Как работает hashset java
Интерфейс Set расширяет интерфейс Collection и представляет набор уникальных элементов. Set не добавляет новых методов, только вносит изменения в унаследованные. В частности, метод add() добавляет элемент в коллекцию и возвращает true, если в коллекции еще нет такого элемента.
Обобщенный класс HashSet представляет хеш-таблицу. Он наследует свой функционал от класса AbstractSet , а также реализует интерфейс Set .
Хеш-таблица представляет такую структуру данных, в которой все объекты имеют уникальный ключ или хеш-код. Данный ключ позволяет уникально идентифицировать объект в таблице.
Для создания объекта HashSet можно воспользоваться одним из следующих конструкторов:
- HashSet() : создает пустой список
- HashSet(Collection col) : создает хеш-таблицу, в которую добавляет все элементы коллекции col
- HashSet(int capacity) : параметр capacity указывает начальную емкость таблицы, которая по умолчанию равна 16
- HashSet(int capacity, float koef) : параметр koef или коэффициент заполнения, значение которого должно быть в пределах от 0.0 до 1.0, указывает, насколько должна быть заполнена емкость объектами прежде чем произойдет ее расширение. Например, коэффициент 0.75 указывает, что при заполнении емкости на 3/4 произойдет ее расширение.
Класс HashSet не добавляет новых методов, реализуя лишь те, что объявлены в родительских классах и применяемых интерфейсах:
import java.util.HashSet; public class Program < public static void main(String[] args) < HashSetstates = new HashSet(); // добавим в список ряд элементов states.add("Germany"); states.add("France"); states.add("Italy"); // пытаемся добавить элемент, который уже есть в коллекции boolean isAdded = states.add("Germany"); System.out.println(isAdded); // false System.out.printf("Set contains %d elements \n", states.size()); // 3 for(String state : states) < System.out.println(state); >// удаление элемента states.remove("Germany"); // хеш-таблица объектов Person HashSet people = new HashSet(); people.add(new Person("Mike")); people.add(new Person("Tom")); people.add(new Person("Nick")); for(Person p : people) < System.out.println(p.getName()); >> > class Person < private String name; public Person(String value)< name=value; >String getName() >
Интерфейс Set и классы HashSet, LinkedHashSet

Он расширяет Collection и определяет поведение коллекций, не допускающих дублирования элементов. Таким образом, метод add() возвращает false , если делается попытка добавить дублированный элемент в набор.
Интерфейс не определяет никаких собственных дополнительных методов.
Интерфейс Set заботится об уникальности хранимых объектов, уникальность определятся реализацией метода equals() . Поэтому если объекты создаваемого класса будут добавляться в Set , желательно переопределить метод equals() .
Ниже представлена ветка иерархии интерфейса Set :
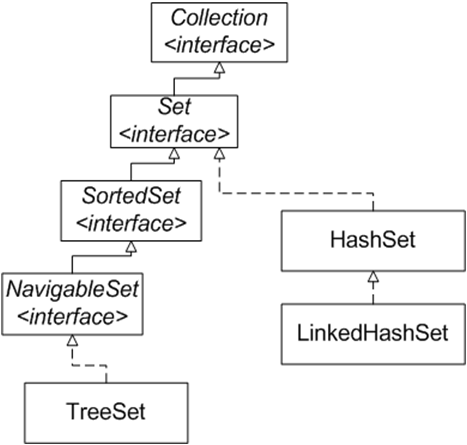
2. Класс HashSet
Класс HashSet реализует интерфейс Set и создает коллекцию, которая хранит элементы в хеш-таблице.
Хеш-таблица
Что же такое хеш-таблица? Элементы хеш-таблицы хранятся в виде пар ключ-значение. Ключ определяет ячейку (или бакет) для хранения значения. Содержимое ключа служит для определения однозначного значения, называемого хеш-кодом.
Мы можем считать, что хеш-код это ID объекта, хотя он необязательно должен быть уникальным. Этот хеш-код служит далее в качестве индекса, по которому сохраняются данные, связанные с ключом.
Вычисление хеш-кода
Рассмотрим пример вычисления хеш-кодов:
A(1) + l(12) + e(5) + x(24)
B(2) + o(15) + b(2)
D(4) + i(9) + r(18) + k(11)
F(6) + r(18) + e(5) + d(4)

Допустим, чтобы получить хеш-код, я сопоставляю каждый символ из ключа с номером этого символа в алфавите и получаю их сумму. Таким образом «Bob» попадает в бакет 19, «Fred» в бакет 33. Как видно из примера, для ключей «Alex» и «Dirk» получается одинаковый хеш-код, что тоже допустимо. Такая ситуация называется коллизией, два значения попадают в один бакет с номером 42.
Каким образом происходит обратный процесс — поиск элемента в хеш-таблице? У нас есть ключ объекта, по которому мы вычисляем хеш-код и определяем бакет, в котором находится наш объект. Но что делать если в бакете находится не один, а несколько элементов? Конечно, же это не значит, что хеш-таблица вернет любой объект из бакета. Если объектов в бакете несколько, далее с помощью метода equals() определяется нужный объект.
Контракт между методами hashCode() и equals()
Как Вы уже поняли, методы hashCode() и equals() тесно связаны между собой. Поэтому существуют специальный контракт написания методов hashCode() и equals() :
- Для одного и того же объекта, хеш-код всегда будет одинаковым.
- Если объекты одинаковые, то и хеш-коды одинаковые (но не наоборот).
- Если хеш-коды равны, то входные объекты не всегда равны.
- Если хеш-коды разные, то и объекты гарантированно будут разные.
На самом деле, корректным, но не эффективным может быть такое определение хеш-кода:
@Override public int hashCode()
Это определение метода hashCode() соответствует контракту, но он разместит все объекты класса в один бакет, что нивелирует все достоинства хеш-таблицы.
Создание метода hashCode()
Эффективным алгоритмом для определения хеш-кода объекта является такой алгоритм, который ровным слоем распределяет объекты по хеш-таблице. Вообще создание такого алгоритма, это достаточно сложный процесс, на котором защищают докторские диссертации. Но хорошей новостью является то, что на самом деле Вам не нужно придумывать свой алгоритм.
В средствах разработки, в частности в IntelliJ IDEA, существует генератор, который сгенерирует Вам метод hashCode() . Обычно все пользуются этим вариантом создания метода.
Конструкторы класса HashSet
Давайте рассмотрим конструкторы класса HashSet:
- HashSet() — начальная емкость по умолчанию (initialCapacity) – 16, коэффициент загрузки по умолчанию (loadFactor) – 0,75.
- HashSet(int initialCapacity) — коэффициент загрузки – 0,75.
- HashSet(int initialCapacity, float loadFactor)
- HashSet(Collection collection) – конструктор, добавляющий элементы из другой коллекции.
В конструкторах можно указывать такие параметры как начальная емкость и коэффициент загрузки. Давайте разберемся что это и для чего они нужны.
Начальная емкость (initial capacity) – это изначальное количество ячеек (buckets) в хэш-таблице. Если все ячейки будут заполнены, их количество увеличится автоматически.
Коэффициент загрузки (load factor) – это показатель того, насколько заполненным может быть HashSet до того момента, когда его емкость автоматически увеличится. Когда количество элементов в HashSet становится больше, чем capacity * loadfactor , хэш-таблица ре-хэшируется (заново вычисляются хэшкоды элементов, и таблица перестраивается согласно полученным значениям) и количество buckets в ней увеличивается в два раза.
Коэффициент загрузки, равный 0,75, в среднем обеспечивает хорошую производительность. Если этот параметр увеличить, тогда уменьшится нагрузка на память (так как это уменьшит количество операций ре-хэширования и перестраивания), но это повлияет на операции добавления и поиска. Чтобы минимизировать время, затрачиваемое на ре-хэширование, нужно правильно подобрать параметр начальной емкости.
Достоинства и недостатки класса HashSet
Выгода от хеширования состоит в том, что оно обеспечивает постоянство время выполнения операций add() , contains() , remove() и size() , даже для больших наборов. Сложность выполнения операций будет О(1). В худшем случае (если в хэш-таблице только один bucket) сложность выполнения будет O(n) для Java 7 и О(log n) для Java 8.
Недостаток класса HashSet (или можно даже сказать особенность) в том, что он не гарантирует упорядоченности элементов, поскольку процесс хеширования сам по себе обычно не приводит к созданию отсортированных множеств.
Пример использования класса HashSet
Рассмотрим пример использования класса HashSet :
import java.util.HashSet; import java.util.Set; public class HashSetDemo < public static void main(String[] args) < Setset = new HashSet<>(); set.add("Харьков"); set.add("Киев"); set.add("Львов"); set.add("Кременчуг"); set.add("Харьков"); System.out.println(set); > >3. Класс LinkedHashSet
Класс LinkedHashSet языка Java расширяет HashSet , не добавляя никаких новых методов.
LinkedHashSet поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор. Но это приводит к тому что класс LinkedHashSet выполняет операции дольше чем класс HashSet .
Рассмотрим пример использования класса LinkedHashSet :
import java.util.LinkedHashSet; import java.util.Set; public class LinkedHashSetDemo < public static void main(String[] args) < Setset = new LinkedHashSet<>(); set.add("Бета"); set.add("Aльфa"); set.add("Этa"); set.add("Гaммa"); set.add("Эпсилон"); set.add("Oмeгa"); System.out.println(set); > > - Интерфейс Collection
- Структуры данных
- Интерфейс List и класс ArrayList
- Интерфейс SortedSet и класс TreeSet
- Интерфейсы Comparable и Comparator
- Интерфейс NavigableSet
- Интерфейс Queue и классы
- Интерфейс Iterator
- Интерфейс ListIterator
- Отображения Map
- Класс Collections
- Backed Collections
- Legacy Classes
- Задания
Что нужно знать об устройстве коллекций, основанных на хешировании
Всем привет. На связи Владислав Родин. В настоящее время я являюсь руководителем курса «Архитектор высоких нагрузок» в OTUS, а также преподаю на курсах, посвященных архитектуре ПО.
Помимо преподавания, как вы могли заметить, я занимаюсь написанием авторского материала для блога OTUS на хабре и сегодняшнюю статью хочу посвятить запуску нового потока курса «Алгоритмы для разработчиков».

Введение
Хеш-таблицы (HashMap) наравне с динамическими массивами являются самыми популярными структурами данных, применяемыми в production’е. Очень часто можно услышать вопросы на собеседованиях касаемо их предназначения, особенностей их внутреннего устройства, а также связанных с ними алгоритмов. Данная структура данных является классической и встречается не только в Java, но и во многих других языках программирования.
Постановка задачи
Давайте зададимся целью создать структуру данных, которая позволяет:
- contains(Element element) проверять, находится в ней некоторый элемент или нет, за О(1)
- add(Element element) добавлять элемент за О(1)
- delete(Element element) удалять элемент за О(1)
Массив
Попробуем сделать эти операции поверх массива, который является самой простой структурой данных. Договоримся, что будем считать ячейку пустой, если в ней содержится null.
Проверка наличия
Необходимо сделать линейный поиск по массиву, ведь элемент потенциально может находиться в любой ячейке. Асимптотически это можно осуществить за O(n), где n — размер массива.
Добавление
Если нам надо добавить элемент абы куда, то вначале мы должны найти пустую ячейку, а затем записать в нее элемент. Таким образом, мы опять осуществим линейный поиск и получим асимптотику O(n).
Удаление
Чтобы удалить элемент, его нужно сначала найти, а затем в найденную ячейку записать null. Опять линейный поиск приводит нас к O(n).
Простейшее хеш-множество
Обратите внимание, что при каждой операции, мы сначала искали индекс нужной ячейки, а затем осуществляли операцию, и именно поиск портит нам асимптотику! Если бы мы научились получать данный индекс за O(1), то исходная задача была бы решена.
Давайте теперь заменим линейный поиск на следующий алгоритм: будем вычислять значение некоторой фунции — хеш-функции, ставящей в соответствие объекту класса некоторое целое число. После этого будем сопоставлять полученное целое число индексу ячейки массива (это достаточно легко сделать, например, взяв остаток от деления этого числа на размер массива). Если хеш-функция написана так, что она считается за O(1) (а она так обычно и написана), то мы получили самую простейшую реализацию хеш-множества. Ячейка массива в терминах хеш-множества может называться bucket‘ом.
Проблемы простейшей реализации хеш-множества
Как бы ни была написана хеш-функция, число ячеек массива всегда ограничено, тогда как множество элементов, которые мы хотим хранить в структуре данных, неограничено. Ведь мы бы не стали заморачиваться со структурой данных, если бы была потребность в сохранении всего лишь десяти заранее известных элементов, верно? Такое положение дел приводит к неизбежным коллизиям. Под коллизией понимается ситуация, когда при добавлении разных объектов мы попадаем в одну и ту же ячейку массива.
Для разрешения коллизий придумано 2 метода: метод цепочек и метод открытой адресации.
Метод цепочек
Метод цепочек является наиболее простым методом разрешения коллизий. В ячейке массива мы будем хранить не элементы, а связанный список данных элементов. Потому как добавление в начало списка (а нам все равно в какую часть списка добавлять элемент) обладает асимптотикой О(1), мы не испортим общую асимптотику, и она останется равной О(1).
У данной реализации есть проблема: если списки будут очень сильно вырастать (в качестве крайнего случая можно рассмотреть хеш-функцию, которая возвращает константу для любого объекта), то мы получим асимптотику O(m), где m — число элементов во множестве, если размер массива фиксирован. Для избежания таких неприятностей вводится понятие коэффициент заполнения (он может быть равен, например, 1.5). Если при добавлении элемента оказывается, что доля числа элементов, находящихся в структуре данных по отношению к размеру массива, превосходит коэффициент заполнения, то происходит следующее: выделяется новый массив, размер которого превосходит размер старого массива (например в 2 раза), и структура данных перестраивается на новом массиве.
Данный метод разрешения коллизий и применяется в Java, а структура данных называется HashSet.
Метод открытой адресации
В данном методе в ячейках хранятся сами элементы, а в случае коллизии происходит последовательность проб, то есть мы начинаем по некоторому алгоритму перебирать ячейки в надежде найти свободную. Это можно делать разными алгоритмами (линейная / квадратичная последовательности проб, двойное хеширование), каждый из которых обладает своими проблемами (например, возникновение первичных или вторичных кластеров).
От хеш-множества к хеш-таблице (HashMap)
Давайте создадим структуру данных, которая позволяет так же быстро, как и хеш-множество (то есть за O(1)), добавлять, удалять, искать элементы, но уже по некоторому ключу.
Воспользуемся той же структурой данных, что у хеш-множества, но хранить будем не элементы, а пары элементов.
Таким образом, вставка (put(Key key, Value value)) будет осуществляться так: мы посчитаем ячейку массива по объекту типа Key, получим номер bucket’а. Пройдемся по списку в bucket’е, сравнивая ключ с ключом в хранимых парах. Если нашли такой же ключ — просто вытесняем старое значение, если не нашли — добавляем пару.
Как осуществляется получение элемента по ключу? Да по похожему принципу: получаем bucket по ключу, проходимся по парам и возвращаем значение в паре, ключ в которой равен ключу в запросе, если такая пара есть, и null в противном случае.
Данная структура данных и называется хеш-таблицей.
Типичные вопросы на собеседовании
Q: Как устроены HashSet и HashMap? Как осуществляются основные операциии в данных коллекциях? Как применяются методы equals() и hashCode()?
A: Ответы на данные вопросы можно найти выше.
Q: Каков контракт на equals() и hashCode()? Чем он обусловлен?
A: Если объекты равны, то у них должны быть равны hashCode. Таким образом, hashCode должен определяться по подможноству полей, учавствующих в equals. Нарушение данного контракта может приводить к весьма интересным эффектам. Если объекты равны, но hashCode у них разный, то вы можете не достать значение, соответствующее ключу, по которому вы только что добавили объект в HashSet или в HashMap.
Вывод
На собеседованиях очень любят задавать различные кейсы, связанные с этими структурами данных. При этом решение любого из них может быть выведено из понимания принципов их работы без всякой «зубрежки».
На этом все. Если вы дочитали материал до конца, приглашаю на бесплатный урок по теме «Секреты динамического программирования» в рамках урока мой коллега — Евгений Волосатов покажет как решить олимпиадную задачу используя идеи динамического программирования.
- Блог компании OTUS
- Программирование
- Java
- Алгоритмы
- Промышленное программирование
HashSet в Java
HashSet в Java реализует интерфейс Set, т.е. не допускает дублирования. Он внутренне поддерживается HashMap, который работает по принципу хеширования.
Мы можем хранить нулевое значение в HashSet . Его емкость по умолчанию составляет 16 с коэффициентом загрузки 0,75, где:
Load factor = Number of Stored Elements / capacity
Java HashSet не синхронизирован. Кроме того, нет гарантии сохранения порядка вставки элементов.
В этом уроке мы узнаем, как работать с Java HashSet .
Создание HashSet :
Мы можем создать Java HashSet, используя один из следующих конструкторов:
HashSet() // default capacity of 16 with a load factor of 0.75
HashSet( int initialCapacity)
HashSet( int initialCapacity, float loadFactor)
HashSet(Collection c)
Каждый из этих конструкторов довольно интуитивно понятен.
Давайте быстро создадим HashSet, используя конструктор по умолчанию:
Set
Обычно используемые методы:
Давайте теперь посмотрим на некоторые методы, которые могут помочь нам манипулировать с помощью Java HashSet:
1. логическое сложение (E e):
Он просто добавляет элемент к данному набору, если его еще нет. Если элемент уже присутствует, add () просто возвращает false:
System.out.println(set.add( 1 )); //true
System.out.println(set.add( 2 )); //true
System.out.println(set.add( 3 )); //true
System.out.println(set.add( 1 )); //false — as already present
//Note that the order of elements isn’t guaranteed
System.out.println(set); //[1, 2, 3]
2. логическое значение содержит (Object obj):
Метод contains () возвращает true, если элемент существует в указанном наборе, в противном случае – false :
System.out.println(set.contains( 1 )); //true
System.out.println(set.contains( 4 )); //false
3. логическое удаление (Object obj):
Как следует из названия, он удаляет элемент obj, если он существует, и возвращает true . Если такого элемента не существует, он просто возвращает false :
System.out.println(set.remove( 1 )); //true
System.out.println(set.remove( 4 )); //false
Обратите внимание, что HashSet также наследует методы removeAll () и removeIf () , которые можно использовать для удаления значений.
4. логическое значение isEmpty ():
Возвращает true для пустого набора, иначе false :
System.out.println(set.isEmpty()); // false
5. int size ():
Он просто возвращает количество элементов, присутствующих в данном наборе.
6. void clear ():
Метод clear () удаляет все значения, присутствующие в указанном наборе, что делает его пустым.
Внутренняя реализация:
HashSet внутренне использует HashMap для хранения своих элементов. Элементы, хранящиеся в HashSet, отображаются как ключи в HashMap . Поля значений всех этих записей содержат константу PRESENT:
private static final Object PRESENT = new Object();
который является фиктивным объектом.
Итерация по HashSet :
Мы можем использовать один из следующих способов для перебора элементов в HashSet :
1. forEach () :
Начиная с Java 8, мы можем использовать forEach () для перебора любой коллекции Java :
set.forEach(e -> System.out.println(e));
2. forEachRemaining ():
Java 8 также поддерживает конструкцию forEachRemaining (), которая будет использоваться с любым итератором в коллекции :
Iterator
itr.forEachRemaining(e -> System.out.println(e));
3. Итерация с использованием итератора :
В случае, если мы находимся на Java 7 или более ранних версиях, мы можем просто перебрать итератор:
Iterator
while (itr.hasNext()) <
System.out.println(itr.next());
4. Расширен для цикла:
Мы также можем использовать расширенный цикл for для прохождения через элементы:
for (Integer e : set) < System.out.println(e);
Вывод:
В этом уроке мы узнали, как создавать и работать с Java HashSet. Мы также знаем, что Java HashSet внутренне использует HashMap для своей реализации.
Оставьте первый комментарий.
Опубликовано на Java Code Geeks с разрешения Шубхры Шриваставы, партнера нашей программы JCG . Смотреть оригинальную статью здесь: HashSet In Java
Мнения, высказанные участниками Java Code Geeks, являются их собственными.