Основные операции с данными
Для добавления данных в БД в MySQL используется команда INSERT , которая имеет следующий формальный синтаксис:
INSERT [INTO] имя_таблицы [(список_столбцов)] VALUES (значение1, значение2, . значениеN)
После выражения INSERT INTO в скобках можно указать список столбцов через запятую, в которые надо добавлять данные, и в конце после слова VALUES скобках перечисляют добавляемые для столбцов значения.
Например, пусть в базе данных productsdb есть следующая таблица Products:
CREATE DATABASE productsdb; USE productsdb; CREATE TABLE Products ( Id INT AUTO_INCREMENT PRIMARY KEY, ProductName VARCHAR(30) NOT NULL, Manufacturer VARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price DECIMAL NOT NULL );
Добавим в эту таблицу одну строку с помощью следующего кода:
INSERT Products(ProductName, Manufacturer, ProductCount, Price) VALUES ('iPhone X', 'Apple', 5, 76000);
В данно случае значения будут передаваться столбцам по позиции. То есть стобцу ProductName передается строка «iPhone X», столбцу Manufacturer — строка «Apple» и так далее.
Важно, чтобы между значениями и типами данных столбцов было соответствие. Так, столбец ProductName представляет тип varchar , то есть строку. Соответственно этому столбцу мы можем передать строковое значение в одинарных кавычках. А стобец ProductCount представляет тип int , то есть целое число, поэтому данному столбцу нужно передать целые числа, но никак не строки.
После удачного выполнения в MySQL Workbench в поле вывода должны появиться зеленый маркер и сообщение «1 row(s) affected»:
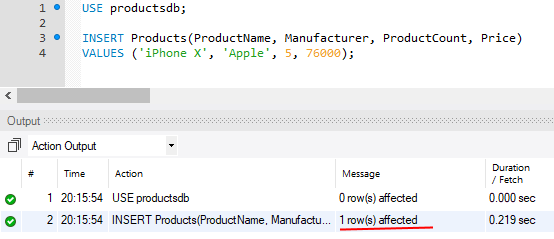
Необязательно при добавлении данных указывать значения абсолютно для всех столбцов таблицы. Например, в примере выше не указано значение для стобца Id. Но поскольку для данного столбца определен атрибут AUTO_INCREMENT , то его значение будет автоматически генерироваться.
Также мы можем опускать при добавлении такие столбцы, которые поддерживают значение NULL или для которых указано значение по умолчанию, то есть для них определены атрибуты NULL или DEFAULT . Так, в таблице Products столбец ProductCount имеет значение по умолчанию — число 0. Поэтому мы можем при добавлении опустить этот столбец, и ему будет передаваться число 0:
INSERT Products(ProductName, Manufacturer, Price) VALUES ('Galaxy S9', 'Samsung', 63000);
С помощью ключевых слов DEFAULT и NULL можно указать, что в качестве значения будет использовать значение по умолчанию или NULL соответственно:
INSERT Products(ProductName, Manufacturer, Price, ProductCount) VALUES ('Nokia 9', 'HDM Global', 41000, DEFAULT);
INSERT Products(ProductName, Manufacturer, Price, ProductCount) VALUES ('Nokia 9', 'HDM Global', 41000, NULL);
Множественное добавление
Также мы можем добавить сразу несколько строк:
INSERT Products(ProductName, Manufacturer, Price, ProductCount) VALUES ('iPhone 8', 'Apple', 51000, 3), ('P20 Lite', 'Huawei', 34000, 4), ('Galaxy S8', 'Samsung', 46000, 2);
В данном случае в таблицу будут добавлены три строки.
Инструкция INSERT (Transact-SQL)
Добавляет одну или несколько строк в таблицу или представление в SQL Server. Примеры см. в разделе Примеры.
Синтаксис
-- Syntax for SQL Server and Azure SQL Database [ WITH [ . n ] ] INSERT < [ TOP ( expression ) [ PERCENT ] ] [ INTO ] < | rowset_function_limited [ WITH ( [ . n ] ) ] > < [ ( column_list ) ] [ ] < VALUES ( < DEFAULT | NULL | expression >[ . n ] ) [ . n ] | derived_table | execute_statement | | DEFAULT VALUES > > > [;] ::= < [ server_name . database_name . schema_name . | database_name .[ schema_name ] . | schema_name . ] table_or_view_name > ::= SELECT FROM ( ) [AS] table_alias [ ( column_alias [ . n ] ) ] [ WHERE ] [ OPTION ( [ . n ] ) ] -- External tool only syntax INSERT < [BULK] < database_name.schema_name.table_or_view_name | schema_name.table_or_view_name | table_or_view_name >( ) [ WITH ( [ [ , ] CHECK_CONSTRAINTS ] [ [ , ] FIRE_TRIGGERS ] [ [ , ] KEEP_NULLS ] [ [ , ] KILOBYTES_PER_BATCH = kilobytes_per_batch ] [ [ , ] ROWS_PER_BATCH = rows_per_batch ] [ [ , ] ORDER ( < column [ ASC | DESC ] >[ . n ] ) ] [ [ , ] TABLOCK ] ) ] > [; ] ::= column_name [ COLLATE collation_name ] [ NULL | NOT NULL ] ::= [ type_schema_name . ] type_name [ ( precision [ , scale ] | max ] -- Syntax for Azure Synapse Analytics and Parallel Data Warehouse and Microsoft Fabric INSERT [INTO] < database_name.schema_name.table_name | schema_name.table_name | table_name >[ ( column_name [ . n ] ) ] < VALUES ( < NULL | expression >) | SELECT > [ OPTION ( [ . n ] ) ] [;] Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
WITH
Определяет временный именованный результирующий набор, также называемый обобщенным табличным выражением, определенным в области инструкции INSERT. Результирующий набор получается из инструкции SELECT. Дополнительные сведения см. в статье WITH common_table_expression (Transact-SQL).
TOP (expression) [ PERCENT ]
Задает число или процент вставляемых случайных строк. expression может быть либо числом, либо процентом от числа строк. Дополнительные сведения см. в разделе TOP (Transact-SQL).
INTO
Необязательное ключевое слово, которое можно использовать между ключевым словом INSERT и целевой таблицей.
server_name
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Имя связанного сервера, на котором расположены таблица или представление. server_name может указываться как имя связанного сервера или с помощью функции OPENDATASOURCE.
Когда server_name указывается как имя связанного сервера, необходимо указать database_name и schema_name. Если server_name указано с помощью OPENDATASOURCE, то аргументы database_name и schema_name могут применяться не ко всем источникам данных, в зависимости от возможностей поставщика OLE DB, который обращается к удаленному объекту.
database_name
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Имя базы данных.
schema_name
Имя схемы, которой принадлежит таблица или представление.
table_or view_name
Имя таблицы или представления, которые принимают данные.
В качестве источника таблицы в инструкции INSERT можно использовать табличную переменную внутри своей области.
Представление, на которое ссылается аргумент table_or_view_name, должно быть обновляемым и ссылаться только на одну базовую таблицу в предложении FROM в представлении. Например, инструкция INSERT в многотабличном представлении должна использовать аргумент column_list, который ссылается только на столбцы из одной базовой таблицы. Дополнительные сведения об обновляемых представлениях см. в разделе CREATE VIEW (Transact-SQL).
rowset_function_limited
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Либо функция OPENQUERY, либо функция OPENROWSET. Использование этих функций зависит от возможностей поставщика OLE DB, который обращается к удаленному объекту.
WITH ( [. n ] )
Задает одно или несколько табличных указаний, разрешенных для целевой таблицы. Ключевое слово WITH и круглые скобки обязательны.
Нельзя использовать подсказки READPAST, NOLOCK, и READUNCOMMITTED. Дополнительные сведения об указаниях по таблицам см. в разделе Указания по таблицам (Transact-SQL).
Возможность указывать указания HOLDLOCK, SERIALIZABLE, READCOMMITTED, REPEATABLEREAD или UPDLOCK для таблиц, которые являются целевыми объектами инструкций INSERT, будут удалены в будущей версии SQL Server. Эти указания не влияют на производительность инструкций INSERT. Избегайте применять их в новых разработках и запланируйте внесение изменений в приложения, использующие их в настоящее время.
Указание подсказки TABLOCK для целевой таблицы инструкции INSERT приведет к тем же последствиям, что и указание подсказки TABLOCKX. К таблице будет применена монопольная блокировка.
(column_list)
Список, состоящий из одного или нескольких столбцов, в которые вставляются данные. Список column_list должен быть заключен в круглые скобки, а его элементы должны разделяться запятыми.
Если столбец не находится в column_list, ядро СУБД должен иметь возможность предоставить значение на основе определения столбца; в противном случае строка не может быть загружена. Ядро СУБД автоматически предоставляет значение столбца, если столбец:
- Имеется свойство IDENTITY. Используется следующее значение приращения для идентификатора.
- Имеется стандартное значение. Используется стандартное значение для столбца.
- Имеет тип данных timestamp. В этом случае используется текущее значение отметки времени.
- Допускает значение NULL. Используется значение NULL.
- Вычисляемый столбец. Используется вычисленное значение.
Аргумент column_list необходимо использовать, когда в столбец идентификаторов вставляются явно заданные значения, а параметру SET IDENTITY_INSERT необходимо присвоить значение ON для таблицы.
Предложение OUTPUT
Возвращает вставленные строки во время операции вставки. Результаты могут возвращаться в обрабатывающее приложение или вставляться в таблицу или табличную переменную для дальнейшей обработки.
Предложение OUTPUT не поддерживается инструкциями DML, которые ссылаются на локальные секционированные представления, распределенные секционированные представления или удаленные таблицы, или инструкциями INSERT, содержащими аргумент execute_statement. Предложение OUTPUT INTO не поддерживается в инструкциях INSERT, содержащих предложение . Дополнительные сведения об аргументах и логике работы этого предложения см. в разделе Предложение OUTPUT (Transact-SQL).
ЗНАЧЕНИЯ
Позволяет использовать один или несколько списков вставляемых значений данных. Для каждого столбца в column_list, если этот параметр указан, или в таблице должно быть одно значение. Список значений должен быть заключен в скобки.
Если значения в списке идут в порядке, отличном от порядка следования столбцов в таблице, или не для каждого столбца таблицы определено значение, то необходимо использовать аргумент column_list для явного указания столбца, в котором хранится каждое входное значение.
Можно использовать конструктор строк Transact-SQL (также называемый конструктором табличных значений), для указания нескольких строк в одной инструкции INSERT. Этот конструктор строк состоит из одного предложения VALUES со списками из нескольких значений, заключенными в круглые скобки и разделенными запятыми. Дополнительные сведения см. в разделе Конструктор табличных значений (Transact-SQL).
Конструктор значений таблиц в Azure Synapse Analytics не поддерживается. Вместо этого можно выполнить приведенные ниже инструкции INSERT для вставки нескольких строк. В Azure Synapse Analytics вставляемые значения могут быть только константными литералами или ссылками на переменные. Чтобы вставить нелитеральное значение, задайте переменной неконстантное значение и вставьте переменную.
ПО УМОЛЧАНИЮ
Принудительно ядро СУБД загрузить значение по умолчанию, определенное для столбца. Если для столбца не задано значение по умолчанию и он может содержать значение NULL, вставляется значение NULL. В столбцы с типом данных timestamp вставляется следующее значение метки времени. Значение DEFAULT недопустимо для столбца идентификаторов.
выражение
Константа, переменная или выражение. Выражение не может содержать инструкцию EXECUTE.
При ссылке на типы данных символов Юникода nchar, nvarchar и ntext выражение ‘expression‘ должно начинаться с заглавной буквы ‘N’. Если значение «N» не указано, SQL Server преобразует строку в кодовую страницу, соответствующую параметрам сортировки по умолчанию базы данных или столбца. Любые символы, не входящие в эту кодовую страницу, будут утрачены.
derived_table
Любая допустимая инструкция SELECT, возвращающая строки данных, которые загружаются в таблицу. Инструкция SELECT не может содержать обобщенное табличное выражение (CTE).
execute_statement
Любая допустимая инструкция EXECUTE, возвращающая данные с помощью инструкций SELECT или READTEXT. Дополнительные сведения см. в статье EXECUTE (Transact-SQL).
Параметры RESULT SETS инструкции EXECUTE нельзя указывать в инструкции INSERT…EXEC.
Если аргумент execute_statement используется с инструкцией INSERT, каждый результирующий набор должен быть совместим со столбцами в таблице или списке column_list.
Аргумент execute_statement может применяться для выполнения хранимых процедур на том же сервере или на сервере, расположенном удаленно. На удаленном сервере выполняется процедура, результирующий набор возвращается на локальный сервер и загружается в таблицу на локальном сервере. В распределенной транзакции нельзя выполнить инструкцию execute_statement для связанного сервера с замыканием на себя, если при соединении включен режим MARS (множественный активный результирующий набор).
Если execute_statement возвращает данные с помощью инструкции READTEXT, каждая инструкция READTEXT может возвращать не более 1 МБ (1024 КБ) данных. execute_statement также может использоваться при работе с расширенными процедурами. execute_statement вставляет данные, возвращенные главным потоком расширенной процедуры; однако выходные данные из других потоков (кроме главного) не вставляются.
Возвращающий табличное значение параметр нельзя указывать в качестве объекта инструкции INSERT EXEC, но его можно указать в виде источника в строке INSERT EXEC или в хранимой процедуре. Дополнительные сведения см. в разделе Использование возвращающих табличные значения параметров (ядро СУБД).
Указывает, что вставленные в целевую таблицу строки были возвращены предложением OUTPUT инструкции INSERT, UPDATE, DELETE или MERGE с возможной фильтрацией предложением WHERE. Если используется аргумент , целевая таблица внешней инструкции INSERT должна удовлетворять следующим ограничениям:
- Быть базовой таблицей, а не представлением.
- Не быть удаленной таблицей.
- Не иметь определенных для нее триггеров.
- Не участвовать в связях «первичный-внешний ключ».
- Объект не должен участвовать в репликации слиянием или обновляемых подписках для репликации транзакций.
Уровень совместимости базы данных должен быть не ниже 100. Дополнительные сведения см. в статье Предложение OUTPUT (Transact-SQL).
Список с разделителями-запятыми, указывающий, какие столбцы возвращены предложением OUTPUT для вставки. Столбцы в должны быть совместимы со столбцами, в которые вставляются значения. не может ссылаться на агрегатные функции или TEXTPTR.
Любые перечисленные в списке SELECT переменные ссылаются на свои исходные значения, независимо от любых изменений, внесенных в них в .
Допустимая инструкция INSERT, UPDATE, DELETE или MERGE, возвращающая изменяемые строки в предложении OUTPUT. Инструкция не может содержать предложение WITH и использовать удаленные таблицы или секционированные представления в качестве целевых. Если указаны UPDATE или DELETE, это не могут быть использующие курсор инструкции UPDATE или DELETE. На исходные строки нельзя ссылаться как на вложенные инструкции DML.
WHERE
Любое предложение WHERE, содержащее допустимый критерий поиска , фильтрующее строки, которые возвращаются аргументом . Дополнительные сведения см. в разделе Условие поиска (Transact-SQL). При использовании в этом контексте критерий не должен содержать вложенных запросов, определяемых пользователем скалярных функций, выполняющих доступ к данным, агрегатных функций, TEXTPTR или предикатов полнотекстового поиска.
DEFAULT VALUES
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Заполняет новую строку значениями по умолчанию, определенными для каждого столбца.
BULK
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Используется внешними средствами для передачи потока двоичных данных. Этот параметр не предназначен для использования с такими инструментами, как SQL Server Management Studio, SQLCMD, OSQL или интерфейсы программирования приложений доступа к данным, такие как собственный клиент SQL Server.
FIRE_TRIGGERS
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Указывает, что при передаче потока двоичных данных будут выполняться триггеры INSERT, определенные для целевой таблицы. Дополнительные сведения см. в разделе BULK INSERT (Transact-SQL).
CHECK_CONSTRAINTS
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Указывает, что при передаче потока двоичных данных будет выполняться проверка всех ограничений целевой таблицы или представления. Дополнительные сведения см. в разделе BULK INSERT (Transact-SQL).
KEEPNULLS
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Указывает, что пустые столбцы во время передачи потока двоичных данных должны сохранить значение NULL. Дополнительные сведения см. в разделе Сохранение значений Null или использование значений по умолчанию при массовом импорте данных (SQL Server).
KILOBYTES_PER_BATCH = kilobytes_per_batch
Определяет приблизительное число килобайт данных в пакете как kilobytes_per_batch. Дополнительные сведения см. в разделе BULK INSERT (Transact-SQL).
ROWS_PER_BATCH =rows_per_batch
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
Указывает приблизительное число строк в потоке двоичных данных. Дополнительные сведения см. в разделе BULK INSERT (Transact-SQL).
Если список столбцов отсутствует, то возникает синтаксическая ошибка.
Замечания
Дополнительную информацию о вставке данных в графовые таблицы SQL см. в разделе INSERT (Граф SQL).
Рекомендации
Используйте функцию @@ROWCOUNT, чтобы вернуть количество вставленных строк клиентскому приложению. Дополнительные сведения см. в разделе @@ROWCOUNT (Transact-SQL).
Рекомендации по массовому импорту данных
Использование инструкции INSERT INTO…SELECT для массового импорта данных с минимальным ведением журнала и параллелизмом
Инструкция INSERT INTO SELECT FROM может эффективно перенести большое количество строк из одной таблицы (например, промежуточной) в другую таблицу с минимальным протоколированием. Минимальное протоколирование может повысить производительность выполнения инструкции и снизить вероятность того, что во время операции будет заполнен весь журнал транзакций.
Для минимального протоколирования этой инструкции необходимо выполнение следующих требований.
- Модель восстановления базы данных настроена на простое или неполное протоколирование.
- целевой таблицей должны быть пустая или непустая куча;
- Целевая таблица не используется в репликации.
- для целевой таблицы должно использоваться указание TABLOCK .
Для строк, которые вставляются в кучу в результате действия вставки в инструкции MERGE, также может применяться минимальное протоколирование.
В отличие от инструкции BULK INSERT , которая удерживает менее строгую блокировку массового обновления, инструкция INSERT INTO … SELECT с указанием TABLOCK удерживает монопольную блокировку (X) таблицы. Это означает, что отсутствует возможность вставки строк с помощью нескольких операций вставки, которые выполняются одновременно.
Однако начиная с SQL Server 2016 (13.x) и уровня совместимости базы данных 130, одна INSERT INTO … SELECT инструкция может выполняться параллельно при вставке в кучу или кластеризованных индексов columnstore (CCI). При использовании указания TABLOCK можно выполнять вставку параллельно.
Требования к параллелизму для указанной выше инструкции (аналогичны требованиям для минимального ведения журнала):
- целевой таблицей должны быть пустая или непустая куча;
- в целевой таблице должны быть кластеризованные индексы columnstore (CCI), но не должно быть некластеризованных индексов;
- для IDENTITY_INSERT в столбце идентификаторов целевой таблицы не должно быть установлено значение OFF;
- для целевой таблицы должно использоваться указание TABLOCK .
Для сценариев, когда требования к минимальному ведению журналов и параллельной вставке соблюдены, оба улучшения будут работать совместно, чтобы обеспечить максимальную пропускную способность для ваших операций загрузки данных.
Дополнительные сведения об использовании INSERT в хранилище в Microsoft Fabric см. в разделе «Прием данных в хранилище» с помощью Transact-SQL.
Операции вставки в локальные временные таблицы (определяемые префиксом #) и глобальные временные таблицы (определяемые префиксами ##) также поддерживают параллелизм с использованием указания TABLOCK.
Использование предложений OPENROWSET и BULK для массового импорта данных
Функция OPENROWSET может принимать следующие табличные подсказки, обеспечивающие оптимизацию массовой загрузки с инструкцией INSERT.
- Использование указания TABLOCK может свести к минимуму число записей в журнале для операции вставки. Для базы данных должна быть установлена простая модель восстановления или модель восстановления с неполным протоколированием. Кроме того, целевая таблица не может использоваться в репликации. Дополнительные сведения см. в разделе Предварительные условия для минимального протоколирования массового импорта данных.
- При использовании указания TABLOCK можно выполнять операции вставки параллельно. Целевая таблица должна быть кучей или кластеризованным индексом columnstore (CCI). При этом не должно быть некластеризованных индексов и для целевой таблицы не должен быть указан столбец идентификаторов.
- Проверку ограничений FOREIGN KEY и CHECK можно временно отключить с помощью указания IGNORE_CONSTRAINTS .
- Выполнение триггеров можно временно отключить с помощью указания IGNORE_TRIGGERS .
- Указание KEEPDEFAULTS позволяет вставить установленное по умолчанию значение столбца таблицы, если таковое имеется, вместо значения NULL, применяемого в случае, когда запись данных не содержит значения для этого столбца.
- Указание KEEPIDENTITY позволяет использовать значения идентификаторов в файле импортированных данных для столбца идентификаторов в целевой таблице.
Эти оптимизации похожи на оптимизации, доступные для команды BULK INSERT . Дополнительные сведения см. в статье Указания по таблицам (Transact-SQL).
Типы данных
При вставке строк необходимо учитывать поведение следующих типов данных:
- Если значение загружается в столбцы с типом данных char, varchar и varbinary, то заполнение или усечение конечных пробелов (пробелы для char и varchar, нули для varbinary) определяется параметром SET ANSI_PADDING, определенным для столбца при создании таблицы. Дополнительные сведения см. в разделе SET ANSI_PADDING (Transact-SQL). В следующей таблице показаны операции по умолчанию для параметра SET ANSI_PADDING, установленного в значение OFF.
Тип данных Стандартная операция char Заполнение значения пробелами до заданной ширины столбца. varchar Удаление конечных пробелов до последнего непробельного символа или до одного пробела, если строка состоит только из пробелов. varbinary Удаление конечных нулей. - Если пустая строка (‘ ‘) загружена в столбец с типом данных varchar или text, то операцией по умолчанию будет загрузка строки нулевой длины.
- Вставка значения NULL в столбец text или image не приводит ни к созданию допустимого текстового указателя, ни к предварительному распределению 8-килобайтной текстовой страницы.
- Столбцы, созданные с типом данных uniqueidentifier, содержат двоичные 16-байтные значения специального формата. В отличие от столбцов удостоверений, ядро СУБД не создает значения для столбцов с типом данных uniqueidentifier. При вставке переменные с типом данных uniqueidentifier и константы строк в форме xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (36 символов, включая дефисы, где x является шестнадцатеричной цифрой в диапазоне 0–9 или a–f) могут быть использованы для столбцов uniqueidentifier. Например, 6F9619FF-8B86-D011-B42D-00C04FC964FF является допустимым значением переменной или столбца uniqueidentifier. Используйте функцию NEWID() для получения идентификатора GUID.
Вставка значений в столбцы определяемого пользователем типа
Вставлять значения в столбцы определяемого пользователем типа можно следующими способами.
- Предоставление значения определяемого пользователем типа.
- Предоставление значения в системном типе данных SQL Server, если определяемый пользователем тип поддерживает неявное или явное преобразование из этого типа. В следующем примере показано, как вставляются значения из столбца определяемого пользователем типа Point путем явного преобразования из строки.
INSERT INTO Cities (Location) VALUES ( CONVERT(Point, '12.3:46.2') ); INSERT INTO Cities (Location) VALUES ( dbo.CreateNewPoint(x, y) ); Обработка ошибок
Для инструкции INSERT можно реализовать обработку ошибок, указав инструкцию в конструкции TRY…CATCH.
Если инструкция INSERT нарушает ограничение или правило, либо в ней присутствует значение, несовместимое с типом данных столбца, то при выполнении инструкции происходит сбой и отображается сообщение об ошибке.
Если инструкция INSERT загружает несколько строк с помощью инструкции SELECT или EXECUTE, то любые нарушения правил или ограничений, возникающие из-за загружаемых значений, приводят к остановке выполнения инструкции, и ни одна из строк не будет загружена.
Когда инструкция INSERT обнаруживает арифметическую ошибку (переполнение, деление на ноль или ошибку домена), возникающей во время оценки выражений, ядро СУБД обрабатывает эти ошибки, как если параметр SET ARITHABORT имеет значение ON. Выполнение пакета прекращается и выводится сообщение об ошибке. Во время вычисления выражений, когда параметр SET ARITHABORT и SET ANSI_WARNINGS отключен, если инструкция INSERT, DELETE или UPDATE сталкивается с арифметической ошибкой, переполнением, разделением на ноль или ошибкой домена, SQL Server вставляет или обновляет значение NULL. Если целевой столбец не пустой, вставка или обновление не осуществляются, и пользователь получает ошибку.
Совместимость
Если триггер INSTEAD OF определен в операциях INSERT для таблицы или представления, то триггер выполняется вместо инструкции INSERT. Дополнительные сведения о триггерах INSTEAD OF см. в разделе CREATE TRIGGER (Transact-SQL).
Ограничения
Если во время вставки значений в удаленные таблицы указаны не все значения для всех столбцов, то необходимо указать столбцы, в которые вставляются заданные значения.
При использовании выражения TOP в инструкции INSERT строки, на которые имеются ссылки, не упорядочиваются, а предложение ORDER BY не может быть прямо указано в этих инструкциях. Если для вставки строк в значимом хронологическом порядке необходимо использовать предложение TOP, вместе с ним в инструкции подзапроса выборки следует использовать предложение ORDER BY. См. подраздел «Примеры» далее в этом разделе.
Запросы INSERT, которые используют SELECT с ORDER BY для заполнения строк, гарантируют способ вычисления значений идентификатора, но не порядок вставки строк.
В Parallel Data Warehouse предложение ORDER BY недопустимо в инструкциях VIEWS, CREATE TABLE AS SELECT, INSERT SELECT, встраиваемых функциях, производных таблицах, подзапросах и обобщенных табличных выражениях, если также не указать TOP.
Режим ведения журнала
Инструкция INSERT всегда полностью регистрируется в журнале, кроме случаев использования функции OPENROWSET с ключевым словом BULK или выполнения инструкции INSERT INTO SELECT FROM . Для этих операций возможно минимальное протоколирование. Дополнительные сведения см. в подразделе «Рекомендации по массовой загрузке данных» этого раздела.
Безопасность
При соединении со связанным сервером отправляющий сервер указывает имя входа и пароль для подключения к принимающему серверу от его имени. Для работы этого соединения необходимо создать сопоставление имен входа между связанными серверами вызовом хранимой процедуры sp_addlinkedsrvlogin.
При использовании OPENROWSET(BULK. ) важно понимать, как SQL Server обрабатывает олицетворение. Дополнительные сведения см. в главе «Вопросы безопасности» в разделе Массовый импорт данных при помощи инструкции BULK INSERT или OPENROWSET(BULK. ) (SQL Server).
Разрешения
Требуется разрешение INSERT на целевую таблицу.
Разрешения INSERT предоставлены по умолчанию членам предопределенной роли сервера sysadmin , членам предопределенных ролей баз данных db_owner и db_datawriter , а также владельцу таблицы. Члены ролей sysadmin , db_owner и db_securityadmin , а также владелец таблицы могут передавать разрешения другим пользователям.
Чтобы выполнить инструкцию INSERT с параметром BULK функции OPENROWSET, необходимо быть членом предопределенной роли сервера sysadmin или bulkadmin .
Примеры
| Категория | Используемые элементы синтаксиса |
|---|---|
| Основной синтаксис | Конструктор значений INSERT * табличного значения |
| Обработка значений столбца | IDENTITY * NEWID * значения по умолчанию * определяемые пользователем типы |
| Вставка данных из других таблиц | ВСТАВИТЬ. SELECT * INSERT. EXECUTE * WITH common table expression * TOP * OFFSET FETCH |
| Указание целевых объектов, отличных от стандартных таблиц | Представления * табличные переменные |
| Вставка строк в удаленную таблицу | Связанный сервер * функция набора строк OPENQUERY * функция набора строк OPENDATASOURCE |
| Массовая загрузка данных из таблиц или файлов данных | ВСТАВИТЬ. SELECT * ФУНКЦИЯ OPENROWSET |
| Переопределение поведения по умолчанию для оптимизатора запросов с помощью указаний | Табличные указания |
| Сбор результатов инструкции INSERT | OUTPUT, предложение |
Базовый синтаксис
В примерах в этом разделе описывается базовая функциональность инструкции INSERT с помощью минимального необходимого синтаксиса.
А. Вставка одной строки данных
В следующем примере вставляется одна строка в таблицу Production.UnitMeasure в базе данных AdventureWorks2022. В этой таблице содержатся столбцы UnitMeasureCode , Name и ModifiedDate . Так как значения для всех столбцов предоставлены и перечислены в том же порядке, что и столбцы в таблице, не требуется указывать имена столбцов в списке столбцов*.*
INSERT INTO Production.UnitMeasure VALUES (N'FT', N'Feet', '20080414'); B. Вставка нескольких строк данных
В следующем примере конструктор значений таблицы используется для вставки трех строк Production.UnitMeasure в таблицу в базе данных AdventureWorks2022 в одной инструкции INSERT. Так как значения для всех столбцов предоставлены и перечислены в том же порядке, что и столбцы в таблице, то не нужно в параметре указывать имена столбцов.
Конструктор значений таблицы не поддерживается в Azure Synapse Analytics.
INSERT INTO Production.UnitMeasure VALUES (N'FT2', N'Square Feet ', '20080923'), (N'Y', N'Yards', '20080923') , (N'Y3', N'Cubic Yards', '20080923'); C. Вставка данных в порядке, отличном от порядка столбцов таблицы
В следующем примере используется список столбцов для явного указания значений, которые будут вставляться в каждый столбец. Порядок столбцов в таблице базы Production.UnitMeasure данных AdventureWorks2022 имеет UnitMeasureCode значение , ModifiedDate Name но столбцы не перечислены в этом порядке в column_list.
INSERT INTO Production.UnitMeasure (Name, UnitMeasureCode, ModifiedDate) VALUES (N'Square Yards', N'Y2', GETDATE()); Обработка значений столбцов
Примеры в этом разделе описывают методы вставки значений в столбцы, которые определяются с помощью свойства IDENTITY, значения DEFAULT или с помощью типов данных, таких как uniqueidentifer или столбцов определяемого пользователем типа.
D. Вставка данных в таблицу со столбцами, имеющими значение по умолчанию
В следующем примере показана вставка строк в таблицу со столбцами, для которых автоматически создается значение или которые имеют значение по умолчанию. Column_1 — это вычисляемый столбец, который автоматически создает значение, объединяя строку со значением, вставленным в столбец column_2 . Столбец Column_2 определен с ограничением по умолчанию. Если для этого столбца не указано значение, используется значение по умолчанию. Столбец Column_3 имеет тип данных rowversion, который автоматически создает уникальное, последовательно увеличиваемое двоичное число. Столбец Column_4 не формирует значения автоматически. Если значение для этого столбца отсутствует, то вставляется значение NULL. Инструкция INSERT вставляет строки, которые содержат значения для некоторых столбцов, но не для всех. В последней инструкции INSERT столбцы не указаны, и поэтому вставляются только значения по умолчанию с помощью предложения DEFAULT VALUES.
CREATE TABLE dbo.T1 ( column_1 AS 'Computed column ' + column_2, column_2 varchar(30) CONSTRAINT default_name DEFAULT ('my column default'), column_3 rowversion, column_4 varchar(40) NULL ); GO INSERT INTO dbo.T1 (column_4) VALUES ('Explicit value'); INSERT INTO dbo.T1 (column_2, column_4) VALUES ('Explicit value', 'Explicit value'); INSERT INTO dbo.T1 (column_2) VALUES ('Explicit value'); INSERT INTO T1 DEFAULT VALUES; GO SELECT column_1, column_2, column_3, column_4 FROM dbo.T1; GO Д. Вставка данных в таблицу со столбцом идентификаторов
В следующем примере показаны различные методы вставки данных в столбец идентификаторов. Первые две инструкции INSERT позволяют формировать значения идентификаторов для новых строк. Третья инструкция INSERT переопределяет свойство IDENTITY столбца с помощью инструкции SET IDENTITY_INSERT и вставляет явно заданное значение в столбец идентификаторов.
CREATE TABLE dbo.T1 ( column_1 int IDENTITY, column_2 VARCHAR(30)); GO INSERT T1 VALUES ('Row #1'); INSERT T1 (column_2) VALUES ('Row #2'); GO SET IDENTITY_INSERT T1 ON; GO INSERT INTO T1 (column_1,column_2) VALUES (-99, 'Explicit identity value'); GO SELECT column_1, column_2 FROM T1; GO Е. Вставка данных в столбец типа uniqueidentifier с помощью функции NEWID()
В следующем примере функция NEWID() вызывается для вставки идентификатора GUID в столбец column_2 . В отличие от столбцов удостоверений, ядро СУБД не создает значения для столбцов с типом данных uniqueidentifier, как показано во втором INSERT операторе.
CREATE TABLE dbo.T1 ( column_1 int IDENTITY, column_2 uniqueidentifier, ); GO INSERT INTO dbo.T1 (column_2) VALUES (NEWID()); INSERT INTO T1 DEFAULT VALUES; GO SELECT column_1, column_2 FROM dbo.T1; G. Вставка данных в столбцы определяемого пользователем типа
Следующие инструкции Transact-SQL вставляют три строки в столбец PointValue таблицы Points . Этот столбец имеет определяемый пользователем тип данных CLR. Тип данных Point состоит из целочисленных значений X и Y, которые представлены как свойства определяемого пользователем типа. Необходимо привести разделяемые запятой значения X и Y к типу Point с помощью функции CAST или CONVERT. Первые две инструкции используют функцию CONVERT для преобразования строкового значения в тип Point , а третья инструкция использует функцию CAST. Дополнительные сведения см. в разделе Работа с данными определяемого пользователем типа.
INSERT INTO dbo.Points (PointValue) VALUES (CONVERT(Point, '3,4')); INSERT INTO dbo.Points (PointValue) VALUES (CONVERT(Point, '1,5')); INSERT INTO dbo.Points (PointValue) VALUES (CAST ('1,99' AS Point)); Вставка данных из других таблиц
В примерах этого раздела показаны методы вставки строк из одной таблицы в другую.
H. Вставка данных из других таблиц с помощью параметров SELECT и EXECUTE
В следующем примере описана вставка данных из одной таблицы в другую с помощью инструкций INSERT…SELECT и INSERT…EXECUTE. Каждый метод основан на многотабличной инструкции SELECT, содержащей выражение и литеральное значение в списке столбцов.
Первая инструкция INSERT использует инструкцию SELECT для получения данных из исходных таблиц ( Employee , SalesPerson и Person ) в базе данных AdventureWorks2022 и хранения результирующий набор в EmployeeSales таблице. Вторая инструкция INSERT с помощью предложения EXECUTE вызывает хранимую процедуру, содержащую инструкцию SELECT, а третья инструкция INSERT с помощью предложения EXECUTE ссылается на инструкцию SELECT как на символьную строку.
CREATE TABLE dbo.EmployeeSales ( DataSource varchar(20) NOT NULL, BusinessEntityID varchar(11) NOT NULL, LastName varchar(40) NOT NULL, SalesDollars money NOT NULL ); GO CREATE PROCEDURE dbo.uspGetEmployeeSales AS SET NOCOUNT ON; SELECT 'PROCEDURE', sp.BusinessEntityID, c.LastName, sp.SalesYTD FROM Sales.SalesPerson AS sp INNER JOIN Person.Person AS c ON sp.BusinessEntityID = c.BusinessEntityID WHERE sp.BusinessEntityID LIKE '2%' ORDER BY sp.BusinessEntityID, c.LastName; GO --INSERT. SELECT example INSERT INTO dbo.EmployeeSales SELECT 'SELECT', sp.BusinessEntityID, c.LastName, sp.SalesYTD FROM Sales.SalesPerson AS sp INNER JOIN Person.Person AS c ON sp.BusinessEntityID = c.BusinessEntityID WHERE sp.BusinessEntityID LIKE '2%' ORDER BY sp.BusinessEntityID, c.LastName; GO --INSERT. EXECUTE procedure example INSERT INTO dbo.EmployeeSales EXECUTE dbo.uspGetEmployeeSales; GO --INSERT. EXECUTE('string') example INSERT INTO dbo.EmployeeSales EXECUTE (' SELECT ''EXEC STRING'', sp.BusinessEntityID, c.LastName, sp.SalesYTD FROM Sales.SalesPerson AS sp INNER JOIN Person.Person AS c ON sp.BusinessEntityID = c.BusinessEntityID WHERE sp.BusinessEntityID LIKE ''2%'' ORDER BY sp.BusinessEntityID, c.LastName '); GO --Show results. SELECT DataSource,BusinessEntityID,LastName,SalesDollars FROM dbo.EmployeeSales; I. Использование обобщенного табличного выражения WITH для определения вставляемых данных
В следующем примере создается NewEmployee таблица в базе данных AdventureWorks2022. Обобщенное табличное выражение ( EmployeeTemp ) определяет строки из одной или нескольких таблиц, которые вставляются в таблицу NewEmployee . Инструкция INSERT ссылается на столбцы в обобщенном табличном выражении.
CREATE TABLE HumanResources.NewEmployee ( EmployeeID int NOT NULL, LastName nvarchar(50) NOT NULL, FirstName nvarchar(50) NOT NULL, PhoneNumber Phone NULL, AddressLine1 nvarchar(60) NOT NULL, City nvarchar(30) NOT NULL, State nchar(3) NOT NULL, PostalCode nvarchar(15) NOT NULL, CurrentFlag Flag ); GO WITH EmployeeTemp (EmpID, LastName, FirstName, Phone, Address, City, StateProvince, PostalCode, CurrentFlag) AS (SELECT e.BusinessEntityID, c.LastName, c.FirstName, pp.PhoneNumber, a.AddressLine1, a.City, sp.StateProvinceCode, a.PostalCode, e.CurrentFlag FROM HumanResources.Employee e INNER JOIN Person.BusinessEntityAddress AS bea ON e.BusinessEntityID = bea.BusinessEntityID INNER JOIN Person.Address AS a ON bea.AddressID = a.AddressID INNER JOIN Person.PersonPhone AS pp ON e.BusinessEntityID = pp.BusinessEntityID INNER JOIN Person.StateProvince AS sp ON a.StateProvinceID = sp.StateProvinceID INNER JOIN Person.Person as c ON e.BusinessEntityID = c.BusinessEntityID ) INSERT INTO HumanResources.NewEmployee SELECT EmpID, LastName, FirstName, Phone, Address, City, StateProvince, PostalCode, CurrentFlag FROM EmployeeTemp; GO J. Использование TOP для ограничения данных, вставляемых из исходной таблицы
В следующем примере создается таблица EmployeeSales и вставляется данные о продажах по имени и годам для первых 5 случайных сотрудников из таблицы HumanResources.Employee в базе данных AdventureWorks2022. Инструкция INSERT выбирает любые пять строк из строк, возвращенных инструкцией SELECT . Предложение OUTPUT отображает строки, вставляемые в таблицу EmployeeSales . Обратите внимание, что предложение ORDER BY в инструкции SELECT не используется для определения 5 наиболее успешных сотрудников.
CREATE TABLE dbo.EmployeeSales ( EmployeeID nvarchar(11) NOT NULL, LastName nvarchar(20) NOT NULL, FirstName nvarchar(20) NOT NULL, YearlySales money NOT NULL ); GO INSERT TOP(5)INTO dbo.EmployeeSales OUTPUT inserted.EmployeeID, inserted.FirstName, inserted.LastName, inserted.YearlySales SELECT sp.BusinessEntityID, c.LastName, c.FirstName, sp.SalesYTD FROM Sales.SalesPerson AS sp INNER JOIN Person.Person AS c ON sp.BusinessEntityID = c.BusinessEntityID WHERE sp.SalesYTD > 250000.00 ORDER BY sp.SalesYTD DESC; Если для вставки строк в значимом хронологическом порядке решено использовать предложение TOP, вместе с ним в инструкции подзапроса выборки следует использовать предложение ORDER BY, как показано в следующем примере. Предложение OUTPUT отображает строки, вставляемые в таблицу EmployeeSales . Обратите внимание, что вставка данных 5 наиболее успешных сотрудников выполняется на основе результатов предложения ORDER BY, а не случайных строк.
INSERT INTO dbo.EmployeeSales OUTPUT inserted.EmployeeID, inserted.FirstName, inserted.LastName, inserted.YearlySales SELECT TOP (5) sp.BusinessEntityID, c.LastName, c.FirstName, sp.SalesYTD FROM Sales.SalesPerson AS sp INNER JOIN Person.Person AS c ON sp.BusinessEntityID = c.BusinessEntityID WHERE sp.SalesYTD > 250000.00 ORDER BY sp.SalesYTD DESC; Указание целевых объектов, отличных от стандартных таблиц
В примерах этого раздела показаны методы вставки строк с указанием представления или табличной переменной.
K. Вставка данных с указанием представления
В следующем примере в качестве целевого объекта указано имя представления; новая строка вставляется в базовую таблицу. Порядок следования значений в инструкции INSERT должен совпадать с порядком следования столбцов в представлении. Дополнительные сведения см. в разделе Изменение данных через представление.
CREATE TABLE T1 ( column_1 int, column_2 varchar(30)); GO CREATE VIEW V1 AS SELECT column_2, column_1 FROM T1; GO INSERT INTO V1 VALUES ('Row 1',1); GO SELECT column_1, column_2 FROM T1; GO SELECT column_1, column_2 FROM V1; GO L. Вставка данных в табличную переменную
В следующем примере указывается табличная переменная в качестве целевого объекта в базе данных AdventureWorks2022.
-- Create the table variable. DECLARE @MyTableVar table( LocationID int NOT NULL, CostRate smallmoney NOT NULL, NewCostRate AS CostRate * 1.5, ModifiedDate datetime); -- Insert values into the table variable. INSERT INTO @MyTableVar (LocationID, CostRate, ModifiedDate) SELECT LocationID, CostRate, GETDATE() FROM Production.Location WHERE CostRate > 0; -- View the table variable result set. SELECT * FROM @MyTableVar; GO Вставка строк в удаленную таблицу
В примерах в этом разделе описаны способы вставки в удаленную целевую таблицу с использованием в качестве ссылки на удаленную таблицу связанного сервера или функции, возвращающей набор строк.
M. Вставка данных в удаленную таблицу с использованием связанного сервера
В следующем примере в удаленную таблицу вставляются строки. Этот пример начинается с создания ссылки на удаленный источник данных с помощью хранимой процедуры sp_addlinkedserver. Имя связанного сервера, MyLinkServer , затем определяется как часть четырехчастного имени объекта в форме server.catalog.schema.object.
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
USE master; GO -- Create a link to the remote data source. -- Specify a valid server name for @datasrc as 'server_name' -- or 'server_nameinstance_name'. EXEC sp_addlinkedserver @server = N'MyLinkServer', @srvproduct = N' ', @provider = N'SQLNCLI', @datasrc = N'server_name', @catalog = N'AdventureWorks2022'; GO -- Specify the remote data source in the FROM clause using a four-part name -- in the form linked_server.catalog.schema.object. INSERT INTO MyLinkServer.AdventureWorks2022.HumanResources.Department (Name, GroupName) VALUES (N'Public Relations', N'Executive General and Administration'); GO О. Вставка данных в удаленную таблицу с помощью функции OPENQUERY
В следующем примере выполняется вставка строки в удаленную таблицу с помощью вызова функции OPENQUERY, возвращающей набор строк. В этом примере используется имя связанного сервера, созданного в предыдущем примере.
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
INSERT OPENQUERY (MyLinkServer, 'SELECT Name, GroupName FROM AdventureWorks2022.HumanResources.Department') VALUES ('Environmental Impact', 'Engineering'); GO O. Вставка данных в удаленную таблицу с помощью функции OPENDATASOURCE
В следующем примере выполняется вставка строки в удаленную таблицу с помощью вызова функции OPENDATASOURCE, возвращающей набор строк. Определите допустимое имя сервера для источника данных, используя формат server_name или server_name\instance_name.
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
-- Use the OPENDATASOURCE function to specify the remote data source. -- Specify a valid server name for Data Source using the format -- server_name or server_nameinstance_name. INSERT INTO OPENDATASOURCE('SQLNCLI', 'Data Source= ; Integrated Security=SSPI') .AdventureWorks2022.HumanResources.Department (Name, GroupName) VALUES (N'Standards and Methods', 'Quality Assurance'); GO P. Вставка во внешнюю таблицу, созданную с помощью PolyBase
Вы можете экспортировать данные из SQL Server в службу хранилища Azure или Hadoop. Для этого сначала необходимо создать внешнюю таблицу, которая указывает на целевой файл или каталог. Затем используйте инструкцию INSERT INTO, чтобы экспортировать данные из локальной таблицы SQL Server во внешний источник данных. При выполнении инструкции INSERT INTO создается целевой файл или каталог (если его не существует), а результаты выполнения инструкции SELECT экспортируются в указанное расположение в заданном формате. Дополнительные сведения см. в разделе Приступая к работе с PolyBase.
Область применения: SQL Server.
-- Create an external table. CREATE EXTERNAL TABLE [dbo].[FastCustomers2009] ( [FirstName] char(25) NOT NULL, [LastName] char(25) NOT NULL, [YearlyIncome] float NULL, [MaritalStatus] char(1) NOT NULL ) WITH ( LOCATION='/old_data/2009/customerdata.tbl', DATA_SOURCE = HadoopHDP2, FILE_FORMAT = TextFileFormat, REJECT_TYPE = VALUE, REJECT_VALUE = 0 ); -- Export data: Move old data to Hadoop while keeping -- it query-able via external table. INSERT INTO dbo.FastCustomer2009 SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2 ON (T1.CustomerKey = T2.CustomerKey) WHERE T2.YearMeasured = 2009 and T2.Speed > 40; Массовая загрузка данных из таблиц или файлов данных
В примерах этого раздела показано два метода массовой загрузки данных в таблицу с помощью инструкции INSERT.
В. Вставка данных в кучу с минимальным протоколированием
В следующем примере создается таблица (куча), в которую вставляются данные из другой таблицы с минимальным протоколированием. В примере предполагается, что для базы данных AdventureWorks2022 выбрана модель восстановления FULL. Чтобы убедиться, что применяется минимальное протоколирование, модель восстановления базы данных AdventureWorks2022 перед вставкой строк устанавливается в значение BULK_LOGGED, а после выполнения инструкции INSERT INTO… SELECT возвращается в значение FULL. Кроме того, для целевой таблицы Sales.SalesHistory указывается подсказка TABLOCK. Это обеспечивает минимальное использование журнала транзакций инструкцией и ее эффективное выполнение.
-- Create the target heap. CREATE TABLE Sales.SalesHistory( SalesOrderID int NOT NULL, SalesOrderDetailID int NOT NULL, CarrierTrackingNumber nvarchar(25) NULL, OrderQty smallint NOT NULL, ProductID int NOT NULL, SpecialOfferID int NOT NULL, UnitPrice money NOT NULL, UnitPriceDiscount money NOT NULL, LineTotal money NOT NULL, rowguid uniqueidentifier ROWGUIDCOL NOT NULL, ModifiedDate datetime NOT NULL ); GO -- Temporarily set the recovery model to BULK_LOGGED. ALTER DATABASE AdventureWorks2022 SET RECOVERY BULK_LOGGED; GO -- Transfer data from Sales.SalesOrderDetail to Sales.SalesHistory INSERT INTO Sales.SalesHistory WITH (TABLOCK) (SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, LineTotal, rowguid, ModifiedDate) SELECT * FROM Sales.SalesOrderDetail; GO -- Reset the recovery model. ALTER DATABASE AdventureWorks2022 SET RECOVERY FULL; GO R. Использование функции OPENROWSET с параметром BULK для массовой загрузки данных а таблицу
В следующем примере выполняется вставка строки в таблицу из файла данных вызовом функции OPENQUERY. Для оптимизации производительности указывается табличная подсказка IGNORE_TRIGGERS. Дополнительные примеры см. в разделе Массовый импорт данных при помощи инструкции BULK INSERT или OPENROWSET(BULK. ) (SQL Server).
Применимо: SQL Server 2008 (10.0.x) и более поздних версий.
INSERT INTO HumanResources.Department WITH (IGNORE_TRIGGERS) (Name, GroupName) SELECT b.Name, b.GroupName FROM OPENROWSET ( BULK 'C:SQLFilesDepartmentData.txt', FORMATFILE = 'C:SQLFilesBulkloadFormatFile.xml', ROWS_PER_BATCH = 15000)AS b ; Переопределение поведения по умолчанию для оптимизатора запросов с помощью указаний
Примеры в этом разделе описывают использование табличных указаний для временного переопределения поведения оптимизатора запросов при обработке инструкции INSERT.
Так как оптимизатор запросов SQL Server обычно выбирает оптимальный план выполнения для запроса, мы рекомендуем использовать указания только в качестве последнего средства опытными разработчиками и администраторами баз данных.
S. Использование подсказки TABLOCK для указания метода блокировки
В следующем примере показано, как монопольная блокировка (Х) применяется к таблице Production.Location и сохраняется до завершения инструкции UPDATE.
Применимо к: SQL Server, База данных SQL.
INSERT INTO Production.Location WITH (XLOCK) (Name, CostRate, Availability) VALUES ( N'Final Inventory', 15.00, 80.00); Получение результатов инструкции INSERT
Примеры в этом разделе описывают использование предложения OUTPUT для возврата данных для всех строк, изменившихся в результате выполнения инструкции INSERT, либо выражений на основе этих данных. Эти результаты могут быть возвращены приложению, например для вывода подтверждающих сообщений, архивирования и т. п.
T. Использование предложения OUTPUT с инструкцией INSERT
В следующем примере производится вставка строки в таблицу ScrapReason , а затем при помощи предложения OUTPUT результаты выполнения инструкции возвращаются в табличную переменную @MyTableVar . Так как столбец ScrapReasonID определен с помощью свойства IDENTITY , то значение для этого столбца не указано в инструкции INSERT . Однако обратите внимание, что значение, созданное ядро СУБД для этого столбца, возвращается в OUTPUT предложении в столбце INSERTED.ScrapReasonID .
DECLARE @MyTableVar table( NewScrapReasonID smallint, Name varchar(50), ModifiedDate datetime); INSERT Production.ScrapReason OUTPUT INSERTED.ScrapReasonID, INSERTED.Name, INSERTED.ModifiedDate INTO @MyTableVar VALUES (N'Operator error', GETDATE()); --Display the result set of the table variable. SELECT NewScrapReasonID, Name, ModifiedDate FROM @MyTableVar; --Display the result set of the table. SELECT ScrapReasonID, Name, ModifiedDate FROM Production.ScrapReason; Ф. Применение предложения OUTPUT со столбцами идентификаторов и вычисляемыми столбцами
В следующем примере создается таблица EmployeeSales , а затем в нее с помощью инструкции INSERT вставляется несколько строк, получаемых инструкцией SELECT из исходных таблиц. Таблица EmployeeSales содержит столбец идентификаторов ( EmployeeID ) и вычисляемый столбец ( ProjectedSales ). Так как эти значения создаются ядро СУБД во время операции вставки, ни в этих столбцах не могут быть определены @MyTableVar .
CREATE TABLE dbo.EmployeeSales ( EmployeeID int IDENTITY (1,5)NOT NULL, LastName nvarchar(20) NOT NULL, FirstName nvarchar(20) NOT NULL, CurrentSales money NOT NULL, ProjectedSales AS CurrentSales * 1.10 ); GO DECLARE @MyTableVar table( LastName nvarchar(20) NOT NULL, FirstName nvarchar(20) NOT NULL, CurrentSales money NOT NULL ); INSERT INTO dbo.EmployeeSales (LastName, FirstName, CurrentSales) OUTPUT INSERTED.LastName, INSERTED.FirstName, INSERTED.CurrentSales INTO @MyTableVar SELECT c.LastName, c.FirstName, sp.SalesYTD FROM Sales.SalesPerson AS sp INNER JOIN Person.Person AS c ON sp.BusinessEntityID = c.BusinessEntityID WHERE sp.BusinessEntityID LIKE '2%' ORDER BY c.LastName, c.FirstName; SELECT LastName, FirstName, CurrentSales FROM @MyTableVar; GO SELECT EmployeeID, LastName, FirstName, CurrentSales, ProjectedSales FROM dbo.EmployeeSales; V. Вставка данных, возвращенных предложением OUTPUT
В следующем примере производится отслеживание данных, возвращаемых предложением OUTPUT инструкции MERGE, а затем производится вставка этих данных в другую таблицу. Инструкция MERGE обновляет Quantity столбец ProductInventory таблицы ежедневно на основе заказов, обрабатываемых в SalesOrderDetail таблице в базе данных AdventureWorks2022. Инструкция также удаляет строки с продуктами, запас которых сократился до 0. В примере собираются удаленные строки и вставляются в другую таблицу, ZeroInventory , в которой ведется учет закончившихся продуктов.
--Create ZeroInventory table. CREATE TABLE Production.ZeroInventory (DeletedProductID int, RemovedOnDate DateTime); GO INSERT INTO Production.ZeroInventory (DeletedProductID, RemovedOnDate) SELECT ProductID, GETDATE() FROM ( MERGE Production.ProductInventory AS pi USING (SELECT ProductID, SUM(OrderQty) FROM Sales.SalesOrderDetail AS sod JOIN Sales.SalesOrderHeader AS soh ON sod.SalesOrderID = soh.SalesOrderID AND soh.OrderDate = '20070401' GROUP BY ProductID) AS src (ProductID, OrderQty) ON (pi.ProductID = src.ProductID) WHEN MATCHED AND pi.Quantity - src.OrderQty Ц. Вставка данных с помощью параметра SELECT
В следующем примере показано, как вставить несколько строк данных с помощью инструкции INSERT с параметром SELECT. Первая инструкция INSERT напрямую использует инструкцию SELECT для получения данных из исходной таблицы и сохранения результирующего набора в таблице EmployeeTitles .
CREATE TABLE EmployeeTitles ( EmployeeKey INT NOT NULL, LastName varchar(40) NOT NULL, Title varchar(50) NOT NULL ); INSERT INTO EmployeeTitles SELECT EmployeeKey, LastName, Title FROM ssawPDW.dbo.DimEmployee WHERE EndDate IS NULL; .X Указание метки с инструкцией INSERT
В следующем примере показано использование метки с инструкцией INSERT.
-- Uses AdventureWorks INSERT INTO DimCurrency VALUES (500, N'C1', N'Currency1') OPTION ( LABEL = N'label1' ); Y. Использование метки и указания запроса с инструкцией INSERT
Этот запрос показывает базовый синтаксис для использования метки и указания на соединение с запросом с инструкцией INSERT. После отправки запроса на узел Control SQL Server, работающий на вычислительных узлах, будет применять стратегию хэш-соединения при создании плана запросов SQL Server. Дополнительные сведения об указаниях по соединению и использованию предложения OPTION см. в разделе OPTION (SQL Server PDW).
-- Uses AdventureWorks INSERT INTO DimCustomer (CustomerKey, CustomerAlternateKey, FirstName, MiddleName, LastName ) SELECT ProspectiveBuyerKey, ProspectAlternateKey, FirstName, MiddleName, LastName FROM ProspectiveBuyer p JOIN DimGeography g ON p.PostalCode = g.PostalCode WHERE g.CountryRegionCode = 'FR' OPTION ( LABEL = 'Add French Prospects', HASH JOIN); Запрос MySQL INSERT INTO: как добавить строку в таблицу (пример)
ВСТАВИТЬ В используется для хранения данных в таблицах. Команда INSERT создает в таблице новую строку для хранения данных. Данные обычно предоставляются прикладными программами, которые работают поверх базы данных.
Основной синтаксис
Давайте посмотрим на основной синтаксис команды INSERT INTO MySQL:
INSERT INTO `table_name`(column_1,column_2. ) VALUES (value_1,value_2. );
ВОТ
- INSERT INTO `table_name` — это команда, которая сообщает серверу MySQL добавить новую строку в таблицу с именем `table_name`.
- (column_1,column_2,…) указывает столбцы, которые будут обновлены в новой строке MySQL.
- VALUES (value_1,value_2,…) определяет значения, которые будут добавлены в новую строку.
При предоставлении значений данных для вставки в новую таблицу следует учитывать следующее:
- Строковые типы данных – все строковые значения должны быть заключены в одинарные кавычки.
- Числовые типы данных. Все числовые значения следует указывать напрямую, не заключая их в одинарные или двойные кавычки.
- Типы данных даты — значения даты заключаются в одинарные кавычки в формате «ГГГГ-ММ-ДД».
Пример:
Предположим, что у нас есть следующий список новых членов библиотеки, которые необходимо добавить в базу данных.
| Полные имена | Дата рождения | пол | Физический адрес | почтовый адрес | Контактный номер | Ваш e-mail |
|---|---|---|---|---|---|---|
| Леонард Хофштадтер | M | Вудкрест | 0845738767 | |||
| Шелдон Купер | M | Вудкрест | 0976736763 | |||
| Раджеш Кутраппали | M | Fairview | 0938867763 | |||
| Лесли Винкль | 14/02/1984 | M | 0987636553 | |||
| Говард Воловиц | 24/08/1981 | M | South Park | Почтовый ящик 4563 | 0987786553 | lwolowitz@email.me |
Давайте вставим данные один за другим. Начнем с Леонарда Хофштадтера. Мы будем рассматривать номер контакта как числовой тип данных и не заключать его в одинарные кавычки.
INSERT INTO `members` (`full_names`,`gender`,`physical_address`,`contact_number`) VALUES ('Leonard Hofstadter','Male','Woodcrest',0845738767);
Выполнение приведенного выше сценария удаляет 0 из контактного номера Леонарда. Это связано с тем, что значение будет рассматриваться как числовое значение, а ноль (0) в начале опускается, поскольку он не имеет значения.
Чтобы избежать таких проблем, значение должно быть заключено в одинарные кавычки, как показано ниже:
INSERT INTO `members` (`full_names`,`gender`,`physical_address`,`contact_number`) VALUES ('Sheldon Cooper','Male','Woodcrest', '0976736763');
В приведенном выше случае ноль (0) не будет отброшен.
Изменение порядка столбцов не влияет на запрос INSERT в MySQL, если правильные значения сопоставлены с правильными столбцами.
Запрос, показанный ниже, демонстрирует вышеизложенное.
INSERT INTO `members` (`contact_number`,`gender`,`full_names`,`physical_address`) VALUES ('0938867763','Male','Rajesh Koothrappali','Woodcrest');
В приведенных выше запросах столбец даты рождения пропущен. По умолчанию MySQL вставит значения NULL в столбцы, которые пропущены в запросе INSERT.
Давайте теперь вставим запись о Лесли, в которой указана дата рождения. Значение даты должно быть заключено в одинарные кавычки в формате «ГГГГ-ММ-ДД».
INSERT INTO `members` (`full_names`,`date_of_birth`,`gender`,`physical_address`,`contact_number`) VALUES ('Leslie Winkle','1984-02-14','Male','Woodcrest', '0987636553');
Все приведенные выше запросы указывали столбцы и сопоставляли их со значениями в операторе вставки MySQL. Если мы предоставляем значения для ВСЕХ столбцов в таблице, то мы можем исключить эти столбцы из запроса на вставку MySQL.
INSERT INTO `members` VALUES (9,'Howard Wolowitz','Male','1981-08-24', 'SouthPark','P.O. Box 4563', '0987786553', 'lwolowitz[at]email.me');
Давайте теперь воспользуемся Оператор SELECT для просмотра всех строк в таблице участника.
SELECT * FROM `members`;
| Количество членов | полные имена | пол | Дата рождения | Физический адрес | почтовый адрес | контактный_ номер | |
|---|---|---|---|---|---|---|---|
| 1 | Джанет Джонс | F | 21-07-1980 | Первая улица, участок № 4 | Частная сумка | 0759 253 542 | janetjones@yagoo.cm |
| 2 | Джанет Смит Джонс | F | 23-06-1980 | Мелроуз 123 | NULL, | NULL, | jj@fstreet.com |
| 3 | Роберт Фил | M | 12-07-1989 | 3-я улица, 34 | NULL, | 12345 | rm@ttreet.com |
| 4 | Глория Уильямс | F | 14-02-1984 | 2-я улица, 23 | NULL, | NULL, | NULL, |
| 5 | Леонард Хофштадтер | M | NULL, | Вудкрест | NULL, | 845738767 | NULL, |
| 6 | Шелдон Купер | M | NULL, | Вудкрест | NULL, | 0976736763 | NULL, |
| 7 | Раджеш Кутраппали | M | NULL, | Вудкрест | NULL, | 0938867763 | NULL, |
| 8 | Лесли Винкль | M | 14-02-1984 | Вудкрест | NULL, | 0987636553 | NULL, |
| 9 | Говард Воловиц | M | 24-08-1981 | Южный парк | Почтовый ящик 4563 | 0987786553 | lwolowitz@email.me |
Обратите внимание, что в контактном номере Леонарда Хофштадтера удален ноль (0). В других контактных номерах в начале не опущен ноль (0).
Вставка в таблицу из другой таблицы
Команда INSERT также может использоваться для вставки данных в таблицу из другой таблицы. Основной синтаксис показан ниже.
INSERT INTO table_1 SELECT * FROM table_2;
Давайте теперь посмотрим на практический пример. Для демонстрационных целей мы создадим фиктивную таблицу категорий фильмов. Мы назовем новую таблицу категорий категории_архив. Сценарий, показанный ниже создает таблицу.
CREATE TABLE `categories_archive` ( `category_id` int(11) AUTO_INCREMENT, `category_name` varchar(150) DEFAULT NULL, `remarks` varchar(500) DEFAULT NULL, PRIMARY KEY (`category_id`))
Выполните приведенный выше сценарий, чтобы создать таблицу.
Давайте теперь вставим все строки из таблицы категорий в таблицу архива категорий. Сценарий, показанный ниже, помогает нам добиться этого.
INSERT INTO `categories_archive` SELECT * FROM `categories`;
Выполнение приведенного выше сценария вставляет все строки из таблицы категорий в таблицу архива категорий. Обратите внимание, что для работы сценария структуры таблиц должны быть одинаковыми. Более надежный сценарий — это сценарий, который сопоставляет имена столбцов в таблице вставки с именами в таблице, содержащей данные.
Запрос, показанный ниже, демонстрирует его использование.
INSERT INTO `categories_archive`(category_id,category_name,remarks) SELECT category_id,category_name,remarks FROM `categories`;
Выполнение запроса SELECT
SELECT * FROM `categories_archive`
дает следующие результаты, показанные ниже.
| ид_категории | category_name | замечания |
|---|---|---|
| 1 | комедия | Фильмы с юмором |
| 2 | Романтический | Любовные истории |
| 3 | Эпический | Сюжетные древние фильмы |
| 4 | Ужас | NULL, |
| 5 | Научная фантастика | NULL, |
| 6 | Триллер | NULL, |
| 7 | Действие | NULL, |
| 8 | Романтическая комедия | NULL, |
| 9 | Мультфильмы | NULL, |
| 10 | Мультфильмы | NULL, |
Пример PHP: вставка в таблицу MySQL
Функция mysqli_query используется для выполнения SQL запросы.
Функция SQL-вставки в таблицу может использоваться для выполнения следующих типов запросов:
- Вставить
- Выберите
- Обновление ПО
- удалять
Он имеет следующий синтаксис.
mysqli_query($db_handle,$query);
«mysqli_query(…)» — это функция, выполняющая SQL-запросы.
«$query» — SQL-запрос, который необходимо выполнить.
«$link_identifier» не является обязательным, его можно использовать для передачи ссылки на подключение к серверу.
Пример
$servername = "localhost"; $username = "alex"; $password = "yPXuPT"; $dbname = "afmznf"; // Create connection $conn = mysqli_connect($servername, $username, $password, $dbname); // Check connection if (!$conn) < die("Connection failed: " . mysqli_connect_error()); >$sql= "INSERT INTO addkeyworddata(link, keyword)VALUES ('https://www.guru99.com/','1000')"; if (mysqli_query($conn, $sql)) < echo "New record created successfully".'
'; > else < echo "Error: " . $sql. "
" . mysqli_error($conn); > >
Итоги
- Команда INSERT используется для добавления новых данных в таблицу. MySql добавит новую строку после выполнения команды.
- Значения даты и строки должны быть заключены в одинарные кавычки.
- Числовые значения не обязательно заключать в кавычки.
- Команда INSERT также может использоваться для вставки данных из одной таблицы в другую.
- Учебное пособие по проектированию базы данных в СУБД: изучение моделирования данных
- Учебное пособие по MySQL Workbench: что такое, как установить и использовать
- Что такое база данных? Определение, значение, типы с примером
- Оператор MySQL SELECT с примерами
- MariaDB против MySQL – разница между ними
Вставка данных в базу данных MySQL
В этом уроке вы узнаете, как вставлять записи в таблицу MySQL с помощью PHP.
Вставка данных в таблицу базы данных MySQL
После создания таблицы, следующим шагом будет ввод данных в таблицу. Чтобы ввести данные в таблицу, мы должны соблюдать определенные правила:
- Если значение, которое нужно вставить, является строкой, мы должны заключить ее в кавычки.
- Числовое значение нельзя заключать в кавычки.
- NULL нельзя заключать в кавычки.
- Если столбец в таблице имеет параметр AUTO_INCREMENT , то нам не нужно вставлять данные в этот столбец, т.к. данные будут вставляются автоматически.
Для вставки новых строк в таблицу базы данных используется оператор INSERT INTO .
INSERT INTO table_name (column1, column2, column3. )
VALUES (value1, value2, value3. )
Давайте сделаем SQL-запрос, используя оператор INSERT INTO с соответствующими значениями, после чего мы передадим его функции PHP mysqli_query() для вставки данных в таблицу.
Следующий пример вставляет новую строку в таблицу persons, указывая значения для полей first_name, last_name и email в трех различных версиях: с использованием синтаксиса объектно-ориентированной процедуры MySQLi, процедурный MySQLi и процедуры PDO.
Пример
Процедурный Объектно-ориентированный PDO
// Попытка выполнения запроса вставки $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('Peter', 'Parker', 'peterparker@mail.com')"; if(mysqli_query($link, $sql)) < echo "Записи успешно вставлены."; >else < echo "ERROR: Не удалось выполнить $sql. " . mysqli_error($link); >// Закрыть соединение mysqli_close($link); ?>connect_error); > // Попытка выполнения запроса вставки $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('Peter', 'Parker', 'peterparker@mail.com')"; if($mysqli->query($sql) === true) < echo "Записи успешно вставлены."; >else< echo "ERROR: Не удалось выполнить $sql. " . $mysqli->error; > // Закрыть соединение $mysqli->close(); ?>setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); > catch(PDOException $e)< die("ОШИБКА: не удалось подключиться. " . $e->getMessage()); > // Попытка выполнения запроса вставки try< $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('Peter', 'Parker', 'peterparker@mail.com')"; $pdo->exec($sql); echo "Записи успешно вставлены."; > catch(PDOException $e)< die("ERROR: Не удалось выполнить $sql. " . $e->getMessage()); > // Закрыть соединение unset($pdo); ?>Примечание: Если столбец — это AUTO_INCREMENT (например, столбец «id»), то его не нужно указывать в запросе SQL. Этот модификатор сообщает MySQL автоматически присвоить значение этому полю.
Вставка нескольких строк в таблицу
Вы также можете вставить сразу несколько строк в таблицу с помощью одного запроса на вставку. Для этого включите в оператор INSERT INTO несколько списков значений столбцов, где значения столбцов для каждой строки должны быть заключены в круглые скобки и разделены запятыми.
В следующем примере вставим еще несколько строк в таблицу persons:
Пример
Процедурный Объектно-ориентированный PDO
// Попытка выполнения запроса вставки $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('John', 'Rambo', 'johnrambo@mail.com'), ('Clark', 'Kent', 'clarkkent@mail.com'), ('John', 'Carter', 'johncarter@mail.com'), ('Harry', 'Potter', 'harrypotter@mail.com')"; if(mysqli_query($link, $sql)) < echo "Записи успешно вставлены."; >else < echo "ERROR: Не удалось выполнить $sql. " . mysqli_error($link); >// Закрыть соединение mysqli_close($link); ?>connect_error); > // Попытка выполнения запроса вставки $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('John', 'Rambo', 'johnrambo@mail.com'), ('Clark', 'Kent', 'clarkkent@mail.com'), ('John', 'Carter', 'johncarter@mail.com'), ('Harry', 'Potter', 'harrypotter@mail.com')"; if($mysqli->query($sql) === true) < echo "Записи успешно вставлены."; >else< echo "ERROR: Не удалось выполнить $sql. " . $mysqli->error; > // Закрыть соединение $mysqli->close(); ?>setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); > catch(PDOException $e)< die("ERROR: Ошибка подключения. " . $e->getMessage()); > // Попытка выполнения запроса вставки try< $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('John', 'Rambo', 'johnrambo@mail.com'), ('Clark', 'Kent', 'clarkkent@mail.com'), ('John', 'Carter', 'johncarter@mail.com'), ('Harry', 'Potter', 'harrypotter@mail.com')"; $pdo->exec($sql); echo "Записи успешно вставлены."; > catch(PDOException $e)< die("ERROR: Не удалось выполнить $sql. " . $e->getMessage()); > // Закрыть соединение unset($pdo); ?>Теперь перейдите в phpMyAdmin и проверьте данные таблицы persons внутри базы данных. Вы обнаружите, что значение столбца id присваивается автоматически путем увеличения значения предыдущего идентификатора на 1.

В MySQL каждая запись представляет собой полный запрос INSERT INTO , разделенный точкой с запятой.
Чтобы облегчить чтение синтаксиса, мы, в отличие от предыдущего примера, разбиваем его на отдельные запросы и добавляем их друг к другу с помощью оператора (.=) :
Пример
$sql = "INSERT INTO Users (name, email) VALUES ('James Bond', 'bond@mail.com');"; $sql .= "INSERT INTO Users (name, email) VALUES ('John Wick', 'wick@mail.com');"; $sql .= "INSERT INTO Users (name, email) VALUES ('Ethan Hunt', 'hunt@mail.com')";
Поскольку точка с запятой является частью SQL-запроса, а не оператором PHP, мы добавляем ее в кавычки запроса.
Вставка данных в БД из HTML-формы
В предыдущем разделе мы узнали, как вставлять данные в базу данных из сценария PHP. Теперь посмотрим, как мы можем вставить данные в базу данных, полученную из HTML-формы. Давайте создадим HTML-форму, которую можно использовать для вставки новых записей в таблицу persons.
Создадим простую HTML-форма с тремя текстовыми полями и кнопкой отправки:
Пример
Add Record Form
Получение и вставка данных формы
Когда пользователь нажимает кнопку отправки HTML-формы, в приведенном выше примере данные формы отправляются в файл-обработчик PHP 'insert.php'. Файл 'insert.php' подключается к серверу базы данных MySQL, извлекает поля форм с использованием переменной PHP $_REQUEST и, наконец, выполняет запрос на вставку записей в БД.
Ниже приведен полный код нашего файла insert.php:
Пример
Процедурный Объектно-ориентированный PDO
// экранирует специальные символы в строке $first_name = mysqli_real_escape_string($link, $_REQUEST['first_name']); $last_name = mysqli_real_escape_string($link, $_REQUEST['last_name']); $email = mysqli_real_escape_string($link, $_REQUEST['email']); // Попытка выполнения запроса вставки $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('$first_name', '$last_name', '$email')"; if(mysqli_query($link, $sql)) < echo "Записи успешно добавлены."; >else < echo "ERROR: Не удалось выполнить $sql. " . mysqli_error($link); >// Закрыть соединение mysqli_close($link); ?>connect_error); > $first_name = $mysqli->real_escape_string($_REQUEST['first_name']); $last_name = $mysqli->real_escape_string($_REQUEST['last_name']); $email = $mysqli->real_escape_string($_REQUEST['email']); // Попытка выполнения запроса вставки $sql = "INSERT INTO persons (first_name, last_name, email) VALUES ('$first_name', '$last_name', '$email')"; if($mysqli->query($sql) === true) < echo "Записи успешно вставлены."; >else< echo "ERROR: Не удалось выполнить $sql. " . $mysqli->error; > // Закрыть соединение $mysqli->close(); ?>setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); > catch(PDOException $e)< die("Ошибка подключения. " . $e->getMessage()); > // Попытка выполнения запроса вставки try< // Создать подготовленную выписку $sql = "INSERT INTO persons (first_name, last_name, email) VALUES (:first_name, :last_name, :email)"; $stmt = $pdo->prepare($sql); // Привязать параметры к оператору $stmt->bindParam(':first_name', $_REQUEST['first_name']); $stmt->bindParam(':last_name', $_REQUEST['last_name']); $stmt->bindParam(':email', $_REQUEST['email']); // Выполнить подготовленный оператор $stmt->execute(); echo "Записи успешно вставлены."; > catch(PDOException $e)< die("Ошибка вставки $sql. " . $e->getMessage()); > // Закрыть соединение unset($pdo); ?>Примечание: Функция mysqli_real_escape_string() экранирует специальные символы в строке и создает допустимую строку SQL для защиты от атаки, при которой злоумышленник может внедрить или выполнить вредоносный код SQL.
Это простой пример вставки данных формы в таблицу базы данных MySQL. Вы можете расширить этот пример и сделать его более интерактивным, добавив проверки для пользовательского ввода перед вставкой его в таблицы базы данных. Ознакомьтесь с руководством по проверке форм PHP, чтобы узнать больше о валидации и проверке вводимых пользователем данных с помощью PHP.