Набор данных MNIST в Python — базовый импорт и построение
Добро пожаловать в этот учебник по набору данных MNIST. В этом руководстве мы узнаем, что такое набор данных MNIST, как импортировать его в Python и как построить его с помощью matplotlib.
Что такое набор данных MNIST?
Набор MNIST — это большая коллекция рукописных цифр. Это очень популярный набор данных в области обработки изображений. Он часто используется для тестирования алгоритмов машинного обучения.
MNIST — это сокращение от модифицированной базы данных Национального института стандартов и технологий.
MNIST содержит коллекцию из 70 000 изображений 28 x 28 рукописных цифр от 0 до 9.
Набор данных уже разделен на наборы для обучения и тестирования. Мы увидим это позже в руководстве.
Дополнительные сведения о MNIST на его странице в Википедии. Мы собираемся импортировать набор данных из Keras.
Начнем с загрузки набора данных в наш блокнот на Python.
Загрузка MNIST из Keras
Сначала нам нужно импортировать набор данных MNIST из модуля Keras.
Мы можем сделать это, используя следующую строку кода:
from keras.datasets import mnist Теперь загрузим обучающий и тестовый наборы в отдельные переменные.
(train_X, train_y), (test_X, test_y) = mnist.load_data() Давайте узнаем, сколько изображений есть в обучающем и тестовом наборах. Другими словами, давайте попробуем выяснить коэффициент разделения этого набора данных.
Чтобы найти коэффициент разделения, мы собираемся распечатать формы всех векторов.
print('X_train: ' + str(train_X.shape)) print('Y_train: ' + str(train_y.shape)) print('X_test: ' + str(test_X.shape)) print('Y_test: ' + str(test_y.shape)) X_train: (60000, 28, 28) Y_train: (60000,) X_test: (10000, 28, 28) Y_test: (10000,) Мы видим, что в обучающей выборке 60 тысяч изображений, а в тестовой — 10 тысяч.
Размерность нашего обучающего вектора составляет (60000, 28, 28), это потому, что имеется 60 000 изображений в градациях серого с размером 28X28.
Полный код для загрузки набора данных MNIST
Вот полный код из этого раздела:
from keras.datasets import mnist #loading the dataset (train_X, train_y), (test_X, test_y) = mnist.load_data() #printing the shapes of the vectors print('X_train: ' + str(train_X.shape)) print('Y_train: ' + str(train_y.shape)) print('X_test: ' + str(test_X.shape)) print('Y_test: ' + str(test_y.shape)) Давайте узнаем, как построить этот набор данных.
Построение набора данных MNIST с использованием matplotlib
Всегда полезно построить график набора данных, над которым вы работаете. Это даст вам хорошее представление о том, с какими данными вы имеете дело.
Как ответственный специалист по данным, вы должны всегда строить набор данных как нулевой шаг.
Чтобы построить набор данных, используйте следующий фрагмент кода:
from matplotlib import pyplot for i in range(9): pyplot.subplot(330 + 1 + i) pyplot.imshow(train_X[i], cmap=pyplot.get_cmap('gray')) pyplot.show() 
Вот как выглядят наши данные!
Представьте себе 70 000 изображений, подобных этим. Это то, что находится внутри набора данных. Большой объем — одна из причин популярности набора данных.
Проблема распознавания почерка, сколь бы банальной она ни была, сейчас устарела. Возникла потребность в более сложной версии набора данных MNSIT, которая могла бы служить его заменой.
Есть ли более сложная версия набора данных MNIST?
Да, есть. Набор данных Fashion MNIST.
7.4. Загрузка других наборов данных ¶
Scikit-learn также встраивает несколько образцов изображений в формате JPEG, опубликованных их авторами по лицензии Creative Commons. Эти изображения могут быть полезны для тестирования алгоритмов и конвейеров на 2D-данных.
| load_sample_images () | Загрузите образцы изображений для обработки изображений. |
| load_sample_image (имя_изображения) | Загрузите массив numpy одного образца изображения |
Кодирование изображений по умолчанию основано на uint8 dtype, чтобы освободить память. Часто алгоритмы машинного обучения работают лучше всего, если входные данные сначала преобразуются в представление с плавающей запятой. Кроме того, если вы планируете использовать matplotlib.pyplpt.imshow , не забудьте масштабировать до диапазона 0–1, как показано в следующем примере.
7.4.2. Наборы данных в формате svmlight / libsvm
scikit-learn включает служебные функции для загрузки наборов данных в формате svmlight / libsvm. В этом формате каждая строка принимает форму : : …. Этот формат особенно подходит для разреженных наборов данных. В этом модуле scipy разреженные матрицы CSR используются для X а массивы numpy используются для y
Вы можете загрузить набор данных следующим образом:
>>> from sklearn.datasets import load_svmlight_file >>> X_train, y_train = load_svmlight_file("/path/to/train_dataset.txt") .
Вы также можете загрузить два (или более) набора данных одновременно:
>>> X_train, y_train, X_test, y_test = load_svmlight_files( . ("/path/to/train_dataset.txt", "/path/to/test_dataset.txt")) .
В этом случае X_train и X_test гарантированно будет такое же количество функций. Другой способ добиться того же результата — исправить количество функций:
>>> X_test, y_test = load_svmlight_file( . "/path/to/test_dataset.txt", n_features=X_train.shape[1]) .
7.4.3. Скачивание наборов данных из репозитория openml.org
openml.org — это общедоступный репозиторий для данных машинного обучения и экспериментов, который позволяет всем загружать открытые наборы данных.
sklearn.datasets Пакет может загрузить наборы данных из хранилища с помощью функции sklearn.datasets.fetch_openml .
Например, чтобы загрузить набор данных экспрессии генов в мозге мышей:
>>> from sklearn.datasets import fetch_openml >>> mice = fetch_openml(name='miceprotein', version=4)
Чтобы полностью указать набор данных, вам необходимо указать имя и версию, хотя версия не является обязательной, см. « Версии набора данных» ниже. Набор данных содержит в общей сложности 1080 примеров, относящихся к 8 различным классам:
>>> mice.data.shape (1080, 77) >>> mice.target.shape (1080,) >>> np.unique(mice.target) array(['c-CS-m', 'c-CS-s', 'c-SC-m', 'c-SC-s', 't-CS-m', 't-CS-s', 't-SC-m', 't-SC-s'], dtype=object)
Вы можете получить более подробную информацию о наборе данных, глядя на DESCR и details атрибуты:
>>> print(mice.DESCR) **Author**: Clara Higuera, Katheleen J. Gardiner, Krzysztof J. Cios **Source**: [UCI](https://archive.ics.uci.edu/ml/datasets/Mice+Protein+Expression) - 2015 **Please cite**: Higuera C, Gardiner KJ, Cios KJ (2015) Self-Organizing Feature Maps Identify Proteins Critical to Learning in a Mouse Model of Down Syndrome. PLoS ONE 10(6): e0129126. >>> mice.details
DESCR cодержит свободный текст описания данных, в то время как details содержит словарь мета-данных , которые хранятся openml, как набор данных ид. Дополнительные сведения см. В документации OpenML. Набор data_id данных белка мышей — 40966, и вы можете использовать это (или имя), чтобы получить дополнительную информацию о наборе данных на веб-сайте openml:
>>> mice.url 'https://www.openml.org/d/40966'
Также data_id уникально идентифицирует набор данных из OpenML:
>>> mice = fetch_openml(data_id=40966) >>> mice.details
7.4.3.1. Версии набора данных
Набор данных однозначно определяется data_id своим именем, но не обязательно своим именем. Может существовать несколько разных «версий» набора данных с одним и тем же именем, которые могут содержать совершенно разные наборы данных. Если в определенной версии набора данных обнаружены серьезные проблемы, ее можно отключить. Использование имени для указания набора данных даст самую раннюю версию набора данных, которая все еще активна. Это означает, что fetch_openml(name=»miceprotein») в разное время могут быть получены разные результаты, если более ранние версии становятся неактивными. Вы можете видеть, что набор данных с data_id 40966, который мы получили выше, является первой версией набора данных «miceprotein»:
>>> mice.details['version'] '1'
Фактически, у этого набора данных есть только одна версия. С другой стороны, набор данных iris имеет несколько версий:
>>> iris = fetch_openml(name="iris") >>> iris.details['version'] '1' >>> iris.details['id'] '61' >>> iris_61 = fetch_openml(data_id=61) >>> iris_61.details['version'] '1' >>> iris_61.details['id'] '61' >>> iris_969 = fetch_openml(data_id=969) >>> iris_969.details['version'] '3' >>> iris_969.details['id'] '969'
Указание набора данных по имени «iris» дает самую низкую версию, версию 1, с data_id 61. Чтобы быть уверенным, что вы всегда получаете именно этот набор данных, безопаснее всего указывать его по набору данных data_id . Другой набор данных с data_id 969 — это версия 3 (версия 2 стала неактивной) и содержит бинаризованную версию данных:
>>> np.unique(iris_969.target) array(['N', 'P'], dtype=object)
Вы также можете указать имя и версию, которые также однозначно идентифицируют набор данных:
>>> iris_version_3 = fetch_openml(name="iris", version=3) >>> iris_version_3.details['version'] '3' >>> iris_version_3.details['id'] '969'
- Ваншорен, ван Рейн, Бишл и Торго «OpenML: сетевая наука в машинном обучении» , ACM SIGKDD Explorations Newsletter, 15 (2), 49-60, 2014.
7.4.4. Загрузка из внешних наборов данных
scikit-learn работает с любыми числовыми данными, хранящимися в виде массивов numpy или scipy разреженных матриц. Другие типы, которые можно преобразовать в числовые массивы, такие как pandas DataFrame, также приемлемы.
Вот несколько рекомендуемых способов загрузки стандартных столбчатых данных в формат, используемый scikit-learn:
- pandas.io предоставляет инструменты для чтения данных из распространенных форматов, включая CSV, Excel, JSON и SQL. DataFrames также могут быть созданы из списков кортежей или dicts. Pandas плавно обрабатывает разнородные данные и предоставляет инструменты для обработки и преобразования в числовой массив, подходящий для scikit-learn.
- scipy.io специализируется на двоичных форматах, часто используемых в контексте научных вычислений, таких как .mat и .arff.
- numpy / routines.io для стандартной загрузки столбчатых данных в массивы numpy
- scikit-learn datasets.load_svmlight_file для разреженного формата svmlight или libSVM
- scikit-learn datasets.load_files для каталогов текстовых файлов, где имя каждого каталога является именем каждой категории, а каждый файл внутри каждого каталога соответствует одному образцу из этой категории
Для некоторых различных данных, таких как изображения, видео и аудио, вы можете обратиться к:
- skimage.io или Imageio для загрузки изображений и видео в массивы numpy
- scipy.io.wavfile.read для чтения файлов WAV в массив numpy
Категориальные (или номинальные) функции, хранящиеся в виде строк (распространенные в pandas DataFrames), потребуют преобразования в числовые функции с помощью OneHotEncoder или OrdinalEncoder или аналогичного. См. Раздел «Предварительная обработка данных» .
Примечание: если вы управляете своими собственными числовыми данными, рекомендуется использовать оптимизированный формат файла, такой как HDF5, чтобы сократить время загрузки данных. Различные библиотеки, такие как H5Py, PyTables и pandas, предоставляют интерфейс Python для чтения и записи данных в этом формате.
Если вы хотите помочь проекту с переводом, то можно обращаться по следующему адресу support@scikit-learn.ru
© 2007 — 2020, scikit-learn developers (BSD License).
Доступ к наборам данных через Python с помощью клиентской библиотеки Python для машинного обучения Azure
Предварительная версия клиентской библиотеки Python для машинного обучения Microsoft Azure может обеспечить безопасный доступ к наборам данных машинного обучения Azure из локальной среды Python. Она также позволяет создавать наборы данных и управлять ими в рабочей области.
В этой статье описано, как:
- установить клиентскую библиотеку Python для машинного обучения;
- обращаться к наборам данных и передавать их, включая указания по получению авторизации для доступа к наборам данных машинного обучения Azure из локальной среды Python;
- получать доступ к промежуточным наборам данных из экспериментов;
- использовать клиентскую библиотеку Python для перечисления наборов данных, получать доступ к метаданным, читать содержимое набора данных, создавать новые наборы данных и обновлять существующие наборы данных
Предварительные требования
Клиентская библиотека Python была протестирована в следующих средах:
- Windows, Mac и Linux
- Python 2.7 и 3.6+
Зависит от следующих пакетов:
- requests
- python-dateutil
- pandas
Мы рекомендуем использовать дистрибутив Python, например Anaconda или Canopy, который поставляется с Python, IPython и тремя устанавливаемыми пакетами, перечисленными выше. Хотя использование IPython не является обязательным, это отличная среда для интерактивного управления данными и их визуализации.
Как установить клиентскую библиотеку Python для Машинного обучения Azure
Чтобы выполнять задачи, описанные в этом разделе, следует установить клиентскую библиотеку Python для Машинного обучения Azure. Библиотеку можно установить из индекса пакета Python. Чтобы установить ее в своей среде Python, выполните следующую команду в локальной среде Python:
pip install azureml Кроме того, можно скачать и установить ее из источников на портале GitHub.
python setup.py install Если на компьютере установлено приложение git, вы можете использовать команду pip для установки непосредственно из репозитория git:
pip install git+https://github.com/Azure/Azure-MachineLearning-ClientLibrary-Python.git Использование фрагментов кода для доступа к наборам данных
Клиентская библиотека Python обеспечивает программный доступ к существующим наборам данных от экспериментов, которые были выполнены.
С помощью веб-интерфейса студии Машинного обучения Azure (классической) можно создавать фрагменты кода, содержащие все необходимые данные для скачивания и десериализации наборов данных в качестве объектов Pandas DataFrame на локальном компьютере.
Безопасность доступа к данным
Фрагменты кода, предоставляемые студией Машинного обучения Azure (классической) для использования с клиентской библиотекой Python, включают идентификатор рабочей области и маркер авторизации. Они предоставляют полный доступ к рабочей области, и их необходимо защитить, например, паролем.
По соображениям безопасности функциональность фрагмента кода доступна только пользователям с ролью Владелец для рабочей области. Роль пользователя отображается в студии Машинного обучения Azure (классической) на странице Пользователи в разделе Параметры.
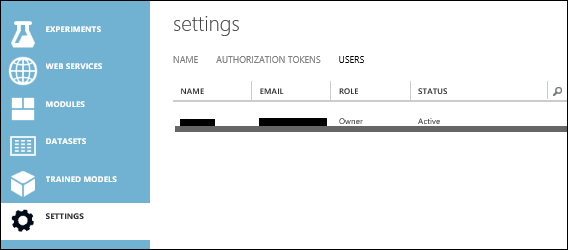
Если ваша роль не Владелец, то вы можете запросить приглашение в качестве владельца или обратиться к владельцу рабочей области за предоставлением фрагмента кода.
Для получения маркера авторизации можно выбрать один из следующих вариантов.
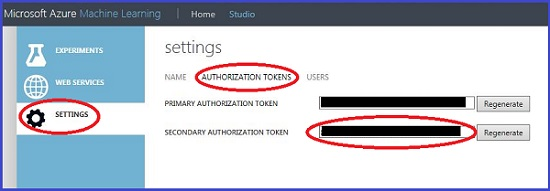
- Запросите маркер у владельца. Владельцы могут получить доступ к своим маркерам авторизации на странице настроек рабочей области в студии Машинного обучения Azure (классической). Выберите Параметры в левой области и щелкните Authorization tokens (Маркеры авторизации), чтобы просмотреть основной и дополнительный маркеры. Хотя в фрагменте кода могут использоваться как основные, так и дополнительные маркеры авторизации, владельцам рекомендуется предоставлять только дополнительные маркеры авторизации.
- Запрос на повышение роли владельца: текущий владелец рабочей области должен сначала удалить вас из рабочей области, а затем пригласить вас в качестве владельца.
После того как разработчики получили идентификатор рабочей области и маркер авторизации, они смогут получить доступ к рабочей области с помощью фрагмента кода независимо от своей роли.
Для управления маркерами авторизации используется раздел Параметры страницы Authorization tokens (Маркеры авторизации). Их можно создать повторно, но эта процедура отменяет доступ для предыдущего маркера.
Доступ к наборам данных из локального приложения Python
- В студии Машинного обучения Azure (классической) на панели навигации слева нужно нажать НАБОРЫ ДАННЫХ.
- Выберите набор данных, к которому хотите получить доступ. Вы можете выбрать любой из наборов данных в списке My datasets (Мои наборы данных) или Примеры.
- На нижней панели инструментов щелкните Generate Data Access Code(Создать код доступа к данным). Эта кнопка отключена, если данные хранятся в формате, несовместимом с клиентской библиотекой Python.
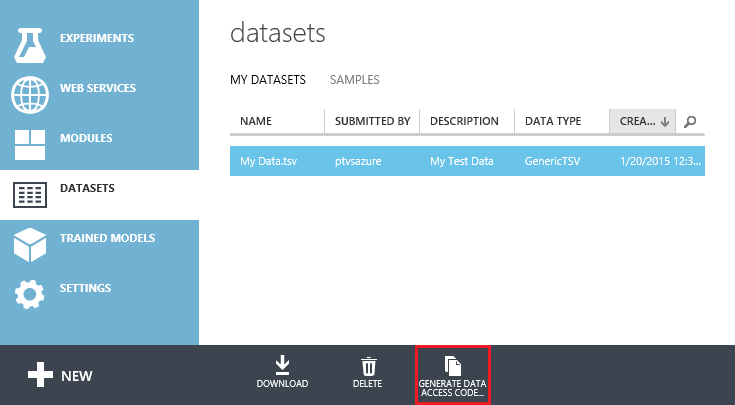
- Выберите фрагмент кода в появившемся окне и скопируйте его в буфер обмена.
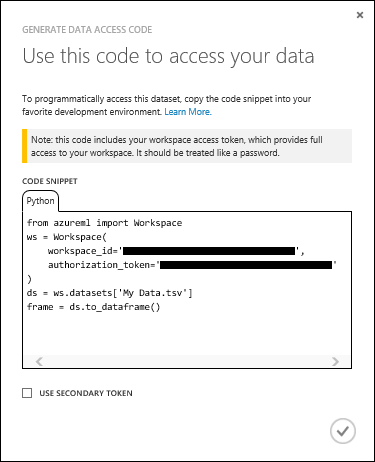
- Вставьте код в заметки своего локального приложения Python.
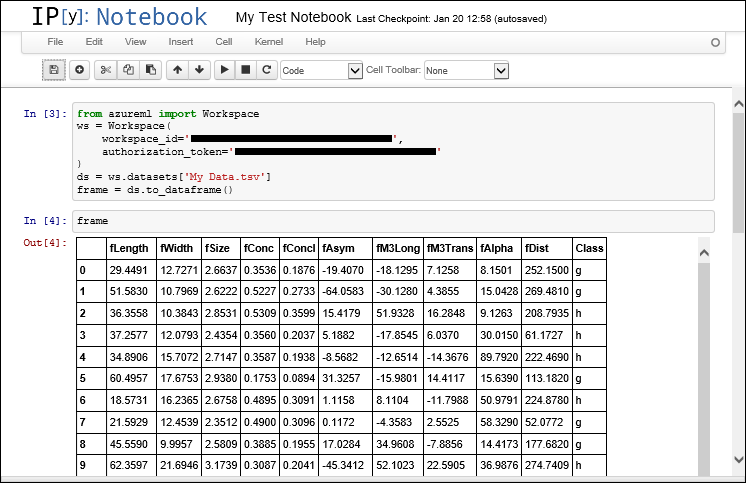
Доступ к промежуточным наборам данных из экспериментов машинного обучения
После выполнения эксперимента в студии Машинного обучения Azure (классической) можно получить доступ к промежуточным наборам данных из выходных узлов модулей. Промежуточные наборы данных — это данные, создаваемые и используемые на промежуточных шагах после запуска инструмента моделирования.
Доступ к промежуточным наборам данных можно получить при условии, что формат данных совместим с клиентской библиотекой Python.
Поддерживаются следующие форматы (константы для них находятся в классе azureml.DataTypeIds ):
- PlainText
- GenericCSV
- GenericTSV
- GenericCSVNoHeader
- GenericTSVNoHeader
Определить формат можно, наведя указатель мыши на выходной узел модуля. Он отображается во всплывающей подсказке вместе с именем узла.
Некоторые модули, например модуль Разделение, выводят данные в формат Dataset , который не поддерживается клиентской библиотекой Python.
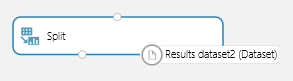
В этом случае требуется модуль преобразования, например Преобразовать в CSV, чтобы получить выходные данные в поддерживаемом формате.
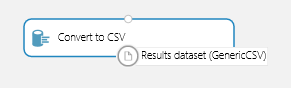
Далее показан пример, который создает эксперимент, выполняет его и обращается к промежуточному набору данных.
- Создайте новый эксперимент.
- Вставьте модуль набора данных Adult Census Income Binary Classification .
- Вставьте модуль Разделение и подключите к его вводу выходные данные модуля набора данных.
- Вставьте модуль Преобразовать в CSV и подключите к его вводу выходные данные модуля набора данных Разделение.
- Сохраните эксперимент, запустите его и дождитесь завершения задания.
- Щелкните выходной узел в модуле Преобразовать в CSV.
- В появившемся контекстном меню щелкните пункт Generate Data Access Code (Создать код доступа к данным).
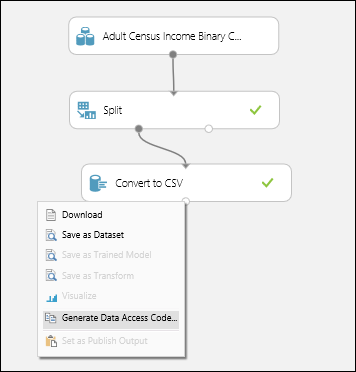
- Выберите фрагмент кода в появившемся окне и скопируйте его в буфер обмена.
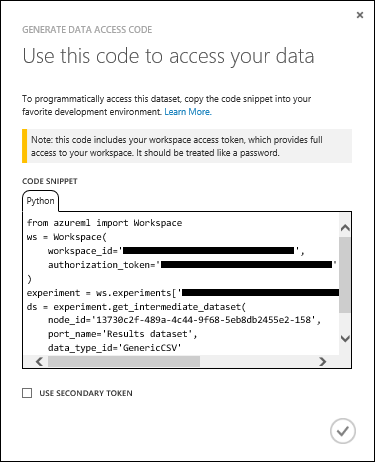
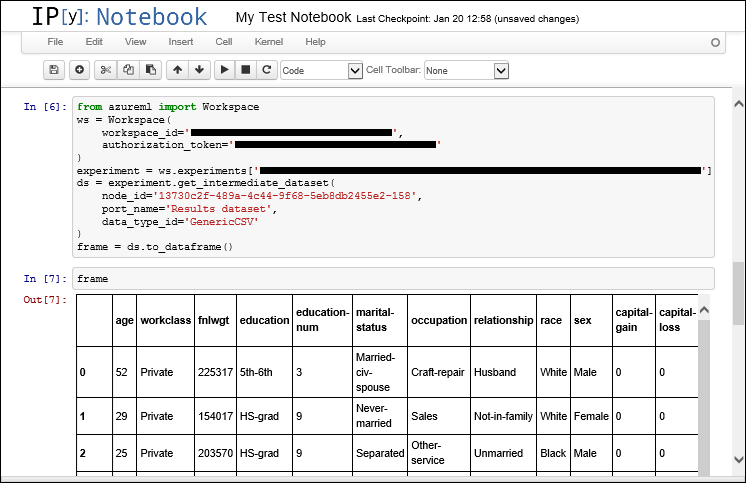
- Вставьте код в заметки.
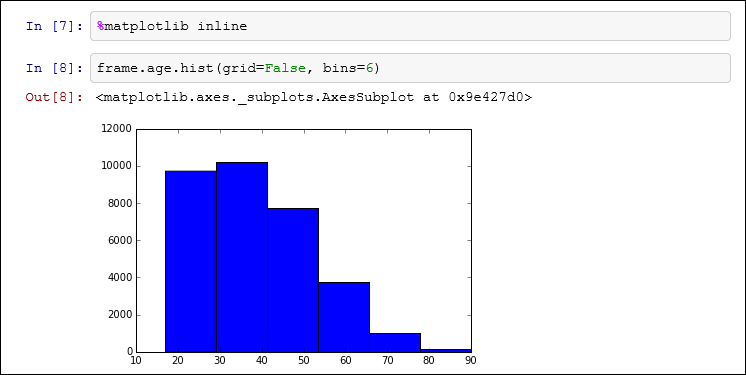
- Вы можете визуализировать данные с помощью matplotlib. Вот как выглядит гистограмма для столбца возраста:
Использование клиентской библиотеки Python для машинного обучения для осуществления доступа, чтения, создания и управления наборами данных
Рабочая область
Рабочая область — это точка входа для клиентской библиотеки Python. Укажите Workspace класс с идентификатором рабочей области и маркером авторизации, чтобы создать экземпляр:
ws = Workspace(workspace_id='4c29e1adeba2e5a7cbeb0e4f4adfb4df', authorization_token='f4f3ade2c6aefdb1afb043cd8bcf3daf') Перечисление наборов данных
Для перечисления всех наборов данных в заданной рабочей области:
for ds in ws.datasets: print(ds.name) Для перечисления только созданных пользователями наборов данных:
for ds in ws.user_datasets: print(ds.name) Для перечисления только примеров наборов данных:
for ds in ws.example_datasets: print(ds.name) Можно обратиться к набору данных по имени (с учетом регистра):
ds = ws.datasets['my dataset name'] ds = ws.datasets[0] Метаданные
Кроме содержимого в наборах данных имеются метаданные. (Промежуточные наборы данных являются исключением из этого правила и не имеют метаданных.)
Некоторые значения метаданных назначаются пользователем во время создания:
- print(ds.name)
- print(ds.description)
- print(ds.family_id)
- print(ds.data_type_id)
Другие значения назначаются Машинным обучением Azure:
- print(ds.id)
- print(ds.created_date)
- print(ds.size)
Дополнительную информацию о доступных метаданных см. в описании класса SourceDataset .
Чтение содержимого
Фрагменты кода, предоставляемые студией Машинного обучения Azure (классической), автоматически скачивают набор данных и выполняют его десериализацию в объект Pandas DataFrame. Это выполняется методом to_dataframe :
frame = ds.to_dataframe() Если вы предпочитаете скачать необработанные данные и выполнить десериализацию вручную, это возможно. На данный момент это единственная возможность для таких форматов, как «ARFF», которые клиентская библиотека Python не может десериализовать.
Для считывания содержимого в виде текста:
text_data = ds.read_as_text() Для считывания содержимого в виде двоичного файла:
binary_data = ds.read_as_binary() Можно также просто открыть поток содержимого:
with ds.open() as file: binary_data_chunk = file.read(1000) Создание нового набора данных
Клиентская библиотека Python позволяет передавать наборы данных из программы Python. Эти наборы данных затем станут доступными для использования в вашей рабочей области.
Для данных в формате Pandas DataFrame используйте следующий код:
from azureml import DataTypeIds dataset = ws.datasets.add_from_dataframe( dataframe=frame, data_type_id=DataTypeIds.GenericCSV, name='my new dataset', description='my description' ) Если данные уже сериализованы, можно использовать:
from azureml import DataTypeIds dataset = ws.datasets.add_from_raw_data( raw_data=raw_data, data_type_id=DataTypeIds.GenericCSV, name='my new dataset', description='my description' ) Клиентская библиотека Python может сериализовать объекты Pandas DataFrame в следующие форматы (константы для них находятся в классе azureml.DataTypeIds ):
- PlainText
- GenericCSV
- GenericTSV
- GenericCSVNoHeader
- GenericTSVNoHeader
Обновление существующего набора данных
Если вы попытаетесь передать новый набор данных с именем, которое совпадает с именем существующего набора данных, то произойдет ошибка конфликта.
Чтобы обновить существующий набор данных, сначала необходимо получить ссылку на существующий набор данных:
dataset = ws.datasets['existing dataset'] print(dataset.data_type_id) # 'GenericCSV' print(dataset.name) # 'existing dataset' print(dataset.description) # 'data up to jan 2015' Затем используйте update_from_dataframe для сериализации и замены содержимого набора данных в Azure:
dataset = ws.datasets['existing dataset'] dataset.update_from_dataframe(frame2) print(dataset.data_type_id) # 'GenericCSV' print(dataset.name) # 'existing dataset' print(dataset.description) # 'data up to jan 2015' Если вы хотите сериализовать данные в другой формат, укажите значение необязательного параметра data_type_id .
from azureml import DataTypeIds dataset = ws.datasets['existing dataset'] dataset.update_from_dataframe( dataframe=frame2, data_type_id=DataTypeIds.GenericTSV, ) print(dataset.data_type_id) # 'GenericTSV' print(dataset.name) # 'existing dataset' print(dataset.description) # 'data up to jan 2015' При необходимости можно задать новое описание, указав значение для параметра description .
dataset = ws.datasets['existing dataset'] dataset.update_from_dataframe( dataframe=frame2, description='data up to feb 2015', ) print(dataset.data_type_id) # 'GenericCSV' print(dataset.name) # 'existing dataset' print(dataset.description) # 'data up to feb 2015' Кроме того, при необходимости можно задать новое имя, указав значение для параметра name . Теперь вы сможете извлекать набор данных только с помощью нового имени. Следующий код обновляет данные, имя и описание.
dataset = ws.datasets['existing dataset'] dataset.update_from_dataframe( dataframe=frame2, name='existing dataset v2', description='data up to feb 2015', ) print(dataset.data_type_id) # 'GenericCSV' print(dataset.name) # 'existing dataset v2' print(dataset.description) # 'data up to feb 2015' print(ws.datasets['existing dataset v2'].name) # 'existing dataset v2' print(ws.datasets['existing dataset'].name) # IndexError Параметры data_type_id , name и description являются необязательными, и по умолчанию используются их предыдущие значения. Параметр dataframe всегда является обязательным.
Если данные уже сериализованы, вместо update_from_dataframe используйте update_from_raw_data : Он работает точно так же, просто вместо raw_data передается dataframe .
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально она была написана следующими авторами.
- Марк Табладильо | Старший архитектор облачных решений
Чтобы просмотреть недоступные профили LinkedIn, войдите в LinkedIn.
Дальнейшие действия
- Изучение и анализ данных с помощью Python
- Клиентская библиотека пакета Машинного обучения Azure для Python версии 1.2.0
- Сбор и обработка данных
Связанные ресурсы
- Изучение данных в процессе обработки и анализа данных группы
- Выборка данных в контейнерах больших двоичных объектов Azure, на сервере SQL Server и в таблицах Hive
- Создание характеристик для данных в SQL Server с помощью SQL и Python
- Что такое процесс обработки и анализа данных группы?
Предварительная обработка данных с помощью библиотеки Pandas (Задача)
В современном мире большинство бизнес-процессов связаны с обработкой больших объемов данных, получаемых от различных источников. Часто эти данные содержат ошибки, дубликаты и пропуски, что может привести к неверным выводам и решениям. Одним из инструментов, которые позволяют очистить и преобразовать данные, является библиотека pandas для языка программирования Python.
Я собираюсь рассмотреть задачу по очистке данных с помощью pandas. Для этого возьмем данные, содержащие дубликаты строк, неправильные типы данных, пропуски и отрицательные значения. Затем я буду использовать функциональные возможности pandas для очистки и преобразования этих данных в форму, пригодную для дальнейшего анализа.
Предположим, у вас есть набор данных, содержащий информацию о продажах компании за последние несколько лет. Но данные не очень чистые, и вы заметили, что есть некоторые проблемы с форматированием и некоторые строки содержат ошибки.
Задача: Необходимо очистить данные о продажах компании за последние несколько лет с помощью библиотеки Pandas.
- Файл CSV, содержащий информацию о продажах компании за последние несколько лет.
- Файл содержит следующие столбцы: дата продажи, название продукта, количество проданного товара, цена за единицу, общая стоимость продажи, имя продавца и регион продажи.
- В некоторых строках присутствуют ошибки, например, неправильный формат даты или отсутствие цены за единицу.
Задачи, которые необходимо выполнить:
- Загрузить исходные данные из файла в Pandas DataFrame.
- Удалить строки, которые содержат ошибки в данных.
- Привести столбец с датами к формату datetime .
- Привести столбцы с числами к числовому формату (float или int).
- Определить и удалить дубликаты строк.
- Сохранить очищенные данные в новый файл CSV.
- date — дата продажи, в формате «YYYY-MM-DD»;
- product_name — название продукта
- quantity — количество продукта
- unit_price — цена за единицу продукта
- total_price — общая стоимость продукта, равная произведению количества и цены за единицу
- seller_name — имя продавца
- region — регион продажи
Загрузка данных
Чтобы загрузить данные в pandas, можно использовать метод read_csv() для загрузки данных из файла CSV или read_excel() для загрузки данных из файла Excel . В нашем случае у нас csv файл.
Импортируем необходимые библиотеки и загружаем данные.
import pandas as pd import re df = pd.read_csv('data_with_errors.csv')Выводим наш DataFrame.
df.head(5)
На первый взгляд в данных видно наличие отрицательных значений и пропусков. Однако, в нашем задании сказано, что после загрузки мы должны удалить строки, в которых есть ошибки. Мы поступим немного по-другому. Сначала мы проверим типы столбцов, и если обнаружится, что какие-то столбцы не соответствуют данным, которые в них находятся, мы изменим тип на соответствующий. При возникновении проблем в ходе выполнения этой задачи, мы будем исправлять то, что будет необходимо.
Обработка данных
Для начала посмотрим на то, какие типы имеют наши столбцы. Для этого нам поможет команда info() .
df.info()Мы получаем информацию о нашем DataFrame, которая говорит нам о наличии пропусков в столбце total_price . Также мы видим, что столбец с датами имеет строковый тип, также как и столбцы quantity и unit_price , которые содержат числовые данные. Нам необходимо это исправить.

Попробуем сразу привести столбец date к типу datetime . Для этого нам понадобится следующий код:
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')К сожалению, этот код не сработает, так как в столбце с данными присутствуют значения, которые не позволяют сразу привести столбец к нужному нам типу. В результате работы выражения будет выведено сообщение об ошибке.

Существует множество способов решения данной проблемы, один из них представлен ниже. Так как даты в нашем столбце date указаны в формате «YYYY-MM-DD», мы можем использовать регулярное выражение для поиска всех значений столбца, которые не соответствуют данному формату. Для этого мы создадим лямбда-функцию, которая будет применена к столбцу методом map() . Регулярное выражение будет выглядеть следующим образом: `\d-\d-\d`.
search = lambda x: x if re.search(r"\d-\d-\d", x) else 'not found'Применяем лямбда-функцию к столбцу date .
df['date'] = df['date'].map(search)df.query('date == "not found"').count()Мы видим, что в 53 строках данные не соответствуют формату..

Посмотрим на эти строки, чтобы понять, с чем мы имеем дело.
df.query('date == "not found"').head(5)
Мы замечаем отсутствие даты, а также латинские буквы вместо чисел в столбце количества quantity . Кроме того, столбец total_price содержит множество пропусков, а unit_price имеет много повторяющихся значений. В таком виде данные не представляют ценности для анализа, и мы должны удалить строки, содержащие ошибки, как указано в задании.
df = df.drop(df.query('date == "not found"').index) df.query('date == "not found"').count()
Приведем столбец date к нужному нам типу данных.
df['date'] = pd.to_datetime(df['date'], format='%Y-%m-%d')df.info()Видим что столбец date теперь имеет тип datetime.

Для того чтобы привести столбец quantity к числовому формату, мы можем использовать метод to_numeric() с параметром errors=’coerce’ , который преобразует значения в числа, а нечисловые значения заменяет на NaN.
df['quantity'] = pd.to_numeric(df['quantity'], errors='coerce')Тоже самое мы делаем с unit_price.
df['unit_price'] = pd.to_numeric(df['unit_price'], errors='coerce')Для продолжения, мы сфокусируемся на отрицательных значениях в указанных столбцах и выведем их на экран.
df.query('quantity < 0')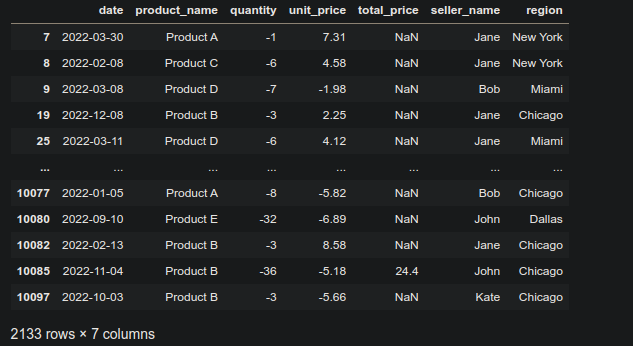
Эти значения будут преобразованы с помощью функции abc() , чтобы преобразовать отрицательные значения в столбцах. Это позволит получить абсолютные значения и избавиться от знака минус.
df.loc[df['quantity'] < 0,'quantity'] = abs(df['quantity'])Таким же образом мы поступим unit_price.
df.query('unit_price < 0')
Заменяем отрицательные значения на положительные.
df.loc[df['unit_price'] < 0,'unit_price'] = abs(df['unit_price'])Обработаем столбец total_price . В задаче указано, что total_price представляет собой общую стоимость продукта, которая равна произведению количества и цены за единицу. Значит, мы можем заполнить пустые значения в этом столбце, умножив значение quantity на значение unit_price . Так и поступим.
df.loc[df['total_price'].isna(), 'total_price'] = df['quantity'] * df['unit_price']Данные содержат некоторое количество дубликатов, которые необходимо удалить в соответствии с заданием.
df[df.duplicated()]
df = df.drop(df[df.duplicated()].index)Проверим категориальные переменные.
df.product_name.unique()
df.seller_name.unique()
df.region.unique()
Все значения категориальных переменных в порядке. Осталось только сохранить данные в csv. В этом нам поможет функция to_csv() .
df.to_csv('processed_data.csv',index=False, header=True)В результате мы получим файл processed_data.csv .
Заключение
Такое задание позволяет закрепить навыки работы с pandas, например, загрузка данных из файла, очистка данных от дубликатов и пропусков, изменение типов данных столбцов и обработка пропущенных значений. Задание также поможет новичкам овладеть принципами анализа данных, включая методы pandas для анализа данных.
В скором времени я планирую выложить разбор реальной задачи для продуктового аналитика, который поможет вам лучше понять, как применять знания и навыки, полученные в процессе изучения данной темы. Я надеюсь, что этот материал будет интересен и полезен для вас, и вы сможете успешно применить полученные знания на практике. Буду благодарен за ваши комментарии! Спасибо!
- данные
- очистка данных
- библиотека Pandas
- ошибки в данных
- удаление строк
- datetime
- дубликаты
- Задача для аналитика
- обработка данных
- Python
- Восстановление данных