . Это означает, что когда вы используете Python как калькулятор, то так проще продолжить расчеты, например:
>>> tax = 12.5 / 100 >>> price = 100.50 >>> price * tax 12.5625 >>> price + _ 113.0625 >>> round(_, 2) 113.06
Эту переменную следует использовать только для чтения. Не присваивайте явно ей значение — вы создадите независимую локальную переменную с тем же именем, скрыв встроенную переменную с ее магическим поведением.
В дополнении к int и float Python поддерживает другие типы чисел, такие как Decimal и Fraction. Python также имеет встроенную поддержку для комплексных чисел, и использует суффикс j или J для указания мнимой части (например, 3+5j ).
Строки
Помимо чисел, Python может работать со строками, которые, в свою очередь, могут быть описаны различными способами. Строки могут быть заключены в одинарные ( ‘. ‘ ) или двойные кавычки ( «. » ), без разницы [2]; \ может быть использован для экранирования кавычек:
>>> 'spam eggs' # single quotes 'spam eggs' >>> 'doesn\'t' # use \' to escape the single quote. "doesn't" >>> "doesn't" # . or use double quotes instead "doesn't" >>> '"Yes," he said.' '"Yes," he said.' >>> "\"Yes,\" he said." '"Yes," he said.' >>> '"Isn\'t," she said.' '"Isn\'t," she said.'
При интерактивном выполнении вывод строк заключается в кавычки и спец. символы экранируются обратными слэшами. Несмотря на то, что иногда это может выглядеть отлично от ввода (окаймляющие кавычки могут измениться), обе строки одинаковы. Строка заключается в двойные кавычки, если строка содержит одинарные кавычки, а не двойные кавычки, иначе она заключается в одинарные кавычки. Функция print() производит более удобочитаемый вывод, опуская окаймляющие кавычки и печатая экранируемые и специальные символы:
>>> '"Isn\'t," she said.' '"Isn\'t," she said.' >>> print('"Isn\'t," she said.') "Isn't," she said. >>> s = 'First line.\nSecond line.' # \n means newline >>> s # without print(), \n is included in the output 'First line.\nSecond line.' >>> print(s) # with print(), \n produces a new line First line. Second line.
Если вы не хотите, чтобы символы, предваренные \ , были интерпретированы как специальные, то вы можете использовать сырые строки добавлением r перед первой кавычкой:
>>> print('C:\some\name') # here \n means newline! C:\some ame >>> print(r'C:\some\name') # note the r before the quote C:\some\name
Строковые литералы могут занимать несколько строк. Один из способов сделать это — тройные кавычки: «»». «»» или »’. »’ . Концы строк автоматически включаются в строку, но возможно избежать этого добавлением \ в конце строки. Следующий пример:
print("""\ Usage: thingy [OPTIONS] -h Display this usage message -H hostname Hostname to connect to """)
выдаст следующий вывод (заметьте, что начальный перевод строки не включен):
Usage: thingy [OPTIONS] -h Display this usage message -H hostname Hostname to connect to
Строки могут быть конкатенированы (соединены вместе) с помощью оператора + , и повторены с помощью * :
>>> # 3 times 'un', followed by 'ium' >>> 3 * 'un' + 'ium' 'unununium'
Два строковых литерала, расположенные друг за другом, автоматически конкатенируются.
>>> 'Py' 'thon' 'Python'
Хотя это работает только с литералами, не с переменными или выражениями:
>>> prefix = 'Py' >>> prefix 'thon' # нельзя конкатенировать переменную и строковый литерал . SyntaxError: invalid syntax >>> ('un' * 3) 'ium' . SyntaxError: invalid syntax
Если вы хотите конкатенировать переменные или переменную или литерал, используйте + :
>>> prefix + 'thon' 'Python'
Эта функция особенно полезна, когда вы хотите разбить длинные строки:
>>> text = ('Put several strings within parentheses ' . 'to have them joined together.') >>> text 'Put several strings within parentheses to have them joined together.'
К символам строки можно обращаться по индексу, первая буква имеет индекс нуль. Отдельного типа для символов нет; символ это просто строка размером 1:
>>> word = 'Python' >>> word[0] # символ с позицией 0 'P' >>> word[5] # символ с позицией 5 'n'
Индексы могут быть негативными числами, чтобы начать считать справа:
>>> word[-1] # последний символ 'n' >>> word[-2] # предпоследний символ 'o' >>> word[-6] 'P'
Заметьте, так как -0 это тоже 0, то негативные индексы начинаются с -1.
В дополнении к индексации, slicing/срезы также поддерживаются. В то время как индексация используется для получения отдельных символов, срез позволяет получить подстроку:
>>> word[0:2] # символы с позициями от 0 (включительно) до 2 (не включая) 'Py' >>> word[2:5] # символы с позициями от 2 (включительно) до 5 (не включая) 'tho'
Заметьте, что начальный символ всегда включается, а конец — всегда исключается. Это гарантирует, что s[:i] + s[i:] всегда равно s :
>>> word[:2] + word[2:] 'Python' >>> word[:4] + word[4:] 'Python'
Индексы срезов имеют полезные значения по умолчанию; опущенный первый индекс заменяется нулём, опущенный второй индекс подменяется размером срезаемой строки.
>>> word[:2] # символы с начала до позиции 2 (не включая) 'Py' >>> word[4:] # символы с позиции 4 (включительно) до конца 'on' >>> word[-2:] # символы с предпоследней позиции (включительно) до конца 'on'
Один из способов запомнить, как работают срезы — думать, что индексы указываются между символами, с левым краем первого символа, пронумерованным 0. Тогда правый край последнего символа строки из n символов имеет идекс n, например:
+---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5 6 -6 -5 -4 -3 -2 -1
Первый ряд чисел дает позицию индексов 0. 6 в строке; второй ряд дает соответствующие негативные индексы. Срез от i до j состоит из всех символов между краями, отмеченными i и j, соответственно.
Для неотрицательных индексов длина среза есть разница индексов, если оба индекса в пределах границ. Например, длина word[1:3] равна 2.
Попытка использовать индекс, который слишком велик, приводит к ошибке:
>>> word[42] # в слове только 6 символов Traceback (most recent call last): File "", line 1, in IndexError: string index out of range
Однако, индексы срезов вне диапазона обрабатываются корректно при нарезании:
>>> word[4:42] 'on' >>> word[42:] ''
Python-строки не могут быть изменены — они являются immutable/иммутабельными. Поэтому присвоение по индексу строки приводит к ошибке:
>>> word[0] = 'J' . TypeError: 'str' object does not support item assignment >>> word[2:] = 'py' . TypeError: 'str' object does not support item assignment
Если вам нужна другая строка, вам следует создать новую:
>>> 'J' + word[1:] 'Jython' >>> word[:2] + 'py' 'Pypy'
Встроенная функция len() возвращает длину строки:
>>> s = 'supercalifragilisticexpialidocious' >>> len(s) 34
Текстовый последовательный тип — str Строки являются примерами последовательного типа, и поддерживают привычные для этих типов операции. Строковые методы Строки поддерживают большое количество методов для поиска и простых трансформаций. Форматирование строковых литералов Строковые литералы, имеющие встроенные выражения. Синтаксис форматирования строк Информация о форматировании строк с применением функции str.format() printf-стиль форматирования строк Старые операции форматирования, вызывающиеся тогда, когда обычные строки или строки в Unicode оказываются левым операндом относительно операции % , более детально рассмотрены здесь.
Списки
В языке Python доступно некоторое количество составных типов данных, использующихся для группировки прочих значений вместе. Наиболее гибкий из них — список (list). Его можно выразить в тексте программы через разделённые запятыми значения (элементы), заключённые в квадратные скобки. Элементы списка могут быть разных типов, но обычно элементы все имеют тот же тип.
>>> squares = [1, 4, 9, 16, 25] >>> squares [1, 4, 9, 16, 25]
Подобно строкам (и всем другим встроенным последовательным типам), списки могут быть индексированы и срезаны:
>>> squares[0] # индексация возвращает элемент 1 >>> squares[-1] 25 >>> squares[-3:] # срез возвращает новый список [9, 16, 25]
Все срезовые операции возвращают новые список, содержащий запрашиваемые элементы. Это означает, что следующий срез возвращает новую (легковесную) копию списка:
>>> squares[:] [1, 4, 9, 16, 25]
Списки также поддерживают такие операции, как конкатенация:
>>> squares + [36, 49, 64, 81, 100] [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
В отличие от строк, которые являются иммутабельными, списки — мутабельного типа, т.е. возможно изменить их содержимое:
>>> cubes = [1, 8, 27, 65, 125] # что-то здесь не так >>> 4 ** 3 # куб от 4 — 64, не 65! 64 >>> cubes[3] = 64 # заменить неправильное значение >>> cubes [1, 8, 27, 64, 125]
Вы также можете добавить новые элементы в конец списка, используя метод append() (позже мы узнаем больше о методах):
>>> cubes.append(216) # добавить куб 6 >>> cubes.append(7 ** 3) # и куб 7 >>> cubes [1, 8, 27, 64, 125, 216, 343]
Присвоение спискам также возможно, и это может даже изменить размер списка или очистить его полностью:
>>> letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g'] >>> letters ['a', 'b', 'c', 'd', 'e', 'f', 'g'] >>> # заменить некоторые значения >>> letters[2:5] = ['C', 'D', 'E'] >>> letters ['a', 'b', 'C', 'D', 'E', 'f', 'g'] >>> # теперь удалить их >>> letters[2:5] = [] >>> letters ['a', 'b', 'f', 'g'] >>> # очистить список заменой всех элементов пустым списком >>> letters[:] = [] >>> letters []
Встроенная функция len() также применима к спискам:
>>> letters = ['a', 'b', 'c', 'd'] >>> len(letters) 4
Можно вкладывать списки (создавать списки, содержащие другие списки), например:
>>> a = ['a', 'b', 'c'] >>> n = [1, 2, 3] >>> x = [a, n] >>> x [['a', 'b', 'c'], [1, 2, 3]] >>> x[0] ['a', 'b', 'c'] >>> x[0][1] 'b'
Первые шаги к программированию
Безусловно, Python можно использовать для более сложных задач, чем сложение двух чисел. Например, мы можем вывести начало последовательности чисел Фибоначчи таким образом:
>>> # последовательность Фибоначчи: . # сумма двух элементов определяет следующий . a, b = 0, 1 >>> while b < 10: . print(b) . a, b = b, a+b . 1 1 2 3 5 8
Этот пример показывает нам некоторые новые возможности.
- Первая строка содержит множественное присваивание: переменные a и b параллельно получают новые значения — 0 и 1. В последней строке этот метод используется снова, демонстрируя тот факт, что выражения по правую сторону [от оператора присваивания] всегда вычисляются раньше каких бы то ни было присваиваний. Правая часть выражения оцениваются слева направо.
- Цикл while (пока) исполняется до тех пор, пока условие (здесь: b < 10 ) остается истиной. В Python, также как и в C, любое ненулевое значение является истиной ( True ); ноль является ложью ( False ). Условием может быть строка, список или вообще любая последовательность; все, что имеет ненулевую длину, играет роль истины, пустые последовательности — лжи. Использованная в примере проверка — простое условие. Стандартные операции сравнения записываются так же, как и в C: < (меньше чем), >(больше чем), == (равно), = (больше или равно) и != (не равно).
- Тело цикла выделено отступом. Отступы — это средство группировки операторов в Python. В интерактивном режиме необходимо использовать табуляции или пробелы для отступа в каждой строке. На практике более сложный текст на Python готовится в текстовом редакторе, а большинство из них имеют функцию авто-отступа. По окончанию ввода составного выражения в интерактивном режиме, необходимо закончить его пустой строкой — признаком завершения (поскольку интерпретатор не может угадать, когда вами была введена последняя строка). Обратите внимание, что размер отступа в каждой строке основного блока должен быть одним и тем же.
- Функция print() выводит значения переданных ей выражений. Поведение этой функции отличается от обычного вывода выражения (как происходило выше в примерах с калькулятором) тем, каким способом обрабатываются ряды выражений, величины с плавающей точкой и строки. Строки выводятся без кавычек и между элементами вставляются пробелы, благодаря чему форматирование вывода улучшается — как, например, здесь:
>>> i = 256*256 >>> print('The value of i is', i) The value of i is 65536
Для отключения перевода строки после вывода или завершения вывода другой строкой используется именованный параметр end:
>>> a, b = 0, 1 >>> while b < 1000: . print(b, end=',') . a, b = b, a+b . 1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,
| ">[1] | Так как ** имеет более высокий приоритет, чем - , то -3**2 будет интерпретирован как -(3**2) и поэтому приведет к -9 . Чтобы избежать этого и получить 9 , вы можете использовать (-3)**2 . |
| ">[2] | В отличие от других языков, специальные символы, такие как \n , имеют тот же смысл и с одинарными( '. ' ), и с двойными ( ". " ) кавычками. Единственная разница между ними — что внутри одинарных кавычек вам нужно экранировать " (но вам придется экранировать \' ), и наоборот. |
Содержание
- Неформальное введение в Python
- Использование Python в качестве калькулятора
- Числа
- Строки
- Списки
Все, что нужно знать о строках в Python

Все символы между открывающим разделителем и соответствующим закрывающим разделителем являются частью строки:
print("Это строка") # напечатает в консоль: Это строка print(type("Это строка")) # напечатает в консоль: print('Это тоже строка') # напечатает в консоль: Это тоже строка print(type('И я тоже строка')) # напечатает в консоль:Строка в Python может содержать столько символов, сколько вы пожелаете. Единственное ограничение – это ресурсы памяти вашего компьютера. Строка также может быть пустой:
Что делать, если вы хотите включить символ кавычки как часть самой строки? Первое, что приходит в голову: попробовать что-то подобное:
print('Эта строка включает одинарную (') кавычку') # мы получим ошибку: SyntaxError: invalid syntaxКак вы видите – эта конструкция не работает. Строка в этом примере открывается одинарной кавычкой, поэтому Python предполагает, что следующая одинарная кавычка, заключенная в круглые скобки, которая должна была быть частью строки, является закрывающим разделителем. Заключительная одинарная кавычка в этом случае является случайной и вызывает синтаксическую ошибку.
Если вы хотите включить в строку кавычку, самый простой способ – разделить строку другим типом кавычки. Если строка должна содержать одинарную кавычку, заключите ее в двойные кавычки и наоборот:
print("Эта строка включает одинарную (') кавычку") print('Эта строка включает двойную (") кавычку')
Экранирующие (escape) символы
Иногда вы можете захотеть, чтобы Python интерпретировал символ или последовательность символов в строке по-другому.
Вы можете сделать это с помощью символа обратной косой черты (\). Символ обратной косой черты в строке указывает на то, что один или несколько следующих за ним символов должны быть обработаны особым образом.Ниже приведена таблица escape-последовательностей, которые заставляют Python подавлять обычную интерпретацию символа в строке.
Escape последовательность Интерпретация \a Гудок встроенного в систему динамика \b Backspace, удаляет один символ перед курсором \\ Символ обратного слеша \newline Продолжает запись с новой строки \’ Одинарная кавычка \” Двойная кавычка \f Разрыв страницы \n Начало новой строки \r Возврат курсора в начало строки \t Горизонтальная табуляция \v Вертикальная табуляция \xhh Шестнадцатеричный код символа (две шестнадцатиричные цифры hh) \ooo Восьмеричный код символа (три восьмеричные цифры ooo) \0 Null \N ID (идентификатор) символа в базе данных Юникода \uhhhh Шестнадцатеричный код 16-битного символа Юникода \Uhhhhhhhh Шестнадцатеричный код 32-битного символа Юникода Примеры
print("Символ\tтабуляции") ''' напечатает в консоль: Символ табуляции ''' print("Символ\n переноса строки") ''' напечатает в консоль: Символ переноса строки '''Манипуляции со строками
В приведенных ниже разделах рассматриваются операторы, методы и функции, доступные для работы со строками.
Строковые операторы
Оператор конкантенации строк +
Этот оператор объединяет строки. Он возвращает строку, состоящую из соединенных вместе операндов, как показано ниже:
s = 'Я' t = ' пошел' u = ' в магазин' print(s + t + u) ''' напечатает в консоль: Я пошел в магазин '''Оператор мультипликации строк *
Этот оператор создает несколько копий строки.
s = 'Слово.' print(s * 3) ''' напечатает в консоль: Слово.Слово.Слово. ''' print(2 * s) ''' напечатает в консоль: Слово.Слово. '''Оператор in
Python также предоставляет оператор вхождения подстроки в строку. Оператор in возвращает значение True, если первый операнд содержится во втором, и значение False в противном случае:
s = 'школа' print(s in 'Это моя школа') # напечатает True print(s in 'Это мой дом') # напечатает FalseВстроенные функции для работы со строками
Python предоставляет множество функций, которые встроены в интерпретатор и всегда доступны. Вот некоторые из них, которые работают со строками:
Функция Описание ord() Преобразует символ в целое число chr() Преобразует целое число в символ len() Возвращает длину строки str() Возвращает строковое представление объекта print(ord('a')) # напечатает 97 print(chr(97)) # напечатает a print(len("Математика")) # напечатает 10 print(str(18.5)) # напечатает '18.5'Индексация строк
Часто в языках программирования к отдельным элементам набора данных можно получить прямой доступ, используя числовой индекс или ключевое значение. Этот процесс называется индексированием.
В Python строки представляют собой упорядоченные последовательности символов и, следовательно, могут быть проиндексированы. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках [].
Индексация строк в Python начинается с 0: первый символ в строке имеет индекс 0, следующий – индекс 1 и так далее. Индекс последнего символа будет равен длине строки минус единица.
Например, схема индексов строки ‘пайтон‘ будет выглядеть следующим образом:

Доступ к отдельным символам можно получить по индексу следующим образом:
s = 'пайтон' print(s[0]) # напечатает 'п' print(s[2]) # напечатает 'й' print(s[6]) # IndexError: string index out of rangeПопытка индексирования за пределами конца строки приводит к ошибке.
Индексы строк также могут быть указаны с отрицательными числами. В этом случае индексация происходит с конца строки в обратном направлении: -1 относится к последнему символу, -2 – к предпоследнему символу и так далее. Вот та же схема, показывающая как положительные, так и отрицательные индексы в строке ‘пайтон‘:

Вот несколько примеров отрицательной индексации:
s = 'пайтон' print(s[-2]) # напечатает 'о' print(s[-6]) # напечатает 'п'Срезы строк (String Slicing)
Python также допускает форму синтаксиса индексирования, которая извлекает подстроки из строки, известную как нарезка строк. Если s является строкой, выражение вида s[m:n] возвращает часть s, начинающуюся с позиции m, и до позиции n, но не включая ее:
s = 'пайтон' print(s[0:3]) # напечатает 'пай'Если вы опустите первый индекс, срез начнется с начала строки. Таким образом, s[:m] и s[0:m] эквивалентны:
s = 'пайтон' print(s[:3]) # тоже напечатает 'пай'Отрицательные индексы также можно использовать в срезах. -1 относится к последнему символу, -2 – к предпоследнему и так далее, точно так же, как при простом индексировании.
s = 'пайтон' print(s[-5:-2]) # напечатает 'айт'Указание шага в срезах строк
Существует еще один вариант синтаксиса срезов, который следует обсудить. Добавление дополнительного двоеточия (:) и третьего индекса обозначает шаг, который указывает, на сколько символов нужно перейти после извлечения каждого символа в срезе.
Например, для строки ‘PYTHON‘ фрагмент 0:6:2 начинается с первого символа и заканчивается последним символом (целой строкой), и каждый второй символ пропускается. Это показано на следующей схеме:

s = 'PYTHON' print(s[0:6:2]) # напечатает 'PTO'Интерполяция переменных в строку
В Python версии 3.6 был введен новый механизм форматирования строк. Эта функция официально называется форматированным строковым литералом, но чаще всего ее называют псевдонимом f-string.
Одна простая функция f-string, которую вы можете начать использовать сразу же, – это интерполяция переменных. Вы можете указать имя переменной непосредственно в литерале f-string, и Python заменит это имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Вы можете сделать это с помощью простого оператора print(), разделяя числовые значения и строковые литералы запятыми:
name = 'Ivan' surname = 'Petrov' print('Name:', name, 'surname:', surname) # напечатает 'Name: Ivan surname: Petrov'Но, это громоздко. Чтобы выполнить то же самое, нужно использовать f-строку:
- Укажите либо строчную f, либо прописную F непосредственно перед начальной кавычкой строкового литерала. Это укажет Python, что это f-строка вместо стандартной строки.
- Укажите любые переменные, которые будут интерполированы, в фигурных скобках <>.
name = 'Ivan' surname = 'Petrov' print(f'Name: surname: ') # напечатает 'Name: Ivan surname: Petrov'Модификация строк
Строки – это один из типов данных, которые Python считает неизменяемыми, то есть не подлежащими изменению.
>>> s = 'Питон' >>> s[2] = 'у' Traceback (most recent call last): File "", line 1, in s[2] = 'у' TypeError: 'str' object does not support item assignmentПо правде говоря, на самом деле нет особой необходимости изменять строки. Обычно вы можете легко выполнить то, что хотите, сгенерировав копию исходной строки, в которой есть нужное изменение. Есть много способов сделать это в Python. Вот несколько вариантов:
s = 'Питон' s = s[:1] + 'у' + s[2:] print(s) # напечатает 'Путон' s = 'Питон' s = s.replace('и', 'у') print(s) # напечатает 'Путон'Встроенные строковые методы
Python – это объектно-ориентированный язык. Каждый элемент данных в программе Python является объектом. Вы также знакомы с функциями: вызываемыми процедурами, которые вы можете вызывать для выполнения определенных задач.
Методы аналогичны функциям. Метод – это специализированный тип вызываемой процедуры, который тесно связан с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается для определенного объекта и имеет информацию о своем целевом объекте во время выполнения.
Синтаксис для вызова метода для объекта следующий:
obj.foo()Выше вызывается метод .foo() для объекта obj. указывает на аргументы, переданные методу (если таковые имеются).
Case методы
Методы в этой группе выполняют преобразование регистра в целевой строке.
s.capitalize()
s.capitalize() возвращает копию строки s с первым символом, преобразованным в верхний регистр, и всеми остальными символами, преобразованными в нижний регистр:
>>> s = 'я Люблю ПиТон' >>> s.capitalize() 'Я люблю питон's.lower()
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
>>> 'Я Учу Питон 3'.lower() 'я учу питон 3's.swapcase()
s.swapcase() возвращает копию s с символами верхнего регистра, преобразованными в нижний регистр, и наоборот:
>>> 'Hello World'.swapcase() 'hELLO wORLD's.title()
s.title() возвращает копию s, в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы – в нижний:
>>> 'hello world'.title() 'Hello World's.upper()
s.upper() возвращает копию s со всеми символами, преобразованными в верхний регистр:
>>> 'Пайтон'.upper() 'ПАЙТОН'Поиск и замена строк
Эти методы предоставляют различные средства поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы start> и end>. Действие метода ограничено частью целевой строки, начинающейся с позиции символа и продолжающейся до, но не включающей позицию символа . Если указано, но нет, метод применяется к части целевой строки от до конца строки.s.count([, [, ]])
s.count() возвращает количество неперекрывающихся вхождений подстроки в s:
>>> 'один два три один четыре один'.count('один') 3s.endswith([, [, ]])
s.endswith() возвращает True, если s заканчивается указанным , и False в противном случае:
>>> 'Java'.endswith('va') True >>> 'Java'.endswith('ton') Falses.find([, [, ]])
Вы можете использовать .find(), чтобы узнать, содержит ли строка Python определенную подстроку. s.find() возвращает наименьший индекс в s, где найдена подстрока :
>>> 'one two nine'.find('two') 4Этот метод возвращает значение -1, если указанная подстрока не найдена
s.index([, [, ]])
Этот метод идентичен .find(), за исключением того, что он вызывает исключение, если не найден, а не возвращает -1:
>>> 'one two nine'.index('eleven') Traceback (most recent call last): File "", line 1, in 'one two nine'.index('eleven') ValueError: substring not founds.rfind([, [, ]])
s.rfind() возвращает наибольший индекс в s, где найдена подстрока :
>>> 'one two nine two'.rfind('two') 13s.rindex([, [, ]])
Этот метод идентичен .rfind(), за исключением того, что он вызывает исключение, если не найден, а не возвращает -1:
>>> '11 22 33'.rindex('44') Traceback (most recent call last): File "", line 1, in '11 22 33'.rindex('44') ValueError: substring not founds.startswith([, [, ]])
s.startswith() возвращает True, если s начинается с указанного , и False в противном случае:
>>> 'scala'.startswith('sc') True >>> 'scala'.startswith('py') FalseКлассификация символов
Методы в этой группе классифицируют строку на основе содержащихся в ней символов.
s.isalnum()
s.isalnum() возвращает значение True, если s не пустая и все ее символы являются буквенно-цифровыми (либо буква, либо цифра), и значение False в противном случае:
>>> 'xyz123'.isalnum() True >>> '100$'.isalnum() False >>> ''.isalnum() Falses.isalpha()
s.isalpha() возвращает значение True, если s не пустая и все ее символы являются буквенными, и значение False в противном случае
s.isdigit()
Вы можете использовать метод .isdigit() в Python, чтобы проверить, состоит ли ваша строка только из цифр. s.isdigit() возвращает True, если s не пустая и все ее символы являются числовыми цифрами, и False в противном случае
s.isidentifier()
s.isidentifier() возвращает True, если s является допустимым идентификатором Python в соответствии с определением языка, и False в противном случае
>>> 'val8'.isidentifier() True >>> '7free'.isidentifier() False >>> 'usd$32'.isidentifier() Falses.islower()
s.islower() возвращает значение True, если значение s не пустое и все содержащиеся в ней буквенные символы являются строчными, в противном случае значение False. Неалфавитные символы игнорируются
s.isprintable()
s.isprintable() возвращает значение True, если значение s пусто или все содержащиеся в ней буквенные символы доступны для печати. Метод возвращает значение False, если s содержит хотя бы один непечатаемый символ. Неалфавитные символы игнорируются
>>> 'Hello \t World'.isprintable() False >>> 'Hello World'.isprintable() True >>> ''.isprintable() True >>> 'Newline \n'.isprintable() Falses.isspace()
Определяет, состоит ли целевая строка из пробелов.
s.isspace() возвращает значение True, если значение s непустое и все символы являются пробелами, и значение False в противном случае
s.istitle()
Метод s.istitle() возвращает значение True, если s не пустая, первый буквенный символ каждого слова прописной, а все остальные буквенные символы в каждом слове строчные. В противном случае он возвращает значение False
>>> 'This Is A Title!'.istitle() True >>> 'This is a title!'.istitle() Falses.isupper()
Определяет, являются ли буквенные символы целевой строки заглавными. Метод s.isupper() возвращает значение True, если значение s непустое и все содержащиеся в нем буквенные символы прописные, в противном случае значение False. Неалфавитные символы игнорируются.
Форматирование строк
s.center([, ])
Центрирует строку. Возвращает строку, состоящую из s, центрированную по ширине.
>>> 'new'.center(10) ' new 's.ljust([, ])
Выравнивает строку в поле по левому краю. s.ljust() возвращает строку, состоящую из s, выровненную по левому краю в поле по ширине width.
>>> 'new'.ljust(10) 'new 's.lstrip([])
Удаляет начальные символы из строки. s.lstrip() возвращает копию s с пробелами, удаленными с левого конца
>>> ' red green blue '.lstrip() 'red green blue ' >>> '\t\nred\t\ngreen\t\nblue'.lstrip() 'red\t\ngreen\t\nblue's.replace(, [, ])
Заменяет вхождения подстроки внутри строки. s.replace(, ) возвращает копию s со всеми вхождениями подстроки , замененной на
>>> 'red green green red'.replace('red', 'blue') 'blue green green blue's.rjust([, ])
Выравнивает строку в поле по правому краю.
s.rjust() возвращает строку, состоящую из s, выровненную по правому краю по ширине width>>> 'sky'.rjust(10) ' sky's.rstrip([])
s.rstrip() возвращает копию s с пробелами, удаленными с правого конца
>>> ' one two '.rstrip() ' one two' >>> 'one\t\ntwo\t\none\t\n'.rstrip() 'one\t\ntwo\t\none's.strip([])
Удаляет пустые символы с левого и правого концов строки.
s.zfill()
Заполняет строку слева нулями.
>>> '51'.zfill(5) '00051'Преобразования между строками и коллекциями
Методы этой группы делают преобразования между строками и коллекциями, либо соединяя объекты вместе, чтобы создать строку, либо разбивая строку на части.
Эти методы работают с iterables или возвращают их (общий термин Python для обозначения последовательной коллекции объектов).
s.join()
s.join() возвращает строку, полученную в результате объединения объектов в , разделенных символом s.
>>> ', '.join(['one', 'two', 'three']) 'one, two, three's.partition()
Разделяет строку на основе разделителя. Возвращаемое значение представляет собой кортеж из трех частей, состоящий из
- Часть s, предшествующая
- сам
- Часть s, следующая за
>>> 'one.two'.partition('.') ('one', '.', 'two') >>> 'one@@two@@three'.partition('@@') ('one', '@@', 'two@@three') >>> 'one.two'.partition('@@') ('one.two', '', '')s.rpartition()
s.rpartition() работает точно так же, как s.partition(), за исключением того, что s разделяется при последнем появлении вместо первого
s.splitlines([])
s.splitlines() разбивает s на строки и возвращает их в виде списка. Любой из следующих символов или последовательностей символов считается границей линии:
Escape последовательность Описание \n Новая строка \r Возврат каретки \r\n Возврат каретки + Новая строка \v or \x0b Вертикальная табуляция \f or \x0c Form Feed \x1c File Separator \x1d Group Separator \x1e Record Separator \x85 Next Line (C1 Control Code) \u2028 Unicode Line Separator \u2029 Unicode Paragraph Separato >>> 'red\ngreen\r\nblue\forange\u2028black'.splitlines() ['red', 'green', 'blue', 'orange', 'black']Заключение
В этом руководстве представлен подробный обзор множества различных механизмов, предоставляемых Python для обработки строк, включая строковые операторы, встроенные функции, индексирование, слайсы и встроенные методы.
Работа со строками в Python
Язык программирования Python поддерживает разные виды данных. В этой статье, предназначенной для начинающих, будет рассмотрен строковый тип string и основные операции, связанные с обработкой строк. Среди них:
- создание строк;
- конкатенация строк;
- выборка символов по индексам.
Создание строки
Строки (strings) используются для хранения текстовых данных. Их создание возможно одним из 3-х способов. Тут все просто, т. к. возможно применение разных кавычек: одинарных, двойных либо тройных. То есть в эти кавычки и нужно обернуть текст:
otus_string_1 = 'Привет, друзья!'
otus_string_2 = "Хотите выучить Python?"
otus_string_3 = """Ждем вас на наших курсах!"""
Кавычки в данном случае — это строковые литералы, позволяющие создавать в памяти программы Python объект типа string.
Нужно понимать, что разницы, какие именно кавычки использует разработчик, нет. Главное — открывающие и закрывающие кавычки должны быть однотипными. Если же поставить вначале одинарную кавычку, а в конце двойную — ошибки не избежать.
Можно ли применять кавычки внутри строк?
Можно, для чего есть несколько вариантов. Один из них — использовать внутри строки кавычки другого типа. К примеру, наружные кавычки являются двойными, а внутренние — одинарными. Или наоборот:
otus_string_1 = 'Хотите выучить "Пайтон?" и стать профессионалом'
otus_string_2 = "Запишитесь на курс в 'Отус' уже сегодня!"
Второй метод — экранирование. Для экранирования используется обратный слэш. Вот, как это выглядит в коде:
otus_string_1 = "Я и 'Пайтон' созданы друг для друга"
У тройных кавычек есть особенности. Заключенные в них строки поддерживают многострочность, то есть для переноса не нужен символ n. А еще внутри тройных кавычек можно вставлять как двойные, так и одинарные кавычки:
Вывод будет следующим:
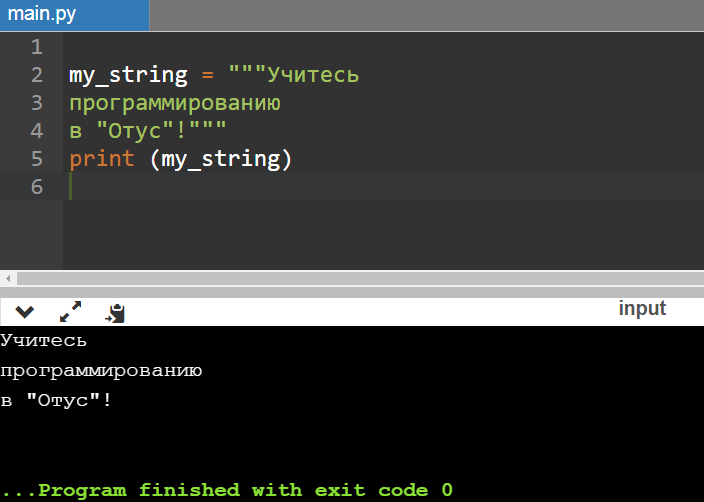
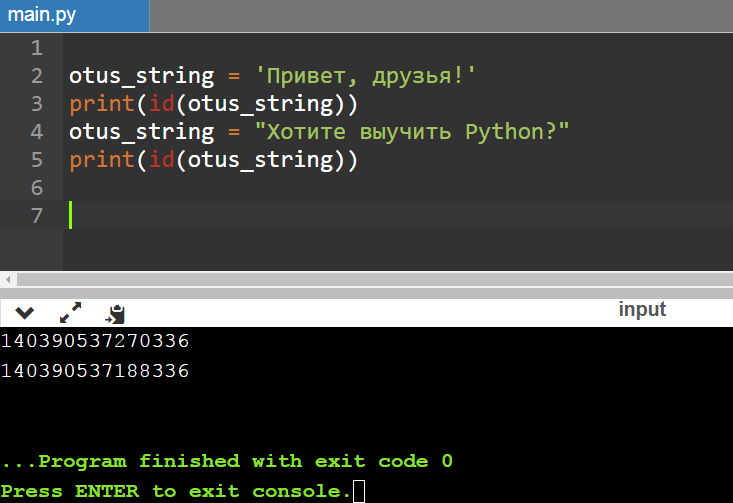
Строки являются неизменяемыми объектами (как и числа). В этом легко убедиться, если создать переменные с одинаковыми именами, а потом вывести на экран их id — идентификаторы будут различаться:
otus_string = 'Привет, друзья!'
otus_string = "Хотите выучить Python?"
Рекомендуется повторить вышеописанные операции самостоятельно и попрактиковаться. Сделать это можно, даже не устанавливая «Пайтон», используя любой онлайн-компилятор.
Конкатенация строк
Конкатенация — это сложение строк, в результате чего они соединяются друг с другом. Самый простой способ сделать это — использовать простейший оператор сложения, то есть знак «+».

Это простейший синтаксис, причем можно брать сколько угодно строк и соединять их:
otus_string = "Я " + "просто " + "обожаю " + "Python!"
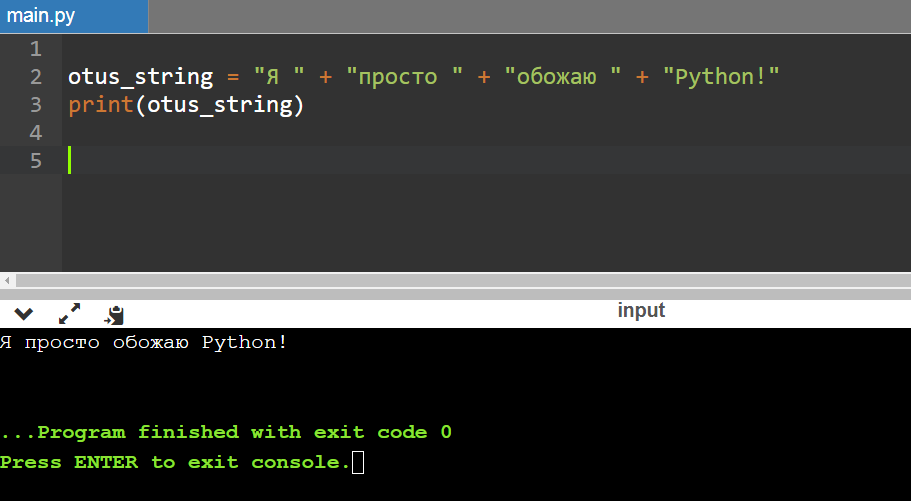
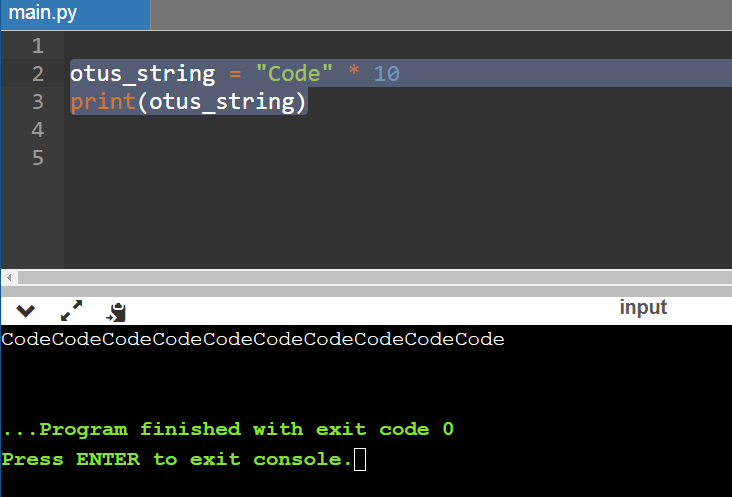
Если надо, можно задействовать и операнд умножения. Он позволит продублировать строку, умножив ее на соответствующее значение, которое разработчик передаст в коде.
otus_string = "Code" * 10
Важное свойство строк — длина (число символов). Узнать количество символов, из которых состоит строка, можно, задействовав встроенную функцию len (от англ. length — длина).
Код ниже посчитает число символов:
otus_string = "Python is a good for coding"
Итого: строка содержит 27 символов (пробел — тоже символ):
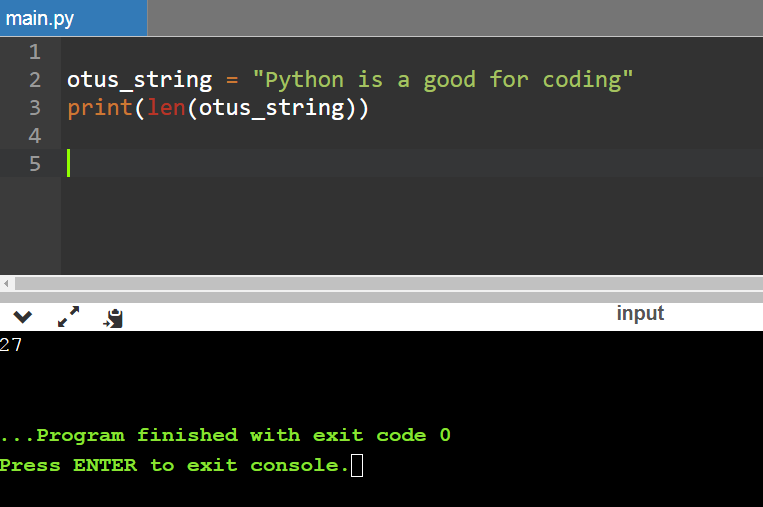
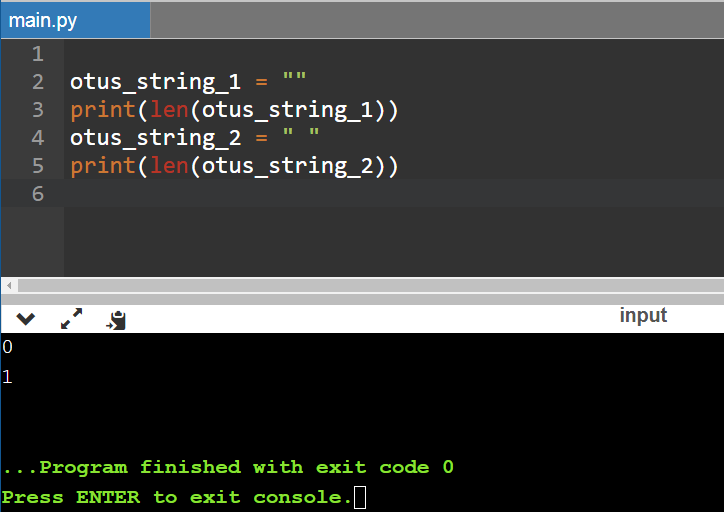
Можно попробовать передать пустую строку и постараться посчитать число символов в ней. Если вставить хотя бы пробел, на выходе получится 1 символ, если не вставлять вообще ничего, число символов будет равняться нулю.
Несколько слов о методах строк
Ранее уже использовались такие методы, как print и id. Есть свои методы и у строковых данных — они принадлежат конкретному классу str. Чтобы вывести их, можно воспользоваться функцией dir:
Зубрить каждый из них нет необходимости, так как нужные методы будут запоминаться с практикой. Чтобы обратиться к одному из них, следует сначала обратиться к соответствующему объекту, потом поставить точку, потом написать нужный метод и круглые скобки. Лучше это увидеть:
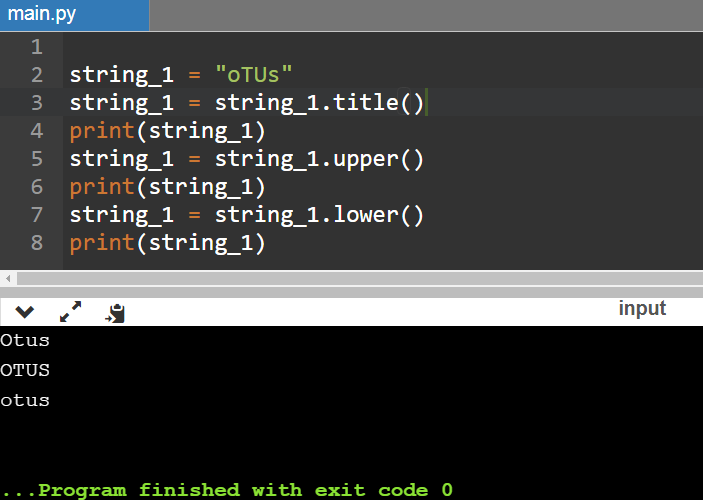
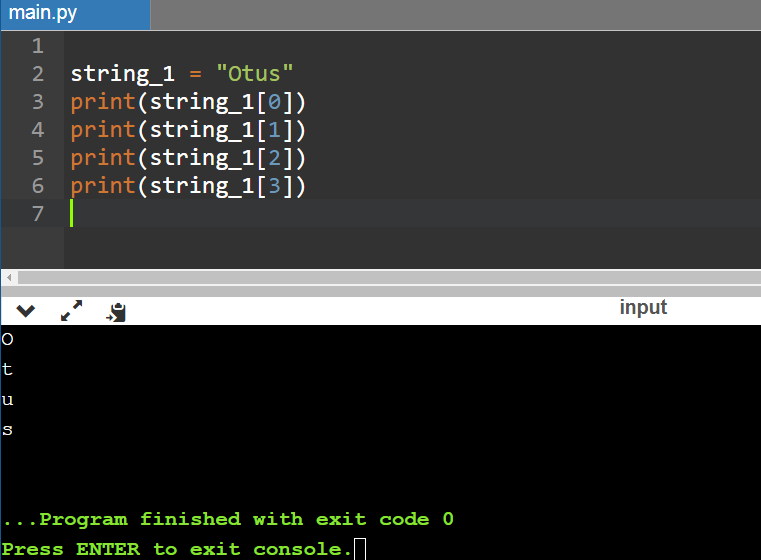
Что отображено на скриншоте выше:
- была создана новая строка string_1 с содержимым “oTUs”;
- вначале задействовали метод title — вывод слова получился с заглавной буквы;
- потом использовали метод для верхнего регистра upper — заглавными (прописными) стали все символы строки;
- далее применили lower — все символы стали маленькими (строчными), то есть перешли в нижний регистр.
Какие еще есть методы:
- replace —для замены одной части исходной строки (подстроки) на другую;
- split — позволяет разделить (не удалить!) строку по переданному делителю, возвращает список;
- join — склеивает подстроки по конкретному разделителю;
- strip. В языке программирования Python strip используется для обрезки ненужных символов, причем ненужный символ передается в виде аргумента. Обрезку можно выполнять по-разному: если с первого символа слева, то применяют не strip, а lstrip, если справа, то rstrip (с конца строки, если интересует последний символ).
Индексы
В «Питоне» у каждого символа есть свой номер — индекс. Если разработчика интересует поиск какого-нибудь символа, к нему можно обратиться. Код ниже возвращает индекс для каждого символа из слова Otus:
Тут важен один момент: индексация начинается не с единицы, а с нуля, поэтому первый символ имеет индекс 0.
Дополнительно: преобразование символа в целое число
Компьютеры хранят все данные в виде цифр, и символьных данных это тоже касается. Для представления символов строкового типа String применяют схему перевода. Самая простая из них — ASCII . Если нужно вернуть число для какого-нибудь конкретного символа, используют функцию ord. К примеру, для символа «a» кодовое значение по ASCII будет равняться 97, а для «#» — 35.

Кроме ASCII, также широко известен Unicode, который тоже поддерживается «Питоном».
- https://zen.yandex.ru/media/id/5cab3ea044061700afead675/vse-o-strokah-v-python-5f60744e5622142b93b2031e;
- https://pythonru.com/osnovy/stroki-python.
Строки в Python
Строка — это последовательность символов.
Символ — это просто одиночный символ. Например, в английском языке 26 символов, букв.
Компьютер работает не с символами, а с числами в двоичной записи. Вы видит на экране символы, но компьютер хранит и обрабатывает их как комбинацию нулей и единиц.
Преобразование символа в число называется кодированием, а обратный процесс — декодированием. О самых известных стандартах кодирования вы, скорее всего, слышали. Это ASCII и Unicode.
В Python каждая строка — это последовательность символов Юникода, поскольку он позволяет использовать символы из всех языков мира и обеспечивает единообразие кодировки.
Как создать строку
Если заключить набор символов в одинарные '' или двойные "" кавычки с двух сторон, получится строка. В Python можно использовать и тройные кавычки '''''' , но их обычно используют для многострочных строк и строк документации.
# все способы ниже эквиваленты: они делают одно и то же my_string = 'Привет' print(my_string) my_string = "Привет" print(my_string) my_string = '''Привет''' print(my_string) # тройные кавычки позволяют создавать многострочные строки my_string = """Привет, добро пожаловать в мир Python""" print(my_string)Вывод:
Привет
Привет
Привет
Привет, добро пожаловать
в мир PythonКак получить доступ к символам в строке
1. По индексу
Получить доступ к отдельным символам в строке можно стандартным способом — по индексу.
Примечание. Первый элемент в строке (то есть первый символ) Python имеет индекс 0.
Индекс всегда должен быть целым числом, поэтому тип float не подойдет. Использование в качестве индекса числа с плавающей точкой приведет к ошибке TypeError.
Если вы попытаетесь получить доступ к символу с индексом, который больше длины строки, Python выдаст ошибку IndexError.
Индекс не обязательно должен быть положительным числом. Python поддерживает и «отрицательную индексацию». Индекс -1 ссылается на последний символ, -2 — на предпоследний и так далее.
2. С помощью среза
Получить доступ к символам в строке можно и с помощью слайсинга (от англ. «нарезание»). Таким способом удобно получать набор символов в заданном диапазоне.
Срезы задаются с помощью квадратных скобов [] и 2-3 аргументов через двоеточие : .
my_collection[старт:стоп:шаг]
string = 'codechick' print('string = ', string) #первый символ print('string[0] = ', string[0]) #последний символ print('string[-1] = ', string[-1]) #срез от 2 до 5 символа print('string[1:5] = ', string[1:5]) #срез от 6 до предпоследнего символа print('string[5:-2] = ', string[5:-2])Вывод:
string = codechick
string[0] = c
string[-1] = k
string[1:5] = odec
string[5:-2] = hiЕсли мы попытаемся получить доступ к символу с индексом вне допустимого диапазона или использовать не целые числа, получим ошибку.
Помните строку my_string?
# длина строки my_string = 6 символов, а мы пытаемся получить 15 символ
>>> my_string[15]
.
IndexError: string index out of range
# индекс должен быть целым числом
>>> my_string[1.5]
.
TypeError: string indices must be integersКак изменить или удалить строку
Строка — неизменяемый тип данных. Это значит, что мы не можем изменить элементы строки после создания. Зато можем переназначать разные строки одной и той же переменной.
>>> my_string = 'codechick'
>>> my_string[5] = 'a'
.
TypeError: 'str' object does not support item assignment>>> my_string = 'Python' >>> my_string 'Python'По той же причине нельзя удалять символы из строки. Зато можно полностью удалить строку: для этого используйте ключевое слово del .
>>> del my_string[1]
.
TypeError: 'str' object does not support item deletion
>>> del my_string
>>> my_string
.
NameError: name 'my_string' is not definedСтроковые операции
Строки — один из самых часто используемых типов данных в Python, поэтому для работы с ними существует куча встроенных операций.
Конкатенация строк
Конкатенация — это объединение двух или более строк в одну.
Эту операцию в Python выполняет оператор + . А с помощью оператора * можно повторить строку заданное количество раз — «умножить» строку на число.
string1 = 'Привет, ' string2 ='мир!' # используем + print('string1 + string2 = ', string1 + string2) # используем * print('string1 * 3 =', string1 * 3)Вывод:
string1 + string2 = Привет, мир!
string1 * 3 = Привет, Привет, Привет,Если просто написать рядом два строковых литерала, они тоже объединятся в одну строку. Еще можно использовать круглые скобки. Давайте рассмотрим пример.
>>> # два строковых литералы записаны вместе >>> 'Привет, ''мир!' 'Привет, мир!' >>> # круглые скобки объединяют строковые литералы >>> s = ('Привет, ' . 'мир') >>> s 'Привет, мир'Итерирование по строке
В Python можно «пройтись» по строке, то есть перебрать все символы в ней. Для этого нужно использовать цикл for.
count = 0 for letter in 'Привет, мир!': if (letter == 'и'): count += 1 print(count, 'буквы «и» в данной строке')Вывод:
2 буквы «и» в данной строке
Проверка на вхождение
В Python можно проверить, находится ли данная подстрока в строке или нет с помощью операторов членства in и not in .
>>> 'chick' in 'codechick' True >>> 'code' not in 'codechick' FalseФункции для работы со строками
Практически все встроенные функции, которые работают с последовательностями, точно так же работают со строками.
Самые полезные:
- enumerate() — позволяет перебирать строку, отслеживая индекс текущего элемента.
- len() — возвращает длину строки.
string = 'кодер' # enumerate() list_enumerate = list(enumerate(string)) print('list(enumerate(string) = ', list_enumerate) # считаем количество символов print('len(string) = ', len(string))Вывод:
list(enumerate(string) = [(0, 'к'), (1, 'о'), (2, 'д'), (3, 'е'), (4, 'р')]
len (string) = 5Методы строк
Разбивает строки по заданном разделителю (по умолчанию — пробел)
«Собирает» строку из списка с разделителем
find(подстрока, начало, конец)
Поиск подстроки в строке. Возвращает индекс первого вхождения слева. Если подстроки в строке нет, возвращает -1
index(подстрока, начало, конец)
Поиск подстроки в строке. Возвращает индекс первого вхождения. Если подстроки в строке нет, возвращает ValueError
Замена шаблона в строке
Проверяет, состоит ли строка из цифр. Возвращает True или False
Проверяет, состоит ли строка из букв. Возвращает True или False
Проверяет, состоит ли строка из символов в нижнем регистре. Возвращает True или False
Проверяет, состоит ли строка из символов в верхнем регистре. Возвращает True или False
Преобразует строку к верхнему регистру
Преобразует строку к нижнему регистру
Преобразует символ в ASCII-код
Преобразует ASCII-код в символ
>>> "CoDeCHicK".lower() 'codechick' >>> "CoDeCHicK".upper() 'CODECHICK' >>> "Эта инструкция разобьет строку и засунет элемент в список".split() ['Эта', 'инструкция', 'разобьет', 'строку', 'и', 'засунет', 'элемент', 'в', 'список'] >>> ' '.join(['Эта', 'инструкция', 'соберет', 'все', 'слова', 'в', 'одну', 'строку']) 'Эта инструкция соберет все слова в одну строку' >>> 'Счастливого Рождества!r'.find('ож') 13 >>> 'Счастливого Рождества!'.replace('Счастливого', 'Чудесного') 'Чудесного Рождества!'Как форматировать строки
Управляющие последовательности
Допустим, нам нужно напечатать на экран такое сообщение: He said, "What's there?" (Он сказал: «Что там?»). Проблема в том, что в этом тексте есть и двойные, и одинарные кавычки (апостроф), поэтому мы не можем использовать их для создания строки — это приведет к ошибке SyntaxError.
>>> print("He said, "What's there?"")
.
SyntaxError: invalid syntax
>>> print('He said, "What's there?"')
.
SyntaxError: invalid syntaxЭта проблема больше актуальная для английского языка, поскольку в русском не используют апострофы, но знать, как ее решить, надо всем.
Есть два способа обойти эту проблему: использовать тройные кавычки или escape-последовательности — их еще иногда называют управляющими последовательностями.
Вот, как это выглядит на практике.
# с помощью тройных кавычке print('''He said, "What's there?"''') # escape-последовательность и одинарные кавычки print('He said, "What\'s there?"') # escape-последовательность и двойные кавычки print("He said, \"What's there?\"")Вывод:
He said, "What's there?"
He said, "What's there?"
He said, "What's there?"Список escape-последовательностей
Управляющая последовательность
Экранирование обратного слэша
Экранирование одинарной кавычки
Экранирование двойной кавычки
Звуковой сигнал или предупреждение
Возврат на одну позицию
Перенос строки на новую
>>> print("C:\\Python32\\Lib") C:\Python32\Lib >>> print("Это сообщение печатается\на двух строках") Это сообщение печатается на двух строкахИгнорирование управляющих последовательностей
Чтобы Python проигнорировал escape-последовательность в строке, можно написать перед этой строкой r или R .
>>> print("Это \nхороший пример") Это хороший пример >>> print(r"Это \nхороший пример") Это \nхороший примерМетод format()
Метод format() — очень гибкий и мощный инструмент для форматирования строк. В качестве заполнителей используются фигурные скобки <> .
Чтобы задать порядок, можно использовать позиционные аргумент и аргументы в виде ключевых слов. Давайте рассмотрим эти способы на примере.
# порядок по умолчанию default_order = "<>, <> и <>".format('Петя','Ваня','Катя') print('\n--- Порядок по умолчанию ---') print(default_order) # порядок с позиционными аргументами positional_order = ", и ".format('Петя','Ваня','Катя') print('\n--- Позиционный порядок ---') print(positional_order) # порядок по ключевым словам keyword_order = ", и ".format(j='Петя',b='Петя',s='Катя') print('\n--- Порядок по ключевым словам ---') print(keyword_order)Вывод:
--- Порядок по умолчанию ---
Петя, Ваня и Катя
--- Позиционный порядок ---
Ваня, Петя и Катя
--- Порядок по ключевым словам ---
Катя, Ваня и ПетяУ метода format() есть дополнительные настройки. Они отделяются от имени поля двоеточием : . Например, строку можно выровнять по левому краю < , по правому краю >или центрировать ее ^ .
Точно так же можно форматировать целые числа в их двоичные, шестнадцатеричные записи и т. д. А числа с плавающей точкой можно округлять или отображать в экспоненциальной записи.
>>> # форматирование целых чисел >>> "Двоичное запись числа = ".format(12) 'Двоичная запись числа 12 = 1100' >>> # форматирование чисел с плавающей точкой >>> "Экспоненциальное представление: ".format(1566.345) 'Экспоненциальное представление: 1.566345e+03' >>> # округление >>> "Одна треть = ".format(1/3) 'Одна треть = 0.333' >>> # выравнивание строк >>> "|||10>|".format('масло', 'булка', 'колбаса') '|масло | булка | колбаса|'
- Использование Python в качестве калькулятора