Произвольный ключ партиционирования
Партиционирование данных доступно для таблиц семейства MergeTree (включая реплицированные таблицы). Таблицы MaterializedView, созданные на основе таблиц MergeTree, также поддерживают партиционирование.
Партиция – это набор записей в таблице, объединенных по какому-либо критерию. Например, партиция может быть по месяцу, по дню или по типу события. Данные для разных партиций хранятся отдельно. Это позволяет оптимизировать работу с данными, так как при обработке запросов будет использоваться только необходимое подмножество из всевозможных данных. Например, при получении данных за определенный месяц, ClickHouse будет считывать данные только за этот месяц.
Ключ партиционирования задается при создании таблицы, в секции PARTITION BY expr . Ключ может представлять собой произвольное выражение из столбцов таблицы. Например, чтобы задать партиционирования по месяцам, можно использовать выражение toYYYYMM(date_column) :
CREATE TABLE visits ( VisitDate Date, Hour UInt8, ClientID UUID ) ENGINE = MergeTree() PARTITION BY toYYYYMM(VisitDate) ORDER BY Hour Ключом партиционирования также может быть кортеж из выражений (аналогично первичному ключу). Например:
ENGINE = ReplicatedCollapsingMergeTree('/clickhouse/tables/name', 'replica1', Sign) PARTITION BY (toMonday(StartDate), EventType) ORDER BY (CounterID, StartDate, intHash32(UserID)); В этом примере задано партиционирование по типам событий, произошедших в течение текущей недели.
По умолчанию, ключ партиционирования с плавающей запятой не поддерживается. Чтобы использовать его, включите настройку allow_floating_point_partition_key.
Каждая партиция состоит из отдельных фрагментов или так называемых кусков данных. Каждый кусок отсортирован по первичному ключу. При вставке данных в таблицу каждая отдельная запись сохраняется в виде отдельного куска. Через некоторое время после вставки (обычно до 10 минут), ClickHouse выполняет в фоновом режиме слияние данных — в результате куски для одной и той же партиции будут объединены в более крупный кусок.
Примечание
Не рекомендуется делать слишком гранулированное партиционирование – то есть задавать партиции по столбцу, в котором будет слишком большой разброс значений (речь идет о порядке более тысячи партиций). Это приведет к скоплению большого числа файлов и файловых дескрипторов в системе, что может значительно снизить производительность запросов SELECT .
Чтобы получить набор кусков и партиций таблицы, можно воспользоваться системной таблицей system.parts. В качестве примера рассмотрим таблицу visits , в которой задано партиционирование по месяцам. Выполним SELECT для таблицы system.parts :
SELECT partition, name, active FROM system.parts WHERE table = 'visits' ┌─partition─┬─name──────────────┬─active─┐ │ 201901 │ 201901_1_3_1 │ 0 │ │ 201901 │ 201901_1_9_2_11 │ 1 │ │ 201901 │ 201901_8_8_0 │ 0 │ │ 201901 │ 201901_9_9_0 │ 0 │ │ 201902 │ 201902_4_6_1_11 │ 1 │ │ 201902 │ 201902_10_10_0_11 │ 1 │ │ 201902 │ 201902_11_11_0_11 │ 1 │ └───────────┴───────────────────┴────────┘ Столбец partition содержит имена всех партиций таблицы. Таблица visits из нашего примера содержит две партиции: 201901 и 201902 . Используйте значения из этого столбца в запросах ALTER … PARTITION.
Столбец name содержит названия кусков партиций. Значения из этого столбца можно использовать в запросах ALTER ATTACH PART.
Столбец active отображает состояние куска. 1 означает, что кусок активен; 0 – неактивен. К неактивным можно отнести куски, оставшиеся после слияния данных. Поврежденные куски также отображаются как неактивные. Неактивные куски удаляются приблизительно через 10 минут после того, как было выполнено слияние.
Рассмотрим детальнее имя куска 201901_1_9_2_11 :
- 201901 имя партиции;
- 1 – минимальный номер блока данных;
- 9 – максимальный номер блока данных;
- 2 – уровень куска (глубина дерева слияний, которыми этот кусок образован).
- 11 — версия мутации (если парт мутировал)
Примечание
Названия кусков для таблиц старого типа образуются следующим образом: 20190117_20190123_2_2_0 (минимальная дата максимальная дата номер минимального блока номер максимального блока уровень).
Как видно из примера выше, таблица содержит несколько отдельных кусков для одной и той же партиции (например, куски 201901_1_3_1 и 201901_1_9_2 принадлежат партиции 201901 ). Это означает, что эти куски еще не были объединены – в файловой системе они хранятся отдельно. После того как будет выполнено автоматическое слияние данных (выполняется примерно спустя 10 минут после вставки данных), исходные куски будут объединены в один более крупный кусок и помечены как неактивные.
Вы можете запустить внеочередное слияние данных с помощью запроса OPTIMIZE. Пример:
OPTIMIZE TABLE visits PARTITION 201902; ┌─partition─┬─name─────────────┬─active─┐ │ 201901 │ 201901_1_3_1 │ 0 │ │ 201901 │ 201901_1_9_2_11 │ 1 │ │ 201901 │ 201901_8_8_0 │ 0 │ │ 201901 │ 201901_9_9_0 │ 0 │ │ 201902 │ 201902_4_6_1 │ 0 │ │ 201902 │ 201902_4_11_2_11 │ 1 │ │ 201902 │ 201902_10_10_0 │ 0 │ │ 201902 │ 201902_11_11_0 │ 0 │ └───────────┴──────────────────┴────────┘ Неактивные куски будут удалены примерно через 10 минут после слияния.
/var/lib/clickhouse/data/default/visits$ ls -l total 40 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 1 16:48 201901_1_3_1 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 5 16:17 201901_1_9_2_11 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 5 15:52 201901_8_8_0 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 5 15:52 201901_9_9_0 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 5 16:17 201902_10_10_0 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 5 16:17 201902_11_11_0 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 5 16:19 201902_4_11_2_11 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 5 12:09 201902_4_6_1 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 1 16:48 detached ‘201901_1_1_0’, ‘201901_1_7_1’ и т. д. – это директории кусков партиции. Каждый кусок содержит данные только для соответствующего месяца (таблица в данном примере содержит партиционирование по месяцам).
Директория detached содержит куски, отсоединенные от таблицы с помощью запроса DETACH. Поврежденные куски также попадают в эту директорию – они не удаляются с сервера.
Сервер не использует куски из директории detached . Вы можете в любое время добавлять, удалять, модифицировать данные в директории detached — сервер не будет об этом знать, пока вы не сделаете запрос ATTACH.
Следует иметь в виду, что при работающем сервере нельзя вручную изменять набор кусков на файловой системе, так как сервер не будет знать об этом. Для нереплицируемых таблиц, вы можете это делать при остановленном сервере, однако это не рекомендуется. Для реплицируемых таблиц, набор кусков нельзя менять в любом случае.
ClickHouse позволяет производить различные манипуляции с кусками: удалять, копировать из одной таблицы в другую или создавать их резервные копии. Подробнее см. в разделе Манипуляции с партициями и кусками.
Секционированные таблицы и индексы
SQL Server, База данных SQL Azure и Управляемый экземпляр SQL Azure поддерживают секционирование таблиц и индексов. Данные секционированных таблиц и индексов делятся на единицы, которые могут распространяться между несколькими файловыми группами в базе данных или хранятся в одной файловой группе. При наличии нескольких файлов в файловой группе данные распределяются по файлам с помощью алгоритма пропорциональной заливки. Данные секционируются горизонтально, поэтому группы строк сопоставляются с отдельными секциями. Все секции одного индекса или таблицы должны находиться в одной и той же базе данных. Таблица или индекс рассматриваются как единая логическая сущность при выполнении над данными запросов или обновлений.
До SQL Server 2016 (13.x) с пакетом обновления 1 (SP1) секционированные таблицы и индексы не были доступны в каждом выпуске SQL Server. Список функций, поддерживаемых выпусками SQL Server, см. в выпусках и поддерживаемых функциях SQL Server 2022. Секционированные таблицы и индексы доступны во всех уровнях служб База данных SQL Azure и Управляемый экземпляр SQL Azure.
Секционирование таблиц также доступно в выделенных пулах SQL в Azure Synapse Analytics с некоторыми различиями синтаксиса. Дополнительные сведения о секционированиях таблиц в выделенном пуле SQL.
Ядро СУБД поддерживает до 15 000 секций по умолчанию. В версиях, предшествующих SQL Server 2012 (11.x), число секций по умолчанию ограничено 1000.
Преимущества секционирования
Секционирование больших таблиц или индексов может дать следующие преимущества в управляемости и производительности.
- Это позволяет быстро и эффективно переносить подмножества данных и обращаться к ним, сохраняя при этом целостность набора данных. Например, операция, например загрузка данных из OLTP в систему OLAP, занимает только секунды, а не в минутах и часах, когда данные не секционируются.
- Вы можете выполнять операции обслуживания или хранения данных на одном или нескольких секциях быстрее. Операции более эффективны, так как выполняются только с поднаборами данных, а не со всей таблицей. Например, можно сжать данные в одной или нескольких секциях, перестроить одну или несколько секций индекса или усечь данные в одной секции. Вы также можете переключать отдельные секции из одной таблицы и в архивную таблицу.
- Вы можете повысить производительность запросов на основе типов часто выполняемых запросов. Например, оптимизатор запросов может обрабатывать запросы на эквивалентность между двумя или более секционированных таблицами быстрее, когда столбцы секционирования совпадают с столбцами, на которых объединяются таблицы. См. подробнее о запросах.
Вы можете повысить производительность, включив эскалацию блокировки на уровне секции вместо всей таблицы. Это может уменьшить количество конфликтов блокировок для таблицы. Чтобы снизить состязание блокировок с помощью применения укрупнения блокировок к секциям, задайте для параметра LOCK_ESCALATION инструкции ALTER TABLE значение AUTO.
Компоненты и основные понятия
Следующие термины относятся к секционированию таблиц и индексов.
Функция секционирования
Функция секционирования — это объект базы данных, определяющий, как строки таблицы или индекса сопоставляются с набором секций на основе значений определенного столбца, называемого столбцом секционирования. Каждое значение в столбце секционирования является входными данными для функции секционирования, которая возвращает значение секции.
Функция секционирования определяет количество и границы секций, которые будут содержаться в таблице. Например, учитывая таблицу, содержащую данные заказа на продажу, может потребоваться разделить таблицу на 12 (ежемесячно) секций на основе столбца datetime , например даты продажи.
Тип диапазона (LEFT или RIGHT) указывает, как значения границ функции секционирования будут помещены в результирующий раздел:
- Диапазон LEFT указывает, что значение границы принадлежит левой части интервала границы, когда значения интервалов сортируются ядром СУБД в порядке возрастания слева направо. Другими словами, максимальное ограничивающее значение будет включено в секцию.
- Диапазон RIGHT указывает, что значение границы принадлежит правой части интервала границы, когда значения интервалов сортируются ядром СУБД в порядке возрастания слева направо. Другими словами, наименьшее ограничивающее значение будет включено в каждую секцию.
Если параметр LEFT или RIGHT не указан, диапазон LEFT является значением по умолчанию.
Например, следующая функция секционирования секционирует таблицу или индекс на 12 секций, по одному для каждого месяца годовых значений в столбце datetime . Используется диапазон RIGHT, указывающий, что значения границ будут служить нижними ограничивающими значениями в каждой секции. Диапазоны RIGHT часто проще работать при секционирования таблицы на основе столбца типов данных datetime или datetime2, так как строки со значением полуночи будут храниться в той же секции, что и строки с последующими значениями в тот же день. Аналогичным образом, если используется тип данных даты и использование секций месяца или более, диапазон RIGHT сохраняет первый день месяца в той же секции, что и более поздние дни в этом месяце. Это помогает точно устранить секции при запросе данных всего дня.
CREATE PARTITION FUNCTION [myDateRangePF1] (datetime) AS RANGE RIGHT FOR VALUES ('2022-02-01', '2022-03-01', '2022-04-01', '2022-05-01', '2022-06-01', '2022-07-01', '2022-08-01', '2022-09-01', '2022-10-01', '2022-11-01', '2022-12-01'); В следующей таблице показано, как будет разбита таблица или индекс, использующие эту функцию секционирования для столбца секционирования datecol. 1 февраля является первой точкой границы, определенной в функции, поэтому она выступает в качестве нижней границы секции 2.
| Секция | 1 | 2 | . | 11 | 12 |
|---|---|---|---|---|---|
| Значения | datecol < 2022-02-01 12:00AM | datecol>= 2022-02-01 12:00AM AND datecol < 2022-03-01 12:00AM | datecol>= 2022-11-01 12:00AM AND col1 < 2022-12-01 12:00AM | datecol>= 2022-12-01 12:00AM |
Для параметра RANGE LEFT и RANGE RIGHT самый левый раздел имеет минимальное значение типа данных в качестве нижнего предела, а самый правый раздел имеет максимальное значение типа данных в качестве верхнего предела.
Дополнительные примеры функций секционирования LEFT и RIGHT см. в разделе CREATE PARTITION FUNCTION (Transact-SQL).
Схема секционирования
Схема секционирования — это объект базы данных, который сопоставляет секции функции секции с одной файловой группой или несколькими файловыми группами.
Найдите пример синтаксиса для создания схем секционирования в CREATE PARTITION SCHEME (Transact-SQL).
Файловые группы
Главная причина, по которой секции разделяются по нескольким файловым группам, заключается в возможности независимого выполнения операций резервного копирования и восстановления в секции. поскольку оно всегда выполняется отдельно для каждой из файловых групп. При использовании многоуровневого хранилища использование нескольких файловых групп позволяет назначать определенные секции определенным уровням хранилища, например размещать старые и менее часто доступные секции на более медленном и менее дорогом хранилище. Все прочие преимущества секционирования применяются независимо от количества используемых файловых групп или размещения секций в определенных файловых группах.
Управление файлами и файловыми группами для секционированных таблиц может значительно усложнить административные задачи с течением времени. Если процедуры резервного копирования и восстановления не используют несколько файловых групп, рекомендуется использовать одну файловую группу для всех разделов. Те же правила проектирования файлов и файловых групп применяются к секционированным объектам, которые применяются к несекционированным объектам.
Секционирование полностью поддерживается в База данных SQL Azure. Так как в База данных SQL Azure поддерживается только файловая PRIMARY группа, все секции должны размещаться в файловой PRIMARY группе.
Найдите пример кода для создания файловых групп для SQL Server и Управляемый экземпляр SQL Azure в файлах ALTER DATABASE (Transact-SQL) и параметрах файловой группы.
Столбец секционирования
Столбец таблицы или индекса, используемый функцией секционирования для секционирования таблицы или индекса. При выборе столбца секционирования применяются следующие рекомендации.
- Вычисляемые столбцы, участвующие в функции секционирования, должны быть явно созданы как PERSISTED.
- Так как в качестве столбца секции можно использовать только один столбец, в некоторых случаях объединение нескольких столбцов с вычисляемого столбца может оказаться полезным.
Чтобы секционировать объект, укажите схему секционирования и столбец секционирования в инструкциях CREATE TABLE (Transact-SQL), ALTER TABLE (Transact-SQL) и CREATE INDEX (Transact-SQL).
При создании некластеризованного индекса, если partition_scheme_name или файловая группа не указана и таблица секционирована, индекс помещается в ту же схему секционирования, используя тот же столбец секционирования, что и базовая таблица. Чтобы изменить секционирование существующего индекса, используйте CREATE INDEX с предложением DROP_EXISTING. Это позволяет секционировать несекционированные индексы, создавать секционированные индексы без секционирования или изменять схему секционирования индекса.
Выровненный индекс
Индекс, созданный на основе той же схемы секционирования, что и соответствующая таблица. Если таблица и его индексы находятся в выравнивании, ядро СУБД может переключать секции в таблицу или из нее быстро и эффективно, сохраняя структуру секций как таблицы, так и ее индексов. Индекс не должен участвовать в той же именованной функции секционирования, чтобы быть выровненной с базовой таблицей. Тем не менее функции секционирования индекса и базовой таблицы не должны существенно различаться, то есть:
- аргументы функции секционирования должны иметь один и тот же тип данных;
- функции должны определять одинаковое количество секций;
- функции должны определять для секций одинаковые граничные значения.
Секционирование кластеризованных индексов
При секционировании кластеризованного индекса столбец секционирования должен содержаться в ключе кластеризации. При секционировании неуникационного кластеризованного индекса и столбца секционирования в ключе кластеризация ядро СУБД добавляет столбец секционирования по умолчанию в список кластеризованных ключей индекса. Если кластеризованный индекс является уникальным, для него следует явным образом задать наличие столбца секционирования в ключе кластеризованного индекса. Дополнительные сведения о кластеризованных индексах и архитектуре индексов см. в разделе Правила проектирования кластеризованного индекса.
Секционирование некластеризованных индексов
При секционировании уникального некластеризованного индекса столбец секционирования должен содержаться в ключе индекса. При секционировании некластеризованного индекса ядро СУБД добавляет столбец секционирования по умолчанию в качестве неключевого (включенного) столбца индекса, чтобы убедиться, что индекс соответствует базовой таблице. Ядро СУБД не добавляет столбец секционирования в индекс, если он уже присутствует в индексе. Дополнительные сведения о некластеризованных индексах и архитектуре индексов см. в разделе Рекомендации по созданию некластеризованных индексов.
Невыровненный индекс
Неровный индекс секционирован по-разному от соответствующей таблицы. То есть индекс имеет другую схему секционирования, которая помещает ее в отдельную файловую группу или набор файловых групп из базовой таблицы. Создание невыровненного секционированного индекса может быть полезно в следующих случаях:
- Базовая таблица не секционирована.
- Ключ индекса является уникальным и не содержит столбец секционирования таблицы.
- Требуется участие базовой таблицы в выровненных соединениях с таблицами, использующими другие столбцы соединения.
Устранение секций
Процесс, в ходе которого оптимизатор запросов обращается только к определенным секциям в соответствии с фильтром запроса.
Дополнительные сведения об устранении секций и связанных понятиях в улучшениях обработки запросов в секционированных таблицах и индексах.
Ограничения
- Область действия функции и схемы секционирования ограничена базой данных, в которой она была создана. Функции секционирования располагаются в отдельном от других функций пространстве имен внутри базы данных.
- Если в секционированных таблицах есть NULLs в столбце секционирования, эти строки помещаются в левую часть секции. Однако если значение NULL указано в качестве первого значения границы и RANGE RIGHT указывается в определении функции секции, то левая часть секции остается пустой, а NULLs помещаются во вторую секцию.
Рекомендации по повышению производительности
Ядро СУБД поддерживает до 15 000 секций на таблицу или индекс. Однако использование более 1000 секций влияет на память, секционированные операции индексов, команды DBCC и запросы. В этом разделе описываются последствия использования более 1000 секций и предоставляются обходные пути при необходимости.
Если на секционированную таблицу или индекс разрешено до 15 000 секций, данные можно хранить в одной таблице в течение длительного времени. Однако данные следует хранить только до тех пор, пока они необходимы и поддерживают баланс между производительностью и количеством секций.
Использование памяти и рекомендации
При большом количестве используемых секций рекомендуется использовать ОЗУ не менее 16 ГБ. Если в системе недостаточно памяти, операторы языка обработки данных (DML), инструкции языка определения данных (DDL) и другие операции могут завершиться ошибкой из-за нехватки памяти. В системах с ОЗУ 16 ГБ и большим количеством процессов, интенсивно использующих память, возможны сбои операций, работающих на большом количестве секций, из-за нехватки памяти. Таким образом, чем больше памяти у вас более 16 ГБ, тем меньше вероятность возникновения проблем с производительностью и памятью.
Ограничения памяти могут повлиять на производительность или способность ядра СУБД создавать секционированные индексы. Это особенно происходит, если индекс не соответствует базовой таблице или не соответствует кластеризованному индексу, если таблица уже имеет кластеризованный индекс.
В SQL Server и Управляемый экземпляр SQL Azure можно увеличить index create memory (KB) параметр конфигурации сервера. Дополнительные сведения см. в разделе «Настройка параметра конфигурации сервера памяти». Для База данных SQL Azure рассмотрите возможность временного или постоянного увеличения цели уровня обслуживания для базы данных в портал Azure, чтобы выделить больше памяти.
Операции секционированного индекса
Создание и перестроение несоотрованных индексов в таблице с более чем 1000 секциями возможно, но не поддерживается. Это может привести к снижению производительности или чрезмерному потреблению памяти во время таких операций.
Создание и перестроение выровненных индексов может занять больше времени для выполнения по мере увеличения числа секций. Рекомендуется не запускать несколько команд создания и перестроения индексов одновременно, так как могут возникнуть проблемы с производительностью и памятью.
Когда ядро СУБД выполняет сортировку для создания секционированных индексов, сначала создается одна таблица сортировки для каждой секции. Затем либо в соответствующей файловой группе каждой секции, либо в tempdb, если задан параметр индекса SORT_IN_TEMPDB, производится построение таблиц сортировки. Для всех таблиц сортировки требуется минимальный объем оперативной памяти. При создании секционированного индекса, выравниваемого с базовой таблицей, таблицы сортировки создаются по одному за раз, используя меньше памяти. Однако при создании неупорядоченного секционированного индекса таблицы сортировки создаются одновременно. В результате необходим достаточный объем оперативной памяти, чтобы параллельно их обрабатывать. Чем больше число секций, тем больше требуется оперативной памяти. Для каждой из секций размер таблицы сортировки составляет не менее 40 страниц, по 8 килобайт каждая. Например, для невыровненного секционированного индекса, разбитого на 100 секций, потребуется объем оперативной памяти для одновременной сортировки 4 000 страниц (40*100). Если такой объем памяти доступен, операция создания будет выполнена успешно, но может пострадать производительность. Если эта память недоступна, операция сборки завершится ошибкой. Кроме того, для выравнивания секционированного индекса с 100 секциями требуется только достаточно памяти для сортировки 40 страниц, так как сортировки не выполняются одновременно.
Если ядро СУБД использует параллелизм запросов к операции сборки на многопроцессорном компьютере, требования к памяти могут быть больше. Это связано с тем, что чем больше степень параллелизма (DOP), тем больше требуется память. Например, если ядро СУБД задает doP 4, неупорядоченный секционированный индекс с 100 секциями требует достаточно памяти для четырех процессоров для сортировки 4000 страниц одновременно или 16 000 страниц. Если секционированный индекс выровнен, требования оперативной памяти снижаются до 40 страниц для каждого из четырех процессоров, то есть 160 страниц (4*40). Параметр индекса MAXDOP можно использовать для ручного уменьшения степени параллелизма.
Команды DBCC
С большим количеством секций команды DBCC, такие как DBCC CHECKDB и DBCC CHECKTABLE , могут занять больше времени, чтобы выполнить по мере увеличения числа секций.
Запросы
После секционирования таблицы или индекса запросы, использующие исключение секций, могут иметь сравнимую или улучшенную производительность с большим количеством секций. Запросы, которые не используют ликвидацию секций, могут занять больше времени для выполнения по мере увеличения количества секций.
Предположим, таблица имеет 100 миллионов строк и столбцов A , B и C .
- В сценарии 1 таблица делится на 1000 секций в столбце A .
- В примере 2 таблица делится на 10,000 секций по столбцу A .
Запрос к таблице, включающий предложение WHERE с фильтром по столбцу A , выполнит функцию устранения секций и просканирует одну секцию. Тот же самый запрос может быть выполнен быстрее в примере 2, так как в секции меньше строк для сканирования. Запрос, включающий предложение WHERE с фильтром по столбцу B, будет сканировать все секции. В примере 1 этот запрос может быть выполнен быстрее, чем в примере 2, так как в этом случае меньше секций для сканирования.
Запросы, в которых используются такие операторы, как TOP или MAX/MIN, в столбцах, отличных от столбца секционирования, могут столкнуться со снижением производительности при секционировании, поскольку вычисляться должны все секции.
Аналогичным образом запрос, выполняющий поиск по одной строке или небольшое сканирование диапазона, займет больше времени в секционируемой таблице, чем в несекреченной таблице, если предикат запроса не включает столбец секционирования, так как он должен выполнять столько запросов или проверок, сколько секций. По этой причине секционирование редко повышает производительность в системах OLTP, где такие запросы являются общими.
Если часто выполняются запросы, связанные с сопоставлением между двумя или несколькими секционированных таблицами, их столбцы секционирования должны совпадать со столбцами, на которых объединяются таблицы. Дополнительно: таблицы или их индексы должны быть упорядочены. Это означает, что они либо используют ту же именованную функцию секционирования, либо используют разные функции секционирования, которые по сути одинаковы, в том, что они:
- Указанные таблицы секционированы по одинаковому количеству параметров, имеющих одинаковый тип данных.
- В указанных таблицах имеется одинаковое количество секций.
- В указанных таблицах секции имеют одинаковые граничные значения.
При выполнении указанных условий оптимизатор запросов проводит операцию соединения гораздо быстрее, так как в этом случае могут быть соединены сами секции. Если запрос присоединяется к двум таблицам, которые не объединяются или не секционируются в поле соединения, наличие секций может на самом деле замедлить обработку запросов, а не ускорить ее.
В некоторых запросах может быть полезно использовать $PARTITION . Дополнительные сведения см. в $PARTITION (Transact-SQL).
Дополнительные сведения об обработке секций в обработке запросов, включая стратегию параллельного выполнения запросов для секционированных таблиц и индексов и дополнительных рекомендаций, см. в разделе «Усовершенствования обработки запросов» для секционированных таблиц и индексов.
Изменения в поведении при статистических вычислениях во время операций с секционированным индексом
В База данных SQL Azure Управляемый экземпляр SQL Azure и SQL Server 2012 (11.x) и более поздних версий статистика не создается путем сканирования всех строк в таблице при создании или перестроении секционированного индекса. Вместо этого оптимизатор запросов использует для создания статистики алгоритм выборки по умолчанию.
После обновления базы данных с секционированных индексов из версии SQL Server ниже 2012 (11.x) вы можете заметить разницу в данных гистограммы для этих индексов. Это изменение в поведении может повлиять на производительность запросов. Для получения статистики по секционированным индексам путем сканирования всех строк таблицы используйте инструкции CREATE STATISTICS или UPDATE STATISTICS с предложением FULLSCAN .
Связанный контент
Дополнительные сведения о секционированных таблицах и стратегиях индексов см. в следующих статьях:
- Создание секционированных таблиц и индексов
- $PARTITION (Transact-SQL)
- Развертывание с помощью Базы данных SQL Azure
- Секционирование таблиц в выделенном пуле SQL
- Руководство по архитектуре и разработке индексов SQL Server и Azure SQ
- Partitioned Table and Index Strategies Using SQL Server 2008
- How to Implement an Automatic Sliding Window in a Partitioned Table on SQL Server 2005
- Массовая загрузка в секционированную таблицу
- Улучшенные возможности обработки запросов для секционированных таблиц и индексов
- Лучшие 10 рекомендаций по созданию хранилища реляционных данных большого масштаба в руководстве ПО SQLCAT: реляционная инженерия
Партицирование баз данных
Партицирование, или секционирование, базы данных — разделение данных, хранящихся в базе данных, на части. Партицирование позволяет осуществлять горизонтальное масштабирование, так как вертикальное масштабирование имеет потолок — нельзя бесконечно долго добавлять память на один сервер. При разделении же данных на части их можно хранить на разных серверах, а серверы добавлять по мере необходимости. Доступность и производительность повышаются, так как запросы обращаются не к огромному куску данных, а к более маленьким и легковесным частям.
Управление ИТ услугами
- горизонтальное партицирование — таблица данных разбивается на строки;
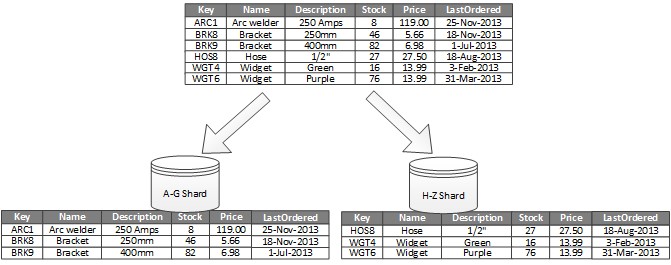
- вертикальное партицирование — таблица данных разбивается на столбцы;
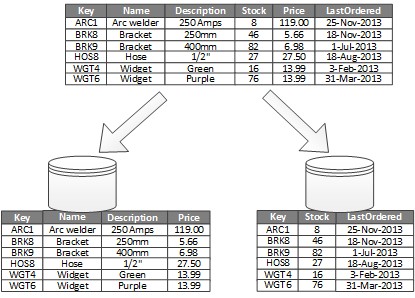
- функциональное партицирование — данные группируются согласно контексту их использования в системе.
SQL Partition overview

In SQL Server there are several kinds of SQL partitions. However, in general, we can say that a partition is a way to divide a table (sometimes a view) into smaller pieces for performance purposes. In this article, we will explain what partition does mean for a table partition and SSAS. We will also provide some guidance to automate the partition process.
What does SQL partition mean?
Let’s start with the Table partition. If we have a big table with TB or GB of information, a select to search a single row may take forever to be executed. To solve the problem, a classic partition is to split the table into smaller pieces divided by month for example. You can partition by month, day, year. It depends on your needs. It is like a thick book. Searching a single page for something will take too much time. Even with indexes. However, if we divide the book into smaller books, it will be faster and easier to search for a page. It will be faster to backup and recover the data. Let’s start with table partitions scenarios and then we will talk about other types of partitions.
What does SQL partition mean in a table?
Table partition means to split the data across multiple tables to get better performance when the tables handle a considerable amount of data. There are 2 main types of partitions in a table. Horizontal partition and vertical partition. In a vertical partition, you could, for example, split the data into 2 tables:
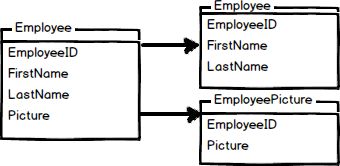 In the previous image, we split the Employee table into 2 tables. The Employee table contains the first name and last name and the other table is EmployeePicture. The images take a lot of resources, so it is a good idea to handle the data separately. It is a good practice to store the images in a separated Filegroup and hard disk. On the other hand, we have the Horizontal partitioning
In the previous image, we split the Employee table into 2 tables. The Employee table contains the first name and last name and the other table is EmployeePicture. The images take a lot of resources, so it is a good idea to handle the data separately. It is a good practice to store the images in a separated Filegroup and hard disk. On the other hand, we have the Horizontal partitioning 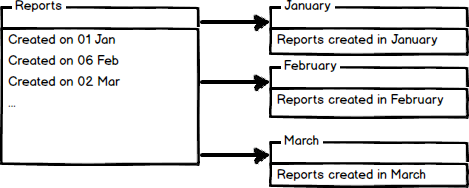 In horizontal partitioning, we divide a big table into smaller tables. The image above shows a partition of a report in tables per month. For more detailed information about table partitioning and how to do it step by step, refer to our article related:
In horizontal partitioning, we divide a big table into smaller tables. The image above shows a partition of a report in tables per month. For more detailed information about table partitioning and how to do it step by step, refer to our article related: - Database table partitioning in SQL Server
What does partition mean for automation?
We explained this before and provide a link to create horizontal partitions. We can automate the table partition process using scripts and monitor the partitions missed using T-SQL queries. To monitor partitions, you can use system tables like the following:
- Sys.indexes
- Sys.objects
- Sys.system_internals_allocation_units
- Sys.partition_schemes
- Sys.partition_functions
- Sys.partition_range_values
The following link provides a tutorial to maintain automatically your partitions.
What does SQL partition mean in SSAS Azure Tabular?
Previously, we talked about the Table partitions used in the SQL Server Database Engine. We worked with the famous and traditional OLTP Databases (Online Transactional Processes). Transactional databases are traditional databases to insert, update, delete data in transactions.
SQL Server included the OLAP databases later as a new concept of database to handle reports with a lot of data. The traditional OLTP databases are pretty slow to generate reports when several joins are required and several GB are used in the database. That is why Microsoft created the OLAP databases (Online Analytical Process) by buying the OLAP technology from Panorama Software from Canada first and then Microsoft improved the technology.
Microsoft created the SSAS (SQL Server Analysis Services) which was the technology used to create OLAP databases. Microsoft started with the Multidimensional Databases. This technology is very powerful, but a little difficult to understand for OLTP DBAs or Developers because it handles different architecture, structures, and components.
To simplify the process to create reports, Microsoft introduced a new feature named Tabular Models. Which is a technology easier to understand and to create reports and queries. To create a new Multidimensional database from scratch, refer to the following link:
If you want to create a tabular database, refer to the following link:
These technologies started being On-premises technologies. However, Microsoft is moving all the efforts in the Cloud.
Now, these technologies are in Azure, then, the SQL partitions for the Tabular and Multidimensional databases are in Azure.
When you use SSDT, creating columns, DAX (Data Analysis Expressions) queries, MDX (Multi-Dimensional Expressions) queries, XMLA (XML for Analysis), and TMLS (Tabular Model Scripting Language) it is transparent if the model is On-premises or in Azure.
In this article, we will explain what partition does mean in Azure Tabular Models. However, the concept is the same for Tabular Models On-Premises.
In a Tabular Model, what does a partition mean?
We can say that it is the same concept to divide the table into smaller pieces using queries. A partition in a Tabular Model is Part of a Table divided into smaller pieces using a query.
In this example, we will show how to do it. I am assuming that you already have a Tabular Instance installed and that you are using the AdventureWorks Tabular Project (take a look at the Implementing an SSAS Tabular Model article if not).
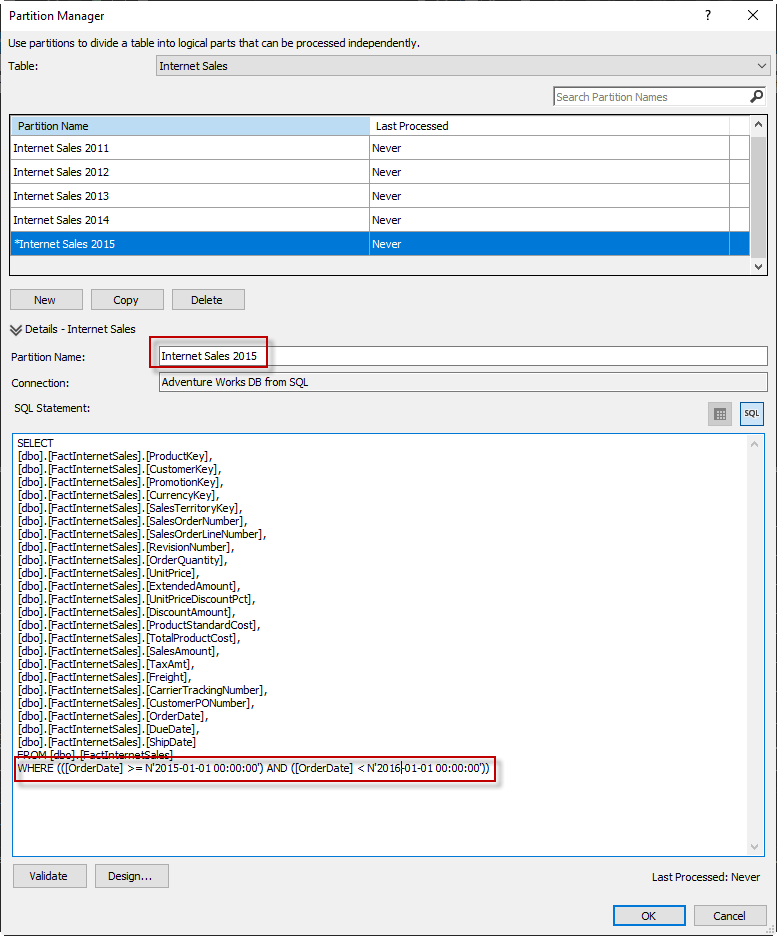
In the Adventureworks Tabular project, select the Internet Sales table.
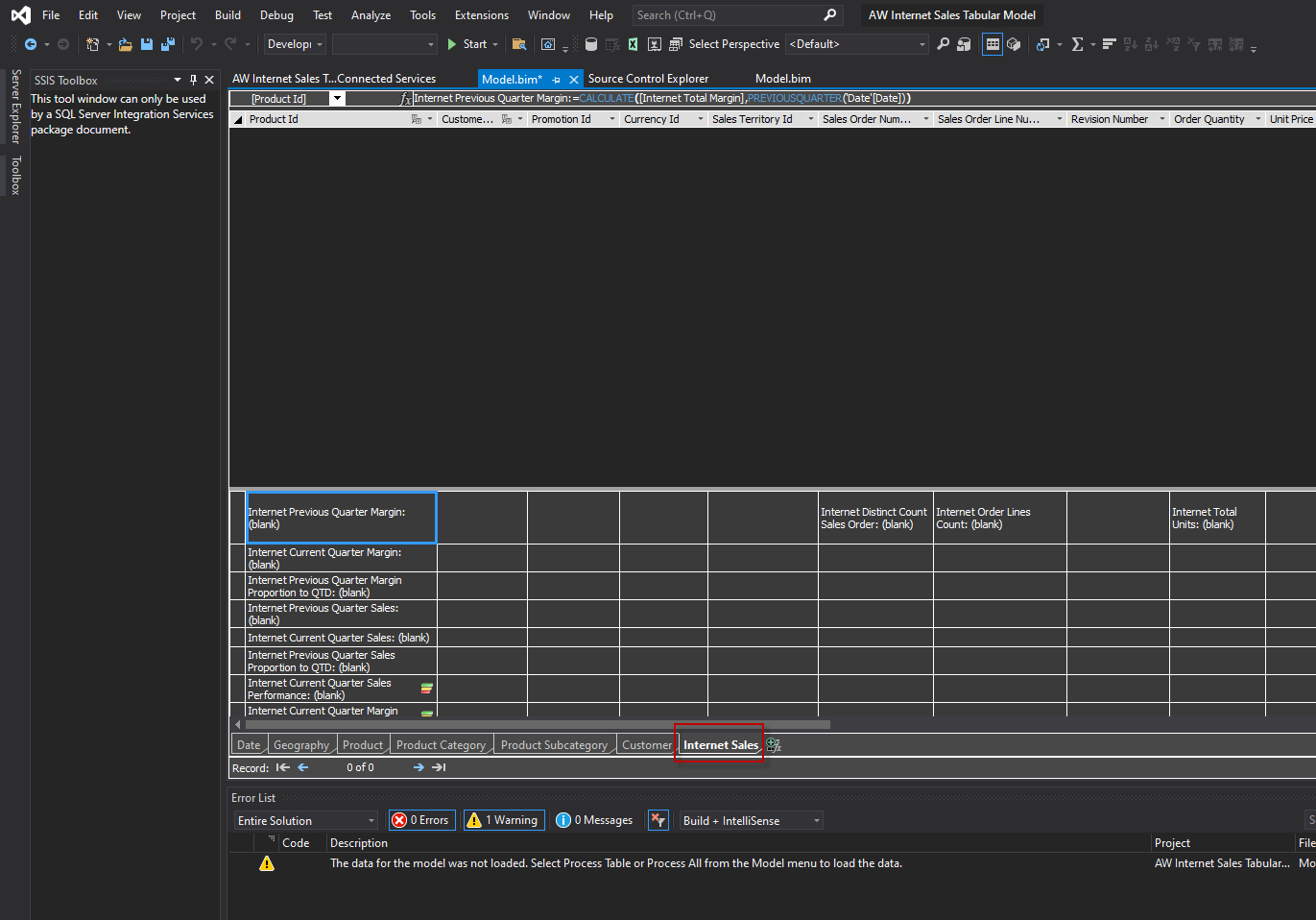
In the Menu, go to Extensions>Table>Partitions.
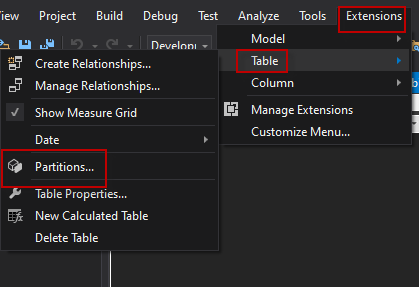
You will see the different partitions for Internet Sales. The partition in this example is per year.
Internet sales 2010, 2011. 2014.
The main difference between partitions is in the where clause. The range of dates of each partition is different. For example, for the Internet Sales 2011 partition the where clause is the following:
WHERE (([OrderDate] >= N’2011-01-01 00:00:00′) AND ([OrderDate] < N’2012-01-01 00:00:00′))
On the other hand, for the Internet Sales 2012 is the following:
WHERE (([OrderDate] >= N’2012-01-01 00:00:00′) AND ([OrderDate] < N’2013-01-01 00:00:00′))
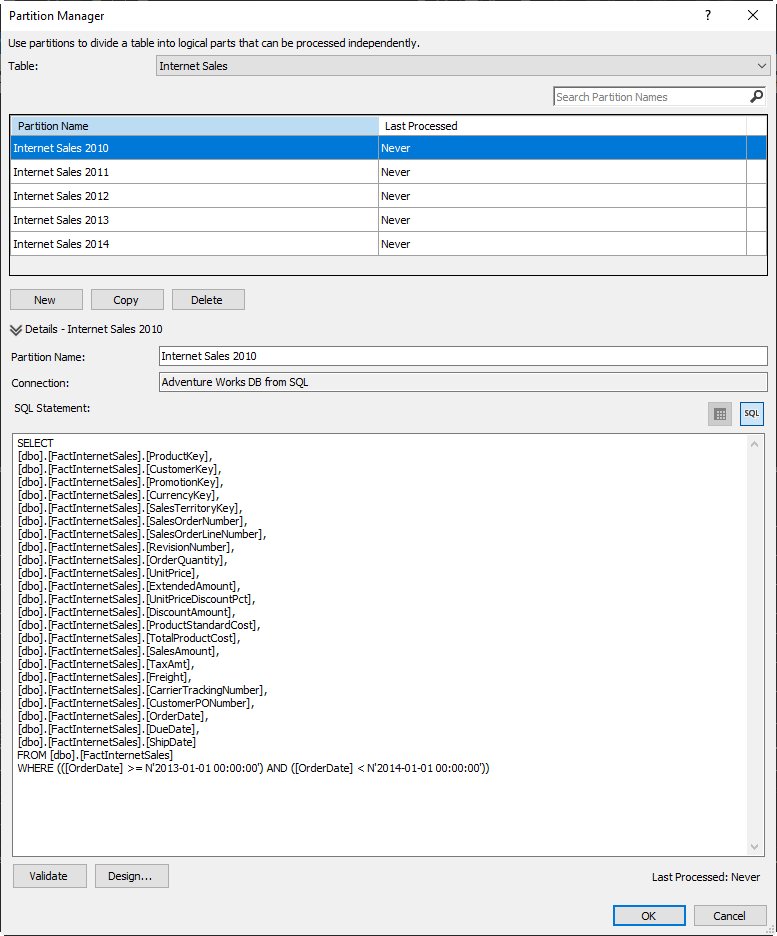
As you can see the difference is very simple. Let’s create a new partition.
Press the New button and in the Partition Name text box write Internet Sales 2015 and, in the query, modify the WHERE Clause to the following and press OK
WHERE (([OrderDate] >= N’2015-01-01 00:00:00′) AND ([OrderDate] < N’2016-01-01 00:00:00′))
The SQL partition will improve not only the queries that apply to specific partitions but also will reduce the time to process information. If you have a query that belongs to the 2012 partition only, the query will be faster than a model without partitions, because when you have partitions only the query that belongs to the range of the query is used to search.
What does partition mean in terms of automation for Azure Tabular models?
If you want to automate partitioning in Azure Analysis Services tabular models, we strongly recommend reading this link:
Conclusion
In this article, we learned what does SQL partition mean in two different scenarios. In a table partition, we explained what is a horizontal and vertical partition. We need to create filegroups, add files and create partitions and partition schemes.
On the other hand, we have partitions in SSAS which is a special technology for reports. We learned how to create partitions in Tabular models using an SSAS Tabular project.
We finally presented our article related to Dynamic Partition in Azure SSAS.
Daniel Calbimonte is a Microsoft Most Valuable Professional, Microsoft Certified Trainer and Microsoft Certified IT Professional for SQL Server. He is an accomplished SSIS author, teacher at IT Academies and has over 13 years of experience working with different databases.
He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
Latest posts by Daniel Calbimonte (see all)
- PostgreSQL tutorial to create a user — November 12, 2023
- PostgreSQL Tutorial for beginners — April 6, 2023
- PSQL stored procedures overview and examples — February 14, 2023
Related posts:
- Exporting SSRS reports to multiple worksheets in Excel
- SQL Server 2017: Columnstore Indexes and Trivial Plan
- Moving the SSISDB Catalog on a new SQL Server instance
- Estructura y conceptos de índices SQL Server
- SQL Server lock issues when using a DDL (including SELECT INTO) clause in long running transactions
About Daniel Calbimonte
Daniel Calbimonte is a Microsoft Most Valuable Professional, Microsoft Certified Trainer and Microsoft Certified IT Professional for SQL Server. He is an accomplished SSIS author, teacher at IT Academies and has over 13 years of experience working with different databases. He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams. He also helps with translating SQLShack articles to Spanish View all posts by Daniel Calbimonte
Follow us!
Popular
- SQL Convert Date functions and formats
- SQL Variables: Basics and usage
- SQL PARTITION BY Clause overview
- Different ways to SQL delete duplicate rows from a SQL Table
- How to UPDATE from a SELECT statement in SQL Server
- How to backup and restore MySQL databases using the mysqldump command
- SELECT INTO TEMP TABLE statement in SQL Server
- Overview of SQL RANK functions
- Understanding the SQL MERGE statement
- SQL Server table hints – WITH (NOLOCK) best practices
- SQL WHILE loop with simple examples
- SQL Server functions for converting a String to a Date
- SQL multiple joins for beginners with examples
- The Table Variable in SQL Server
- CASE statement in SQL
- INSERT INTO SELECT statement overview and examples
- Understanding the SQL Decimal data type
- SQL Lag function overview and examples
- SQL CROSS JOIN with examples
- SQL percentage calculation examples in SQL Server

Trending
- SQL Server Transaction Log Backup, Truncate and Shrink Operations
- Six different methods to copy tables between databases in SQL Server
- How to implement error handling in SQL Server
- Working with the SQL Server command line (sqlcmd)
- Methods to avoid the SQL divide by zero error
- Query optimization techniques in SQL Server: tips and tricks
- How to create and configure a linked server in SQL Server Management Studio
- SQL replace: How to replace ASCII special characters in SQL Server
- How to identify slow running queries in SQL Server
- SQL varchar data type deep dive
- How to implement array-like functionality in SQL Server
- All about locking in SQL Server
- SQL Server stored procedures for beginners
- Database table partitioning in SQL Server
- How to drop temp tables in SQL Server
- How to determine free space and file size for SQL Server databases
- Using PowerShell to split a string into an array
- KILL SPID command in SQL Server
- How to install SQL Server Express edition
- SQL Union overview, usage and examples
Solutions
- Read a SQL Server transaction log
- SQL Server database auditing techniques
- How to recover SQL Server data from accidental UPDATE and DELETE operations
- How to quickly search for SQL database data and objects
- Synchronize SQL Server databases in different remote sources
- Recover SQL data from a dropped table without backups
- How to restore specific table(s) from a SQL Server database backup
- Recover deleted SQL data from transaction logs
- How to recover SQL Server data from accidental updates without backups
- Automatically compare and synchronize SQL Server data
- Open LDF file and view LDF file content
- Quickly convert SQL code to language-specific client code
- How to recover a single table from a SQL Server database backup
- Recover data lost due to a TRUNCATE operation without backups
- How to recover SQL Server data from accidental DELETE, TRUNCATE and DROP operations
- Reverting your SQL Server database back to a specific point in time
- How to create SSIS package documentation
- Migrate a SQL Server database to a newer version of SQL Server
- How to restore a SQL Server database backup to an older version of SQL Server
- BI performance counters
- SQL code smells rules
- SQL Server wait types
© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy