Как сравнить две таблицы по определенным столбцам, и вывести разницу?
Здравствуйте. Подскажите пож., как мне python сравнить в двух таблицах (разные по размерам) определенные столбцы и в случае, если в таблице №1 нет значения из таблицы №2, то возвращает строку из 1 таблицы.
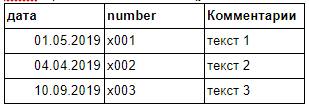
Пример таблиц.
Таб1 Сравниваем по столбцу number
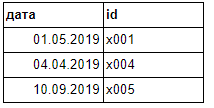
Таб2 Сравниваем по столбцу id

Ожидаемый результат (из первой таблицы исключить первую строчку (x001), т.к. id есть во второй таблице):
- Вопрос задан более трёх лет назад
- 555 просмотров
2 комментария
Средний 2 комментария
Сравнение данных двух таблиц
Сравнение таблиц как условие
Здравствуйте. Значит так это снова я не "понимающий". Опишу ситуацию. Есть процедура в которую я.

Сравнение всех данных двух таблиц access
Добрый день профи. Прошу помочь решить проблему сравнения таблиц. В базе Access есть 2 таблицы.
Сравнение двух таблиц и вывод данных из другой колонки
Добрый день. Возникла такая проблема: Есть база в ней допустим 2 таблицы(tab1 и tab2). В таблице.
Сравнение двух таблиц и копирование в третью таблицу разницу в данных
Здравствуйте уважаемые форумчане и все спецы по Access. Выкладываю базу с надеждой на вашу помощь.
Как сравнить две таблицы в sql и найти разницу
Есть две одинаковые по колонкам таблицы (номенклатуру, количество — т.е. в таблицах всего две колонки).
Задача сравнить исходные таблицы и получить таблицу с отличающимся количеством номенклатуры. т.е. буквально необходимо понять, что в 1ой таблице номенклатуры Х больше на 2шт, номенклатуры Х1 меньше на 1 шт и т.д. Перебором то у меня получается, но хочется сделать это запросом, т.к. таблицы могут быть до 150 строк в каждой — наверное запросом быстрей ? Спасибо.
ВЫБРАТЬ * ИЗ &ВТ1 ПОЛНОЕ СОДЕНИНЕНИЕ &ВТ2
Т.е. сначала получить совпадающие строки, удалить их из исходных таблиц и дальше уже перебором по 2м таблицам бегать ?
Спасибо. (перепутал с внутренним сначала)
Соединяешь по номенклатуре и неравному количеству
Выяснился нюанс. В одной из исходных таблиц может вообще не быть какой то номенклатуры. Поэтому, результат запроса все равно обрабатывать перебором нужно.
ВЫБРАТЬ СУмма(Количество),
Номенклатура
(ВЫБРАТЬ -Количество,
Номенклатура Из &Первая
Объедини
-Количество,
Номенклатура Из &Вторая) Подзапрос
Сгруппировать ПО Номенклатура
ИМЕЮЩИЕ
СУмма(Количество) <> 0
(6) Самое оптимальное, если минус количество, то номенклатура есть в первой таблице, а если плюс, то во второй.
(6) Зачем с группировкой? Сервак грузить. Можно просто из полного соединения:
Идея:
Выбрать
Выбор когда Ном1 есть null тогда Ном2 иначе Ном1 конец,
естьNull(Кол1,0)-естьNull(Кол1,0)
из
1 полное соединение 2
по
Номенклатура
где
естьNull(Кол1,0) <> естьNull(Кол2,0)
(8) не знаю, что там в SQL
Но чаще делаю как (6): проще и нагляднее, точно нигде не вылезет NULL ))
(6)В результат попадает и та номенклатура, по которой полное совпадение. Строки, по которым все хорошо мне не нужны.
(10) Сначала полное соединение, потом условие.
(6) Тогда первый или второй минус в подзапросе убери, чтобы человек получил только отличия.
(1)Спасибо.
(8)Спасибо за условие.
У меня получилось вот так. Может и не оптимально, но остаются только строки по которым нет соответствия между таблицами.
ЗапросСравнение.Текст = «ВЫБРАТЬ РАЗРЕШЕННЫЕ
| ТекущаяТаблицаНоменклатуры.Номенклатура КАК Номенклатура,
| ТекущаяТаблицаНоменклатуры.Количество КАК Количество
|ПОМЕСТИТЬ ВТ1
|ИЗ
| &ТекущаяТаблицаНоменклатуры КАК ТекущаяТаблицаНоменклатуры
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ВТ1.Номенклатура,
| ВТ1.Количество,
| ПоследняяТаблицаРазмещения.Номенклатура КАК ПоследняяНоменклатура,
| ПоследняяТаблицаРазмещения.Количество КАК ПоследняяКоличество
|ПОМЕСТИТЬ РезультатСоединения
|ИЗ
| ВТ1 КАК ВТ1
| ПОЛНОЕ СОЕДИНЕНИЕ ПоследняяТаблицаРазмещения КАК ПоследняяТаблицаРазмещения
| ПО ВТ1.Номенклатура = ПоследняяТаблицаРазмещения.Номенклатура
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| РезультатСоединения.Номенклатура,
| РезультатСоединения.Количество,
| РезультатСоединения.ПоследняяНоменклатура,
| РезультатСоединения.ПоследняяКоличество
|ИЗ
| РезультатСоединения КАК РезультатСоединения
|ГДЕ
| ЕСТЬNULL(РезультатСоединения.Количество, 0) <> ЕСТЬNULL(РезультатСоединения.ПоследняяКоличество, 0)»;
Как сравнить две таблицы в sql и найти разницу
Коллеги, поделитесь, кто чем пользуется для сравнения больших объемов данных двух баз 1с при сверках, для регрессионного тестирования и т.д,
Интересны быстрые реализации, например когда представления ссылок извлекаются только для результата сравнения, а сама сверка выполняется по уидам и т.п.
(0) Простые самопальные обработки, запросы в консоли, ХМЛ-ки сравниваю как текстовики, чтобы проводки сравнить в 2 базах. От случая к случаю надо проверять разные вещи — универсального инструмента нет и быть не может.
(0) Для сверки нужно сравнивать не таблицы БД, а отчеты.
Для регрессионного тестирования не нужны большие объемы.
Давай твой конкретный сценарий, найдется конкретное решение. А натягивать сову на глобус не надо.
так мердж ведь
берёшь 2 таблицы , сортируешь по ключу и вперёд
(4) вопрос каким инструментом, чтобы сверить _к примеру_ обороты регистра в двух базах
(5) Делай регистр копию в базе, в него через XML заливай движуху из 2 базы через XML обмен и потом запросик.
Ну или ВнешниеИсточникиДанных
(5) отчет — mxl — сравнить файлы
Это если надо быстро различия глазками увидеть
(5) выкидываешь нужные поля из своих регистров своих двух баз во внешнюю sql базу (1С на чтение шустра достаточно)
внешнюю sql можно использовать sqlite, mssql и прочие на свой вкус
1С, Файл — сравнить файлы.
что значит «большие»? это 10 тыс или 10 лямов или больше?
(11) сотни мегабайт
если на 32 клиенте выбирать то запрос падает по нехватке памяти
(0) У нас есть такая система регресс-тестов. Тупо выгружаем в текстовые файлы и их сравниваем автоматом. Если есть расхождения, то уже смотрим их суть глазками.
Но это реально тупик в развитии тестов, так как с таким подходом 99% ресурсов и времени уходит впустую. Лучше все же переходить на конкретные сценарии с той же Vanessa. Но это дорого в части ресурсов на разработку тестов и сопровождение.
если таблицы действительно большие и идентичные — можно хэшировать и сравнивать только хэш.
у нас только в таком режиме получилось сравнить таблицы в сотни гигабайт между разными городами.
(10) Использую иногда, но выложить файл в ГИТ, а потом поверх него другую версию положить мне больше нравится
потому что в рамках одной строчки последовательности анализируются, а не тупо различающиеся строки выводятся
(5) пару раз пользовались http://catalog.mista.ru/public/276275/ от ildarovich, отлично работает
(13) как всегда, ресурсы либо там тратятся либо тут
(17) сейчас не могу скачать, там по уидам сравнение идет?
Для сравнения таблиц еще есть инструмент в ИР «Сравнение таблиц»
http://devtool1c.ucoz.ru/index/sravnenie_tablic/0-62 (свежий скриншот https://i.imgur.com/TThTRLs.png )
Не знаю насколько он быстр относительно аналогов, но гибкость большая.
Сотни гигибайт через него не сравнивал, но сотни гигабайт вполне комфортно сравнивать.
(20) Сотни мегабайт сравнивал. В нем НЕ потоковое сравнение.
(19) там кейс использования(описан в статье) например в сравнении с вчерашней копией чтобы узнать что изменилось, быстрота реализации достигается не за счет упаковки ссылок.
какой смысл сразу тащить все ссылки, если по факту нужны только ссылки по расхождениям в ресурсах, нужно сначала найти их. ссылки извлекаются (ЗначениеИзСтрокиВнутр) только на этапе когда найдено расхождение в количестве.
Когда требовалось сравнивать огромные идентичные регистры бухгалтерии, выгружал его в файл в одной базе и использовал автоматизированное потоковое сравнение с БД в другой базе. Если процесс сравнения прерывался по какой то причине, то регламент его восстанавливал и он шел дальше. Конечно это далеко не секунды, как у знаменитого Ильдаровича, но работало надежно и без прямого соединения между базами.