Data Race / Состояние гонки
Data race или состояние гонки — это ошибка проектирования многопоточной системы, при которой работа программы зависит от порядка выполнения частей кода, которые не синхронизированы должным образом.
Обновление от 12.07.2021: Судя по всему, в статье произошла путаница терминов. Data Race — это не состояние гонки. Скорее race condition нужно переводить как состояние гонки, а data race — это немного другое. Статью, похоже, нужно переписать или поправить.
Состояние гонки зачастую сложно исправить, так как оно проявляется в случайные моменты времени и пропадает при попытке её локализовать. Data race возникает при условии:
- два или более потока обращаются к одной и той же общей переменной;
- как минимум один из потоков пытается менять значение этой переменной;
- потоки не используют блокировки для обращения к этой переменной.
При выполнении этих трёх условий порядок обращения к переменной становится неопределённым, что приводит к различным и непредвиденным результатам выполнения программы при каждом запуске.
Состояние гонки. Race condition
Состояние гонки. Race condition. Другое название: гонки данных (data race). Ошибка программирования многозадачной системы, при которой работа системы зависит от того, в каком порядке выполняются части кода. Состояние гонки является классическим гейзенбагом. Состояние гонки возникает тогда, когда несколько потоков многопоточного приложения пытаются одновременно получить доступ к данным, причем хотя бы один поток выполняет запись. Состояния гонки могут давать непредсказуемые результаты, и зачастую их сложно выявить. Иногда последствия состояния гонки проявляются только через большой промежуток времени и в совсем другой части приложения. Кроме того, ошибки такого рода невероятно сложно воспроизвести повторно. Для предотвращения состояния гонки используются приемы синхронизации, позволяющие правильно упорядочить операции, выполняемые разными потоками. Приведем пример. Пусть, один поток выполняет над общей переменной x операцию x = x + 3, а второй поток — операцию x = x + 5. Данные операции для каждого потока фактически разбиваются на три отдельных подоперации: считать x из памяти, увеличить x, записать x в память. В зависимости от взаимного порядка выполнения потоками подопераций финальное значение переменной x может быть больше исходного на 3, 5 или 8.
Библиографический список
- Википедия. Состояние гонки
- Википедия. Гейзенбаг
Что такое состояние гонки в java

Многопоточность в Java. Часть 2
Многопоточность в Java. Часть 2
Введение
В предыдущей статье мы рассмотрели базовые темы многопоточности: потоки, класс Thread и интерфейс Runnable. В данной публикации продолжаем осваивать эту непростую тему, разбирая такие понятия, как процесс, проблема видимости, volatile, состояние гонки и многое другое.
1. Что такое процесс?
Процесс — это совокупность ресурсов (кода, виртуального адресного пространства, открытых файлов, уникального идентификатора PID и т. д.), выделенных операционной системой для выполнения запускаемого приложения.
Иногда, в качестве упрощения, под процессом понимают исполняемое приложение.
У каждого процесса имеется хотя бы один поток, называемый главным, с которого начинается выполнение программы. В Java после создания процесса работа главного потока стартует с метода main(). Затем в заданных программистом местах запускаются другие потоки.
Для нужд процесса выделяется необходимый объем памяти из оперативной памяти (в Java — из пространства кучи) в границах которой и происходит обработка данных приложения, а для каждого потока — свой стек и регистры. При этом сам процесс не исполняет код программы — этим занимаются потоки, создаваемые внутри него.
Доступ к памяти друг друга у процессов ограничен, что позволяет избежать множества проблем.
2. Подпроцессы
Когда мы хотим выполнить большие куски задач, разбивая их на более мелкие части, то зачастую не все они могут работать независимо друг от друга. Некоторые из них должны обмениваться данными, при этом работая в разных процессах. Для такого обмена используется межпроцессное взаимодействие.
Проблема с этой идеей заключается в том, что наличие слишком большого количества процессов на компьютере, которые должны общаться между собой, несет и большие расходы. И именно в этот момент становится актуальным использование потоков.
Идея потока заключается в том, что процесс может иметь внутри себя множество крошечных подпроцессов, которые совместно используют пространство его памяти. Это позволяет им быстрее получать доступ к ней, что, несомненно, ведет к увеличению производительности. Эти подпроцессы и называются потоками.
Считается, что процессы являются достаточно ресурсоемкими сущностями, а подпроцессы — их облегченным вариантом или легковесными процессами.
Процессы используются для группировки ресурсов; потоки — для выполнения приложения.
Вроде бы идея хорошая. Однако, есть и ряд недостатков, хотя преимущества все равно перевешивают проблемы. Давайте обсудим некоторые из них и то, как мы можем с ними справиться.
3. Порядок выполнения потоков
Пусть у нас имеется следующий код:
public class Playground < private static boolean running; public static void main(String[] args) < var t1 = new Thread(() -> < while (!running) <>System.out.println("topjava.ru"); >); var t2 = new Thread(() -> < running = true; System.out.println("I love"); >); t1.start(); t2.start(); > >
В приведенном выше фрагменте создаются два потока с общей переменной boolean running. Внутри первого потока while будет продолжать выполняться до тех пор, пока переменная имеет значение false. Как только он прервется, напечатается topjava.ru. Второй поток изменяет переменную running, а затем печатает I love.
Возникает вопрос, что в итоге будет выведено на консоль? Можно предположить следующий вариант (пусть это будет Ситуация 1):
I love topjava.ru
Такой вывод возможен, но если вы запустите приведенный выше код несколько раз, то увидите разные результаты. Это связано с тем, что мы можем только попросить потоки выполнить какую-то часть кода, но нет гарантии, что они сделают эту работу в нужном нам порядке.
Разберем другие возможные варианты работы потоков программы, что, несомненно, повлияет на порядок вывода текста в консоль.
Ситуация 2. Второй поток запускается первым и меняет значение переменной. В первом потоке прерывается цикл и отображается topjava.ru. А второй поток печатает I love.
topjava.ru I love
Ситуация 3. Первый поток может застрять, а второй напечатает I love. И на этом все, больше никакого вывода. Это трудновоспроизводимая ситуация, но она может произойти.
Это связано с тем, что т. к. в современном компьютере может быть несколько процессоров, то мы не можем гарантировать, в каком ядре в конечном итоге будет выполняться поток. Например, вышеупомянутые два потока могут выполняться в двух разных процессорах, что, скорее всего, так и есть.
Когда процессор выполняет код, он считывает данные из основной памяти. Однако современные процессоры имеют различные кэши для более быстрого доступа к памяти: L1 Cache, L2 Cache и L3 Cache — в этом и кроется проблема из третьей ситуации.
При запуске первого потока процессор, который его стартует, может закэшировать переменную running. При этом, второй поток запустится на другом процессоре и изменит переменную, что сделает ее новое значение невидимым первому потоку, т. к. он будет пользоваться старым значением из кэша.
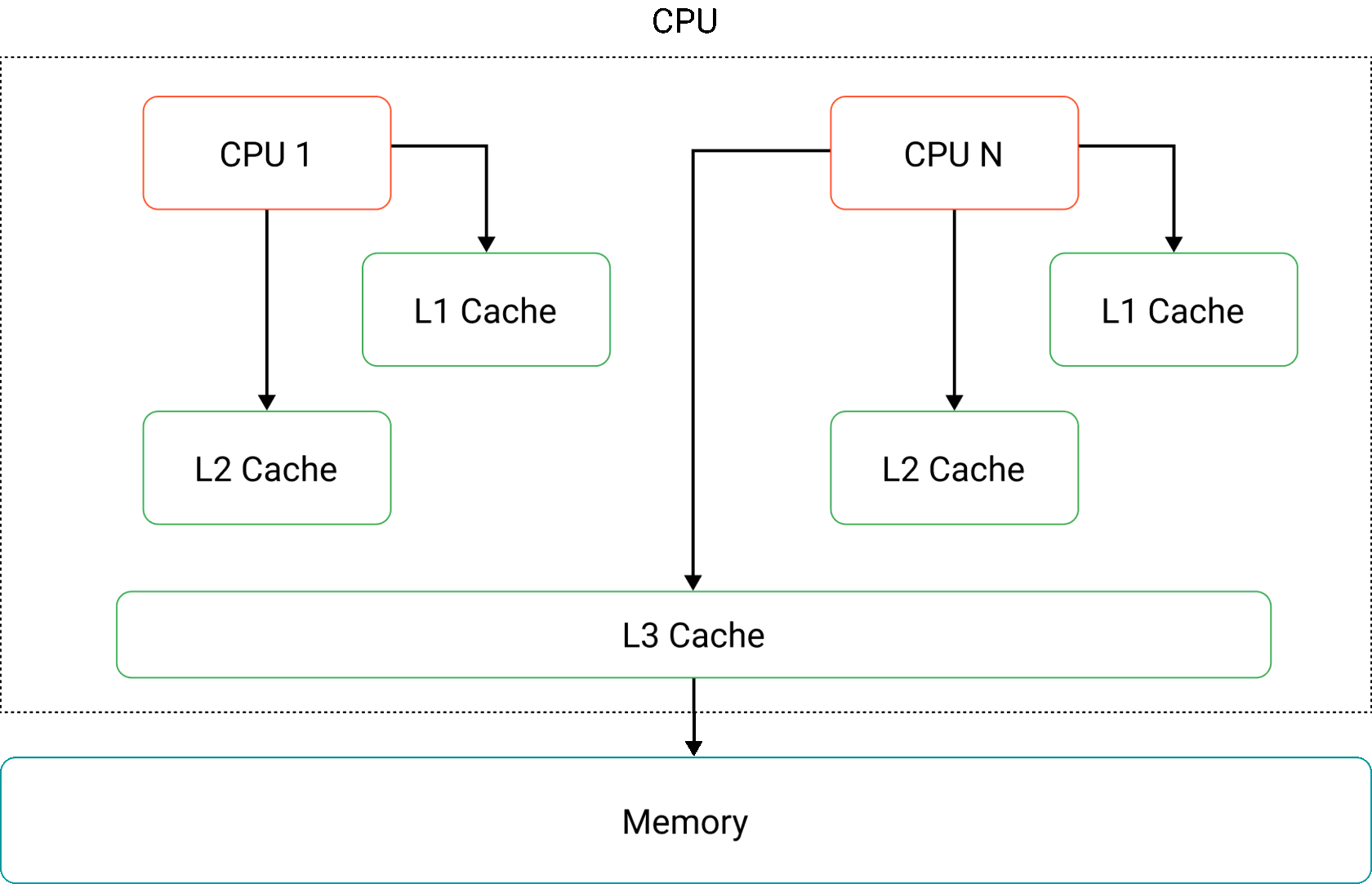
Чтобы этого не происходило, мы можем запретить процессору кэшировать значение переменной, используя модификатор volatile. Вместо этого он будет считывать ее из основной памяти:
public class FoojayPlayground
Теперь, если снова запустить программу, то Ситуация 3 не произойдет.
Описанная выше проблема называется проблемой видимости (visibility problem).
Давайте разберем еще одну подобную ситуацию, используя для ее объяснения символы и псевдокод.
4. Символы и псевдокод
- L — локальная переменная, например, L1, L2
- S — ссылочная переменная, например, S1, S2. Видна нескольким потокам, может быть статической
- S.X — S является ссылочной переменной, а X — полем объекта
В псевдокоде мы будем использовать номер потока и номер строки. Например, 1.1, где 1 — ID потока, а число после точки — номер строки. Или 1.2 — поток 1, строка 2.
Запишем программу, обсуждаемую выше, используя символы и псевдокод:

Порядок ее выполнения, как мы выяснили ранее, может быть следующим:
1) 1.1, 2.1, 1.2, 2.2 2) 1.1, 2.1, 2.2, 1.2 3) 1.1, 2.1, 2.2
Рассмотрим еще одну проблему на другом примере:

У этой программы вывод может быть следующим:
1) 1.1, 1.2, 1.3, 2.1, 2.2, 2.3 2) 2.1, 2.2, 2.3, 1.1, 1.2, 1.3
В первом случае вывод будет:


Существует еще один возможный порядок выполнения:
3) 1.1, 2.1, 1.2, 2.2, 1.3, 2.3
Вывод будет следующим:

5. Оптимизация порядка выполнения
Несмотря на то, что мы показали три возможных варианта выполнения, которые могут прийти на ум в первую очередь, однако, также можно получить следующий результат:

4) 1.2, 2.1, 2.2, 1.1, 1.3, 2.3
Но как это вообще возможно?
Ответ заключается в том, что хоть мы и пишем код в определенной последовательности, но это не означает, что компилятор и виртуальная машина выполнят его в заданном порядке. Они легко могут изменить его в качестве оптимизации (или вообще удалить, как «мертвый код»), если решат, что выходные данные не изменятся. Например, если в первом потоке поменять местами 1.1 и 1.2, то это не повлияет на конечный результат.
Такого рода вмешательства происходят по разным причинам. Например, интеллектуальный алгоритм компилятора может найти способ оптимизировать конкретный код для более быстрого выполнения. Но нужно понимать, что эти изменения могут стать потенциальным источником багов, которые не всегда легко обнаружить. У этого вида ошибок есть даже свое название — Heisenbugs (близкий по значению термин — «плавающая ошибка»). Баги данного типа могут исчезать при их поиске и появляться в произвольные моменты времени.
Обнаружение состояний гонки в java-программах на основе синхронизационных контрактов Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Трифанов Виталий Юрьевич
Состояния гонки (data races) это несинхронизированные обращения к одному и тому же участку памяти разных потоков параллельной программы. Состояния гонки являются одними из самых трудно обнаруживаемых ошибок многопоточного программирования. Автоматический поиск гонок является предметом активных исследований в последние двадцать лет, однако, например, для Java-приложений на настоящий момент не существует полноценного программного средства (детектора гонок), применимого для промышленных приложений (сотни и тысячи классов). В статье предлагается идея динамического обнаружения гонок на основе синхронизационных контрактов. Последние помогают корректно исключать из области анализа произвольные части приложения, по той или иной причине не интересные с точки зрения поиска гонок (например код стандартных библиотек), делая процесс поиска гонок гибко управляемым. Это, в свою очередь, позволяет существенно понизить накладные расходы при поиске гонок без потери точности. В статье также представлена реализация этой идеи и апробация созданного инструмента.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Трифанов Виталий Юрьевич
Статические и post-mortem методы обнаружения гонок в параллельных программа
Динамические средства обнаружения гонок в параллельных программах
Вопросы индустриального применения синхронизационных контрактов при динамическом поиске гонок в Java-программах
Подход к проведению динамического анализа Java-программ методом модификации виртуальной машины Java
Автоматический поиск ошибок синхронизации в приложениях на платформе Android
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Data races occur in parallel programs when several threads perform concurrent accesses to the same location of shared memory without consistent synchronization. Data races are one of the most hardly detectable multithreading errors. A lot of research in the area of automatic data race detection has been held during last twenty years, but, for example, no full-fledged dynamic data race detector for Java-applications, applicable to industrial systems (hundreds and thousands classes), still exists. In this article an idea of dynamic data race detection based on synchronization contracts is proposed. Synchronization contracts assist to exclude certain, uninteresting from the view of data race detection (for example, code of standard libraries), parts of application form the analysis scope, making data race detection process flexibly manageable. By-turn, it makes possible to reduce overhead significantly without loss of precision. An implementation of this idea and evaluation of resulting tool are also introduced.
Текст научной работы на тему «Обнаружение состояний гонки в java-программах на основе синхронизационных контрактов»
Трифанов Виталий Юрьевич
обнаружение состояний гонки
в java-программах на основе синхронизационных контрактов
Состояния гонки (data races) — это несинхронизированные обращения к одному и тому же участку памяти разных потоков параллельной программы. Состояния гонки являются одними из самых трудно обнаруживаемых ошибок многопоточного программирования. Автоматический поиск гонок является предметом активных исследований в последние двадцать лет, однако, например, для Java-приложений на настоящий момент не существует полноценного программного средства (детектора гонок), применимого для промышленных приложений (сотни и тысячи классов). В статье предлагается идея динамического обнаружения гонок на основе синхронизационных контрактов. Последние помогают корректно исключать из области анализа произвольные части приложения, по той или иной причине не интересные с точки зрения поиска гонок (например код стандартных библиотек), делая процесс поиска гонок гибко управляемым. Это, в свою очередь, позволяет существенно понизить накладные расходы при поиске гонок без потери точности. В статье также представлена реализация этой идеи и апробация созданного инструмента.
Ключевые слова: многопоточность, параллельное программирование, автоматическое обнаружение ошибок, состояние гонки.
В настоящее время один из основных ресурсов в увеличении производительности программно-аппаратных систем — это параллелизм. Становится все больше многоядерных и многопроцессорных вычислительных устройств, но, для того чтобы их эффективно использовать, нужны параллельные программы. Однако разработка таких программ является сложной задачей, при их создании допускаются специфические ошибки, связанные с синхронизацией параллельных потоков. Состояния гонки (data race) -одни из самых трудно обнаруживаемых ошибок параллельного программирования. Состояние гонки возникает, когда два потока несинхронизированно обращаются к одному и тому же участку памяти и одно из этих обращений является записью данных [27].
© Трифанов В.Ю., 2012
Гонки очень трудно обнаружить с помощью тестирования, так как их возникновение обычно не приводит к немедленному сбою в программе. Но повреждаются глобальные данные, и это проявляется лишь через некоторое время, в других модулях и подсистемах, отличных от той, где произошла гонка, в виде необъяснимых поведенческих эффектов. Более того, эти эффекты могут быть разными и иметь «плавающий» характер. Кроме того, разработка и тестирование программной системы обычно осуществляются на рабочих станциях с малым количеством ядер и процессоров, а использование — на больших серверах, которые могут содержать несколько сотен или даже тысяч ядер и процессоров. В последнем случае вероятность проявления многопоточных ошибок очень высока, а в первом случае они могут не проявиться из-за низкого уровня параллелизма.
Итак, задача автоматического обнаружения гонок является актуальной и востребованной на практике, исследования в этой области ведутся уже более двух десятков лет. Существуют два принципиально разных подхода к автоматическому обнаружению гонок — статический анализ исходного кода или скомпилированных файлов программы [18, 23, 26] и динамический анализ программы непосредственно во время её выполнения [16, 17, 19, 30].
Методы статического анализа не требуют запуска исследуемого приложения, поэтому их работа не зависит от входных данных, окружения и контекста исполнения приложения. Кроме того, статические методы осуществляют поиск гонок во всех модулях приложения, независимо от частоты их реального выполнения. К сожалению, задача проверки существования потенциальных состояний гонки в программе NP-пол-на для конечных графов выполнения и алгоритмически неразрешима в общем случае [27, 28]. Поэтому статическим детекторам приходится существенно ограничивать глубину анализа графа выполнения программы, что приводит к низкой точности поиска — то есть существующие в программе гонки не обнаруживаются (false negatives) — и множеству ложных срабатываний — находятся псевдогонки (false positives).
Динамические методы поиска гонок нацелены на преодоление этих проблем. Они осуществляют проверки непосредственно во время работы программы, когда доступна вся информация о ходе её выполнения. Однако существует ряд трудностей, препятствующих разработке эффективных динамических детекторов, главная из которых — большие накладные расходы, возникающие из-за того, что требуется обрабатывать очень большой объем данных: все операции синхронизации и все обращения к разделяемым данным.
Фактически, основными требованиями к промышленному динамическому детектору является сочетание приемлемой точности поиска и производительности. Проблема
высокой точности является сугубо алгоритмической и была решена на заре исследований в области динамического поиска гонок посредством изобретения точного алгоритма happens-before, одна из эталонных реализаций которого представлена в работе [21]. В работе [11] представлена проведённая нами адаптация данного алгоритма к Java-программам. Однако обработку всех операций синхронизации и всех обращений к разделяемым данным в программе невозможно осуществить эффективно, и, по-видимому, оптимизации в этом направлении не дадут эффекта, поскольку количество перехватываемых операций все равно остаётся очень большим, равно как и накладные расходы на хранение векторных часов и т. д. В связи с этим сокращение объёма обрабатываемых данных видится более перспективным подходом — необходимо сузить область анализа программы для достижения приемлемой производительности. Этим путём идёт метод семплирования (sampling) [15, 24] (анализируются не все события, а лишь их часть). Такой подход существенно увеличивает производительность, однако ведёт к потере точности1. Необходимо отметить, что, несмотря на обилие исследований в области динамического поиска гонок, большинство работ ограничивается усовершенствованием существующих алгоритмов и реализацией прототипов.
В данной статье предлагается и обосновывается идея динамического обнаружения гонок на основе синхронизационных контрактов. Последние предназначены для того, чтобы позволять корректно исключать из области анализа произвольные части приложения, по той или иной причине не интересные с точки зрения поиска гонок (например код стандартных библиотек), и избежать потери точности, тем самым делая процесс поиска гонок гибко управляемым. Это, в свою очередь, позволяет существенно понизить накладные расходы динамического поиска гонок без потери точности. В статье также представлена реализация этой идеи и апробация созданного инструмента.
1 Подробный обзор статических и динамических методов поиска гонок представлен автором в работах [12, 13].
2. ОТНОШЕНИЕ HAPPENS-BEFORE
При динамическом подходе к поиску гонок нужно уметь отвечать на следующий вопрос: правда ли, что любые два обращения к разделяемому участку памяти из различных потоков, где одно из них является обращением на запись, упорядочены с помощью синхронизационных операций? Более формально, программа считается свободной от гонок, если в ней между любыми двумя обращениями разных потоков Т1 (на запись) и Т2 (на чтение или запись) к одной переменной происходит синхронизация (то есть устанавливается барьер памяти): поток Т2 видит изменения, сделанные потоком Т1 [31]. Это отношение называется отношением Ьарреш-ЪеЮге и формально задаётся следующим образом [20]:
— если событие А синхронизировано с событием В, то А Ьарреш-ЪеЮге В;
— действия в одном потоке, произошедшие одно после другого, находятся в отношении Ьарреш-ЪеЮге;
— завершение конструктора объекта предшествует запуску его финализатора (йпа^ег);
— отношение Ьарреш-ЪеЮге транзитив-но замкнуто.
Два обращения А и В из различных потоков к одному участку памяти не образуют гонку, если А Ьарреш-ЪеЮге В или В Ьарреш-ЪеЮге А [20].
Для отслеживания отношения Ьарреш-ЪеЮге используется предложенный Лампортом в 1978 году механизм векторных часов [22]. Векторные часы представляют собой массив чисел, по длине равный количеству потоков в программе: каждому потоку соответствуют одни часы (одно число), увеличивающиеся по мере совершения потоком операций. Каждый поток хранит свою локальную копию векторных часов, синхронизиру-ясь с копиями часов других потоков во время синхронизационных операций. Передача часов между потоками осуществляется с помощью вспомогательных часов, ассоциированных с синхронизационными объектами.
Векторные часы хранят информацию о каждом потоке в системе и потому очень
«дороги»: если в программе n потоков, то каждая операция над векторными часами требует O (n) времени, а для хранения часов нужно O(n) памяти. Поэтому, хотя теоретически и возможен сбор информации о программе с любой степенью точности, на практике эта точность сильно ограничена необходимостью обеспечивать эффективность как по потреблению ресурсов, так и по скорости выполнения программы. Динамический анализ приводит к большим накладным расходам, поэтому его крайне сложно применять для высоконагружен-ных приложений.
В спецификации Java happens-before задается с помощью отношения «synchronized-with» (отношение синхронизировонности), которое формально определяется следующим образом:
— освобождение монитора всегда синхронизировано с его последующим захватом;
— запись volatile-переменной всегда синхронизирована с её последующим чтением;
— операция запуска потока всегда синхронизирована с первым действием в этом потоке;
— последнее действие потока T1 всегда синхронизировано с любым действием потока T2, который «знает», что поток T1 остановился (с помощью Thread.join() или Thread.isAlive());
— если поток T1 прерывает поток T2, прерывание синхронизировано с любым действием в любом потоке, который «знает», что поток T1 был прерван (перехватил InterruptedException или вызвал Thread.isInterruptedO);
— запись значения по умолчанию каждой переменной всегда синхронизирована с первым действием любого потока.
В Java каждой паре синхронизированных событий соответствует определённый синхронизационный объект — например монитор, volatile-переменная или сам поток. Первый элемент пары событий мы в дальнейшем будем называть захватом синхронизационного объекта, а второй — его освобождением (по аналогии с частным случаем -захватом и освобождением блокировки).
Для популярных индустриальных языков программирования (Java, C# и т. д.) существует множество готовых библиотек и подсистем, реализующих стандартную функциональность — работу с базой данных, организацию клиент-серверного сетевого взаимодействия и т. д., которые имеют хорошо специфицированные и детально документированные интерфейсы (см. рис. 1). При разработке нового приложения в большинстве случаев используется значительное количество таких библиотек — это помогает сконцентрироваться на специфических для приложения задачах, делегировав типовую функциональность хорошо зарекомендовавшим себя надежным сторонним программным компонентам.
Безусловно, существует ряд систем с повышенными требованиями надёжности и отказоустойчивостью: как правило, это системы реального времени, например системы управления телевещанием, бортовые системы управления или регистраторы аварийных событий. В таких системах надежности используемых сторонних компонент уделяется не меньше внимания, чем самому приложению. Однако для широчайшего класса бизнес-систем надёжность используемых библиотек предполагается достаточной, то есть основным источником ошибок априори предполагается разрабатываемый код. Кроме того, сложность самих приложений достаточно велика, поэтому разработ-
чики и тестеровщики фокусируются на корректности и качестве самого приложения, а не используемых им компонент.
Обнаружение и устранение гонок в приложении является частью разработки и тестирования системы, поэтому и в этом случае логично сфокусироваться на анализе самого приложения, а все сторонние библиотеки исключить из анализа. В некоторых разрабатываемых системах код самого приложения может составлять лишь малую часть (несколько процентов) от совокупного объема кода приложения и используемых библиотек. Например, именно таким будет соотношение для типичного клиент-серверного приложения с незначительной бизнес-логикой. Для других же систем количество собственного кода, напротив, может составлять 80% всего кода системы и более. Так обстоит дело в приложениях, реализующих сложные протоколы взаимодействия систем. В среднем можно утверждать, что объем программного кода используемых приложением библиотек сопоставим с объёмом кода самого приложения. В этом свете исключение библиотек из области поиска гонок позволит получить существенный прирост производительности.
Однако недостаточно просто исключить библиотеки из анализа — это приведёт к тому, что детектор пропустит множество операций синхронизации и произведёт большое количество ложных срабатываний. Сложно точно оценить количество таких ложных срабатываний, однако результаты разработчи-
Рис. 1. Типовая организация взаимодействия приложения со сторонними библиотеками
ков метода семплирования позволяют утверждать, что в общем случае их количество будет достаточно большим, чтобы существенно затруднить вычленение реальных гонок из множества всех обнаруженных [15, 24]. Более того, в современном программировании очень часто непосредственное управление ходом выполнения программы, а также порождение и контроль выполнения потоков делегируется различным стандартным библиотекам. Например в типичном клиент-серверном Java-приложении ходом выполнения программы может управлять Spring1 или Seam2, а обработкой клиентских запросов в различных потоках — контейнер сервлетов Apache Tomcat3. В таких случаях фактически вся синхронизация между потоками осуществляется вне кода самого приложения, поэтому при исключении этих библиотек из анализа количество ложных срабатываний будет огромно.
Итак, если мы хотим исключить из анализа гонок код библиотек, то нам необходимо описать поведение этого кода в многопоточной среде. Например, если подсистема обмена сообщениями экспортирует интерфейс потокобезопасной очереди сообщений, то необходимо описать свойство по-токобезопасности его методов и, возможно, дополнительные свойства, гарантирующие синхронизацию между потоками в случае корректного использования методов данной очереди.
Интерфейсы библиотек и модулей содержат только описания сигнатуры экспортируемых примитивов, но не их поведенческие свойства и, более того, не предоставляют средств для описания этих свойств. Можно было бы аннотировать исходный код библиотек — о применении аннотирования в статическом анализе и компиляции см. например работы [1, 9]. Однако исходный код сторонних библиотек, как правило, недоступен и
фактически никогда не включается в сборку приложения.
В программировании существует широко известная концепция контрактов [25], воплощённая в языке Eiffel. Базовым понятием этой концепции является контракт программной сущности (как правило, метода), состоящий из предусловий, постусловий и инвариантов [25]. Кроме того, дополнительно можно задавать инварианты для классов и других комплексных сущностей. По сути, в данном подходе контракты являются описаниями поведенческих свойств, которые дополнительно экспортируются наружу наряду с сигнатурой. В общем случае язык описания контрактов имеет сложность, сопоставимую со сложностью обычных языков программирования4.
Предлагаемый нами подход базируется на идее контрактов, однако не следует ей в строгом смысле, поскольку набор свойств, интересных с точки зрения обнаружения гонок, весьма узок и специфичен и может быть описан более простым способом, без использования полноценного языка описания контрактов.
4. СИНХРОНИЗАЦИОННЫЕ КОНТРАКТЫ
Принцип инкапсуляции в объектно-ориентированном подходе к программированию подразумевает, что использование объекта осуществляется посредством вызова его публичных операций. В Java это вызовы методов классов. Соответственно, достаточно уметь описать возможность использования методов исключённых классов в многопоточной среде. С этой точки зрения возможны следующие варианты:
— метод не является потокобезопасным, то есть его одновременное использование несколькими потоками не предусмотрено и требует внешней синхронизации;
1 Spring framework: http:// www .spring source.or g/.
2 Seam framework: http ://www. seamframework.org/.
3 Apache tomcat: http://tomcat.apache.org/.
4 Например, см. такие расширения Java, предоставляющие возможность описания контрактов, как JavaTESK (http://www.unitesk.ru/content/categorv/5/25/60/), jContractor (http://icontractor.sourceforge.net/), contract4j (http:// sourceforge.net/projects/contract4i/), а также использование контрактов в модельно-ориентированном тестировании [3].
— метод потокобезопасен и может вызываться несколькими потоками одновременно без внешней синхронизации;
— метод не только потокобезопасен, но и является частью комплексного механизма синхронизации, который гарантирует синхронизацию потоков.
Эти варианты составляют различные примитивы синхронизационного контракта программной компоненты. Рассмотрим эти варианты подробней, а затем перейдём к определению синхронизационного контракта (рис. 2).
4.1. ПОТОКОНЕБЕЗОПАСНЫЕ МЕТОДЫ
Поскольку предполагается, что мы имеем дело с интерфейсом, не имеющим побочных эффектов, то вызов такого метода может модифицировать только тот объект, на котором он был вызван. Соответственно, необходимо отслеживать вызовы потоконе-безопасных методов одного и того же объекта из различных потоков и сигнализировать об этом пользователю. Однако возможно и такое, что метод является немодифицирую-щим, то есть он лишь читает внутреннее состояние объекта, но не изменяет его. Со-
гласно определению гонки, одновременные чтения общей разделяемой памяти из различных потоков не образуют гонки — необходимо, чтобы один из потоков осуществлял запись в эту память. Соответственно, необходимо разделять модифицирующие и немодифицирующие методы объектов. Однако для понимания природы метода зачастую необходимо существенно углубиться в его реализацию. С другой стороны, если все методы трактовать как модифицирующие, то возможно лишь обнаружение ложных гонок (false positive), что не так критично, как пропуск гонок (false negative). Поэтому по умолчанию нужно трактовать все методы как модифицирующие, но предоставлять возможность пометить метод как немодифици-рующий.
4.2. ПОТОКОБЕЗОПАСНЫЕ МЕТОДЫ
Если метод предназначен для одновременного использования несколькими потоками, то его использование не может привести к гонке, поэтому динамическому детектору отслеживать вызовы данных методов не нужно.
Рис. 2. Взаимодействие динамического детектора с целевым приложением и контрактами сторонних библиотек
4.3. МЕТОДЫ-ЧАСТИ КОМПЛЕСКНЫХ МЕХАНИЗМОВ СИНХРОНИЗАЦИИ
Методы экспортируемого интерфейса могут не только гарантировать корректность поведения в многопоточной среде, но и обеспечивать синхронизацию между потоками. Иными словами, такие методы могут быть частью высокоуровневого синхронизационного механизма, обеспечивающего передачу отношения Ьарреш-ЪеЮге, и это описано в документации. Данную информацию, безусловно, необходимо использовать при поиске гонок, поскольку это обеспечит отсутствие потери точности, которое возможно по причине сужения области анализа. Следовательно, необходим способ описания подобных механизмов.
Передача отношения Ьарреш-ЪеЮге, как говорилось выше, связана с синхронизационным объектом и состоит из двух частей -один поток освобождает синхронизационный объект, а второй впоследствии его захватывает, что и обеспечивает синхронизацию между этими потоками. Следовательно, передача Ьарреш-ЪеЮге обеспечивается парой вызовов методов — один поток вызывает первый метод, а потом второй поток вызывает второй метод (возможно, совпадающий с первым, возможно — нет). Таким образом, необходимо уметь описывать связи между вызовами пар методов. Это возможно, поскольку с этими вызовами связан синхронизационный объект. Поскольку мы предположили отсутствие побочных эффектов, то связь между вызовами методов посредством синхронизационного объекта должна быть явной, то есть опираться на объекты, являющиеся частями сигнатуры метода. Переберем все варианты примитивной связи между вызовами методов.
Пусть у нас есть два метода: метод /(Р11, . Р1п) объекта 01 и метод g(Р21, . Р2т) объекта 02, где п, т > 0. Объект 01 будем называть объектом-вла-делъцем метода f, а 02 — объектом-владель-цем1 метода g. Примитивная связь может быть одной из следующих трёх типов, представленных ниже.
1. Связь «владелец-владелец»: 01 == 02, то есть методы принадлежат одному объекту.
2. Связь «владелец-параметр»:
3 г е [1..п]: 02 == Риог 3у е [1..т]: 01 == Ру, то есть параметр одного метода является объектом-владельцем второго метода.
3. Связь «параметр-параметр»:
3 г е [1..п],у е [1..т]: Ри == Ру, то есть г-й параметр метода /и у-й параметр метода g являются одним и тем же объектом.
Фактически, любая реальная связь между вызовами методов является комбинацией конечного количества представленных выше примитивных связей2. Все такие связи, гарантирующие синхронизацию (отношение Ьарреш-ЪеЮге), необходимо явно описывать в синхронизационном контракте библиотеки.
Вернемся к потокобезопасным методам. Они предназначены для одновременного использования несколькими потоками и не требуют дополнительной синхронизации, то есть эти методы обеспечивают синхронизацию потоков внутри себя. Таким образом, если два потока вызывают по очереди один и тот же потокобезопасный метод, то между ними может возникнуть отношение Ьарреш-ЪеЮге. Но поскольку эта синхронизация не декларирована явно и носит, скорее, случайный характер, мы не будем описывать такую передачу отношения Ьарреш-ЪеЮге в наших контрактах. В качестве примера рассмотрим
1 Строго говоря, в объектно-ориентированных языках программирования методы бывают двух типов -методы, принадлежащие непосредственно классу (например, в Java они помечаются ключевым словом static), и методы, принадлежащие конкретному объекту данного класса. Для упрощения изложения мы считаем, что для каждого класса существует единственный объект типа «class», которому принадлежат все методы из этого класса. Например, в Java такой объект действительно существует и может быть получен с помощью ключевого слова «class». Имея в виду данное допущение, мы можем трактовать любой метод как принадлежащий объекту, а не классу.
2 Возможна также связь через возвращаемое значение метода, которую мы не рассматриваем в данной статье. По нашим наблюдениям, такая связь встречается крайне редко, однако безусловно требует изучения. Обсуждение этого вопроса см. в разделе 6 «Ограничения подхода».
метод print, отвечающий за печать в файл, и предположим, что он потокобезопасен и внутри себя защищает непосредственное обращение к файлу критической секцией, поскольку с файлом одновременно и безопасно может работать только один поток. Два потока, которые по очереди вызвали этот метод, в действительности синхронизируются — выход первого потока из критической секции будет предшествовать (happens-before) входу второго потока в критическую секцию. Однако данная передача отношения happens-before является частью реализации метода print, не описана в его документации и не должна использоваться программистом для обеспечения синхронизации потоков.
4.4. СИНХРОНИЗАЦИОННЫЕ КОНТРАКТЫ
Будем называть happens-before контрактом описание пары вызовов методов, которые, будучи вызванными в определённом порядке (связь между вызовами этих методов определяется суперпозицией примитивных связей, определённых выше), гарантируют корректную синхронизацию потоков.
Рассмотрим пример. В листинге 1 приведён фрагмент happens-before контракта для пары методов put() и get() известного Java-интерфейса ConcurrentMap. В этом контракте указано, что вызов метода put() синхронизирован с последующим вызовом метода get() того же объекта по тому же ключу (в обоих методах ключ является первым пара-
метром; в Java нумерация параметров начинается с нуля). То есть описываемая в данном случае связь является суперпозицией примитивных связей первого и третьего рода.
Будем называть синхронизационным контрактом программной компоненты объединение всех happens-before контрактов для вызовов методов её публичных интерфейсов и перечисление всех ее потокобезопасных методов.
Можно описать следующим образом схему анализа кода, который готовится к исключению и для которого мы хотим описать синхронизационный контракт. Нужно найти все вызовы методов исключаемого кода в основном коде и обработать их по алгоритму, пред-ставленому на рис. 3.
Каждый вызов метода нужно проанализировать на предмет его потокобезопаснос-ти. Если метод потокобезопасен и не является частью механизма синхронизации, то необходимо пометить его как потокобезопас-ный в контракте данной программной компоненты; если является — создать соответствующий happens-before контракт. Если же метод потоконебезопасен, то по нему следует искать гонки. Как говорилось выше, любой такой метод будет по умолчанию трактоваться детектором, как модифицирующий (write). Однако, если анализ показал, что данный метод точно является немодифици-рующим, можно пометить его соответству-
Листинг 1. Пример happens-before контракта для Java